📄 Stable Video Infinity: Infinite-Length Video Generation with Error Recycling
#视频生成 #流匹配 #数据增强 #多模态模型
🔥 8.8/10 | 前10% | #视频生成 | #数据增强 | #流匹配 #多模态模型
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Wuyang Li(EPFL VITA实验室)
- 通讯作者:Alexandre Alahi(EPFL VITA实验室)
- 作者列表:Wuyang Li(EPFL VITA实验室)、Wentao Pan(EPFL VITA实验室)、Po-Chien Luan(EPFL VITA实验室)、Yang Gao(EPFL VITA实验室)、Alexandre Alahi(EPFL VITA实验室)
💡 毒舌点评
亮点:论文将长视频生成的“误差累积”问题从现象层面(如何缓解)深刻剖析到根源层面(训练与推理的假设鸿沟),并巧妙地将模型的“弱点”(自身错误)转化为训练的“资源”(监督信号),这种“以毒攻毒”的闭环反馈思想极具启发性和理论美感。短板:论文的方法高度依赖于自回归的片段式生成范式,尽管声称“无限”,但其生成质量的长期稳定性(如分钟级甚至小时级)仍需更严苛的验证;此外,误差银行的记忆管理策略(如仅用L2距离替换)可能过于简单,或难以捕捉复杂多样的错误模式。
🔗 开源详情
- 代码:论文中未提及代码链接,但承���将公开“full codebase”。
- 模型权重:论文中提到将公开模型,但未提供具体链接或平台。
- 数据集:论文构建了新的基准数据集(一致、创造性、条件生成),并承诺将开源所有“benchmark datasets”。
- Demo:未提及在线演示。
- 复现材料:提供了非常详细的训练超参数(Tab. 12)、数据集描述、架构修改说明和消融实验设置,复现指南较为充分。
- 论文中引用的开源项目:依赖的基础模型为Wan 2.1,以及Kong et al. (2025)的音频交叉注意力、Wang et al. (2025b)的骨架注入方法。
📌 核心摘要
- 问题:现有长视频生成方法受限于误差累积(漂移),生成长度通常在10秒到1分钟左右。根本原因在于训练时假设历史轨迹无误差(误差自由假设),但自回归推理时却依赖自身含有误差的输出,造成训练-测试的假设鸿沟。
- 核心方法:提出Stable Video Infinity (SVI),其核心是误差回收微调(ERFT)。该方法打破误差自由假设,主动将模型自身生成的错误(误差)注入到干净输入中,训练模型预测一个指向干净目标的“误差回收速度”,从而让模型学会识别和纠正自身错误。
- 创新与差异:不同于以往通过修改噪声调度器、锚定参考帧或改进采样策略来缓解误差,SVI通过误差回收机制主动纠正误差本身。具体包括:(i) 在流匹配的起始、中间、终点注入三类误差来模拟累积退化;(ii) 通过单步双向积分高效计算误差;(iii) 设计误差重放缓存池,根据时间步动态存取和采样误差。
- 主要结果:在三个基准(一致性、创造性、条件生成)上均达到SOTA。在250秒超长一致性视频生成中,SVI-Shot的主体一致性达到97.89%,仅比短设置下降0.63%,而基线方法下降显著(如FramePack降13.71%)。在创造性视频生成中,SVI-Film能根据文本流生成平滑的场景切换,而基线方法失败。具体实验结果见下表:
