📄 SumRA: Parameter Efficient Fine-tuning with Singular Value Decomposition and Summed Orthogonal Basis
#语音识别 #参数高效微调 #多语言 #低资源
✅ 7.5/10 | 前25% | #语音识别 | #参数高效微调 | #多语言 #低资源
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Chin Yuen Kwok(南洋理工大学数字信任中心 & 计算与数据科学学院)
- 通讯作者:Yongsen Zheng(南洋理工大学数字信任中心 & 计算与数据科学学院)
- 作者列表:Chin Yuen Kwok(南洋理工大学数字信任中心 & 计算与数据科学学院)、Yongsen Zheng(南洋理工大学数字信任中心 & 计算与数据科学学院)、Jia Qi Yip(南洋理工大学计算与数据科学学院)、Kwok-Yan Lam(南洋理工大学数字信任中心 & 计算与数据科学学院)、Eng Siong Chng(南洋理工大学数字信任中心 & 计算与数据科学学院)
💡 毒舌点评
本文巧妙地将SVD的数学结构与LoRA的参数效率需求结合,通过“求和奇异向量”这一简洁操作,在冻结A矩阵的同时显著提升了多语言ASR的微调效果,证明了好的初始化比训练时的参数自由度有时更重要。然而,论文的实验完全集中在语音领域,对方法在更广泛NLP任务(如摘要中提到的GLUE)上的失效缺乏深入剖析,且未开源任何代码或模型,使得其“参数高效”在可复现性和实际部署上打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的Common Voice数据集,但未提供具体的划分脚本或处理后的数据。
- Demo:未提及。
- 复现材料:给出了模型配置(Whisper small/large-v2)、训练轮数、batch size、优化器、学习率调度器名称、LoRA插入位置、α设置等关键训练细节。提供了方法的数学公式和算法描述。
