📄 TINY BUT MIGHTY: A SOFTWARE-HARDWARE CO- DESIGN APPROACH FOR EFFICIENT MULTIMODAL IN- FERENCE ON BATTERY-POWERED SMALL DEVICES
#多模态模型 #实时处理 #多通道 #开源工具
✅ 7.0/10 | 前25% | #多模态模型 | #实时处理 | #多通道 #开源工具
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Yilong Li(University of Wisconsin – Madison)
- 通讯作者:未说明
- 作者列表:Yilong Li(University of Wisconsin – Madison)、Shuai Zhang(Amazon Web Services AI)、Yijing Zeng(University of Wisconsin – Madison)、Chengpo Yan(University of Wisconsin – Madison)、Hao Zhang(University of Wisconsin – Madison)、Xinmiao Xiong(University of Wisconsin – Madison)、Jingyu Liu(University of Wisconsin – Madison)、Pan Hu(Uber)、Suman Banerjee(University of Wisconsin – Madison)
💡 毒舌点评
这篇论文亮点在于提出了一个完整的、软硬件协同设计的系统框架(NANOMIND),并通过自研硬件原型机验证了其在电池供电设备上运行多模态大模型的可行性,实测的能效比数据(降低42.3%能耗)很有说服力。短板在于其对比实验主要聚焦于自身设计的硬件平台与不同软件框架的对比,缺乏与当前主流商用边缘设备(如最新款旗舰手机)上SOTA框架的公平、全面比较,这削弱了其结论的普适性和说服力。
🔗 开源详情
- 代码:论文中未提及NANOMIND框架本身的代码仓库链接。
- 模型权重:论文中未提及公开的、经过其框架优化后的模型权重。
- 数据集:实验使用了公开的基准数据集(InfoVQA, DocVQA, MMBench, MME),但论文未提供额外数据集。
- Demo:论文展示了硬件原型机(图11),但未提供在线演示或远程访问方式。
- 复现材料:论文提供了硬件设计框图(图4)、部分内核设计思路和性能数据,但未给出完整的构建指南、驱动源码、内核实现或检查点。
