📄 SupCLAP: Controlling Optimization Trajectory Drift in Audio-Text Contrastive Learning with Support Vector Regularization
#对比学习 #音频检索 #多语言 #预训练
✅ 7.5/10 | 前25% | #音频检索 | #对比学习 | #多语言 #预训练
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Jiehui Luo(中央音乐学院,2∗)
- 通讯作者:Yuguo Yin(北京大学,1†)
- 作者列表:
- Jiehui Luo(中央音乐学院)
- Yuguo Yin(北京大学)
- Yuxin Xie(北京大学)
- Jinghan Ru(北京大学)
- Xianwei Zhuang(北京大学)
- Minghua He(北京大学)
- Aofan Liu(北京大学)
- Zihan Xiong(电子科技大学)
- Dongchao Yang(香港中文大学)
💡 毒舌点评
本文的亮点在于从优化动力学的角度(力分解)为对比学习中的“轨迹漂移”现象提供了新颖的理论解释,并据此设计出简洁有效的SVR正则化方法,理论自洽且实验证据扎实。短板在于其验证主要依赖于相对较小规模的数据集(AudioCaps, Clotho),且未与更多、更强的近期基线(如一些大规模的CLIP式音频-文本模型)进行对比,其实效性和普适性在更大规模场景下有待进一步证明。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开预训练模型权重。
- 数据集:使用了公开的AudioCaps和Clotho数据集,并自行构建了多语言翻译版本。多语言测试集的质量在附录E.9中进行了评估。
- Demo:论文中未提及在线演示。
- 复现材料:论文在正文和附录中提供了较为详尽的训练设置(超参数、优化器、硬件)、模型架构细节(编码器型号、MLP结构)以及评估方法,为复现提供了基础。
- 引用的开源项目:论文依赖的编码器模型为CED(Dinkel et al., 2024)和SONAR-TE(Duquenne et al., 2023),均为公开可用模型。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 本文针对音频-文本对比语言-音频预训练(CLAP)中优化轨迹漂移的问题,该问题源于负样本推力中不受控的垂直分量,导致训练不稳定和收敛缓慢。
