📄 TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
#音频生成 #流匹配 #扩散模型 #模型评估 #开源工具
🔥 8.5/10 | 前25% | #音频生成 | #流匹配 | #扩散模型 #模型评估
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Chia-Yu Hung(南洋理工大学)
- 通讯作者:未说明(论文未明确指定通讯作者)
- 作者列表:Chia-Yu Hung(南洋理工大学), Navonil Majumder(南洋理工大学), Zhifeng Kong(NVIDIA), Ambuj Mehrish(威尼斯卡福斯卡里大学), Amir Ali Bagherzadeh(Lambda Labs), Chuan Li(Lambda Labs), Rafael Valle(NVIDIA), Bryan Catanzaro(NVIDIA), Soujanya Poria(南洋理工大学)
💡 毒舌点评
亮点:在音频生成这个“缺乏裁判”(无标准答案和可靠奖励模型)的赛道上,CRPO方法巧妙地利用CLAP打分实现了“自我训练、自我提升”的闭环,效果显著且思路优雅。短板:其声称的“超快”优势,很大程度上依赖于50步推理和44.1kHz采样率的设定,与一些专为极低延迟设计的模型(如ConsistencyTTA)的定位不同,其“最快”的宣称存在语境限定。
🔗 开源详情
- 代码:论文明确承诺将公开代码(“We will release the code and model weights”),但未提供具体仓库链接。论文中未提及代码链接。
- 模型权重:承诺公开模型权重,未提及具体链接。未提及。
- 数据集:训练使用WavCaps、AudioCaps等公开数据集。CRPO使用的提示池为AudioCaps训练集。未提供专属新数据集链接。
- Demo:提供了模型生成音频样本的在线对比页面:https://tangoflux.github.io/。
- 复现材料:论文附录(A.5节等)提供了完整的训练超参数、硬件配置(预训练阶段)、数据处理细节、评估指标定义、人工评估指南和所有实验设置,复现信息非常充分。
- 论文中引用的开源项目:引用了多个开源模型和工具,包括:Stable Audio Open的VAE、CLAP模型(用于奖励评估)、FLAN-T5文本编码器、FLUX图像生成模型(作为架构灵感)、stable-audio-metrics评估工具、AudioLDM评估工具包、kadtk评估工具等。
📌 核心摘要
解决的问题:文本到音频(TTA)生成模型的对齐难题,即如何让生成的音频内容忠实于复杂的文本提示,且缺乏类似LLM对齐中现成的奖励模型和验证机制。
