📄 STITCH: Simultaneous Thinking and Talking with Chunked Reasoning for Spoken Language Models
#语音大模型 #自回归模型 #语音对话系统 #流式处理
✅ 7.5/10 | 前25% | #语音对话系统 | #自回归模型 | #语音大模型 #流式处理
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Cheng-Han Chiang(台湾大学;微软)
- 通讯作者:Xiaofei Wang(微软)
- 作者列表: Cheng-Han Chiang (台湾大学, 微软), Xiaofei Wang (微软), Linjie Li (微软), Chung-Ching Lin (微软), Kevin Lin (微软), Shujie Liu (微软), Zhendong Wang (微软), Zhengyuan Yang (微软), Hung-yi Lee (台湾大学), Lijuan Wang (微软)
💡 毒舌点评
这篇论文巧妙地利用“音频播放时间”来“偷”时间进行内部推理,为语音大模型引入“边想边说”能力,解决了传统“先想后说”带来的延迟问题,思路很工程化且有效。但论文的“突破性”有限,核心是将文本CoT技术适配到特定语音模型架构(GLM-4-Voice)的生成流程上,并非提出全新的模型范式;同时,实验主要局限于英语数学问答,对多语言、复杂对话场景的验证有待加强。
📌 核心摘要
- 要解决的问题:当前的语音语言模型(SLM)缺乏在回答前进行内部、无声思考过程的能力,而直接生成完整思维链(CoT)再说话会导致响应延迟不可控。
- 方法核心:提出STITCH(Simultaneous Thinking and Talking with Chunked Reasoning),使模型在生成语音响应的音频片段(chunk)的播放时间内,交替生成无声推理块(reasoning chunks)和文本-语音响应块,实现“同时思考与说话”。其两个变体:STITCH-R(先推理后说话)和STITCH-S(先说话后推理)。
- 与已有方法相比新在哪里:首次将无声音频推理能力引入语音语言模型。相比“先说后想”的基线,STITCH在数学推理任务上性能大幅提升(平均提升15%),同时STITCH-S的初始响应延迟与无推理模型相同。
- 主要实验结果: 在数学推理数据集上(GSM8K等),TBS(先完整思考再说话)的平均准确率为79.12%,STITCH-R为78.70%,STITCH-S为78.04%,远高于无推理基线(62.98%)。在非推理任务上,STITCH系列性能与基线持平或略优。人类评估显示STITCH-S的响应速度优于STITCH-R和TBS。关键对比数据见下表:
| Id | Config | Latency | Average Accuracy (Math QA) |
|---|---|---|---|
| 2 | No reasoning | Ntext + Nspeech | 62.98 |
| 4 | TBS | Nfull + Ntext + Nspeech | 79.12 |
| 6 | STITCH-R | Nreason + Ntext + Nspeech | 78.70 |
| 7 | STITCH-S | Ntext + Nspeech | 78.04 |
- 实际意义:为构建更智能、响应更自然的语音助手提供了一种新范式,能在不增加用户等待时间的前提下,提升模型处理复杂推理任务的能力。
- 主要局限性:实验集中在英语数学和问答任务;方法强依赖于所选SLM(GLM-4-Voice)的特定文本-语音交替生成架构;未探讨更长、更复杂的推理链如何影响语音输出的连贯性。
🏗️ 模型架构
论文提出的STITCH是一种生成方法(pipeline),而非一个全新的模型架构。它作用于现有的交错解码(Interleaved Decoding) 类语音语言模型(如GLM-4-Voice)之上。
