📄 SpeechJudge: Towards Human-Level Judgment for Speech Naturalness
#模型评估 #强化学习 #奖励模型 #大语言模型 #语音合成
🔥 8.0/10 | 前25% | #模型评估 | #强化学习 | #奖励模型 #大语言模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Xueyao Zhang(香港中文大学(深圳))
- 通讯作者:Zhizheng Wu(香港中文大学(深圳)、深圳湾区研究院、澳门城市大学、Amphion Technology Co., Ltd)
- 作者列表:
- Xueyao Zhang(香港中文大学(深圳))
- Chaoren Wang(香港中文大学(深圳))
- Huan Liao(香港中文大学(深圳))
- Ziniu Li(香港中文大学(深圳))
- Yuancheng Wang(香港中文大学(深圳))
- Li Wang(香港中文大学(深圳))
- Dongya Jia(字节跳动 Seed)
- Yuanzhe Chen(字节跳动 Seed)
- Xiulin Li(DataBaker Technology)
- Zhuo Chen(字节跳动 Seed)
- Zhizheng Wu(香港中文大学(深圳)、深圳湾区研究院、澳门城市大学、Amphion Technology Co., Ltd)
💡 毒舌点评
亮点:工作非常“接地气”且系统,从最基础的“数据集-基准-模型”三位一体入手,解决了语音合成对齐中缺乏大规模人类偏好数据的关键瓶颈,且承诺全部开源,这对领域发展是扎实的贡献。 短板:核心的奖励模型训练依赖闭源的Gemini-2.5-Flash生成CoT数据进行“冷启动”,其“教学”质量直接决定了“学生”GRM的上限,这使得方法的独立性和可复现性打了点折扣;同时,数据集的语言(中英)和风格覆盖仍有明显局限。
🔗 开源详情
- 代码:论文明确承诺将开源,代码仓库链接为
https://github.com/AmphionTeam/SpeechJudge。 - 模型权重:论文明确承诺将发布训练好的SpeechJudge-GRM模型检查点。
- 数据集:论文明确承诺将公开SpeechJudge-Data数据集。
- Demo:论文提供了音频样本的在线演示网站
https://speechjudge.github.io/。 - 复现材料:论文在正文中描述了数据集构建协议,并在附录F中提供了详尽的SFT和RL训练细节(学习率、优化器、LoRA秩、batch size等)。
- 论文中引用的开源项目:
- 基础模型:Qwen2.5-Omni-7B
- 教师模型(API调用):Gemini-2.5-Flash
- 训练工具包:ms-swift
- TTS模型(用于生成数据):CosyVoice2, F5-TTS, MaskGCT等
- 评估工具:Whisper, Paraformer, WavLM, UTMOS, AASIST等
📌 核心摘要
- 问题:语音合成领域缺乏大规模、以“自然度”为核心的人类偏好反馈数据集,这严重阻碍了能真正与人类感知对齐的模型的开发与评估。