方法核心:提出CLAP-Ranked Preference Optimization (CRPO)。该框架在训练过程中迭代地执行:生成音频、利用CLAP模型对生成的多个音频进行排序以构建偏好数据(赢家-输家对)、使用改进的损失函数(LCRPO = LDPO-FM + LFM)进行偏好优化。
创新点:与静态偏好数据集(如BATON、Audio-Alpaca)不同,CRPO能动态生成并优化偏好数据,实现模型的持续自我改进。损失函数通过添加流匹配损失(LFM)作为正则化,缓解了直接偏好优化(DPO)可能引起的过优化问题。
实验结果:TangoFlux(515M参数)在AudioCaps基准测试上取得SOTA性能。例如,其CLAPscore达到0.480,FDopenl3达到75.1,均优于Tango 2(0.447, 108.4)等强基线。在人工评估中,其在整体质量(OVL)和文本相关性(REL)上的z-score和Elo评分也均为最高。具体对比见下表:
模型 参数量 推理步骤 FDopenl3 ↓ KLpasst ↓ CLAPscore ↑ IS ↑ Tango 2 866M 200 108.4 1.11 0.447 9.0 GenAU-Full-L 1.25B 100 93.2 1.37 0.447 12.0 TangoFlux-base 516M 50 80.2 1.22 0.431 11.7 TangoFlux 516M 50 75.1 1.15 0.480 12.2 实际意义:提供了一个高效、高质量且完全基于开源数据训练的TTA模型,降低了生成长音频(最长30秒)的算力门槛,为创意内容生成、音效设计等应用提供了实用工具。
主要局限性:CRPO的迭代过程增加了训练复杂度和计算成本。CLAP作为代理奖励模型可能引入偏差。此外,模型的“快速”优势与特定推理设置强相关,在极低延迟场景下可能并非最优选择。
🏗️ 模型架构
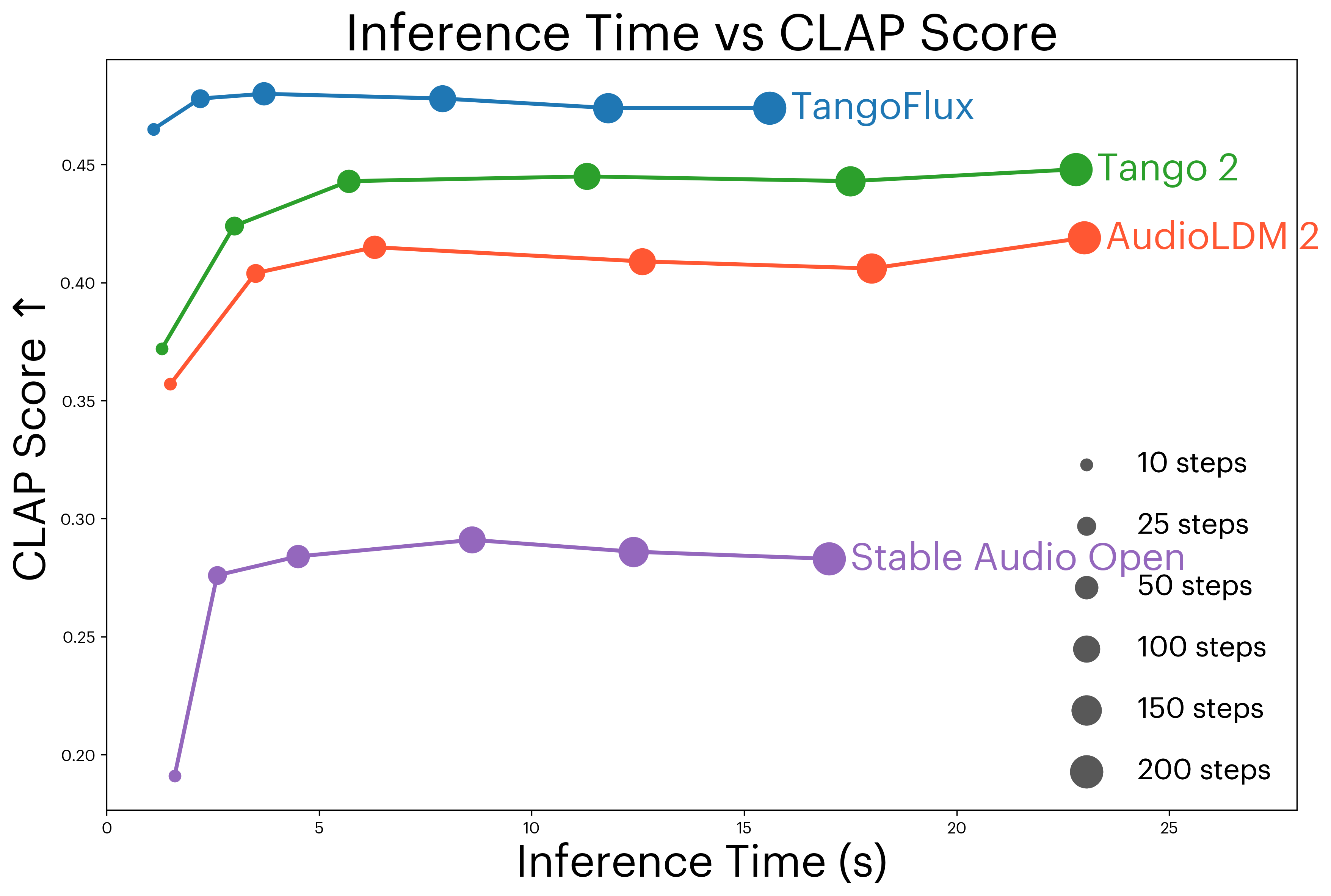 图1展示了TangoFlux的整体训练流程,主要包含预训练和在线迭代对齐(CRPO)两个阶段。
图1展示了TangoFlux的整体训练流程,主要包含预训练和在线迭代对齐(CRPO)两个阶段。
- 音频编码:使用预训练的变分自编码器(VAE)将44.1kHz立体声音频编码为潜在表示Z。VAE在整个训练过程中保持冻结。
- 条件注入:
- 文本条件:使用FLAN-T5文本编码器将输入文本描述编码为
ctext。 - 时长条件:使用一个小型神经网络将目标音频时长(最长30秒)编码为
cdur,与文本编码拼接后输入模型。模型始终在固定的30秒潜在空间上操作,时长条件控制实际音频内容占据的空间。
- 文本条件:使用FLAN-T5文本编码器将输入文本描述编码为
- 模型主体:基于Flux架构,采用混合MMDiT(多模态扩散Transformer)和DiT(扩散Transformer)结构。具体由6个MMDiT块和18个DiT块组成,每个块有8个注意力头,宽度1024,总参数量515M。MMDiT块用于同时处理文本和音频条件,DiT块则专注于音频建模。