- 方法核心是提出支持向量正则化(SVR),通过在原损失函数中添加一个辅助损失项,利用构造的文本“支持向量”来选择性地抑制推力的垂直分量,从而稳定优化轨迹。
- 与已有方法(如InfoNCE、SigLIP)相比,本文新在:(1) 首次从梯度力分解视角明确剖析了轨迹漂移问题;(2) 设计了SVR方法进行针对性干预,且无需额外数据和推理开销;(3) 提出了无监督的语义半径建模策略(StaticSVR 和 DynamicSVR)来控制干预强度。
- 主要实验结果:在AudioCaps和Clotho数据集上,bi-DynamicSVR 方法在单语和多语言文本-音频检索任务上均显著超越InfoNCE和SigLIP基线。例如,在AudioCaps的T2A R@1指标上,InfoNCE为41.87,而bi-DynamicSVR达到44.16(提升约2.3%);在零样本ESC-50分类上,InfoNCE为89.6,bi-DynamicSVR为92.1(提升2.5%)。
- 实际意义在于,该方法以极低的额外计算成本(训练开销可忽略),提升了对比学习的训练效率和最终对齐质量,可直接应用于各种基于对比学习的音频-文本模型训练流程中。
- 主要局限性包括:(1) 实验数据集规模相对较小;(2) 与更先进的、可能已包含复杂技巧的基线对比不完全;(3) DynamicSVR的性能依赖于预测半径的准确性,在极端噪声环境下可能不稳定(论文附录E.7对其鲁棒性有一定分析)。
🏗️ 模型架构
SupCLAP的架构并未提出全新的编码器模型,而是在标准的对称对比学习框架(由音频编码器和文本编码器组成)之上,修改了训练目标函数。
- 整体流程:输入为音频-文本对,经各自的编码器得到归一化的嵌入向量
a+和t+。训练时,同时计算两个方向的原始InfoNCE损失(Lorig,t2a和Lorig,a2t)以及一个额外的SVR正则化损失Lsvr。总损失为L_SupCLAP = L_orig + α * L_svr。 - 核心组件:
- 原始对比损失 (
Lorig):标准的对称InfoNCE损失,用于拉近正样本对、推开负样本对。 - 支持向量正则化项 (
Lsvr):这是本文的核心架构创新。对于文本到音频方向,它计算一个新的对比损失:锚点不再是原始文本嵌入t+,而是其支持向量tsup。tsup是通过将t+沿正样本拉力方向(从t+指向a+的单位向量û)移动一个语义半径R得到:tsup = t+ + R * û。Lsvr计算tsup与所有音频嵌入的对比损失。
