📄 SyncTrack: Rhythmic Stability and Synchronization in Multi-Track Music Generation
#音乐生成 #音频生成 #扩散模型 #模型评估
✅ 7.5/10 | 前25% | #音乐生成 | #扩散模型 | #音频生成 #模型评估
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hongrui Wang (香港科技大学数学系)
- 通讯作者:Can Yang (香港科技大学数学系/神经系统疾病国家重点实验室), Yang Wang (香港大学)
- 作者列表:
- Hongrui Wang (香港科技大学数学系,*共同第一作者)
- Fan Zhang (香港科技大学数学系,*共同第一作者,†共同通讯)
- Zhiyuan Yu (浙江大学CAD&CG国家重点实验室)
- Ziya Zhou (香港科技大学交叉学科学院)
- Xi Chen (香港科技大学交叉学科学院)
- Can Yang (香港科技大学数学系/神经系统疾病国家重点实验室,†共同通讯)
- Yang Wang (香港大学,†共同通讯)
💡 毒舌点评
亮点:论文精准击中了多轨音乐生成中“节奏打架”这一要害,并给出了“分而治之”的优雅解法(共享模块管节奏,特定模块管音色),提出的三个节奏评估指标(IRS, CBS, CBD)直击FAD指标的软肋,非常实用。 短板:模型架构虽然有效,但创新性主要体现在针对性设计上,基础框架(U-Net, LDM)仍属借用,未在生成模型理论上实现根本性突破。此外,实验主要在Slakh2100这个相对干净的数据集上进行,对于更复杂、更自由的音乐风格,模型的表现有待进一步验证。
🔗 开源详情
- 代码:论文提供了项目主页和代码仓库链接:
https://synctrack-v1.github.io。 - 模型权重:论文中未明确提及是否公开预训练模型权重。项目主页可能包含更多信息,但论文正文未说明。
- 数据集:实验使用Slakh2100数据集,这是一个公开数据集。论文未提及是否提供或修改后的数据集。
- Demo:论文未提及在线演示。
- 复现材料:提供了极其详尽的复现材料。包括:
- 训练细节:附录A.5给出了完整的训练配置(数据集、采样率、片段长度、优化器、学习率、批大小、训练迭代次数/轮数、硬件环境)。
- 模型架构:附录表A3列出了SyncTrack完整的网络架构层次和参数量。
- 评估细节:附录A.1和A.2详细说明了节拍跟踪工具(madmom)的使用、关键超参数(fps, tl)及其敏感性分析。
- 消融研究:表6提供了详细的消融实验结果。
- 复现性声明:明确表示提供了全部实验细节。
- 论文中引用的开源项目:
- 核心框架:潜在扩散模型(LDM)(Rombach et al., 2022)。
- 音频处理/声码器:HiFi-GAN (Kong et al., 2020a)。
- 预训练模型:使用了MusicLDM (Chen et al., 2024)的预训练权重进行初始化。
- 评估工具:使用了madmom库 (Böck et al., 2016) 进行节拍检测;使用VGGish计算FAD。
- 数据集:Slakh2100 (Manilow et al., 2019)。
📌 核心摘要
- 问题:现有的多轨音乐生成模型(如MSDM, MSG-LD)通常学习多轨道的联合分布,但过度关注轨道间的差异性,忽略了多轨音乐中至关重要的共同节奏信息,导致生成的音乐在节拍稳定性和跨轨道同步性上表现不佳。
- 方法核心:提出SyncTrack模型,其架构创新地分为“轨道共享模块”和“轨道特定模块”。轨道共享模块包含全局跨轨道注意力和时间特定跨轨道注意力两种子模块,用于建立和同步所有轨道的共同节奏。轨道特定模块为每个轨道引入可学习的乐器先验,以更好地表征其独特的音色和特征。