模型 场景 主体一致性 背景一致性 美学质量 图像质量 一致视频生成 (50秒) Wan 2.1 单一 92.45% 56.40% 65.70% 12.68% FramePack 单一 94.72% 63.57% 66.72% 7.75% SVI-Shot (Ours) 单一 98.19% 63.84% 71.88% 17.61% 超长一致视频生成 (250秒) Wan 2.1 单一 87.27% 56.19% 65.37% 14.29% FramePack 单一 86.64% 55.66% 57.61% 0.00% SVI-Shot (Ours) 单一 97.89% 65.75% 71.54% 21.43% - 实际意义:首次实现了从“秒”到“无限”的非循环超长视频生成,突破了现有长度限制,为端到端长片创作、互动叙事和世界模型模拟开辟了新可能。
- 主要局限:当测试时图像风格与训练分布不符时,模型可能误将风格差异当作“错误”进行“纠正”,导致相邻片段颜色偏移;目前模型基于并行生成,尚未实现实时流式输出;在复杂多镜头创意生成中,长期身份一致性仍有挑战。
🏗️ 模型架构
SVI的核心架构是基于视频扩散Transformer (DiT),并通过误差回收微调(ERFT)进行增强,其主要流程如下:
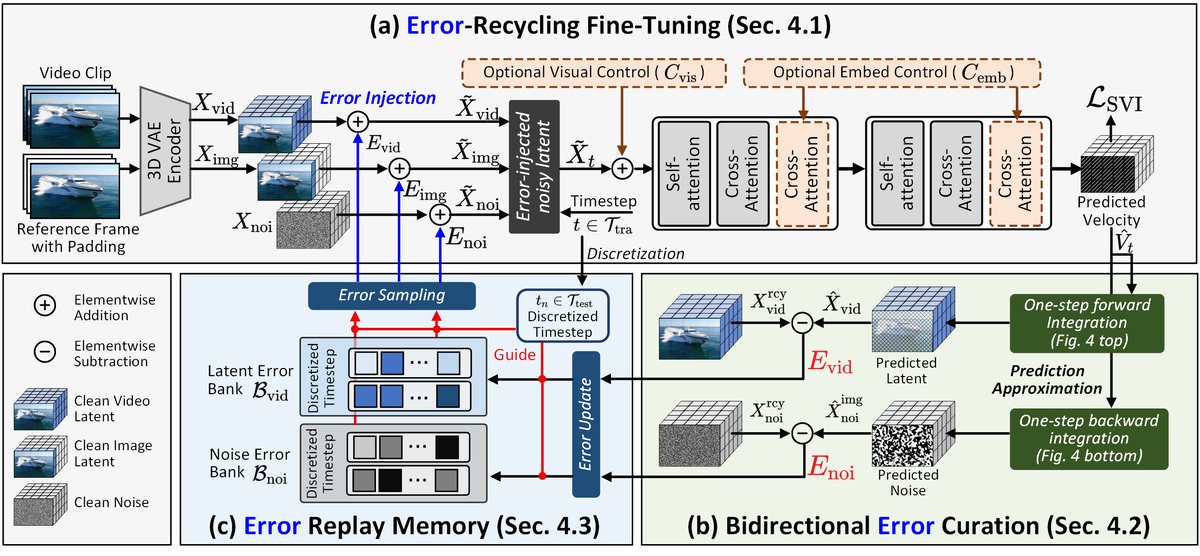 图3:Stable Video Infinity 的整体流程。 (a) 将误差注入干净输入以打破误差自由假设; (b) 通过单步积分双向近似预测并计算误差; (c) 从记忆库中动态存入和重采样误差,形成闭环循环。
图3:Stable Video Infinity 的整体流程。 (a) 将误差注入干净输入以打破误差自由假设; (b) 通过单步积分双向近似预测并计算误差; (c) 从记忆库中动态存入和重采样误差,形成闭环循环。
- 输入准备:对于一个干净视频片段
{I_i}_{vid},通过3D VAE编码得到视频潜在表示X_vid和参考图像潜在表示X_img。同时采样噪声X_noi和时间步t。 - 误差注入(核心模块):与传统方法不同,SVI从误差银行
B_vid,B_noi中采样历史误差E_vid,E_noi,E_img,并以一定概率(如p_vid=0.9, p_noi=0.01, p_img=0.9)注入到干净输入中,生成“带误差的”输入̃X_vid,̃X_noi,̃X_img。同时,为保持生成能力,也以概率p=0.5使用干净输入。最终输入为̃X_t = Concat(̃X_t, ̃X_img),其中̃X_t = t·̃X_vid + (1-t)·̃X_noi。 - 条件控制与预测:支持两种控制信号注入:(a) 视觉条件
C_vis(如骨架)通过token化的输入进行元素级加法注入;(b) 嵌入条件C_emb(如文本、音频)通过DiT块中的特定交叉注意力层注入。经过处理的̃X_t和C送入DiT预测速度̂V_t = u(̃X_t, ̃X_img, C, t; θ)。 - 误差计算与存储:根据
̂V_t,通过单步前向和后向积分,近似预测出退化的视频潜在̂X_vid和噪声̂X_img_noi。然后根据公式(4)计算出新的误差E_vid和E_noi。这些误差被存入动态的误差重放缓存池B_vid,n和B_noi,n(n为离散化时间步索引),池大小上限为Z=500,采用基于L2距离的替换策略以保持多样性。 - 优化目标:损失函数为公式(6),即预测的误差回收速度与指向干净目标的速度
V^rcy_t = X_vid - ̃X_noi之间的均方误差。训练仅更新LoRA适配器参数。
💡 核心创新点
- 重新定义问题根源:训练-测试假设鸿沟:首次系统性地指出并形式化了长视频生成误差累积的根本原因——训练时的“误差自由假设”与推理时“自回归误差条件”之间的矛盾。将误差分为“单片段预测误差”和“跨片段条件误差”,为解决问题提供了清晰的理论框架。