- 原始对比损失 (
- 数据流与交互:
Lsvr的梯度会通过链式法则反向传播到文本编码器。附录D的数学分析表明,该梯度等效于对原始推力的垂直分量施加一个(1 - R / ||a+ - t+||)的缩放因子,从而选择性地抑制它。因此,Lsvr并未引入新的编码器结构,而是通过改变梯度景观来优化训练过程。 - 关键设计选择:引入
tsup的动机是“重塑梯度空间”。其参数R不是直接监督学习的,而是通过无监督方式建模(见下节)。
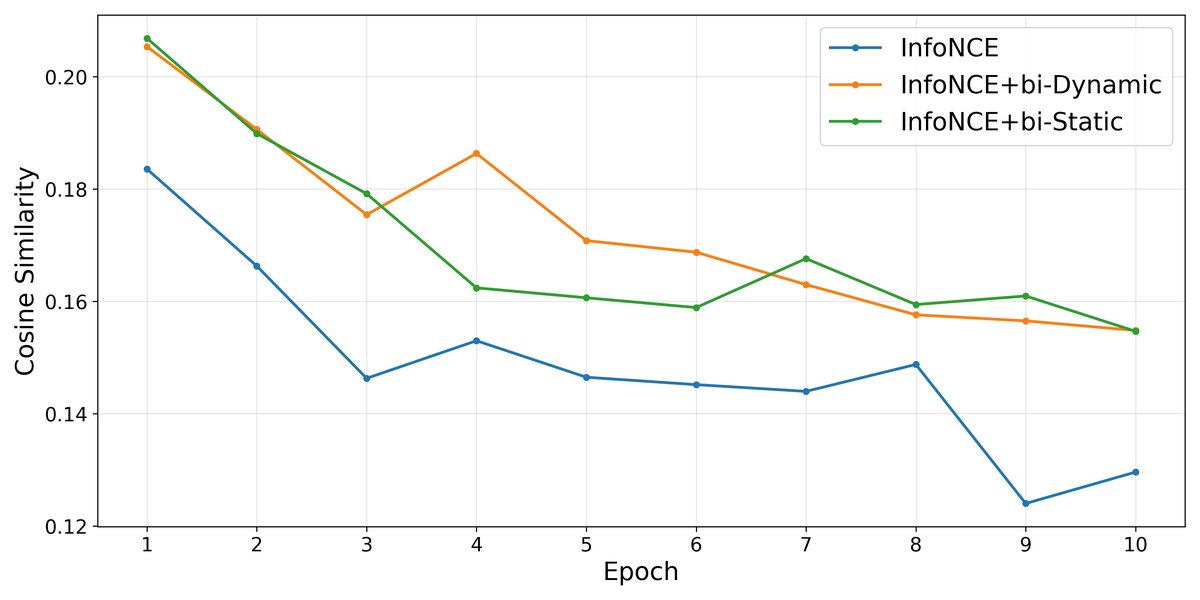 图1:优化轨迹漂移分析。该图用于验证“轨迹漂移”的存在。它衡量了更新向量与“拉力”向量之间的余弦相似度,相似度越高表示漂移越小。图中显示,相比InfoNCE损失,SVR方法(尤其是DynamicSVR)的相似度更高,表明其有效缓解了漂移。
图1:优化轨迹漂移分析。该图用于验证“轨迹漂移”的存在。它衡量了更新向量与“拉力”向量之间的余弦相似度,相似度越高表示漂移越小。图中显示,相比InfoNCE损失,SVR方法(尤其是DynamicSVR)的相似度更高,表明其有效缓解了漂移。
💡 核心创新点
- 从力分解视角定义“优化轨迹漂移”问题:将对比学习的梯度分解为正样本的“拉力”和负样本的“推力”,并指出推力中与拉力不共线的垂直分量是导致训练不稳定和轨迹漂移的直接原因。这一理论分析为方法设计提供了清晰依据。
- 提出支持向量正则化(SVR)方法:通过构造一个指向正样本方向的“支持向量”
tsup,并基于其计算一个辅助对比损失,从数学上推导出该方法能选择性地、自适应地抑制推力的垂直分量,同时保留其有益信息,从而稳定优化轨迹。 - 无监督语义半径建模:针对SVR中关键参数
R无监督标注的问题,提出两种策略:(a) StaticSVR:将R作为全局可学习标量;(b) DynamicSVR:使用一个轻量MLP,根据批次内文本与音频的相似度向量预测实例级的R,并加入约束项Lcons防止预测值过大或过负。 - 验证SVR的通用性与高效性:实验证明SVR能即插即用地提升InfoNCE和SigLIP等主流损失函数在单语/多语言检索、分类任务上的性能,且几乎不增加训练时间和显存开销。
🔬 细节详述
- 训练数据:
- 数据集:AudioCaps(约49k训练样本)和Clotho(6974个音频片段)。
- 多语言扩展:将所有英文描述翻译为7种其他语言(fra, deu, spa, nld, cat, jpn, zho)。
- 预处理:音频重采样至16kHz。