- 生成目标:采用流匹配(Rectified Flow)框架。模型学习一个向量场
u(xt, t; θ),将随机噪声x0沿直线路径引导至目标音频潜在表示x1。推理时,使用欧拉求解器从噪声开始,经过50步迭代生成音频。 - 训练流程:如图1所示,首先在WavCaps等数据集上预训练TangoFlux-base。然后,CRPO迭代执行:(1) 使用当前模型πk对一批提示生成N个音频;(2) 利用CLAP模型对生成的音频进行评分排序,为每个提示构建一个赢家(最高分)-输家(最低分)对;(3) 使用包含DPO和流匹配项的LCRPO损失函数,将模型πk优化为πk+1。
💡 核心创新点
- CLAP-Ranked Preference Optimization (CRPO) 框架:针对音频领域缺乏标准奖励和验证答案的挑战,提出了一个动态生成偏好数据并迭代优化的自举式框架。这是将LLM对齐中的“在线/迭代”理念成功迁移到非自回归生成模型上的重要尝试。
- 动态偏好数据构建:与使用静态数据集(如BATON、Audio-Alpaca)进行对齐不同,CRPO在每个训练迭代开始时,利用当前模型生成新的合成数据并构建偏好对。实验表明,这种动态数据能持续提升模型性能,避免了静态数据带来的过拟合和性能饱和。
- 改进的偏好优化损失函数(LCRPO):在DPO-Diffusion损失(LDPO-FM)基础上,增加了在赢家音频上的流匹配损失(LFM)作为正则化项。这缓解了DPO优化中可能出现的“赢家和输家损失同时增加”的悖论现象,稳定了训练过程,防止模型为了扩大赢输差距而严重偏离高质量数据的分布。
- 高效流匹配架构:采用轻量级的混合MMDiT/DiT架构(515M参数),结合Rectified Flow的直线路径特性,实现了在较少的推理步骤(50步)内生成高采样率(44.1kHz)、长时长(30秒)音频,显著提升了推理效率(A40 GPU上3.7秒)。
🔬 细节详述
- 训练数据:
- 预训练/微调数据:约40万条来自WavCaps的音频和4.5万条来自AudioCaps训练集的音频。音频统一处理为30秒(短的填充静音,长的中心裁剪),单声道转换为伪立体声。
- CRPO数据集:使用AudioCaps训练集的4.5万个提示作为提示池。每次CRPO迭代从中随机采样2万个提示,每个提示生成5个音频。
- 评估数据集:使用AudioCaps测试集的886个样本进行客观评估。人工评估使用50个由GPT-4生成的、包含多个复杂事件的分布外提示。
- 损失函数:
- 流匹配损失 (LFM):L_FM = E_{x1, x0, t} ||u(xt, t; θ) - vt||^2,用于预训练和微调。
- DPO流匹配损失 (LDPO-FM):基于赢/输音频对,最大化赢家被模型分配的概率相对于参考模型的提升,同时最小化输家的提升。具体为公式(2)。
