📄 Steering Autoregressive Music Generation with Recursive Feature Machines
#音乐生成 #可解释性 #自回归模型 #基准测试 #模型评估
🔥 8.0/10 | 前25% | #音乐生成 | #可解释性 | #自回归模型 #基准测试
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Daniel Zhao (University of California, San Diego)
- 通讯作者:未明确说明(论文列出了所有作者邮箱,无指定通讯作者)
- 作者列表:Daniel Zhao (University of California, San Diego)、Daniel Beaglehole (University of California, San Diego)、Taylor Berg-Kirkpatrick (University of California, San Diego)、Julian McAuley (University of California, San Diego)、Zachary Novack (University of California, San Diego)
💡 毒舌点评
亮点:该工作将“可解释性”与“可控生成”两个热门方向巧妙结合,通过激活空间干预提供了无需重训模型的细粒度控制方案,实验设计全面,既有严谨的量化指标,也有主观听感测试。 短板:对节奏、和弦进行等强时序依赖概念的控制效果仍较弱,其核心控制单元(均值池化的探针)本质上牺牲了时序动态信息,这在未来可能是需要突破的瓶颈。
🔗 开源详情
- 代码:是。论文明确提供了代码仓库链接:
https://github.com/astradzhao/music-rfm。 - 模型权重:未提及是否公开在MUSICGEN-Large上训练好的RFM探针权重。
- 数据集:依赖公开的SYNTHEORY(需联系原作者Wei等人)和SONG-DESCRIPTOR数据集,但论文中未提供直接下载链接。
- Demo:提供了交互式演示页面:
https://musicrfm.github.io/controllable-music-rfm/。 - 复现材料:论文附录提供了详细的超参数配置(表8)、RFM训练细节(附录B)、消融实验设置(附录C)和算法伪代码(附录F,算法1)。