- 论文中引用的开源项目:引用了Whisper(Radford et al., 2023)、SpeechBrain(用于学习率调度器)以及Common Voice数据集。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的参数高效微调方法(如LoRA-FA、PiSSA)在冻结部分矩阵以节省存储和内存时,其初始化策略(如仅使用前几个主奇异向量)限制了模型对预训练知识空间的整体适应能力,尤其在需要全局知识迁移的多语言ASR任务中。
- 方法核心:提出SumRA,一种改进的LoRA矩阵A的初始化策略。其核心是将通过SVD分解预训练权重W₀得到的所有奇异向量(按Σ^(1/2)V⊤的形式)进行求和压缩,分配到矩阵A的每一行中,从而使A的每行能同时影响多个知识概念子集。同时,论文提出了“交错求和”和“贪心求和”策略来均匀分配重要奇异向量,避免干扰。
- 与已有方法相比的新颖性:相比于PiSSA仅使用顶部r个主奇异向量初始化A,SumRA通过求和方式利用了全部奇异向量(从主到次),从而让A矩阵能在更广的知识子空间上进行操作。这可以看作是在单次训练前就高效地“集成”了多个不同初始化方向的LoRA(如图5所示)。
- 主要实验结果:在Common Voice数据集上使用5种新语言(每种仅10小时数据)对Whisper模型进行适配的实验中:
- SumRA在WER(词错误率)上显著优于LoRA、PiSSA和CorDA等基线。例如,在Whisper-large-v2上,SumRA将WER从LoRA的14.42%降至12.41%(相对改进约14%),同时参数量减半(17.6M vs 34.3M)。
- 消融实验(表3)表明,提出的“交错求和”与“贪心求和”策略性能接近且均优于简单的“块求和”。
- 实际意义:在需要为大量语言或个性化用户部署微调模型的场景中,SumRA通过共享冻结的A矩阵、仅存储每个任务的B矩阵,能显著降低总存储成本(如图4所示),同时保持甚至提升性能,为大规模、可扩展的语音模型适配提供了更优的解决方案。
- 主要局限性:方法对全局属性的适应(如口音、说话风格)有效,但对局部适应(如添加少量领域术语)帮助有限。在NLP的GLUE基准测试等任务上初步实验未见明显提升,表明其优势可能局限于需要广泛表示空间调整的任务。