- 与已有方法相比新在哪里:a) 架构设计上明确解耦了节奏(共享)和音色(特定)信息的建模,而先前方法是统一学习联合分布;b) 设计了两种互补的跨轨道注意力机制,分别针对全局节奏稳定和细粒度的时间点同步;c) 首次针对多轨音乐生成提出了三个可量化的节奏一致性评估指标(IRS, CBS, CBD),弥补了仅用FAD评估的不足。
- 主要实验结果:在Slakh2100数据集上的实验显示,SyncTrack在多项指标上显著优于基线。客观结果:混合音频FAD得分相比最强基线MSG-LD降低约45.8%(从1.31降至1.26);单轨道FAD在鼓和钢琴轨道上分别降低约27.6%和45.6%。节奏指标:SyncTrack的IRS(节奏稳定性)接近真实数据,显著优于基线;CBS(节拍同步率)达到0.5206,比MSG-LD高34.8%;CBD(节拍离散度)显著降低。主观评估:SyncTrack的平均得分为3.42(5分制),远高于MSG-LD的1.57,更接近真实数据的4.48。
- 实际意义:该模型能生成更和谐、更符合听觉习惯的多轨音乐,直接服务于专业音乐制作、混音和编曲等下游任务。提出的评估指标为社区提供了更精细的衡量标准。
- 主要局限性:模型训练和评估主要基于Slakh2100数据集,其音乐风格和乐器种类有限;论文未明确讨论对更长时序(如完整歌曲)生成的支持;虽然提供了评估指标和代码,但并未公开大规模预训练模型权重和训练数据集。
🏗️ 模型架构
SyncTrack整体是一个基于潜在扩散模型(LDM)的多轨音频生成框架,其核心创新在于用于去噪的U-Net网络内部模块设计。
整体输入输出流程:
- 训练流程:S个轨道的原始音频波形 → 经STFT和梅尔滤波器组转换为梅尔频谱图 → 经过预训练的VAE编码器压缩为潜在表示
{z_s}→ 加入不同等级的高斯噪声{z_s^l}→ SyncTrack模型ϵ_θ预测加入的噪声ϵ→ 优化损失函数L(θ)(公式2)。 - 推理流程:从纯噪声开始,经SyncTrack模型迭代去噪,得到生成的潜在表示
ẑ_s→ 经过VAE解码器和HiFi-GAN声码器还原为各轨道的音频波形x̂_s(公式3)。
SyncTrack模型内部结构: SyncTrack是一个类U-Net的编解码结构,其输入块、中间块和输出块由两类模块交替堆叠构成:
 图2:SyncTrack整体流程图。a. 训练与采样流程;b. SyncTrack由输入块、中间块和输出块组成,包含轨道特定模块和轨道共享模块。
图2:SyncTrack整体流程图。a. 训练与采样流程;b. SyncTrack由输入块、中间块和输出块组成,包含轨道特定模块和轨道共享模块。
- 轨道共享模块 (Track-shared Module) 功能:处理所有轨道共有的节奏和和声信息。 内部结构(如图3a所示):
- 包含一个ResBlock用于特征变换。
- 内轨道注意力 (Inner-track attention):沿用标准2D U-Net注意力,仅在单个轨道内计算,捕捉轨道内部的时频依赖关系(如单个乐器的旋律走向)。
- 全局跨轨道注意力 (Global cross-track attention) (图3c-i):对于每个轨道在特定时间点
t和频率点f的表示z_s^{t,f},将其作为Query,而所有轨道在全部时间1:T和频率1:F维度上的表示z_{1:S}^{1:T,1:F}作为Key和Value进行注意力计算(公式4)。动机:让每个轨道都能“看到”所有轨道在整个时间段上的全局信息,从而学习和保持一致的整体节拍框架(全局稳定性)。 - 时间特定跨轨道注意力 (Time-specific cross-track attention) (图3c-ii):对于每个轨道在特定时间点