- 引用的开源项目:主要依赖MUSICGEN(Copet et al.)、EnCodec(Défossez et al.)、Essentia(Bogdanov et al.)、librosa(McFee et al.)等开源工具和模型。
📌 核心摘要
本文旨在解决可控音乐生成中模型需重训、易引入伪影的问题。方法核心是提出MusicRFM框架,首次将递归特征机(RFM)应用于冻结的自回归音乐生成模型(MUSICGEN-Large),通过分析内部梯度提取可解释的“概念方向”(如特定音符、和弦),并在推理时直接注入模型激活空间以引导生成。与已有方法相比,其创新在于:1) 完全免训练、免优化,仅需训练轻量RFM探针;2) 提出分层权重(Top-K/指数加权)和时间调度等精细控制机制。主要实验结果:在SYNTHEORY合成数据集上,MusicRFM可将目标音符的分类准确率从0.23提升至0.82,同时保持CLAP分数在基线±0.02内(控制与保真的有利折衷)。在外部评估中,其控制效果也优于提示工程基线。实际意义是为可控音乐生成提供了一种高效、可解释的新范式,有望降低创作门槛。主要局限性是依赖于均值池化,对序列依赖性强的概念(如节拍、和弦进行)控制能力有限。
🏗️ 模型架构
论文的核心是MusicRFM框架,它并非一个单一生成模型,而是一套针对已冻结生成模型的控制方法。其完整流程如下:
- 输入与预处理:输入为文本提示和控制目标(如“音符C#”)。音频先通过EnCodec编码为离散标记,作为自回归模型的输入。
- 探针训练阶段(离线):
- 使用合成数据集SYNTHEORY,将音频过模型,在每个Transformer解码层(共48层) 的激活值上进行均值池化,得到表示片段的向量。
- 针对每个音乐概念(音符、和弦等)和每一层,训练一个轻量RFM探针。该探针通过迭代计算平均梯度外积(AGOP) 矩阵并特征分解,得到一组正交的特征方向
{q_j}。这些方向对应模型对特定概念最敏感的激活空间轴。
- 推理阶段(实时):
- 在模型前向传播的每一层(
ℓ)和每一步(t),注册前向钩子(forward hook)。 将训练好的RFM方向q_ℓ, j按层权重w_ℓ、时间调度ϕ(t)和随机门控ψ_p(t)进行缩放,直接加到该层的残差流隐藏状态h_t,ℓ上(公式:h'_{t,ℓ} = h_{t,ℓ} + η_ℓ(t) q_{ℓ,j})。 - 通过这种对激活空间的直接干预,引导模型的输出偏向目标概念,最后解码得到控制后的音频。
- 在模型前向传播的每一层(
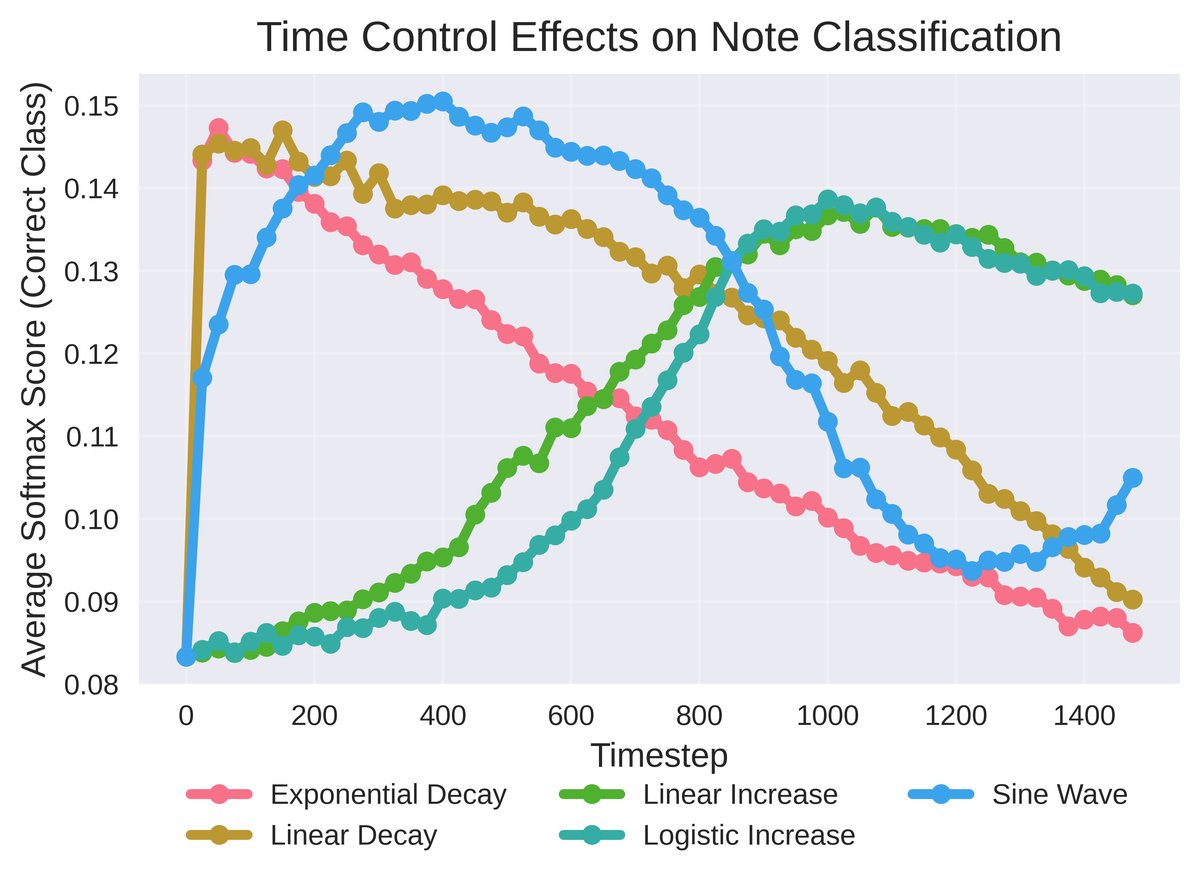 图1:展示了MusicRFM的控制流程。左侧为探针训练,从模型各层激活中提取概念方向;右侧为推理时注入,通过钩子将方向加到隐藏状态上,实现引导。