- 数据增强:未明确说明使用额外数据增强。
- 损失函数:
- 主损失:标准对称InfoNCE损失
Lorig。 - 正则化损失:
Lsvr,其形式为另一个对比损失,锚点为文本支持向量tsup。 - 总损失:
L_SupCLAP = L_orig + α * L_svr。 - 约束损失(DynamicSVR):
Lcons = Relu(R - ||a+ - t+||) + Relu(-R),用于约束预测的语义半径R。总损失变为L_SupCLAP + β * Lcons。 - 权重:
α默认为1;β默认为0.01。
- 主损失:标准对称InfoNCE损失
- 训练策略:
- 优化器:Adam。
- 学习率:5e-5。
- Batch Size:24(主实验),消融实验测试了48和72。
- 训练轮数:10个epoch。
- 温度参数
τ:0.07。 - 初始化:音频编码器(CED-Base)和文本编码器(SONAR-TE)使用预训练权重。
- 关键超参数:
- 嵌入维度
d:由编码器决定(未说明具体值,CED-Base和SONAR-TE通常为768或512)。 - DynamicSVR中的半径预测器:3层MLP。
- 嵌入维度
- 训练硬件:单张NVIDIA H800 GPU。
- 推理细节:推理流程与标准CLAP相同,仅计算音频和文本嵌入的相似度进行排序,无需计算支持向量
tsup,因此无额外推理开销。 - 正则化技巧:SVR本身是作为优化正则化项提出的;对于DynamicSVR,引入了约束项
Lcons以稳定训练。
📊 实验结果
表1:单语AudioCaps和Clotho数据集上的检索召回率和精度结果
| Model | AudioCaps T2A R@1 | AudioCaps T2A R@10 | AudioCaps A2T R@1 | AudioCaps A2T R@10 | Clotho T2A R@1 | Clotho T2A R@10 | Clotho A2T R@1 | Clotho A2T R@10 |
|---|---|---|---|---|---|---|---|---|
| 基线 (InfoNCE) | 41.87 | 87.69 | 56.72 | 92.33 | 18.67 | 58.42 | 22.61 | 63.09 |
| -bi-StaticSVR | 43.89 | 88.78 | 57.77 | 92.75 | 19.50 | 58.86 | 24.93 | 63.19 |