t的表示z_s^{t,f},将其作为Query,而所有轨道在同一时间点t、全部频率1:F维度上的表示z_{1:S}^{t,1:F}作为Key和Value进行注意力计算(公式5)。动机:强制不同轨道在完全相同的时间位置上对齐其音乐事件(如和弦起振),实现精细的瞬时同步。
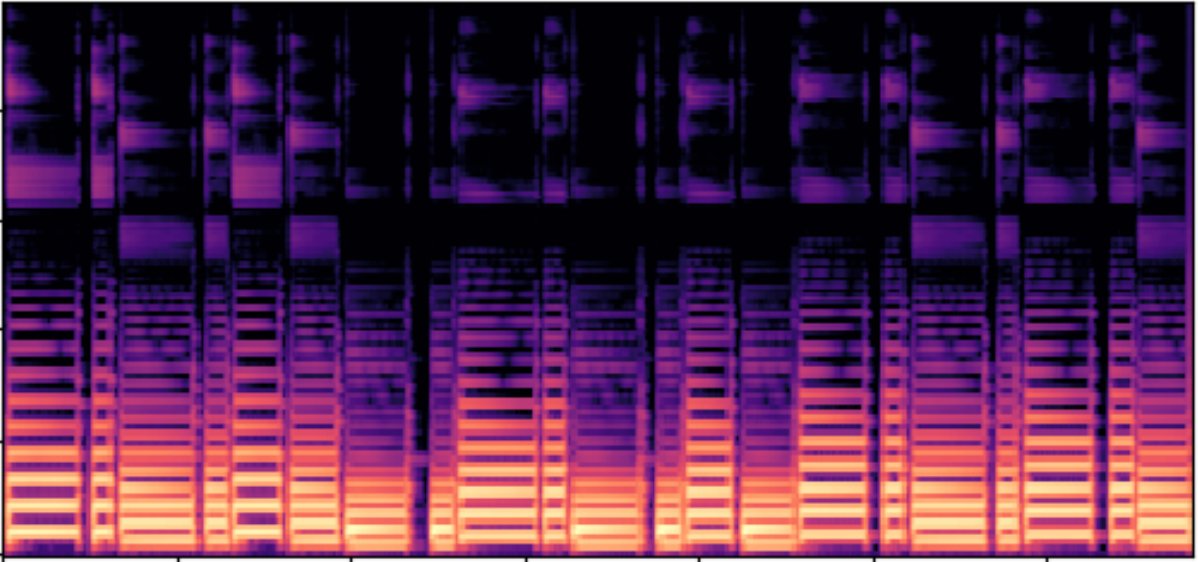 图3:模块示意图。(a) 轨道共享模块,包含ResBlock、内轨道注意力、全局和时间特定跨轨道注意力。(b) 轨道特定模块,包含可学习乐器先验。(c) 两种跨轨道注意力子模块的可视化。
图3:模块示意图。(a) 轨道共享模块,包含ResBlock、内轨道注意力、全局和时间特定跨轨道注意力。(b) 轨道特定模块,包含可学习乐器先验。(c) 两种跨轨道注意力子模块的可视化。
- 轨道特定模块 (Track-specific Module) 功能:处理每个轨道独有的音色、音域等特征。 内部结构(如图3b所示):
- 设计一个可学习乐器先验 (Learnable instrument prior)。具体做法:用独热向量
V表示不同轨道 → 经过位置编码和两层神经网络变换为嵌入 → 与时间步嵌入n相加 → 最终加到第一个ResBlock的输出上。 - 再经过第二个ResBlock得到该轨道特定的表示。 动机:通过显式注入轨道标识信息,鼓励模型为每个轨道学习独立的音色表示,而非混淆在一起。
关键设计选择及其动机:论文明确指出,多轨音乐中“节奏是共享的,音色是独立的”。因此,架构上将共享信息(节奏)和特定信息(音色)的处理解耦。全局注意力管宏观节拍一致性,时间特定注意力管微观事件对齐,乐器先验管音色分化。这种结构被设计为可嵌入到其他潜在音频扩散系统中。
💡 核心创新点
- 针对多轨音乐本质特性的解耦架构:提出“轨道共享模块”+“轨道特定模块”的统一框架,显式区分并分别建模多轨音乐中的共同节奏信息与个体音色信息,解决了先前方法(将多轨视为多变量时间序列)忽略共享节奏结构的根本缺陷。
- 双层次跨轨道注意力机制:设计了“全局跨轨道注意力”和“时间特定跨轨道注意力”。前者通过引用所有轨道全局信息来维持整体节奏稳定;后者通过强制同一时间点不同轨道的交互来实现精细的瞬时同步。二者互补,从宏观到微观全面增强节奏一致性。
- 引入可学习的乐器先验:在轨道特定模块中,通过嵌入轨道标识向量,为每个轨道提供了明确的“身份”信号,引导模型更好地学习和保持各轨道独特的音色特征,避免音色混淆。
- 提出多轨音乐节奏一致性评估指标:针对FAD无法评估节奏质量的局限,提出IRS(单轨道节奏稳定性)、CBS(跨轨道节拍同步率)和CBD(跨轨道节拍离散度)三个可解释、可量化的客观指标,为评估和改进多轨音乐生成提供了新的工具箱。
🔬 细节详述
- 训练数据:使用Slakh2100数据集,遵循Mariani等人的公共子集,包含Bass, Drums, Guitar, Piano四轨。所有音频重采样至16kHz,分割为10.24秒片段。预处理转换为梅尔频谱图(窗口大小1024,跳数160)。
- 损失函数:标准的扩散模型噪声预测损失
L(θ) = E[||ϵ - ϵ_θ(z_l, l)||^2](公式2),即预测噪声与实际添加噪声之间的均方误差。 - 训练策略:使用Adam优化器,学习率为3e-5。批次大小为16。在单张A6000 GPU上训练。每个epoch约11分钟,完整训练21个epoch,耗时约3小时7分钟。未提及warmup或学习率调度策略。
- 关键超参数:模型总参数量为241M(可训练)+ 128M(非可训练)。U-Net的具体深度和通道数在附录表A3中详细列出(例如输入块有3层,中间块有9层等)。
- 训练硬件:NVIDIA A6000 GPU,1张。