- CRPO损失 (LCRPO):L_CRPO = L_DPO-FM + L_FM。添加赢家音频上的LFM作为正则化。
- 训练策略:
- 预训练:在WavCaps上训练80 epochs。优化器AdamW(β1=0.9, β2=0.95),最大学习率5e-4,线性学习率预热2000步。使用5块A40 GPU,总batch size 80。
- 微调(TangoFlux-base):在AudioCaps训练集上微调65 epochs。优化器同上,最大学习率10^-5,batch size 48,线性预热100步。
- CRPO对齐:进行5次迭代。每次迭代训练8个epochs,使用最后一个epoch的检查点生成下一轮的偏好数据。优化器同微调阶段,学习率10^-5。
- 关键超参数:模型参数量515M;Transformer块结构(6 MMDiT + 18 DiT);隐藏维度1024;注意力头数8;音频采样率44.1kHz;最大生成时长30秒;推理步数50;分类器自由引导(CFG)尺度默认为4.5(消融实验表明3.5-4.5范围表现良好)。
- 训练硬件:未在主要实验部分说明CRPO迭代的具体GPU型号和数量,但预训练提到了5块A40 GPU。
- 推理细节:使用欧拉求解器(Euler Solver)进行50步积分。采样噪声后逐步去噪。CFG用于提升生成质量。
- 正则化技巧:1) 在LCRPO损失中添加LFM项作为正则化,防止过优化。2) 训练时从logit-normal分布(均值0,方差1)中采样时间步
t,侧重中间时间步,已被证明能提升效果。
📊 实验结果
主要对比实验(表1):在AudioCaps测试集上,TangoFlux在大部分客观指标上优于基线。例如,在FDopenl3(75.1)和CLAPscore(0.480)上显著优于Tango 2(108.4, 0.447)和Stable Audio Open(89.2, 0.291)。推理速度(3.7秒)也远快于大多数扩散模型。
| 模型 | 参数量 | 推理步数 | FDopenl3 ↓ | KLpasst ↓ | CLAPscore ↑ | 推理时间(s) |
|---|---|---|---|---|---|---|
| AudioLDM 2-large | 712M | 200 | 108.3 | 1.81 | 0.419 | 24.8 |
| Tango 2 | 866M | 200 | 108.4 | 1.11 | 0.447 | 22.8 |
| GenAU-Full-L | 1.25B | 100 | 93.2 | 1.37 | 0.447 | 5.3 |
| TangoFlux | 516M | 50 | 75.1 | 1.15 | 0.480 | 3.7 |
人工评估结果(表2):在50个复杂分布外提示上,TangoFlux在整体质量(OVL)和文本相关性(REL)上均获得最高z-score、最佳排名和最高Elo分数,表明其生成质量高且对齐准确。