- 方法:本文提出了SpeechJudge套件,包含三部分:a) SpeechJudge-Data:使用多种先进零样本TTS模型生成语音对,并由人工标注可懂度与自然度偏好,构建了99K对的大规模数据集。b) SpeechJudge-Eval:从数据集中筛选高质量样本构成基准,用于评估模型判断语音自然度的能力。c) SpeechJudge-GRM:一个基于Qwen2.5-Omni-7B的生成式奖励模型,通过两阶段后训练(监督微调+基于人类偏好的强化学习)来提升自然度判断能力。
- 创新性:与先前工作相比,a) 首次构建了大规模、多风格、多语言、以自然度为核心的人类偏好数据集;b) 提出了具有挑战性的自动化评估基准,并揭示了当前最佳AudioLLM(Gemini-2.5-Flash)的一致性不足70%;c) 提出的GRM模型结合了链式思维推理和推理时缩放,在性能上显著优于经典的Bradley-Terry奖励模型。
- 主要实验结果:
- SpeechJudge-Eval基准测试:现有指标和模型表现不佳,最强闭源模型Gemini-2.5-Flash准确率为69.1%。
- SpeechJudge-GRM性能:经两阶段训练后,准确率达77.2%;使用推理时缩放(Voting@10)后,进一步提升至79.4%(表3)。
- 下游应用:作为奖励模型用于语音合成模型的后训练,能有效提升生成语音的自然度(图6);用于样本选择时,优于BTRM基线(图5)。
- 实际意义:为语音合成的对齐与评估提供了关键基础设施(数据与基准),并证明了一个更优的奖励模型可以用于改进语音生成模型本身,形成“评估促进生成”的闭环。
- 主要局限性:数据集和标注者群体主要集中于中英双语,对其他语言和文化背景的覆盖不足;奖励模型的能力依赖于闭源教师模型(Gemini)生成的训练数据;模型在处理极端表达风格或细微自然度差异时仍有错误。
🏗️ 模型架构
SpeechJudge-GRM是一个生成式奖励模型(Generative Reward Model, GRM),其核心是一个经过专门微调的音频-文本多模态大语言模型。
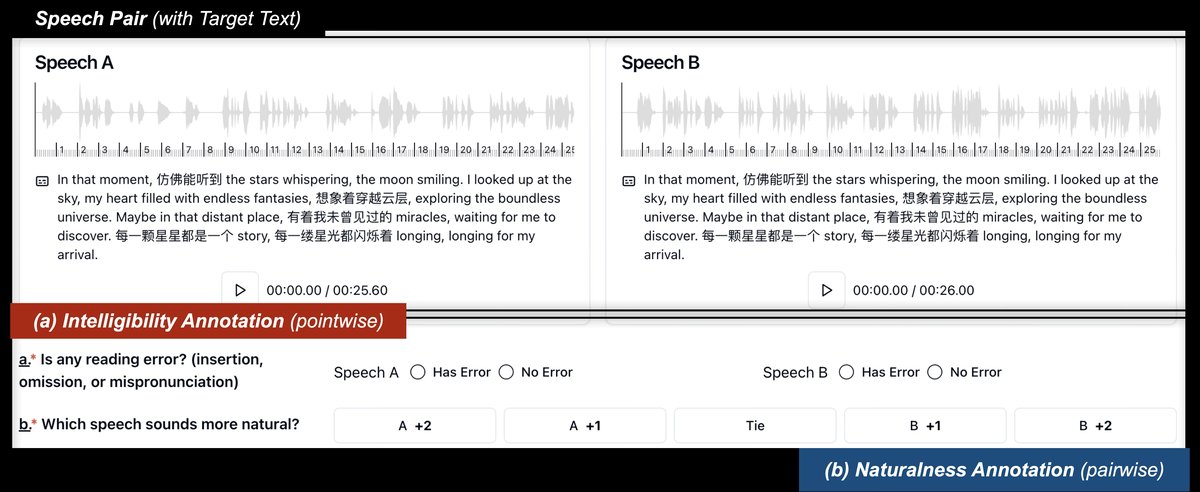 图1:数据集构建与任务示意。 左侧展示了数据集构建流程:使用多种TTS模型基于参考语音和目标文本生成语音对,人工标注进行可懂度(点式标注)和自然度(成对偏好)评估。右侧展示了GRM的任务:输入目标文本和两个音频,通过链式思维推理,输出自然度判断。
图1:数据集构建与任务示意。 左侧展示了数据集构建流程:使用多种TTS模型基于参考语音和目标文本生成语音对,人工标注进行可懂度(点式标注)和自然度(成对偏好)评估。右侧展示了GRM的任务:输入目标文本和两个音频,通过链式思维推理,输出自然度判断。
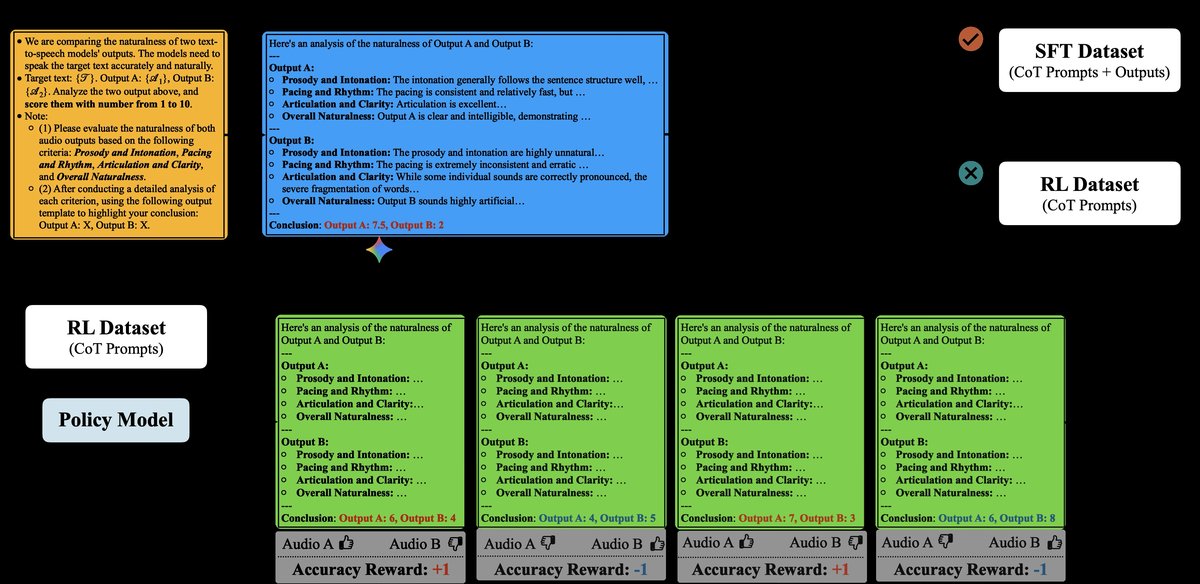 图2:数据集分布。 展示了数据集在(a) TTS模型、(b) 参考语音来源、(c) 语言设置上的分布,体现了多样性。
图2:数据集分布。 展示了数据集在(a) TTS模型、(b) 参考语音来源、(c) 语言设置上的分布,体现了多样性。
完整输入输出流程:
- 输入:一个文本字符串
t(目标句子)和两个音频片段a1,a2(由不同TTS模型生成的合成语音)。 - 处理流程:
- 输入被构造成一个包含任务指令和要求的提示(Prompt),该指令要求模型分析两个音频在韵律、节奏、发音清晰度和整体自然度方面的表现,并给出评分(1-10分)。
- 模型(Qwen2.5-Omni-7B)对输入进行处理,利用其多模态理解能力同时处理文本和两个音频。