🏗️ 模型架构
本文的SumRA本身不是一个独立的模型架构,而是对现有LoRA(低秩适应)模块初始化方式的改进,用于适配大型预训练语音模型(如Whisper)的线性层。整体流程如下:
- 目标模型:采用预训练的Whisper模型(encoder-decoder Transformer架构)。适配时,在解码器的前馈网络(FFN)和注意力层(Attention)的所有线性层中插入LoRA模块。
- LoRA模块结构:对于一个预训练的权重矩阵W₀ ∈ ℝ^{d×k},LoRA引入两个低秩矩阵B ∈ ℝ^{d×r}和A ∈ ℝ^{r×k}(r ≪ min(d, k))。前向传播为:h = W₀x + α B A * x。其中α是缩放系数,通常设为r。
- SumRA的初始化与训练:
- 初始化:对W₀进行奇异值分解(SVD):W₀ = UΣV⊤。SumRA将矩阵Σ^(1/2)V⊤ ∈ ℝ^{k×k}按照特定策略(交错求和或贪心求和)“求和压缩”成矩阵A ∈ ℝ^{r×k}。A矩阵在训练过程中保持冻结。矩阵B初始化为零并可训练。
- 训练:只更新B矩阵以及模型的归一化层参数,冻结模型原始权重W₀和初始化的A矩阵。
- 多任务部署:对于不同的任务(如不同语言),可以共享同一个冻结的A矩阵,只需为每个任务存储和加载不同的B矩阵。
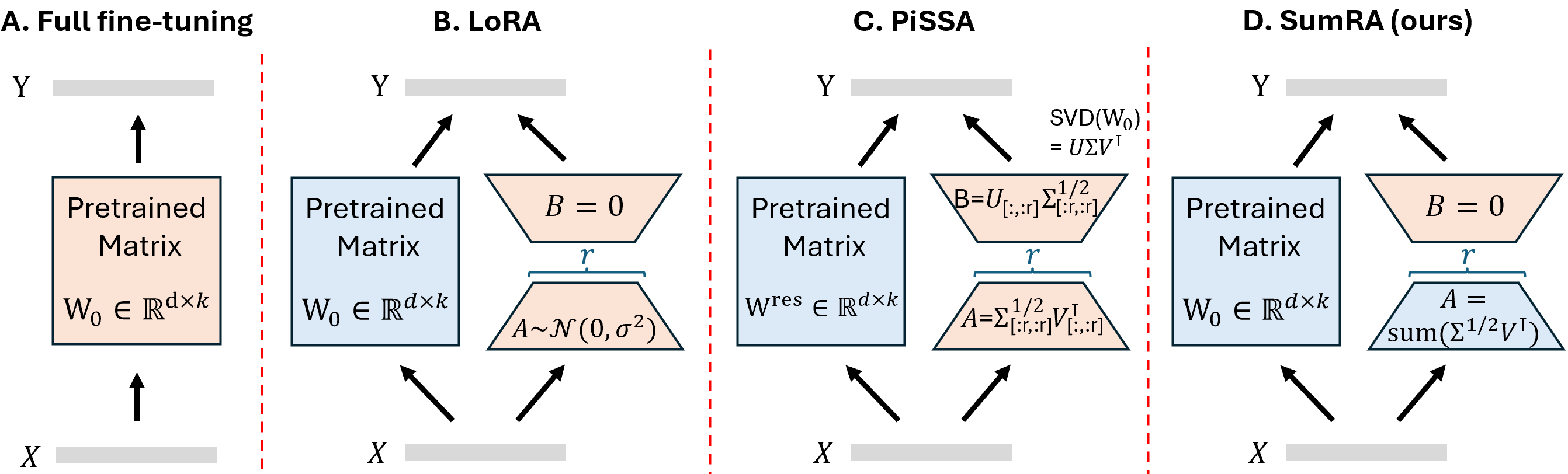 图1展示了全量微调、标准LoRA、PiSSA和SumRA的区别。SumRA(D)中,A矩阵是冻结的(蓝色),由求和后的奇异向量初始化,只有B矩阵(橙色)是可训练的。
图1展示了全量微调、标准LoRA、PiSSA和SumRA的区别。SumRA(D)中,A矩阵是冻结的(蓝色),由求和后的奇异向量初始化,只有B矩阵(橙色)是可训练的。
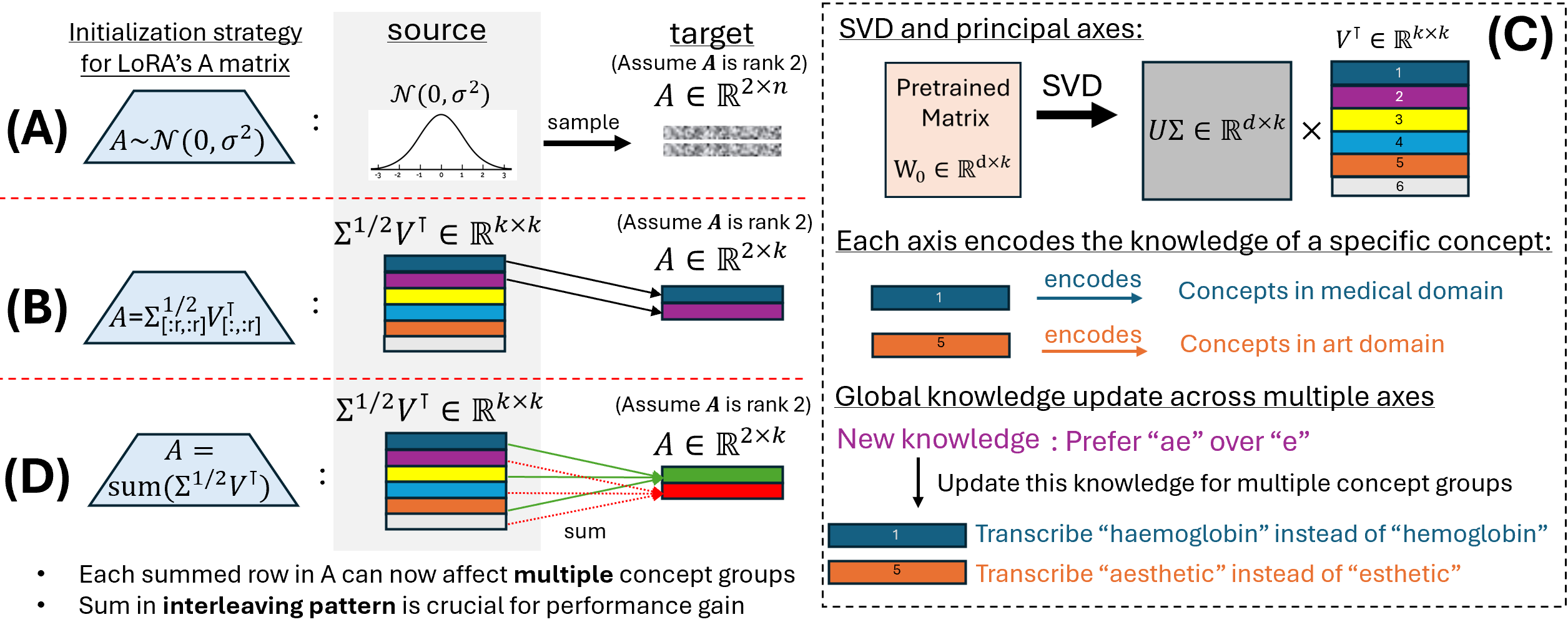 图2直观解释了核心动机:A) 标准LoRA随机初始化;B) PiSSA用顶部r个奇异向量初始化每行A;C) 每行A只影响一个概念子集;D) SumRA将多个奇异向量求和到一行A,使其能同时影响多个子集。