图1:展示了MusicRFM的控制流程。左侧为探针训练,从模型各层激活中提取概念方向;右侧为推理时注入,通过钩子将方向加到隐藏状态上,实现引导。
关键设计选择与动机:
- 均值池化:相比只使用最后一个词元的激活,能更好地捕捉整个音频片段的时序信息,提升探针性能。
- 分层权重(Top-K/指数加权):解决“朴素”注入所有层导致音质下降和文本一致性变差的问题,让控制集中在信息量大的层。
- 时间调度与随机门控:实现控制强度随时间动态变化,并降低累积伪影,增强生成稳定性。
💡 核心创新点
- 将RFM迁移至音乐生成控制:首次将递归特征机从文本模型的特征分析,适配为对冻结音乐生成模型的实时激活空间引导方法,实现了无需微调的细粒度控制。
- 分层感知的权重机制:提出Top-K选择和基于探针性能的指数加权两种层剪枝策略,有效平衡了控制强度与生成质量,这是对原始RFM方法的重要改进。
- 时间动态控制调度:引入线性/指数/正弦等多种时间调度函数和伯努利随机门控,允许控制强度随时间平滑变化或稀疏应用,支持渐变、交叉淡化等复杂音乐控制场景。
- 多方向并行控制:支持同时注入多个概念方向,实现对不同音乐属性(如音符+和弦)的联合控制,并允许为每个方向设置独立的系数和调度。
🔬 细节详述
- 训练数据:
- 探针训练:使用SYNTHEORY数据集,这是一个为研究音乐理论概念设计的合成数据集,包含音符、和弦、音阶等7类标签,提供干净、细粒度的监督信号。
- 控制评估:评估集来自SONG-DESCRIPTOR数据集(250个提示)。
- 真实数据验证:在MUSICBENCH真实音乐数据集上进行了迁移性验证。
- 损失函数/训练目标:探针训练采用核岭回归作为基础学习器。对于二分类任务,最大化AUC;对于多分类,使用交叉熵损失(通过softmax和独热编码);对于回归任务(如节拍),最小化MSE。RFM迭代本身通过AGOP矩阵实现特征学习,无需反向传播。
- 训练策略:RFM探针训练15次迭代。使用70/15/15的训练/验证/测试集划分。通过随机搜索(100-300组)优化超参数(见附录表8)。
- 关键超参数:
- 基础生成模型:MUSICGEN-Large,包含48个 Transformer解码块。
- 控制系数
η_0:实验中扫描了{0.15, 0.30, 0.45, 0.60}。 - 层权重:指数加权中
κ=0.95;Top-K中K从4到48。 - 随机门控概率