- 推理细节:采用DDIM采样器,采样步数为200步。
- 正则化或稳定训练技巧:未明确提及使用Dropout或权重衰减等技术。模型初始化使用了预训练的MusicLDM权重。
📊 实验结果
主要对比实验:在Slakh2100测试集上,与MSDM, STEMGEN, JEN-1 Composer, MSG-LD四个基线进行对比。
表1:混合音频FAD得分(越低越好)
| 方法 | MSDM | STEMGEN | JEN-1 Composer | MSG-LD | SyncTrack |
|---|---|---|---|---|---|
| FAD ↓ | 6.55 | 4.3 | 4.04 | 1.31 | 1.26 |
表2:单轨道FAD得分(越低越好)
| 方法 | Bass | Drum | Guitar | Piano |
|---|---|---|---|---|
| SyncTrack | 0.710 | 0.710 | 1.450 | 1.110 |
| MSG-LD | 1.050 | 0.980 | 1.830 | 2.040 |
| MSDM | 6.304 | 6.721 | 4.259 | 5.563 |
结论:SyncTrack在混合和单轨道音质上均大幅领先基线,尤其在鼓和钢琴轨道上优势明显。
表3:主观评估得分(5分制,越高越好)
| 类别 | 方法 | 组1 | 组2 | 组3 | 组4 |
|---|---|---|---|---|---|
| 混合 | Ground Truth | 4.2±0.9 | 4.5±0.6 | 4.7±0.5 | 4.6±0.6 |
| SyncTrack | 3.3±1.0 | 3.5±0.8 | 3.0±0.9 | 3.9±0.9 | |
| MSG-LD | 1.5±0.6 | 1.3±0.5 | 1.8±0.9 | 1.7±0.8 | |
| 鼓 | Ground Truth | 3.0±0.2 | 2.6±0.7 | - | - |
| SyncTrack | 1.9±0.3 | 2.1±0.5 | - | - | |
| MSG-LD | 1.2±0.5 | 1.3±0.6 | - | - | |
| 钢琴 | Ground Truth | 2.9±0.3 | 3.0±0.2 | - | - |
| SyncTrack | 1.9±0.4 | 1.8±0.5 | - | - | |
| MSG-LD | 1.2±0.5 | 1.2±0.4 | - | - |
结论:人类听众对SyncTrack生成音乐的节奏同步性感知显著优于MSG-LD,平均得分3.42 vs 1.57。
表4:轨道内节奏稳定性IRS(越低越稳定)
| 方法 | Bass | Drum | Guitar | Piano |
|---|---|---|---|---|
| Ground Truth | 0.015 | 0.005 | 0.016 | 0.015 |
| SyncTrack | 0.021 | 0.011 | 0.024 | 0.023 |
| MSG-LD | 0.041 | 0.040 | 0.039 | 0.039 |
| MSDM | 0.050 | 0.036 | 0.034 | 0.046 |
结论:SyncTrack的IRS值最接近真实数据,表明其生成的单轨节奏更稳定。
表5:跨轨道节奏同步指标(CBS越高越好,CBD越低越好)
| 指标 | Ground Truth | SyncTrack | MSG-LD | MSDM |
|---|---|---|---|---|
| CBS ↑ | 0.5740 | 0.5206 | 0.3861 | 0.4694 |
| CBD (mean) ↓ | 0.2412 | 0.2681 | 0.3714 | 0.3127 |