CRPO vs 静态数据集(表3):使用CRPO动态生成的数据进行一次迭代优化(TangoFlux-crpo-1)后,模型在所有指标上均优于使用Audio-Alpaca或BATON静态数据集优化的版本,证明了动态数据的优势。
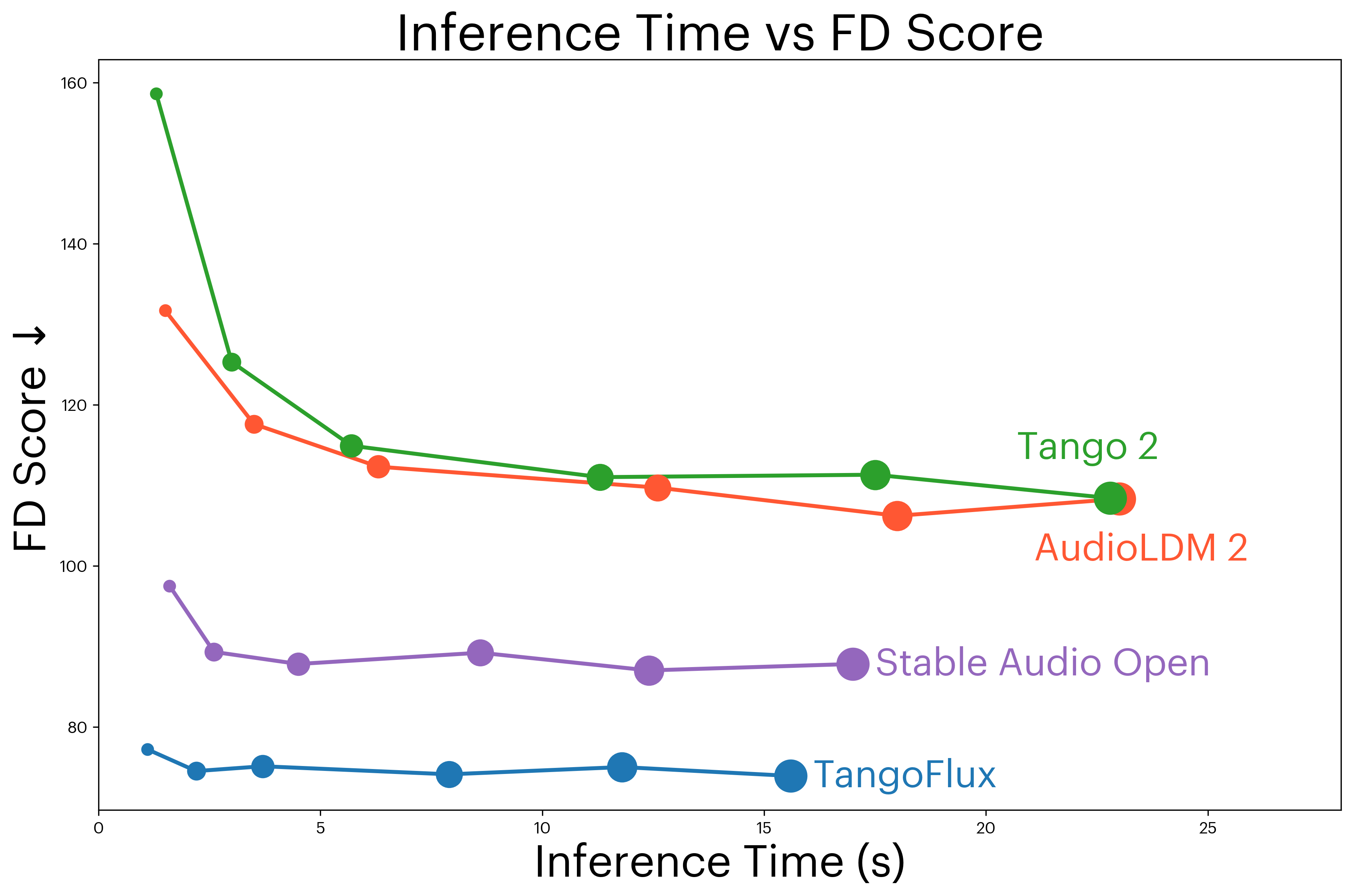 图2显示,在CRPO的多次迭代中,在线(每迭代生成新数据)训练使CLAPscore持续上升,KLpasst持续下降,性能稳步提升。而离线(重复使用同一数据集)训练在第二次迭代后性能即饱和并恶化,证实了动态数据生成的重要性。
图2显示,在CRPO的多次迭代中,在线(每迭代生成新数据)训练使CLAPscore持续上升,KLpasst持续下降,性能稳步提升。而离线(重复使用同一数据集)训练在第二次迭代后性能即饱和并恶化,证实了动态数据生成的重要性。
损失函数分析(图3, 图4):
 图3显示,LCRPO(本文方法)在CLAPscore上优于LDPO-FM,同时在KLpasst和FDopenl3上保持稳定或略优。
图4(未提供URL)显示,两种损失函数下的赢/输损失均随迭代增加,但LCRPO的赢输损失增长更平缓、稳定,证明了添加LFM项的正则化效果,避免了LDPO-FM在后期迭代可能出现的过优化。
图3显示,LCRPO(本文方法)在CLAPscore上优于LDPO-FM,同时在KLpasst和FDopenl3上保持稳定或略优。
图4(未提供URL)显示,两种损失函数下的赢/输损失均随迭代增加,但LCRPO的赢输损失增长更平缓、稳定,证明了添加LFM项的正则化效果,避免了LDPO-FM在后期迭代可能出现的过优化。
推理时间 vs 性能(图6):在不同推理步数下,TangoFlux均能以更短时间达到更高的CLAPscore和更低的FDopenl3,证明了其优越的效率-质量权衡。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了针对音频对齐难题的有效解决方案(CRPO),技术路线清晰,实验非常充分(包括大量对比、消融、损失分析、人工评估)。创新性在于将LLM迭代对齐思想成功应用于流匹配音频模型,并改进了损失函数。证据可信度高。扣分项:CLAP作为奖励模型的潜在偏差未深入讨论;部分消融实验(如GRPO)的对比结果仅略逊于CRPO,优势未完全凸显。
- 选题价值:1.5/2:文本到音频生成是热门且应用价值高的任务。TangoFlux聚焦于“高效”和“忠实”,并承诺完全开源,具有很强的实际吸引力。但其核心生成框架(流匹配)和对齐思想(DPO变体)并非该论文首次提出,更多是有效的领域应用和优化。
- 开源与复现加成:0.5/1:论文明确承诺将公开代码、模型权重和训练细节,附录提供了详尽的超参数和实验设置,复现指引清晰。扣分项在于,承诺的开源��源在论文发表时尚未实际提供,读者无法立即验证和复现。