- 论文中引用的开源项目:llama.cpp, Whisper.cpp, Piper, Rockchip RKNN Toolkit2, Qualcomm AI Hub。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的大型多模态模型(LMM)在电池供电的小型设备上部署时,通常以单一整体方式运行,无法充分利用现代SoC中的异构加速器(NPU、GPU等),导致延迟高、能效低。
- 方法核心:提出NANOMIND框架,核心是将LMM分解为独立的模块(如视觉编码器、语言解码器),并根据硬件特性(如NPU擅长低比特运算、GPU擅长并行浮点计算)将其动态调度到最合适的加速器上执行。同时,设计了专用硬件(基于RK3566 SoC)和配套的软件优化(如零拷贝的Token感知缓冲区管理器TABM、定制的低比特GEMM内核、电池感知调度策略)。
- 与已有方法相比新在哪里:突破了现有框架(如llama.cpp)将模型视为单一负载在单个加速器上运行的局限,实现了跨异构加速器的模块级动态卸载。此外,它针对统一内存(UMA)架构进行了系统级优化,避免了传统PC架构设计在移动设备上的低效问题。
- 主要实验结果:
- 与使用llama.cpp的框架相比,NANOMIND将能耗降低了42.3%,GPU内存使用减少了11.2%。
- 在一个2000mAh电池供电的原型设备上,低功耗模式下可运行近20.8小时。
- 在Orange Pi 5(RK3588)上运行Qwen2-1.5B-W8A8模型时,其定制GPU内核的吞吐量(tok/s)高于llama.cpp、MLC-LLM和PowerInfer-2。
- 运行Qwen2-VL-2B-Instruct模型,NANOMIND的端到端延迟比Orange Pi 5 Ultra使用官方rkllm降低了36.2%。 (实验结果图表见下文“实验结果”部分)
- 实际意义:为在严格资源受限的电池供电小型设备上部署隐私优先、低延迟的多模态AI助手提供了可行的软硬件协同设计方案,有助于推动边缘端AI的普及。
- 主要局限性:框架目前主要在定制的RK3566/RK3588硬件上实现和验证,在其他商用SoC(如高通、苹果)上的支持仍在开发或仅为部分支持。与最先进商用设备上的框架对比不够充分。开源情况不明,复现门槛较高。
🏗️ 模型架构
NANOMIND并非一个单一的神经网络模型,而是一个推理系统框架。其整体架构旨在将一个大型多模态模型(如LlaVA-OneVision-Qwen2-0.5B)分解并映射到异构硬件上高效执行。
整体输入输出流程与组件交互:
- 输入:图像(来自摄像头)和语音(来自麦克风)。
- 处理流程:
- 语音输入:通过Whisper模型(运行在CPU上)进行语音转文本。
- 图像输入:经过预处理(调整为固定分辨率)后,送入视觉编码器(SigLip ViT)。
- 视觉编码器:卸载到NPU上执行,输出图像嵌入向量。
- Token感知缓冲区管理器(TABM):作为核心协调器,管理共享内存中的环形缓冲区。NPU将生成的视觉嵌入直接写入缓冲区,GPU无需CPU介入即可读取作为LLM的输入,实现零拷贝传输。