- 提出“误差回收微调”新范式:设计了闭环的误差循环利用机制。不再被动缓解误差,而是主动将模型自身产生的错误作为监督信号,训练模型在误差存在的情况下仍能预测指向正确目标的速度,从而“教会”模型自我纠错。
- 实现高效且通用的训练方案:仅通过轻量级的LoRA微调(数据量小,如6K视频),即可将长视频生成能力“注入”预训练的DiT模型。该方法兼容多种控制信号(文本、音频、骨架),实现了SVI-Shot、SVI-Film、SVI-Talk、SVI-Dance等模型变体,展示了强大的通用性和实用性。
🔬 细节详述
- 训练数据:SVI-Shot/Film使用MixKit数据集(6K视频);SVI-Talk使用Hallo3数据集(5K视频片段);SVI-Dance使用TikTok数据集。均仅训练10个epoch。
- 损失函数:核心是流匹配中的速度预测损失(公式6),目标是使模型在误差输入下预测出指向干净视频潜在
X_vid的速度V^rcy_t。 - 训练策略:使用Adam优化器,学习率
2e-5,梯度裁剪1.0,DeepSpeed Stage 2分布式训练,梯度检查点。 - 关键超参数:
- 模型基于Wan 2.1-I2V-14B-480P。
- LoRA:秩
128,Alpha128,应用于q,k,v,o,ffn.0,ffn.2模块。 - 误差注入:
p_vid=0.9,p_noi=0.01,p_img=0.9,干净输入概率p=0.5。 - 误差银行:时间步离散化网格数
50,每个网格最大容量Z=500。 - 生成参数:视频帧数
81,分辨率480x832,使用Tiled Inference。
- 训练硬件:在大型GH200集群上进行,具体数量和时长未说明。
- 推理细节:支持并行生成,但未提及流式生成设置。误差回收强度可通过调整LoRA alpha控制。
📊 实验结果
主要基准结果(来自Tab. 1):
| 模型 | 场景 | 主体一致性 | 背景一致性 | 美学质量 | 图像质量 | 动态程度 | 运动平滑度 |
|---|---|---|---|---|---|---|---|
| 一致视频生成 (单提示词,无场景切换,~50秒) | |||||||
| Wan 2.1 | 单一 | 92.45% | 56.40% | 65.70% | 12.68% | 98.51% | - |
| StreamingT2V | 单一 | 89.27% | 56.81% | 66.41% | 57.04% | 99.00% | - |
| FramePack | 单一 | 94.72% | 63.57% | 66.72% | 7.75% | 99.57% | - |
| SVI-Shot (Ours) | 单一 | 98.19% | 63.84% | 71.88% | 17.61% | 98.93% | - |
| 超长一致视频生成 (单提示词,无场景切换,~250秒) | |||||||
| Wan 2.1 | 单一 | 87.27% | 56.19% | 65.37% | 14.29% | 98.74% | - |
| StreamingT2V | 单一 | 77.62% | 40.49% | 55.18% | 85.71% | 95.60% | - |
| FramePack | 单一 | 86.64% | 55.66% | 57.61% | 0.00% | 99.63% | - |
| SVI-Shot (Ours) | 单一 | 97.89% | 65.75% | 71.54% | 21.43% | 98.81% | - |