p=0.3(默认值)。
- 训练硬件:未明确说明具体GPU型号和训练时长,仅提及使用A6000 GPU进行超参数搜索。
- 推理细节:解码策略未说明(推测为模型默认)。控制在每个解码步骤的每个层上应用(根据权重和门控条件)。
- 正则化/稳定技巧:随机门控(伯努利采样)和分层剪枝是主要的稳定技巧,用于防止过控制和累积伪影。
📊 实验结果
本文进行了全面的实验,包括分类、单方向控制、多方向控制和时间控制评估。
分类性能(表1):证明RFM作为探针优于线性探测和原始SYNTHEORY的FFN探针。
模型 音符 音程 音阶 和弦 进行 拍号 节拍 平均 MusicRFM (均值池化,本文) 0.850 0.975 0.956 0.984 0.943 0.900 0.985 0.942 RFM (最后词元) 0.734 0.743 0.546 0.866 0.811 0.771 0.959 0.776 Syntheory FFN 0.866 0.972 0.905 0.989 0.901 0.905 0.965 0.929 单方向控制(表2,核心结果):展示了控制系数
η_0与各指标的关系。以“音符”类别为例:方法 指标 η_0=0.15η_0=0.30η_0=0.45η_0=0.60MusicRFM-only 准确率↑ 0.231 0.461 0.684 0.824 CLAP↑ 0.315 0.311 0.318 0.303 Prompt+RFM 准确率↑ 0.657 0.826 0.921 0.952 CLAP↑ 0.343 0.325 0.321 0.329 Prompt-only基线 准确率↑ 0.436 (固定) CLAP↑ 0.342 (固定)
关键发现:增加η_0可显著提升控制准确率(音符从0.23到0.82),同时CLAP分数下降轻微(约0.02)。提示+RFM结合效果最佳。
外部评估(表4):使用色度图和和弦估计器验证控制有效性。RFM控制准确率随
η_0单调上升,且常优于提示基线。主观听感测试(表3):12名参与者评分显示,MusicRFM(最优配置)在音符、音程、和弦、节拍控制上的评分均显著高于无控制基线。
控制类型 无控制 朴素RFM MusicRFM (最优) 和弦 59.71 ± 6.01 69.21 ± 5.25 73.46 ± 4.18 音程 54.75 ± 5.52 62.58 ± 5.84 70.33 ± 4.02 音符 57.08 ± 6.37 68.13 ± 5.97 72.88 ± 5.67 节拍 55.75 ± 7.08 73.33 ± 4.35 73.38 ± 4.75 时间控制(图1a, 1b):探针softmax概率随时间调度函数(线性增加/衰减、正弦波等)精确变化,并展示了音符交叉淡化效果。