- 语言解码器(LLM):卸载到GPU上执行,处理文本指令和视觉嵌入,生成文本回答。
- 语音输出:生成的文本通过Piper TTS模型(运行在CPU上)转换为语音输出。
- 输出:文本和/或语音回答。
主要组件详解:
- 模型分解:将LMM拆分为独立的模块:视觉编码器(ViT)、投影器、多模态嵌入层、语言模型基座。语音处理(Whisper, Piper)作为独立模块运行。
- 硬件调度:一个轻量级的CPU调度器,基于电池电量、内存使用情况和延迟需求,为每个层或模块做卸载决策。
- TABM:核心数据流管理组件。它跟踪缓冲槽状态(空闲、可写、可读、正读),通过轻量同步机制协调NPU(生产者)和GPU(消费者),消除数据拷贝,平滑生产者-消费者不匹配,维持高吞吐。
- 定制硬件:包括RK3566 SoC、并行LPDDR4x内存模块、专用电源管理单元(PMU)用于实时能耗监控,以及精简的Linux内核。
- 软件栈:包括针对RKNN NPU的驱动、基于OpenCL的GPU内核(融合了线性注意力和反量化GEMM操作)、电池感知的电源管理策略、以及“按需级联推理”流水线(在低电量时采用顺序执行,每个模块“加载-执行-释放”)。
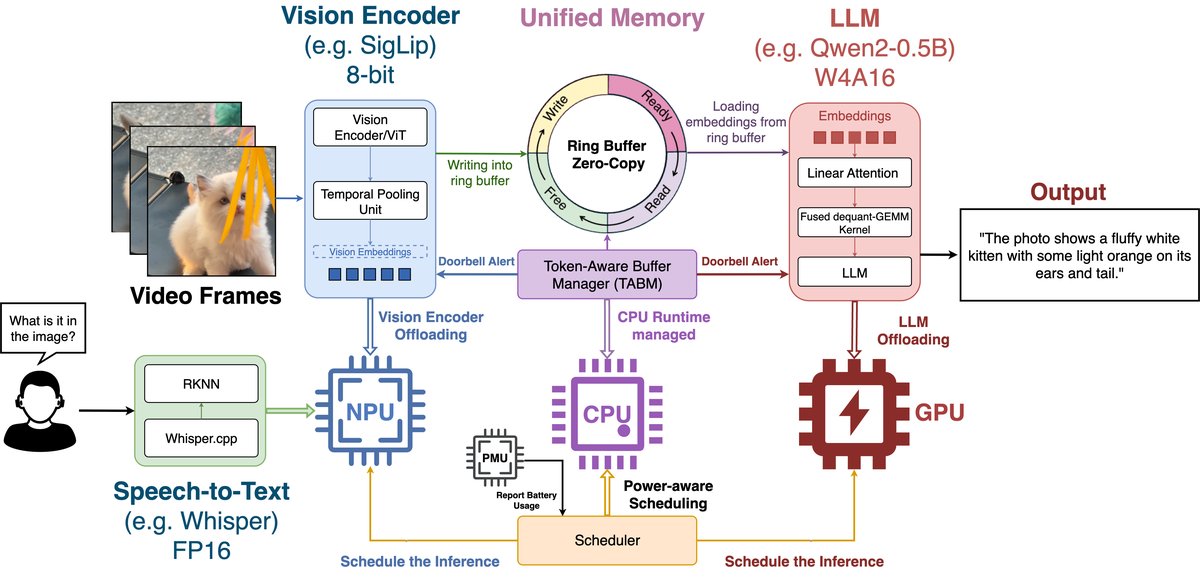 图1展示了核心思想:视觉编码器(ViT)运行在NPU上,语言解码器(LLM)运行在GPU上,它们通过TABM管理的共享内存(Ring Buffer)交换数据,避免了CPU参与的冗余内存拷贝。
图1展示了核心思想:视觉编码器(ViT)运行在NPU上,语言解码器(LLM)运行在GPU上,它们通过TABM管理的共享内存(Ring Buffer)交换数据,避免了CPU参与的冗余内存拷贝。
 图3是系统架构的完整视图。(a)部分展示了从硬件(SoC, PMU, 并行内存)、操作系统层(驱动、调度器)、计算内核到上层应用(级联推理流水线)的全栈设计。(b)部分展示了多模态推理的数据流:摄像头/麦克风输入 -> 语音/视觉编码器 -> LLM -> 语音/文本输出。
图3是系统架构的完整视图。(a)部分展示了从硬件(SoC, PMU, 并行内存)、操作系统层(驱动、调度器)、计算内核到上层应用(级联推理流水线)的全栈设计。(b)部分展示了多模态推理的数据流:摄像头/麦克风输入 -> 语音/视觉编码器 -> LLM -> 语音/文本输出。
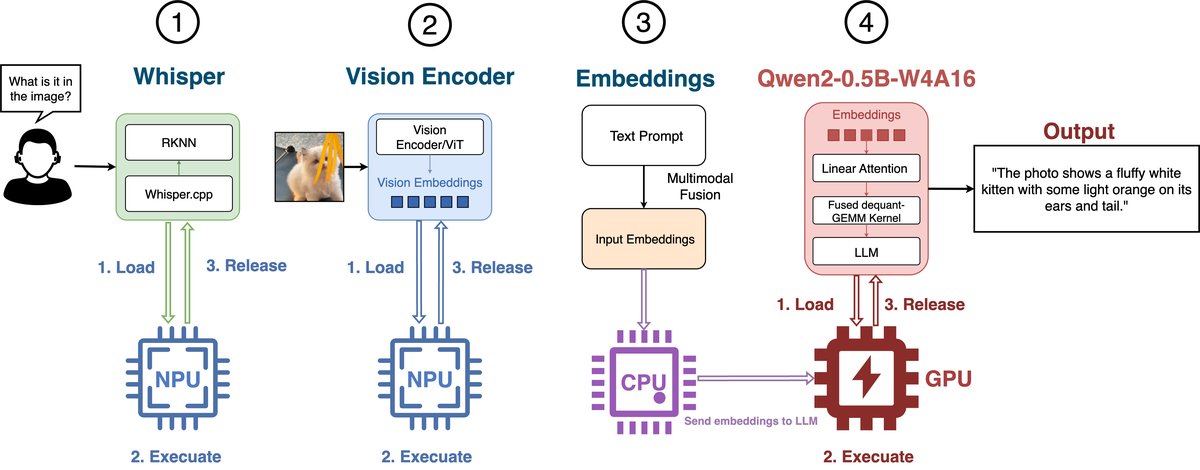 图2展示了低功耗模式下的推理流程:每个模块按顺序执行,完成后立即释放资源,仅将最小输出(如嵌入向量或文本)传递给下一阶段,形成轻量的“多米诺骨牌”式执行链。
图2展示了低功耗模式下的推理流程:每个模块按顺序执行,完成后立即释放资源,仅将最小输出(如嵌入向量或文本)传递给下一阶段,形成轻量的“多米诺骨牌”式执行链。