| 创造性视频生成 (提示词流,有场景切换,~50秒) | |||||||
| Wan 2.1 | 多重 | 89.81% | 51.33% | 53.09% | 61.97% | 98.57% | - |
| SVI-Film (Ours) | 多重 | 90.85% | 55.25% | 59.97% | 62.68% | 98.69% | - |
| FramePack | 单一 | 91.22% | 59.41% | 59.44% | 9.15% | 99.49% | - |
消融实验(来自Tab. 4):
| 方法 | 主体一致性 | 背景一致性 | 美学质量 | 图像质量 |
|---|---|---|---|---|
| Wan 2.1 (基线) | 82.83% | 43.95% | 42.31% | - |
| SVI w/o E_img | 84.21% | 49.58% | 57.63% | - |
| SVI w/o E_noi | 94.87% | 59.80% | 69.90% | - |
| SVI w/o E_vid | 95.01% | 58.99% | 71.50% | - |
| SVI full | 95.39% | 61.88% | 71.22% | - |
结论:1)SVI在所有一致性、质量和美学指标上全面超越现有方法;2)在超长设置下,SVI性能下降极小(主体一致性-0.63%),而其他方法大幅下降;3)消融实验表明,图像误差E_img的注入最为关键,移除它会导致性能显著下降,验证了干预轨迹起始点以模拟误差累积的重要性。
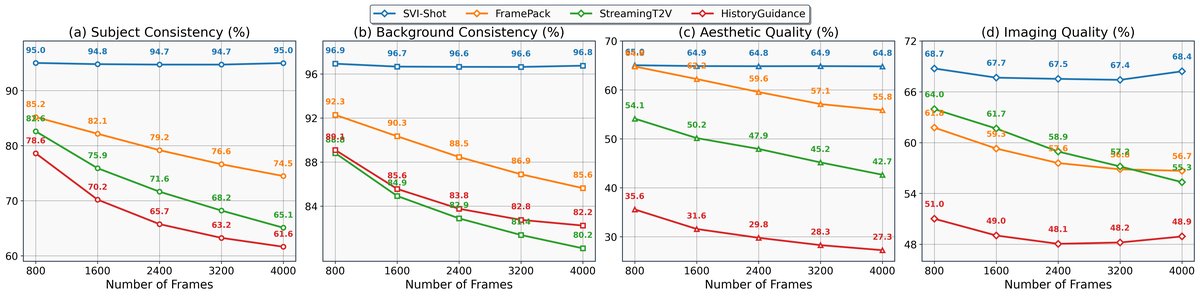 图5:不同视频长度下的稳定性对比。SVI(蓝色实线)在长度增加时,主体一致性和背景一致性保持稳定,而其他方法(如FramePack,橙色虚线)呈现下降趋势。
图5:不同视频长度下的稳定性对比。SVI(蓝色实线)在长度增加时,主体一致性和背景一致性保持稳定,而其他方法(如FramePack,橙色虚线)呈现下降趋势。
 图7:定性对比。(a) 创造性视频生成:SVI-Film能根据提示词流实现平滑场景转换,而其他方法失败。(b) 一致视频生成:SVI-Shot保持高保真度和连贯性,其他方法出现颜色偏移和退化。(c) 多模态条件生成:SVI-Talk和SVI-Dance能稳定生成超长对话和舞蹈视频。
图7:定性对比。(a) 创造性视频生成:SVI-Film能根据提示词流实现平滑场景转换,而其他方法失败。(b) 一致视频生成:SVI-Shot保持高保真度和连贯性,其他方法出现颜色偏移和退化。(c) 多模态条件生成:SVI-Talk和SVI-Dance能稳定生成超长对话和舞蹈视频。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了深刻的理论洞见(假设鸿沟),并设计了逻辑自洽、工程可行的解决方案(ERFT)。实验全面覆盖了长视频生成的多个关键场景,设置了新颖的“创意生成”基准,并进行了充分的消融研究。主要技术正确性高,证据可信。稍逊之处在于部分超参数选择的理论依据可进一步加强。
- 选题价值:1.8/2:长视频生成是生成式AI的关键挑战和前沿方向。论文的工作直接瞄准该领域的核心痛点,其“主动纠错”的思路具有范式创新意义,潜在应用价值巨大(影视、游戏、模拟)。与音频/语音读者的直接相关性不高,但其方法论可能对其他序列生成任务有启发。
- 开源与复现加成:+0.5/1:论文承诺开源所有资源,提供了极其详尽的实现细节表格(Tab. 12),包括数据、超参数、训练策略,复现基础很好。但代码和权重尚未发布,因此加成有限。