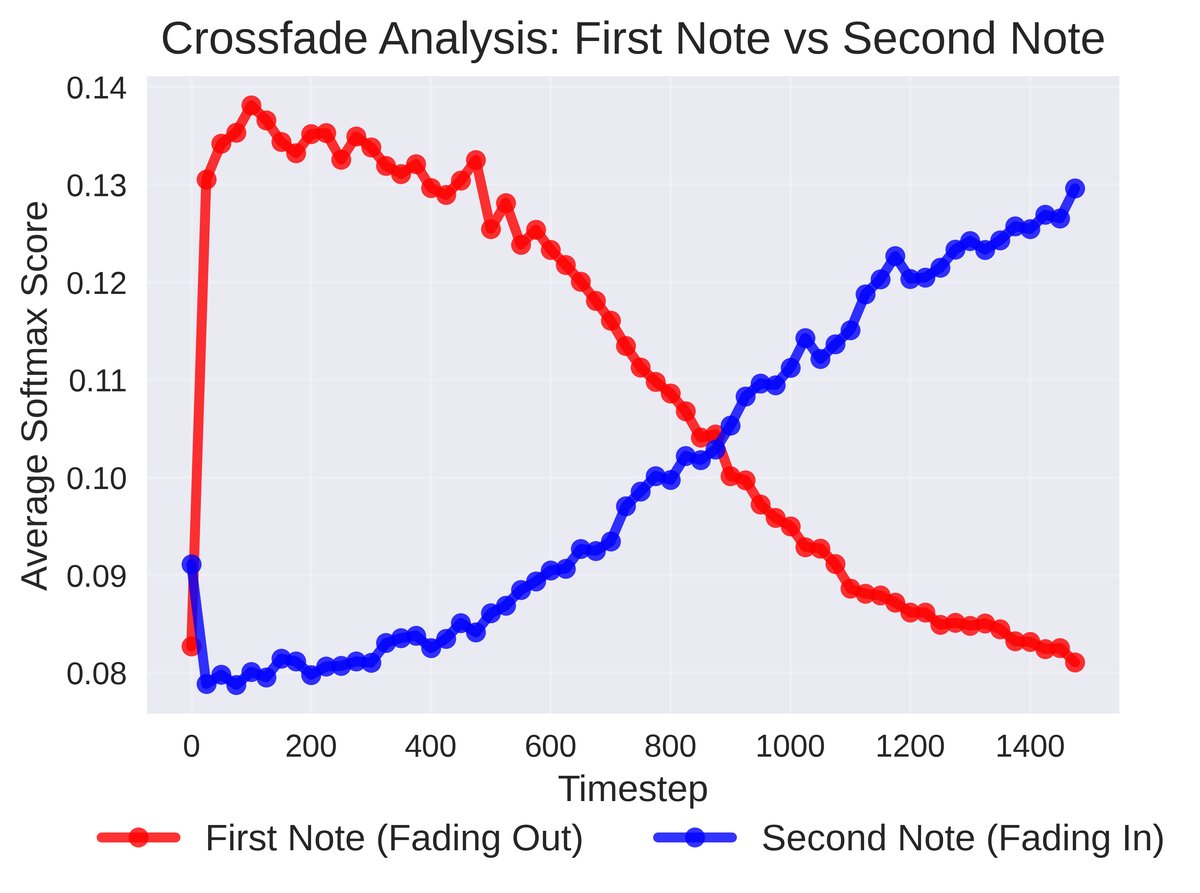 图1a:不同时间调度下,目标音符类别的探针预测概率随生成步数的变化,曲线与调度函数高度吻合。
图1a:不同时间调度下,目标音符类别的探针预测概率随生成步数的变化,曲线与调度函数高度吻合。
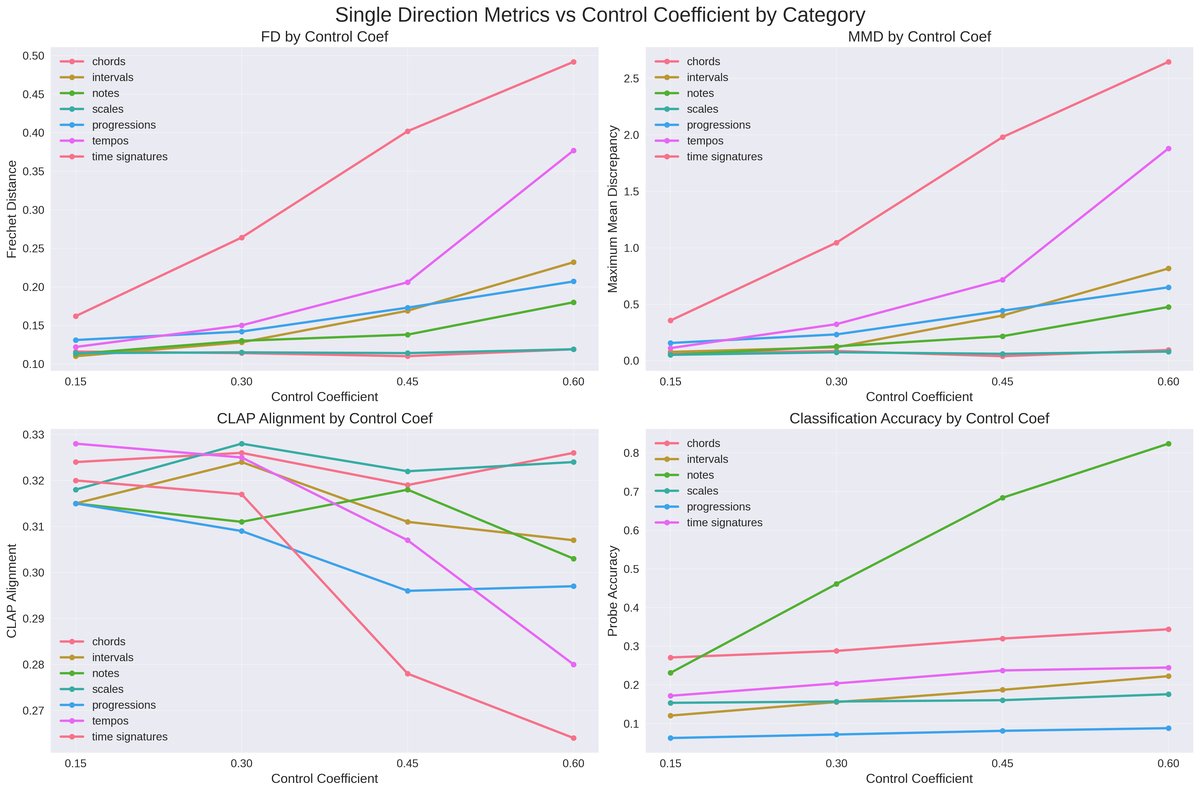 图1b:两个音符的交叉淡化实验,展示了概率此消彼长的过程。
图1b:两个音符的交叉淡化实验,展示了概率此消彼长的过程。多方向控制(表6):同时控制两个概念(如音符+和弦)时,控制强度增加仍能提升准确率,但FD、MMD和CLAP恶化更明显,表明多目标控制会放大分布漂移。
真实数据迁移(表5):在MUSICBENCH上,RFM控制表现出与合成数据一致的趋势,验证了方法的迁移性。
⚖️ 评分理由
- 学术质量 (6.0/7):
- 创新性 (好):将RFM系统性地适配到音乐生成控制,并设计了分层、时间、多方向等一整套实用机制,是该方法在音乐领域的首次成功应用。
- 技术正确性 (好):方法流程清晰,数学描述完整(如AGOP、激活注入公式),实验设计合理。
- 实验充分性 (优秀):实验非常全面,涵盖了探针性能、多种控制场景、定量指标(FD, MMD, CLAP)、主观测试和外部评估工具。
- 证据可信度 (好):关键结论(控制与保真的权衡)有大量表格数据和可视化图表支持,人耳测试也佐证了量化结果。
- 选题价值 (1.5/2):
- 前沿性:可控生成是当前AIGC领域的热点,该工作提供了一种新颖的、可解释的解决方案。
- 潜在影响与应用:为音乐人、游戏音频设计等提供了潜在的细粒度创作工具。其“免训练”的特性可能降低使用门槛。
- 读者相关性:对专注于音频/音乐生成、模型可解释性的读者有较高参考价值。
- 开源与复现加成 (0.5/1):
- 提供了GitHub代码仓库链接(
https://github.com/astradzhao/music-rfm),包含主要算法实现。 - 附录中详细给出了超参数搜索空间(表8)、训练细节和伪代码(算法1),便于复现核心实验。
- 但未提及是否公开预训练好的RFM探针权重,也未说明SYNTHEORY数据集的详细获取方式(可能需向原作者申请),这在一定程度上增加了完全复现的门槛。
- 提供了GitHub代码仓库链接(