💡 核心创新点
跨加速器的模块级动态卸载调度:
- 之前局限:现有框架(如llama.cpp)通常将模型视为单一负载,要么全部运行在CPU,要么在CPU和GPU间按层分割,但数据传输仍由CPU管理,效率低下,且无法利用NPU。
- 如何起作用:NANOMIND将模型分解为功能模块,根据计算特性(如视觉编码适合NPU的低比特运算,LLM解码适合GPU的并行浮点)和硬件状态(电池、内存),动态决定将每个模块放置到最合适的加速器(CPU, GPU, NPU)上。
- 收益:提高了异构加速器的利用率,降低了端到端推理延迟。实验表明,视觉编码在NPU上远快于CPU和GPU。
面向统一内存(UMA)的零拷贝Token流管理:
- 之前局限:传统框架(如llama.cpp)为分离内存架构设计,数据需要在CPU和GPU内存间复制,增加了延迟和内存开销。在UMA架构下,这种复制是冗余的。
- 如何起作用:设计TABM和环形缓冲区。所有加速器共享同一物理DRAM。TABM直接管理共享内存中的缓冲槽,NPU写入后,GPU可以直接读取,无需CPU介入进行内存拷贝或管理。
- 收益:大幅减少了内存使用和CPU负载,平滑了模块间的数据流。实验证明,TABM相比传统的CPU拷贝方式,内存占用更低,CPU利用率显著下降。
紧密集成的软硬件协同设计:
- 之前局限:大多数量化和部署框架是纯软件方案,无法针对特定硬件(如移动GPU/NPU缺乏高效的低比特张量核)进行深度优化。
- 如何起作用:在硬件上,设计了包含PMU和并行内存的专用设备。在软件上,为GPU编写了融合了反量化操作的GEMM内核,并为NPU适配了静态形状的视觉模型。实现了电池感知的动态电源管理策略。
- 收益:在自定义硬件上实现了显著的能效提升。例如,定制内核的吞吐量在对比测试中表现最优,系统能在2000mAh电池下持续运行超过20小时。
🔬 细节详述
- 训练数据:论文未提及训练数据。这是一个推理框架,不涉及模型训练。
- 损失函数:论文未提及。同上。
- 训练策略:论文未提及。同上。
- 关键超参数:
- 模型:测试了LlaVA-OneVision-Qwen2-0.5B, Qwen2-VL-2B/1.5B, SmolVLM-500M等。
- 量化位宽:支持2-bit, 3-bit, 4-bit (GGUF/GPTQ), 8-bit, 1.58-bit (BitNet), FP16。
- 视觉编码器输入分辨率:384x384(Llava-OneVision)或448x736(Qwen2-VL)。
- 电源管理阈值:定义了
Thigh和Tlow两个电量阈值,用于切换三种功耗模式,具体数值未说明。
- 训练硬件:不适用。
- 推理细节:
- 解码策略:论文未明确提及解码策略(如贪心、采样)。根据性能指标(吞吐量、延迟),推测可能使用了标准自回��解码。