- 模型进行链式思维(Chain-of-Thought, CoT)推理,生成一段解释其判断理由的文本。
- 最终,从模型输出的推理文本中解析出自然度偏好判断(
a1更好或a2更好)。
- 输出:一个自然语言推理过程(可选,用于可解释性)和一个二元偏好判断结果。
主要组件与训练阶段:
- 基础模型:Qwen2.5-Omni-7B(Thinker),一个开源的音频-文本多模态大语言模型,具备处理音频和文本的能力。
- SFT阶段(冷启动):
- 目标:提升模型的指令遵循、推理和语音自然度理解能力。
- 数据:使用Gemini-2.5-Flash(闭源模型)作为教师,为训练集中的样本生成CoT推理数据。选取教师判断与人类一致的数据(约25K样本)作为SFT数据。
- 训练:对Qwen2.5-Omni-7B进行LoRA微调,训练时仅计算生成部分(CoT推理)的损失。
- RL阶段:
- 目标:利用更难的样本(教师判断与人类不一致的约17K样本)进一步优化模型。
- 奖励:将人类标注的偏好视为可验证奖励(Verifiable Reward)。对于模型生成的判断,奖励为+1(与人类一致)或-1(不一致)。
- 算法:采用GRPO(一种简化的PPO变体)算法,基于SFT后的模型进行强化学习训练。
💡 核心创新点
大规模、高质量的语音自然度人类偏好数据集(SpeechJudge-Data):
- 之前局限:现有语音MOS数据集规模小、使用旧模型生成、缺乏直接的成对偏好标注,且很少专注于“自然度”这一整体性指标。
- 如何起作用:使用多种先进TTS模型(6种不同架构)生成语音,覆盖多种风格(常规、情感、口音、耳语、游戏角色)、语言(中、英、混合)和语音对类型(模型内、模型间)。由69名专业标注员进行可懂度点标注和自然度成对偏好标注,获得99K对数据,平均每对2.49个标注。
- 收益:提供了该领域迄今最大规模、最多样的自然度偏好语料库,为后续研究和模型训练奠定了基础。
具有挑战性的语音自然度判断基准(SpeechJudge-Eval):
- 之前局限:缺乏统一的、高质量的自动化评估基准来衡量模型判断语音自然度的能力。
- 如何起作用:从数据集中筛选出人类标注者达成完全一致的高质量样本(1000对),作为黄金标准测试集。
- 收益:揭示了当前尖端模型(如Gemini-2.5-Flash)在该任务上的性能天花板(<70%准确率),明确了研究差距,为后续工作提供了明确的评估标尺。
两阶段训练的生成式奖励模型(SpeechJudge-GRM):
- 之前局限:传统的Bradley-Terry奖励模型(BTRM)是判别式的,不输出解释,且推理时无法缩放;直接使用AudioLLM进行零样本判断性能不足。
- 如何起作用:提出“SFT+RL”的两阶段训练范式。SFT阶段利用教师模型的CoT数据教会模型如何“思考和解释”;RL阶段在困难样本上,以人类偏好为奖励信号,直接优化模型的最终判断准确性。
- 收益:GRM不仅判断准确率(77.2%)显著高于BTRM(72.7%),还能输出推理过程增强可解释性,并支持通过多次采样投票(Voting@10)进一步提升性能(79.4%),展示了生成式奖励模型的优势。
🔬 细节详述
- 训练数据:
- 来源:SpeechJudge-Data (train),包含约42K个语音对及其人类偏好标签,是从99K原始数据中经过过滤(去除完全分歧样本、Tie样本,控制WER差异)得到的。