图2直观解释了核心动机:A) 标准LoRA随机初始化;B) PiSSA用顶部r个奇异向量初始化每行A;C) 每行A只影响一个概念子集;D) SumRA将多个奇异向量求和到一行A,使其能同时影响多个子集。
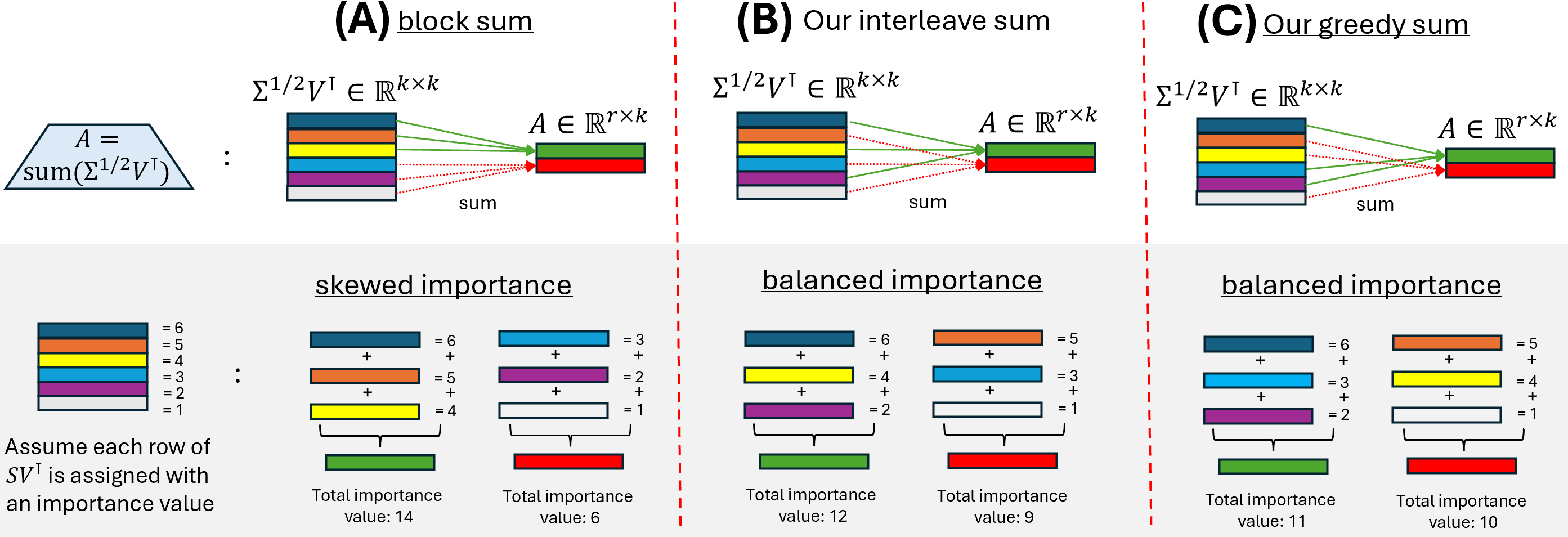 图3展示了三种求和策略:A) 块求和会将重要的向量集中到一行,导致干扰;B) 交错求和和 C) 贪心求和则能均匀分配重要向量,最小化最大行负载。
图3展示了三种求和策略:A) 块求和会将重要的向量集中到一行,导致干扰;B) 交错求和和 C) 贪心求和则能均匀分配重要向量,最小化最大行负载。
💡 核心创新点
- 利用全部奇异向量进行初始化:这是最核心的创新。突破了PiSSA仅使用前r个主奇异向量的限制,通过“求和”操作,将全部k个奇异向量的信息压缩进r行A矩阵中,使初始化后的A具有更广泛的表示能力。
- 结构化求和策略以最小化干扰:认识到简单求和会导致重要向量间的破坏性干扰,提出了“交错求和”与“贪心求和”两种策略。其中贪心求和在理论上(附录A.1证明)能最优地最小化“最大行负载”(即分配到一行中的奇异值之和),确保重要信息分布均匀。
- 冻结A以实现极致参数效率与任务扩展性:继承并强化了LoRA-FA“冻结A,只训练B”的思想,但通过更优的初始化解决了LoRA-FA随机初始化导致性能差的问题。这使得在多任务场景下,A矩阵可共享,仅需存储B矩阵,存储成本线性降低(如图4所示)。
- 与模型平均的理论联系:论文从模型平均(Model Averaging)的视角解释了SumRA的有效性(图5)。SumRA的初始化相当于在训练前就对多个不同初始化方向的LoRA矩阵进行了求和集成,从而在单次训练中实现了集成学习的效果。
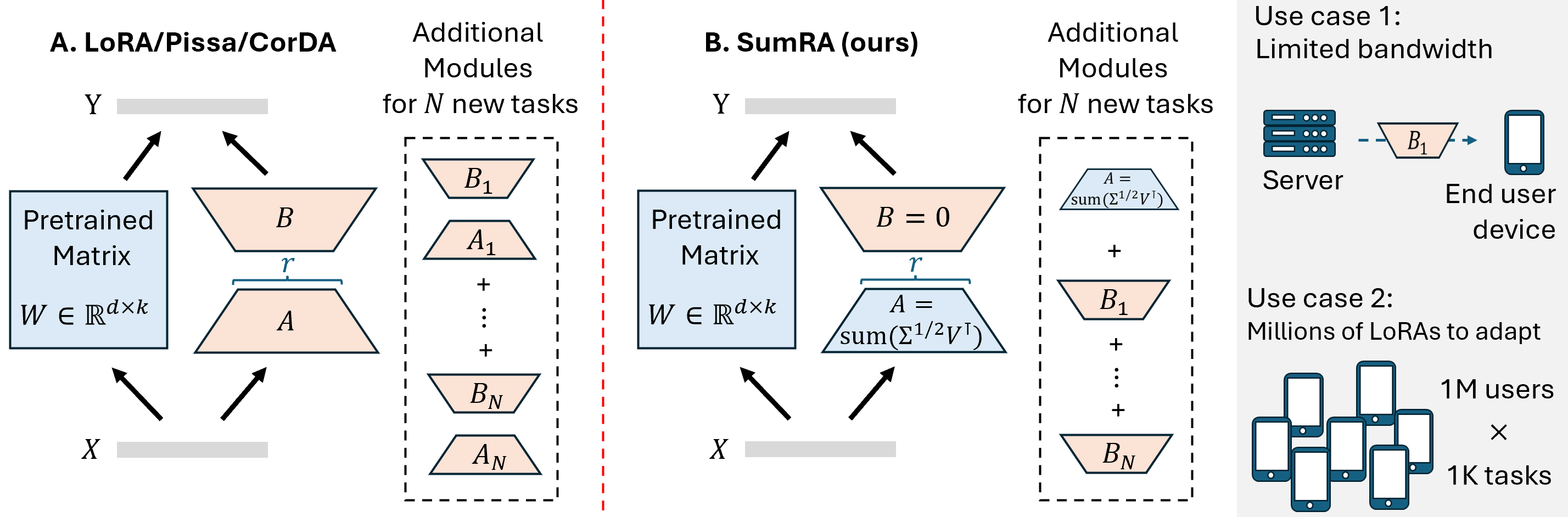 图4清晰展示了在多任务场景下,LoRA/PiSSA为每个任务存储完整的A和B,而SumRA共享A,仅存储B,显著降低总存储开销。