- 流式设置:实现了“按需级联推理”流水线,支持事件触发的顺序执行。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
主要基准与结果: 论文在多个数据集(InfoVQA, DocVQA, MMBench, MME)上评估了模型精度,在自定义硬件上测量了资源使用和功耗。
内存使用对比(图5):
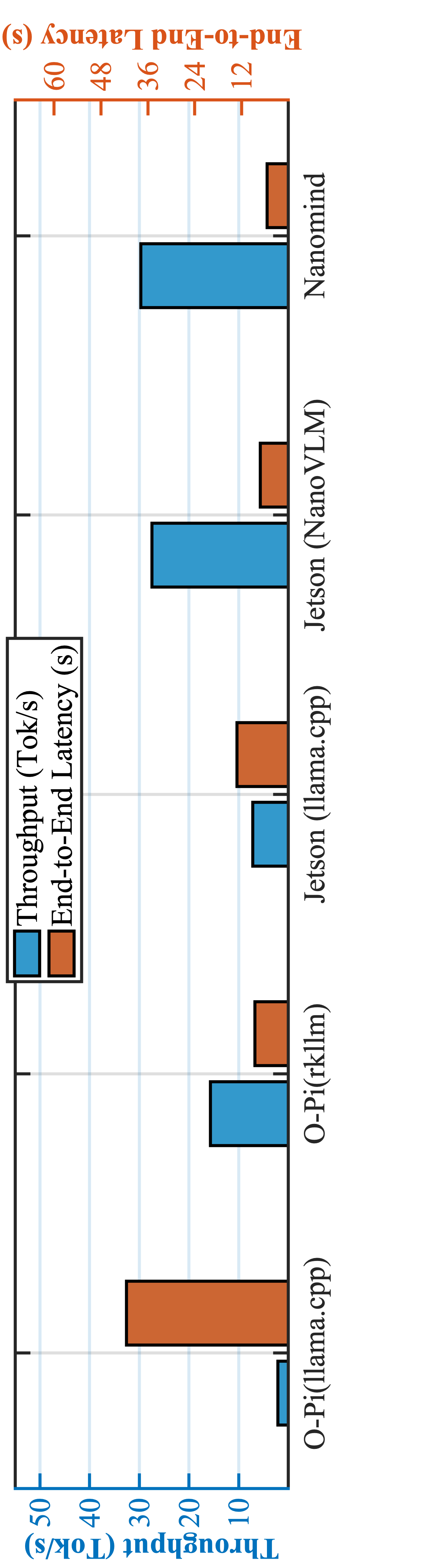 图5比较了Llava-onevision-0.5B, Qwen2-VL-2B, SmolVLM-500M在不同平台(NANOMIND, Orange Pi, Jetson Nano/AGX)和框架(llama.cpp, NanoVLM, NANOMIND自有实现)下的内存使用。关键结论:NANOMIND(自有实现)在多数情况下内存占用低于或接近其他高效框架(如NanoVLM),显著低于使用llama.cpp的方案。
图5比较了Llava-onevision-0.5B, Qwen2-VL-2B, SmolVLM-500M在不同平台(NANOMIND, Orange Pi, Jetson Nano/AGX)和框架(llama.cpp, NanoVLM, NANOMIND自有实现)下的内存使用。关键结论:NANOMIND(自有实现)在多数情况下内存占用低于或接近其他高效框架(如NanoVLM),显著低于使用llama.cpp的方案。吞吐量与延迟对比(图6):
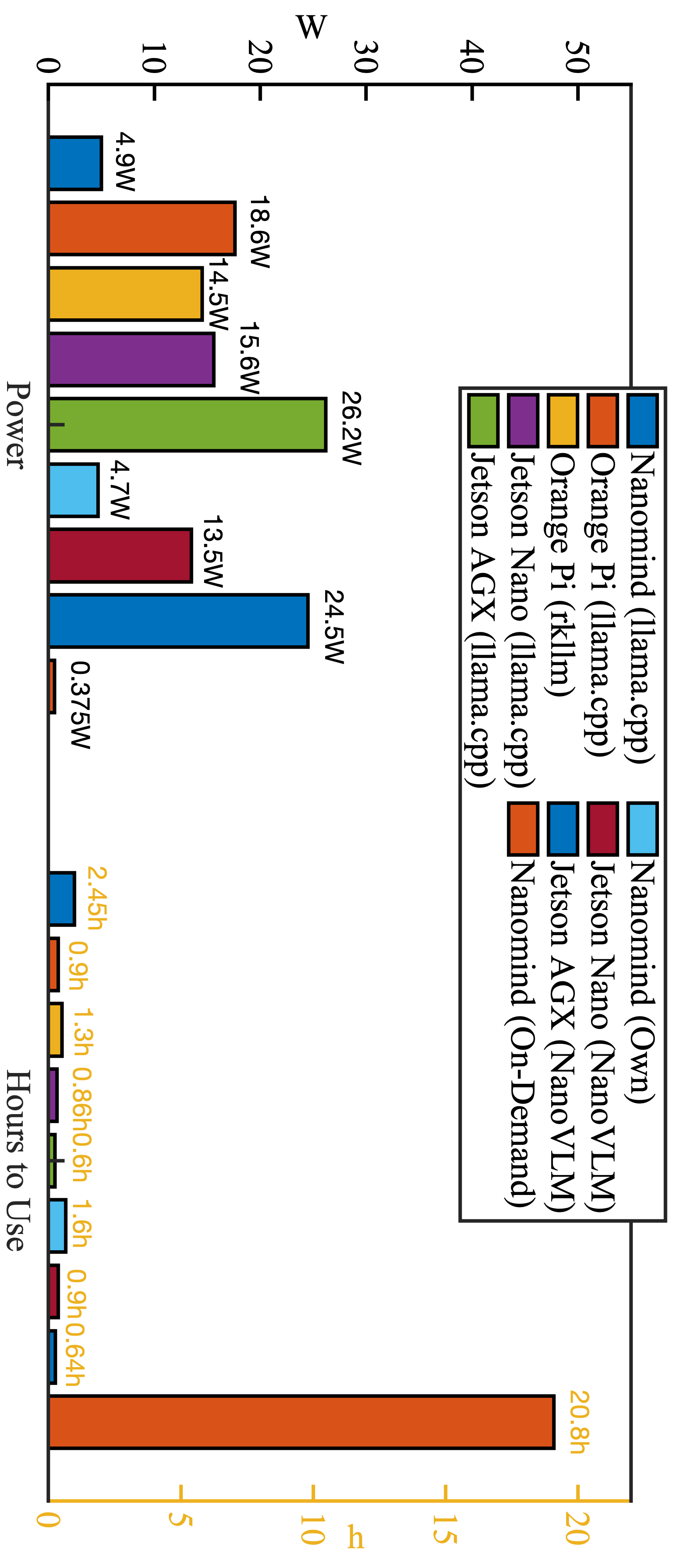 图6展示了在InfoVQA数据集上运行Qwen2-VL-2B(4-bit)的性能。关键结论:尽管硬件性能弱于Orange Pi 5 Ultra和Jetson Nano,NANOMIND实现了与Jetson Nano(CUDA, NanoVLM)相当的吞吐量(约35.7 tok/s),且端到端延迟比Orange Pi 5 Ultra(官方rkllm)降低了36.2%。
图6展示了在InfoVQA数据集上运行Qwen2-VL-2B(4-bit)的性能。关键结论:尽管硬件性能弱于Orange Pi 5 Ultra和Jetson Nano,NANOMIND实现了与Jetson Nano(CUDA, NanoVLM)相当的吞吐量(约35.7 tok/s),且端到端延迟比Orange Pi 5 Ultra(官方rkllm)降低了36.2%。系统组件分解性能(图7):
 图7包含三个子图:(a) TABM与传统CPU拷贝方式的内存和CPU使用对比,显示TABM显著降低了CPU利用率。(b) 视觉嵌入模型(SigLip, ArcFace)在NPU、CPU、GPU上的单图像编码延迟,显示NPU具有明显优势。(c) 不同框架(NANOMIND内核, llama.cpp, MLC-LLM, PowerInfer-2)在RK3588和QCS6490上运行Qwen2-1.5B-W8A8的GPU解码吞吐量,显示NANOMIND内核表现最佳。