- 预处理:对于SFT数据,使用Gemini-2.5-Flash生成CoT推理文本,并将人类标签与之对齐。对于RL数据,仅使用提示(Prompt)和人类标签。
- 损失函数:
- SFT阶段:标准的语言模型下一个token预测损失(交叉熵),但仅在模型输出的CoT推理部分计算损失。
- RL阶段:基于GRPO算法的损失函数,其核心是最大化策略模型在给定提示下生成获得更高奖励(+1)的响应的概率。奖励函数是二元的(正确+1,错误-1)。
- 训练策略:
- SFT:使用AdamW优化器,学习率
5e-5。使用LoRA进行参数高效微调,LoRA秩为128。最大batch token数为4000。 - RL (GRPO):使用DAPO(GRPO的增强变体)进行训练。学习率
5e-6。LoRA秩为64。每个提示的rollout数(生成数量)为8,batch size为32。
- SFT:使用AdamW优化器,学习率
- 关键超参数:
- 模型大小:基于7B参数的Qwen2.5-Omni-7B。
- LoRA秩:SFT阶段128,RL阶段64。
- 训练硬件:论文中未具体说明GPU型号、数量及训练时长。
- 推理细节:
- 解码策略:标准解码(论文未指定具体温度、top-p等)。
- 推理时缩放:支持通过多数投票提升性能,即对一个输入生成10次输出,取其中多数判断作为最终结果(Voting@10)。
- 正则化或稳定训练技巧:论文中未明确说明。
📊 实验结果
- 基准测试(SpeechJudge-Eval)结果 论文在SpeechJudge-Eval上评估了各类模型,结果如下表所示:
| 模型类型 | 模型名称 | Regular (准确率%) | Expressive (准确率%) | Total (准确率%) |
|---|---|---|---|---|
| 客观指标 | WER | 59.3 | 57.0 | 57.9 |
| SIM | 47.5 | 42.5 | 44.5 | |
| FAD | 50.3 | 47.5 | 48.6 | |
| MOS预测器 | DNSMOS | 61.0 | 55.8 | 57.9 |
| UTMOS | 54.0 | 53.5 | 53.7 | |
| 深度伪造检测器 | AASIST | 40.5 | 50.8 | 46.7 |
| ADV | 35.3 | 40.3 | 38.3 | |
| AudioLLMs (开源) | Qwen2.5-Omni-7B | 62.0 | 59.7 | 60.6 |
| Kimi-Audio-7B-Instruct | 65.5 | 68.0 | 67.0 | |
| AudioLLMs (闭源) | Gemini-2.5-Flash | 73.5 | 66.2 | 69.1 |
| GPT-4o Audio | 71.5 | 64.7 | 67.4 |
结论:现有最佳模型(Gemini-2.5-Flash)准确率不足70%,表明语音自然度判断是极具挑战的任务。传统指标(WER, FAD等)和深度伪造检测器在此任务上关联性很弱。
- SpeechJudge-GRM性能对比 论文将GRM与基线BTRM和教师模型进行了对比:
| 模型 | Regular | Expressive | Total |
|---|---|---|---|
| Gemini-2.5-Flash | 73.5 | 66.2 | 69.1 |