完整输入输出流程:
- 输入:用户语音输入,被编码为语音token序列。
- 输出:生成一个混合序列,包含三种类型的token块:推理token块(无声的文本CoT)、文本token块(响应的文本转录)、语音token块(响应的离散语音表示)。这些块按照特定模式交替生成。
- 后处理:语音token块被送入语音解码器(Speech Decoder) 合成音频波形并播放给用户。
关键设计选择与动机:
- 交错生成模式:核心创新。在播放上一个语音块(时长
_chunk)的音频期间,模型利用这段“空闲时间”生成下一个推理块和文本-语音块,从而实现“同时思考与说话”。 - STITCH-R(推理优先):生成模式为
推理块 → 文本块 → 语音块循环。首次语音输出需等待第一个推理块(Nreason个token)生成,延迟略高于无推理模型。 - STITCH-S(说话优先):生成模式为
文本块 → 语音块 → 推理块循环。首先生成文本和语音块,实现与无推理模型相同的低初始延迟,然后在播放音频时生成推理块。 - 特殊标记符:使用
[SOPR],[EOPR],[EOR]等标记推理块的开始、部分结束和整体结束,确保生成结构可控。
架构图说明:
图1: STITCH-R的时序图。展示了模型如何在播放第一段语音音频(S1)的tchunk秒时间内,生成下一个推理块、文本块和语音块(S2)。关键在于生成所有token的时间ttoken小于音频播放时长tchunk。
图2: 对比了不同生成方法。(a) GLM-4-Voice基线:文本与语音块交错。(b) TBS:先生成完整推理,再交错生成文本与语音。(c) STITCH-R:推理块、文本块、语音块交错。(d) STITCH-S:文本块、语音块、推理块交错。清晰展示了STITCH在生成顺序上的创新。
💡 核心创新点
- “同时思考与说话”生成范式:首次在语音语言模型中实现无声音频推理与语音输出生成的并行化,利用音频播放时长作为推理的“免费”计算时间窗口,从根本上解决了“先想后说”的延迟问题。
- STITCH-S的零延迟引入:通过调整生成块的顺序(先说话后推理),在保持与无推理模型完全相同的首次包延迟(first packet latency)的前提下,获得了推理能力的提升。
- 灵活的推理长度控制:在训练固定的推理块长度(Nreason=100)后,推理时可通过注入
[EOPR]标记动态调整实际生成的推理块长度(N’_token),在性能与计算成本间提供灵活折衷。
🔬 细节详述
- 训练数据:
- 来源与规模:约40万条数据,混合三类任务:
- 通用对话:VoiceAssistant400K (约17.7万)。
- 数学推理:Tulu-3系列 (约22万)。
- 知识问答:Natural Question + TriviaQA (约7万)。
- 预处理:数学和知识问答数据通过TTS合成语音,并使用GPT-4o生成或改写CoT推理
z和口语化响应y。对话数据使用GPT-4o生成推理z。 - 数据构建:以TBS数据
(x, z, y)为基础,STITCH-R将z分块后交错插入y中,STITCH-S则将z分块后插入y的块之间。
- 来源与规模:约40万条数据,混合三类任务:
- 损失函数:标准语言建模交叉熵损失,自回归预测整个交错token序列(包括推理、文本和语音token)。
- 训练策略:
- 微调方式:在GLM-4-Voice-9B基础上进行全参数微调,冻结语音编码器和解码器。
- 超参数:学习率1e-5,批量大小2(32张A100上梯度累积8步),cosine学习率调度,warmup比例0.1,训练2个epoch,使用bf16和DeepSpeed ZeRO-2。
- 关键超参数:推理块长度
Nreason = 100,文本块长度Ntext = 13,语音块长度Nspeech = 26(与GLM-4-Voice一致)。
- 训练硬件:32张 NVIDIA A100-80GB GPU,训练约17小时。