图4清晰展示了在多任务场景下,LoRA/PiSSA为每个任务存储完整的A和B,而SumRA共享A,仅存储B,显著降低总存储开销。
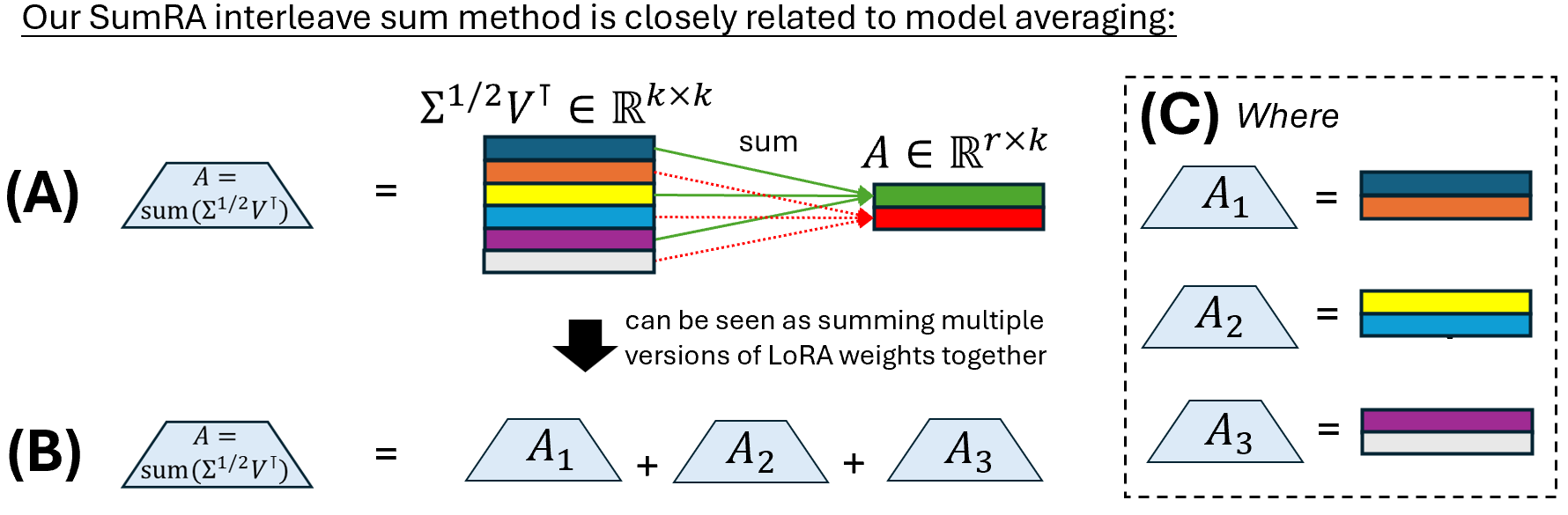 图5阐释了交错求和策略如何等效于多个基于部分奇异向量初始化的LoRA A矩阵的加权平均。
图5阐释了交错求和策略如何等效于多个基于部分奇异向量初始化的LoRA A矩阵的加权平均。
🔬 细节详述
- 训练数据:
- 数据集:Common Voice MASR数据集子集(Ardila et al., 2020)。
- 任务:多语言ASR适配,选择了5种Whisper预训练未包含的语言:世界语(eo)、草地马里语(mhr)、中库尔曼吉库尔德语(kmr)、弗里斯兰语(fy-NL)、国际语(ia)。
- 规模:每种语言使用10小时训练数据,1小时验证数据,1小时测试数据(遵循Della Libera et al., 2024的划分)。
- 损失函数:未在论文正文中明确提及,但根据Whisper的训练框架,应为标准的交叉熵损失(Cross-Entropy Loss),用于自回归解码器生成文本转录。
- 训练策略:
- 模型:Whisper-small 和 Whisper-large-v2。
- 适配层:解码器中的所有FFN和注意力层的线性层。
- 训练轮数:2个epoch。
- 批量大小(Batch Size):4。
- 优化器:AdamW。
- 学习率调度器:采用了一种基于验证集性能的调度策略(原文链接指向SpeechBrain的
NewBobScheduler)。 - 缩放系数α:设为等于LoRA的秩r(遵循Lee et al., 2023)。
- 关键超参数:
- LoRA秩(r):实验主要比较了r=2和r=32两种情况。
- 可训练参数量:随r和模型大小变化。例如,对于Whisper-large-v2,r=2时SumRA可训练参数为1.6M,r=32时为17.6M,均约为标准LoRA的一半。
- 训练硬件:论文中未说明。
- 推理细节:
- 解码策略:贪心解码(Greedy Decoding)。
- 未提及温度、beam size等设置。
- 正则化或稳定训练技巧:仅提到更新归一化层参数以稳定训练。