图7包含三个子图:(a) TABM与传统CPU拷贝方式的内存和CPU使用对比,显示TABM显著降低了CPU利用率。(b) 视觉嵌入模型(SigLip, ArcFace)在NPU、CPU、GPU上的单图像编码延迟,显示NPU具有明显优势。(c) 不同框架(NANOMIND内核, llama.cpp, MLC-LLM, PowerInfer-2)在RK3588和QCS6490上运行Qwen2-1.5B-W8A8的GPU解码吞吐量,显示NANOMIND内核表现最佳。功耗与续航(图8,图9):
 图8展示了系统如何根据电池电量(B)动态调整工作模式,在延迟和功耗间进行权衡。
图8展示了系统如何根据电池电量(B)动态调整工作模式,在延迟和功耗间进行权衡。
 图9显示了在低功耗模式下,平均功耗为0.375W。使用标准2000mAh电池,估算续航时间可达20.8小时。
图9显示了在低功耗模式下,平均功耗为0.375W。使用标准2000mAh电池,估算续航时间可达20.8小时。
与最强基线对比:
- 在Orange Pi 5(RK3588)的纯GPU解码测试中,NANOMIND的定制内核吞吐量(tok/s)高于llama.cpp、MLC-LLM和PowerInfer-2。
- 在端到端多模态推理中,NANOMIND在自定义硬件上的延迟优于使用官方rkllm的Orange Pi 5 Ultra。
- 论文未提供与当前最先进旗舰手机(如三星S24、小米14)上部署的框架(如Google AI Edge, MLC LLM)的直接对比。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文提出了一个清晰、完整的系统级问题(边缘设备多模态推理效率低),并给出了一个合理的软硬件协同解决方案。技术路径明确,实验设计围绕其系统目标(资源效率、能效)展开,并提供了详细的组件级分解实验,数据可信。扣分点在于:对比实验的范围有限,主要与基于相同SoC或开源框架对比,未能在更广泛的商用硬件生态中证明其优越性;部分关键系统设计细节(如调度算法具体策略、内存一致性管理)描述不够深入。
- 选题价值:1.5/2 - 边缘AI、隐私计算、高效推理是当前的重要前沿方向。该工作直接针对电池供电的便携设备,应用场景明确(智能头戴设备、离线助手),具有实际应用价值和市场潜力。与音频/语音读者的相关性在于,其框架集成了语音处理,并展示了在资源受限设备上实现完整语音交互的可能性。
- 开源与复现加成:0.0/1 - 论文未提供代码仓库、模型权重或详细的复现指南。它提到了依赖的开源项目(llama.cpp, Whisper.cpp, Piper),但NANOMIND本身的实现细节(特别是定制内核和调度器)未开源,复现门槛极高。