- 推理细节:解码策略未明确说明(推测为自回归贪心或采样)。语音解码器与token生成可并行运行,确保音频流无缝播放。可通过在生成N’_token个推理token后插入
[EOPR]来动态控制推理长度。
📊 实验结果
主要性能对比(数学推理任务):
| Id | Config | Latency | Use Reasoning (Train/Infer.) | Average Accuracy (Math QA) |
|---|---|---|---|---|
| 1 | GLM-4-Voice | Ntext + Nspeech | - / ✘ | 53.08 |
| 2 | No reasoning | Ntext + Nspeech | ✘ / ✘ | 62.98 |
| 4 | TBS | Nfull + Ntext + Nspeech | ✔ / ✔ | 79.12 |
| 6 | STITCH-R | Nreason + Ntext + Nspeech | ✔ / ✔ | 78.70 |
| 7 | STITCH-S | Ntext + Nspeech | ✔ / ✔ | 78.04 |
非推理任务性能: STITCH系列在知识问答和对话数据集(Llama Questions, TriviaQA, WebQuestions, AlpacaEval)上性能与基线持平或略优(见原文表1b)。
推理token与文本token数量统计:
| Model | Dataset | Avg Reason Tokens | Avg Text Tokens |
|---|---|---|---|
| TBS | GSM8K | 360.04 | 70.49 |
| STITCH-R | GSM8K | 322.40 | 74.36 |
语音质量评估:UTMOSv2(感知质量)和GPT-4o-score(文本流畅度)分数显示,STITCH系列与基线相当(约3.1和4.7/5),表明引入推理未损害语音输出质量。
动态调整推理长度实验:
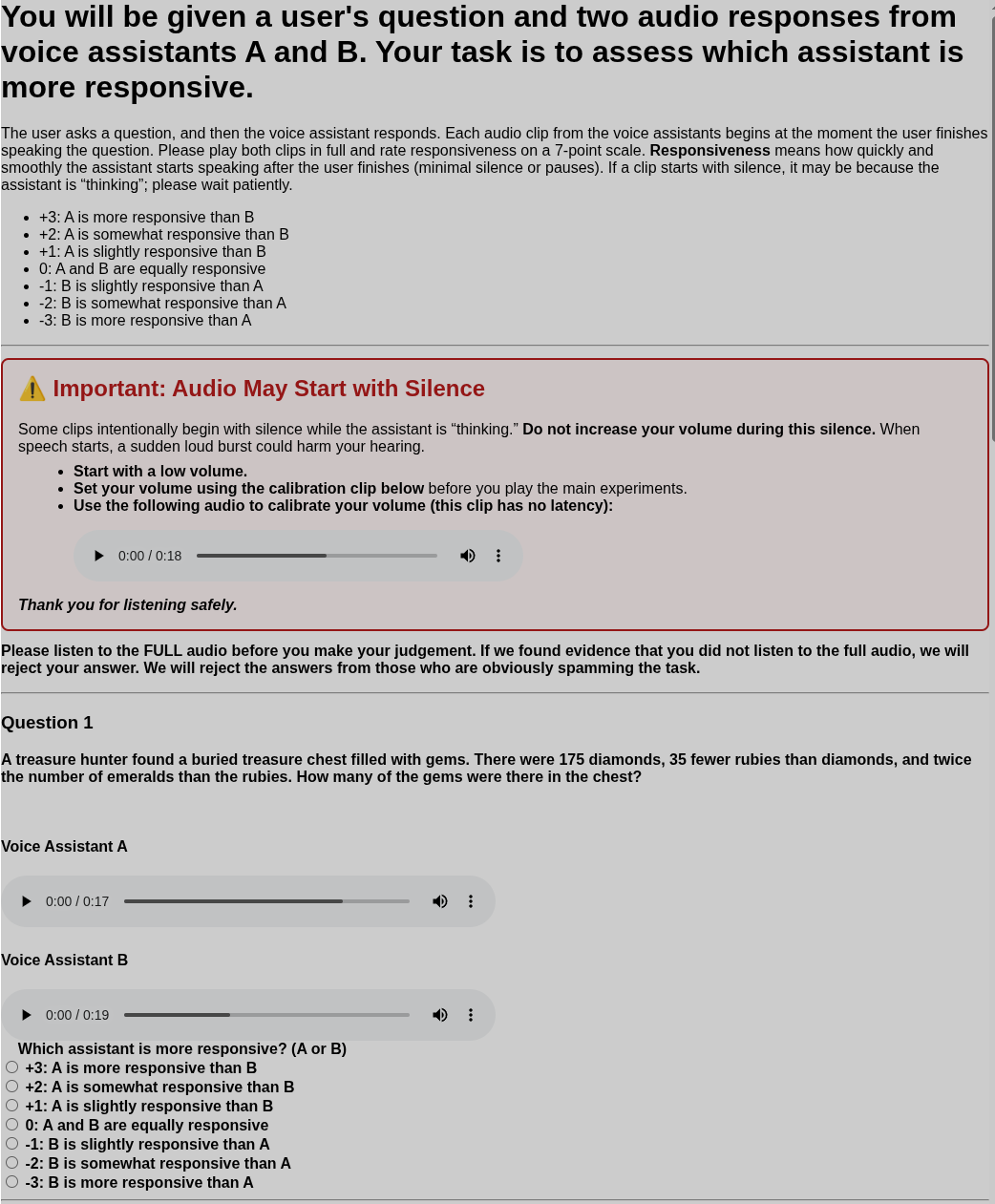 图3: (a)(b) 显示在STITCH-R和STITCH-S中,将推理块长度N‘_token从100缩减至60-90时,各数学任务准确率变化。结论:N’_token ≥80时,性能可恢复到Nreason=100时的90%以上。 (c) 显示使用不同外部模型作为“推理增强器”时,STITCH-R的平均准确率。更强的模型(GLM-4-9B)带来更好性能。
图3: (a)(b) 显示在STITCH-R和STITCH-S中,将推理块长度N‘_token从100缩减至60-90时,各数学任务准确率变化。结论:N’_token ≥80时,性能可恢复到Nreason=100时的90%以上。 (c) 显示使用不同外部模型作为“推理增强器”时,STITCH-R的平均准确率。更强的模型(GLM-4-9B)带来更好性能。
⚖️ 评分理由
- 学术质量:6.5/7:论文清晰定义了问题,并提出了一个设计巧妙、工程上可行的解决方案(STITCH)。方法新颖性强,是首次将无声音频推理引入语音模型的生成流程。实验设计全面,包含多种基线对比、消融实验(推理长度调整、推理源替换)、人工评估和语音质量评估,证据可信。扣分点在于,其创新更多是生成策略和流程的创新,而非底层模型架构或学习算法的突破。
- 选题价值:1.5/2:选题切中当前大模型“推理”能力的热点,并将其拓展至语音交互领域,具有前沿性和明确的应用价值(提升语音助手在复杂问题上的表现)。潜在影响较大,但应用范围目前局限于需要复杂推理的问答场景。
- 开源与复现加成:0.5/1:论文提供了详细的训练超参数、数据处理流程(附录包含完整提示词)、代码配置片段和项目主页链接。但未明确承诺开源代码、模型权重或完整数据集。部分依赖外部工具(GLM-4-Voice, LlamaFactory)。因此给中等加成。