| CBD (std) ↓ | 0.1578 | 0.2131 | 0.2642 | 0.2217 |
| CBD (median) ↓ | 0.2066 | 0.2258 | 0.3545 | 0.2811 |
结论:SyncTrack在跨轨道同步性上优于所有基线,最接近真实数据。
消融实验 (RQ3): 表6:消融研究(FAD得分)
| 模型 | Bass | Drum | Guitar | Piano | Mixture | 相对SyncTrack提升 |
|---|---|---|---|---|---|---|
| Backbone | 5.234 | 3.081 | 6.012 | 6.170 | 2.570 | 50.97% |
| Backbone w/ a | 0.816 | 0.809 | 2.634 | 1.695 | 1.742 | 27.67% |
| Backbone w/ a+b | 0.632 | 0.758 | 2.367 | 1.359 | 1.627 | 22.56% |
| Backbone w/ a+c | 0.892 | 0.889 | 2.680 | 1.547 | 1.429 | 11.83% |
| SyncTrack-alternate | 0.900 | 0.897 | 2.663 | 1.757 | 1.586 | 20.55% |
| SyncTrack-reorder | 0.957 | 0.943 | 2.887 | 1.877 | 1.681 | 25.04% |
| SyncTrack | 0.710 | 0.710 | 1.450 | 1.110 | 1.260 | - |
结论:三个模块(a: 轨道特定模块, b: 全局跨轨道注意力, c: 时间特定跨轨道注意力)均有贡献。顺序“先b后c”优于交替或调换顺序,证实了设计的合理性。
图表展示:
图4:主观评分与客观指标(IRS, CBS, CBD)的散点图,展示了客观指标与人类感知的相关性,验证了所提指标的有效性。
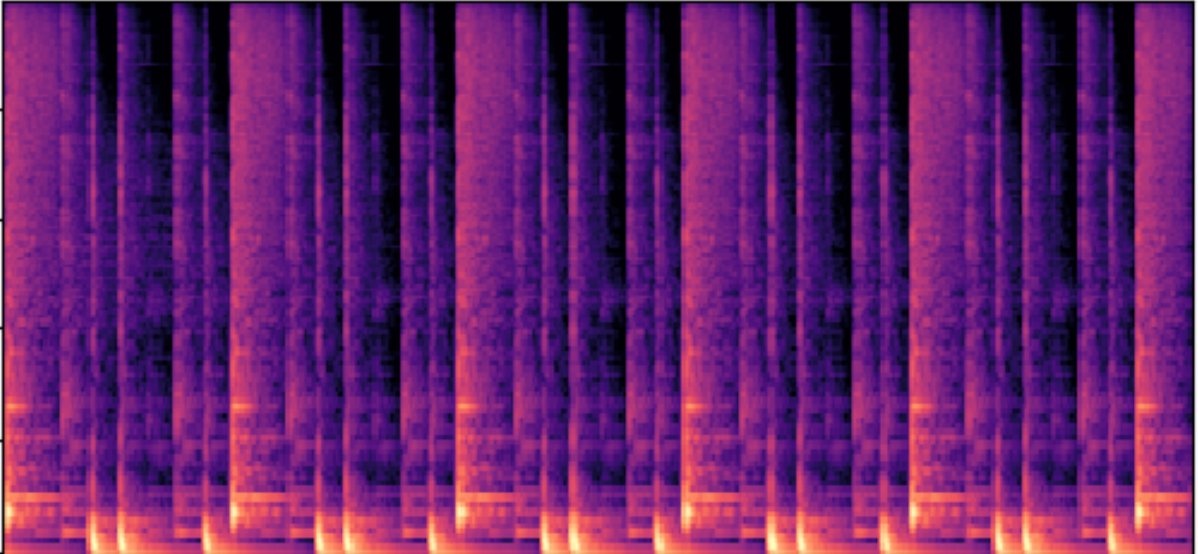
图A3:在Slakh2100上各轨道IRS得分对比图,直观显示SyncTrack(绿)的稳定性最接近Ground Truth(蓝)。
图A4:跨轨道同步指标(CBS, CBD各统计量)对比图,清晰展示SyncTrack在同步性上优于其他生成模型。

附录图A7:展示了所提指标在Slakh2100、MUSDB18数据集以及MSG-LD、SyncTrack生成音乐上的分布,验证了指标的区分度。
⚖️ 评分理由
- 学术质量 (7.0/7):论文逻辑清晰,针对多轨音乐生成的核心缺陷(节奏不一致)提出了结构化的解决方案(解耦架构+双层注意力+乐器先验),并配套设计了专门的评估指标。技术实现正确,基于成熟的LDM框架进行针对性改进。实验设计全面,对比了多个SOTA基线,进行了充分的消融研究和指标鲁棒性分析,所有结论都有明确的数据支持。虽然创新是在现有框架内的针对性优化而非基础理论突破,但解决了一个实际且重要的问题,完成度很高。
- 选题价值 (1.5/2):多轨音乐生成是AI音乐创作向专业化、可编辑化发展的关键环节,节奏同步是其中的技术瓶颈。该选题具有明确的应用价值和前沿性。提出的评估指标对推动该领域发展有积极意义。但相对于更广泛的语音合成、音频理解等领域,其受众和影响力范围相对较窄。
- 开源与复现加成 (0.5/1):论文开源了代码仓库,并提供了极为详尽的复现信息(附录中包含了从数据处理、模型架构、训练配置到评估工具的所有细节),这极大地方便了同行验证和后续研究。虽然未明确提及是否提供预训练权重和原始训练数据,但附录信息已使代码层面的复现成为可能。