📊 实验结果
主要实验在Common Voice数据集的5种新语言上进行,评估指标为词错误率(WER),越低越好。下表总结了使用不同方法适配Whisper-large-v2模型的关键结果(r=32):
| 方法 | 额外存储参数 | eo WER(%) | ia WER(%) | fy-NL WER(%) | mhr WER(%) | kmr WER(%) |
|---|---|---|---|---|---|---|
| 未适配 | - | 62.54 | 47.96 | 105.00 | 81.28 | 102.00 |
| 全量微调(FT) | 100%模型参数 | 15.59 | 13.20 | 26.05 | 30.60 | 36.86 |
| LoRA | 34.3M | 14.42 | 8.67 | 24.75 | 32.39 | 37.72 |
| PiSSA | 34.3M | 13.00 | 8.82 | 22.43 | 29.97 | 34.26 |
| CorDA | 34.3M | 13.13 | 9.18 | 22.96 | 29.20 | 36.33 |
| SumRA (ours) | 17.6M | 12.41 | 8.17 | 22.27 | 27.19 | 34.21 |
关键结论:
- 性能优越:SumRA在所有5种语言上均取得了最低的WER。相比最强基线CorDA,在fy-NL语言上相对改进达10% (22.96% -> 22.27%);相比LoRA,在mhr语言上相对改进达16% (32.39% -> 27.19%)。
- 参数高效:SumRA的可训练参数量(17.6M)仅为标准LoRA(34.3M)的约一半,体现了“冻结A”带来的效率优势。
- 与全量微调对比:对于大模型(large-v2),SumRA在部分语言(如fy-NL, mhr)上性能接近甚至超过全量微调,且参数量极少,显示了其在避免过拟合方面的优势。
求和策略消融实验(基于Whisper-small, r=32):
| 方法 | eo | ia | fy-NL | mhr | kmr |