| -bi-DynamicSVR | 44.16 | 89.24 | 59.66 | 93.49 | 19.75 | 59.13 | 25.31 | 63.29 |
| 基线 (SigLIP) | 36.74 | 85.71 | 48.00 | 88.03 | 13.58 | 51.21 | 17.10 | 52.56 |
| -bi-StaticSVR | 42.54 | 87.61 | 55.25 | 90.55 | 16.21 | 53.60 | 21.26 | 59.13 |
| -bi-DynamicSVR | 43.09 | 89.26 | 56.30 | 92.67 | 17.51 | 56.85 | 22.71 | 60.87 |
结论:在InfoNCE和SigLIP基线上,添加SVR(尤其是bi-DynamicSVR)均带来显著性能提升。在AudioCaps T2A R@1上,相比InfoNCE提升2.29%,相比SigLIP提升6.35%。
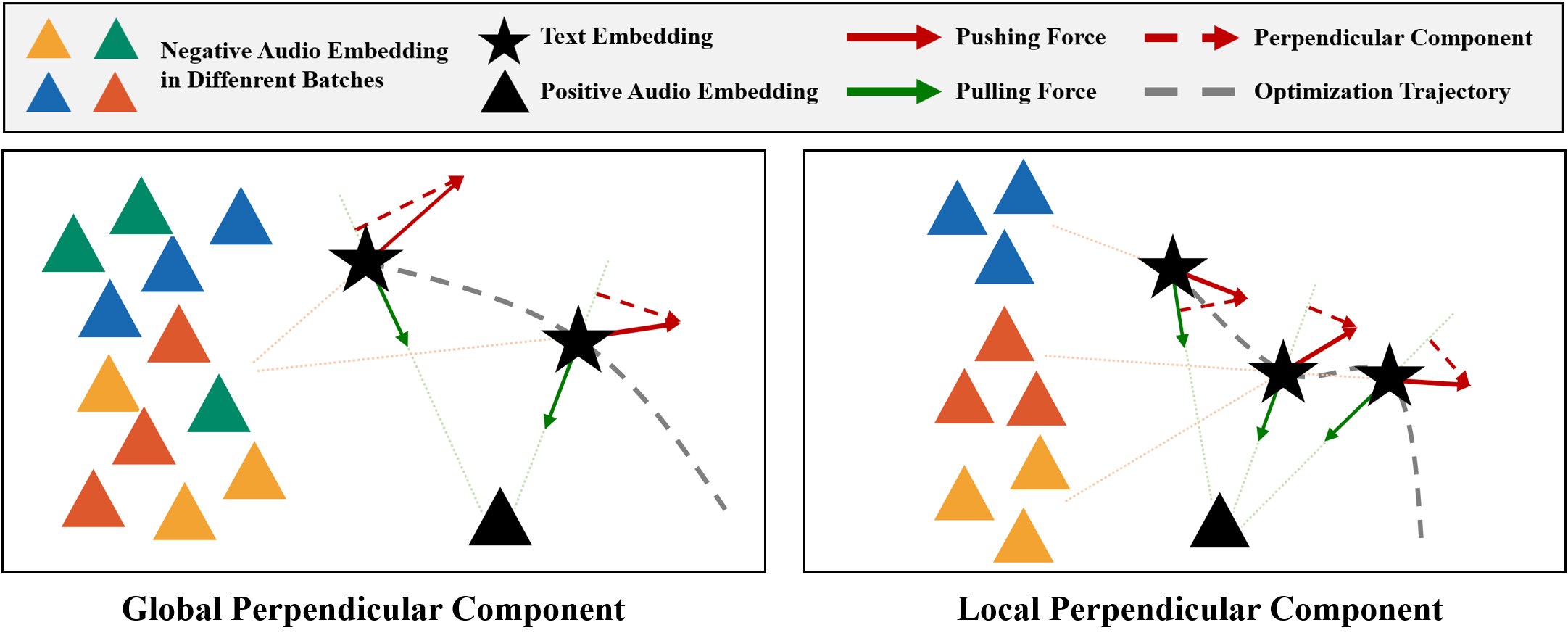 图3:语义半径变化结果。该图展示了训练过程中语义半径
图3:语义半径变化结果。该图展示了训练过程中语义半径 R 的变化趋势。随着训练进行,R 逐渐减小。StaticSVR的曲线平滑,而DynamicSVR的曲线有波动。这表明模型在训练初期需要更强的正则化(大R)来稳定轨迹,后期则减弱以保留更多负样本信息。
表2:CLAP模型的零样本音频分类性能
| Model | ESC-50 | US8K | VGGSound |
|---|---|---|---|
| InfoNCE | 89.6 | 81.63 | 24.57 |
| -bi-StaticSVR | 90.7 | 83.63 | 24.65 |
| -bi-DynamicSVR | 92.1 | 83.74 | 25.11 |
结论:在零样本分类任务上,SVR方法同样取得提升,证明了学习到的表征具有更好的泛化性。
表3:单语文本-音频检索SVR变体消融研究 (AudioCaps)
| ID | Model | T2A R@1 | T2A mAP10 | A2T R@1 | A2T mAP10 |
|---|---|---|---|---|---|
| 0 | InfoNCE | 41.87 | 56.74 | 56.72 | 35.36 |
| 1 | -bi-DynamicSVR | 44.16 | 58.79 | 59.66 | 36.69 |