| SpeechJudge-BTRM | 77.5 | 69.5 | 72.7 |
| SpeechJudge-GRM (SFT) | 77.8 | 73.7 | 75.3 |
| SpeechJudge-GRM (SFT) w/ Voting@10 | 77.4 | 77.6 | 77.6 |
| SpeechJudge-GRM (SFT+RL) | 79.0 | 76.0 | 77.2 |
| SpeechJudge-GRM (SFT+RL) w/ Voting@10 | 80.5 | 78.7 | 79.4 |
结论:GRM在相同训练数据上显著优于BTRM(77.2% vs 72.7%)。SFT+RL两阶段训练有效提升了性能,且推理时缩放(Voting@10)能带来约2个百分点的额外增益。
- 分布外(OOD)测试:人类语音 vs TTS克隆 论文额外测试了模型在区分真实人类录音和高质量语音克隆(SeedTTS)时的表现:
| 模型 | Character1 | Character2 | Avg |
|---|---|---|---|
| AASIST | 97.2 | 100 | 98.6 |
| Kimi-Audio-7B-Instruct | 85.2 | 85.6 | 85.4 |
| SpeechJudge-BTRM | 55.6 | 45.2 | 50.4 |
| SpeechJudge-GRM (SFT+RL) | 57.6 | 67.2 | 62.4 |
| SpeechJudge-GRM (SFT+RL) w/ Voting@10 | 59.8 | 67.5 | 63.7 |
结论:专门训练用于区分“合成vs合成”的自然度奖励模型,在区分“合成vs真实”的任务上性能有限,但比BTRM基线更好。这表明不同的判断任务需要不同的专门模型。
- 下游应用:语音合成模型后训练
使用Qwen2.5-0.5B-TTS作为基础模型,对比了不同对齐方法的效果:
图6:使用SpeechJudge进行后训练的效果。 (a) 显示文本准确率和自然度CMOS分数。(b) 显示说话人相似度的胜/负/平比例。
结论:使用SpeechJudge-GRM作为奖励模型(无论是离线标注还是在线RL)进行后训练,在提升自然度的同时,保持或略微提升了说话人相似度。GRM-based方法在自然度提升上优于仅使用现有数据(INTP)的方法。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作系统、完整且扎实。它没有提出颠覆性的新模型架构,而是精心构建了该领域的关键基础设施(数据集、基准),并基于现有强大基座模型,通过有效的训练范式(SFT+RL)训练出了一个性能优越的专用模型。实验设计全面,消融清晰(SFT vs SFT+RL,BTRM vs GRM,支持Voting),并探索了下游应用,证据可信。主要扣分点在于GRM训练过程中对闭源教师模型(Gemini)的依赖。
- 选题价值:1.5/2:语音自然度判断是语音合成评估与对齐的基石问题。本文工作直接针对这一核心痛点,提供了大规模资源和性能更优的解决方案,对推动语音合成系统向人类水平发展有明确价值。选题重要且应用空间明确。
- 开源与复现加成:1.0/1:论文承诺开源所有资源(数据、基准、模型、代码),并提供了极其详尽的训练细节、超参数和复现步骤(附录F)。这对于社区后续研究和应用是巨大的促进,复现门槛低,加成满分。