|---|---|---|---|---|---|
| LoRA | 23.39 | 15.31 | 39.34 | 40.63 | 48.51 |
| SumRA (块求和) | 21.68 | 13.91 | 35.38 | 37.35 | 47.30 |
| SumRA (交错求和) | 20.77 | 13.38 | 33.37 | 36.30 | 44.47 |
| SumRA (贪心求和) | 20.73 | 13.16 | 33.91 | 37.53 | 44.72 |
| 结论:贪心求和和交错求和策略性能接近且均显著优于块求和,验证了均匀分配重要奇异向量的必要性。 |
数据规模影响实验(Whisper-small适配世界语eo):
| 方法 | 10h | 50h | 100h |
|---|---|---|---|
| FT | 18.89 | 15.31 | 13.62 |
| LoRA | 23.39 | 15.20 | 13.28 |
| SumRA (冻结A) | 20.77 | 14.49 | 13.39 |
| SumRA (训练A) | 20.14 | 13.75 | 13.02 |
| 结论:SumRA的优势在低资源(10h)设置下最明显,随着数据量增加,改进幅度减小。如果额外训练A矩阵,性能还能进一步提升,但会增加参数量。 |
⚖️ 评分理由
- 学术质量:6.0/7。创新性明确(将SVD全量向量通过求和压缩引入LoRA初始化),理论动机清晰(扩展知识影响空间),并从模型平均角度提供了新视角。技术实现正确,实验设计合理,在目标多语言ASR任务上提供了充分的证据(多语言、多模型规模、多对比基线、消融实验)。主要扣分点在于实验范围局限于语音领域,对方法在其他模态或任务上的普适性未做深入验证。
- 选题价值:1.5/2。选题处于参数高效微调与大模型适配的前沿,对于解决多语言/个性化语音模型部署的存储扩展性问题有直接的实用价值。与音频/语音读者的相关性高。
- 开源与复现加成:0.0/1。论文未提供代码仓库、模型权重或详细的超参数搜索记录。虽然描述了训练配置,但完整的复现仍存在信息缺口,因此无加分。