| 2 | -bi-DynamicSVR wo/ constraints | 44.01 | 58.47 | 59.24 | 36.64 |
| 3 | -uni-DynamicSVR | 43.63 | 58.16 | 58.51 | 36.00 |
| 5 | -bi-StaticSVR | 43.89 | 58.36 | 57.77 | 35.72 |
| 6 | -uni-StaticSVR | 43.28 | 57.95 | 57.56 | 34.62 |
结论:(1) 双向SVR优于单向;(2) DynamicSVR优于StaticSVR;(3) 为DynamicSVR添加约束项 Lcons 能进一步提升性能。
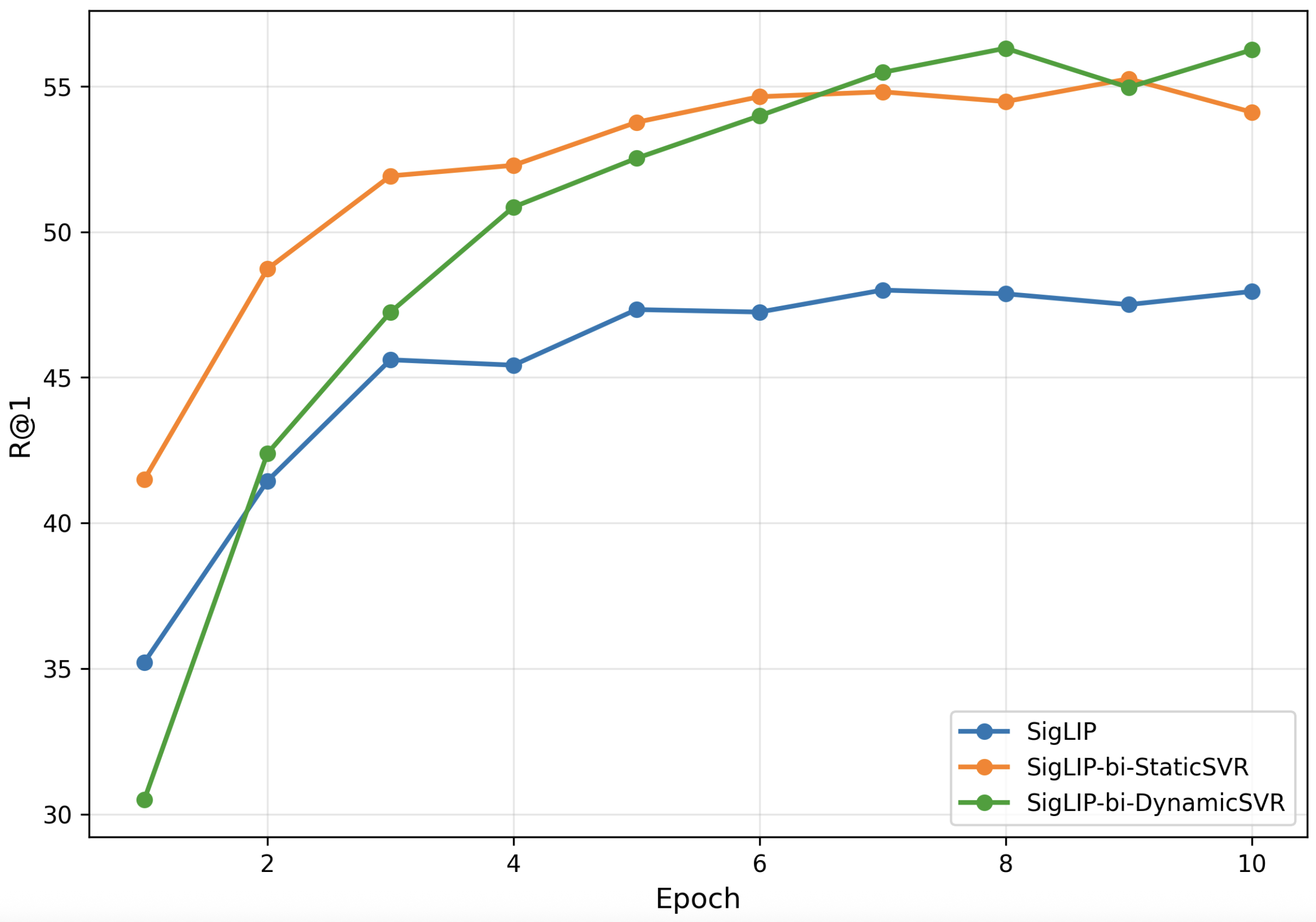 图5:基线损失与SVR之间收敛速度的比较。四幅图分别展示了在SigLIP和InfoNCE基线上,添加SVR(StaticSVR和DynamicSVR)后,A2T和T2A任务的R@1随训练轮数的变化曲线。可以看到,SVR方法在早期epoch就能达到更高的性能,并始终保持优势,直观地证明了其稳定优化轨迹、加速收敛的效果。
图5:基线损失与SVR之间收敛速度的比较。四幅图分别展示了在SigLIP和InfoNCE基线上,添加SVR(StaticSVR和DynamicSVR)后,A2T和T2A任务的R@1随训练轮数的变化曲线。可以看到,SVR方法在早期epoch就能达到更高的性能,并始终保持优势,直观地证明了其稳定优化轨迹、加速收敛的效果。
⚖️ 评分理由
- 学术质量:6.0/7:论文从理论分析出发,清晰定义了问题(轨迹漂移),并提出针对性的解决方案(SVR),数学推导严谨(附录D)。实验设计合理,对比了多种基线和变体,在多个任务和数据集上验证了方法的有效性,消融研究充分。主要扣分点在于:(1) 实验规模相对较小;(2) 与更强大或更近期的基线(例如,论文中表格列举的一些CLAP变体如Cacophony、T-CLAP等并未被完全超越)对比不够全面;(3) 对SVR在更复杂模型或更大batch size下的效果探索有限。
- 选题价值:1.5/2:优化对比学习的训练动态是提升模型性能的关键基础问题。本文工作对提升音频-文本对齐质量有直接应用价值,其思路也可能启发视觉-语言等其他对比学习场景的研究。
- 开源与复现加成:0/1:论文详细描述了实现细节,具备复现可能性。但论文中未提及��码链接、模型权重或训练脚本的开源计划,因此无法提供加成。