📄 SCRAPL: Scattering Transform with Random Paths for Machine Learning
#音频生成 #信号处理 #时频分析
🔥 8.5/10 | 前25% | #音频生成 | #信号处理 | #时频分析
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Christopher Mitcheltree(Queen Mary University of London, Centre for Digital Music)
- 通讯作者:未说明(从邮箱推测可能与通讯作者单位一致,但未在文中明确标注)
- 作者列表:Christopher Mitcheltree(Queen Mary University of London, Centre for Digital Music)、Vincent Lostanlen(Nantes Université, LS2N)、Emmanouil Benetos(Queen Mary University of London, Centre for Digital Music)、Mathieu Lagrange(Nantes Université, LS2N)
💡 毒舌点评
亮点:本文提出SCRAPL算法,巧妙地利用散射变换的树状结构,通过随机路径采样和定制化优化器(P-Adam, P-SAGA),将计算成本高昂的全树散射变换损失,成功转化为一种高效且无偏的随机近似,为在大规模神经网络训练中使用复杂感知损失扫清了障碍。 短板:该方法本质上是一种采样近似,在最终精度上(如表1所示)依然无法超越计算成本高得多的全树散射变换(JTFS),且在处理信号衰减部分(如表9所示)时表现不佳,表明其对稀疏低频路径的捕捉能力有待加强。
🔗 开源详情
- 代码:论文明确提供了代码和Python包的链接:https://christhetree.github.io/scrapl/。
- 模型权重:论文中未明确提及是否公开了训练好的编码器模型权重。
- 数据集:论文使用了公共音频样本集(
samplesfrommars.com的TR-808样本),并提供了用于生成训练数据的合成器配置。 - Demo:提供了音频示例供聆听评估。
- 复现材料:附录E详细列出了所有三个实验的超参数和训练细节,提供了配置文件和复现说明。
- 引用的开源项目:论文依赖/引用了
nnAudio(CQT计算)、auraloss(部分损失函数基线)、pytorch-hessian-eigenthings(用于θ-IS的海森特征值计算)。
📌 核心摘要
- 要解决的问题:散射变换(尤其是JTFS)作为损失函数能提供与人类感知高度相关的梯度,但其完整的树状结构计算成本极高,内存占用大,严重阻碍了它在神经网络训练中的实际应用。
- 方法核心:提出SCRAPL算法,其核心是在每次优化迭代中随机采样一条散射路径来近似全树散射变换的梯度。为稳定这一随机近似过程,作者提出了三项关键技术:1) 路径自适应矩估计(P-Adam);2) 路径级随机平均梯度加速法(P-SAGA);3) 基于合成器参数重要性的路径采样(θ-importance sampling)。
- 与已有方法相比新在哪里:与全树计算或路径剪枝(如pGST)不同,SCRAPL进行的是单路径随机采样,并通过专门的优化技术来控制方差。此外,θ-importance sampling是一个创新的初始化启发式方法,能根据任务自适应调整路径采样概率。
- 主要实验结果:在非确定性合成器(颗粒合成、chirplet合成、TR-808鼓机)的无监督声音匹配任务上,SCRAPL实现了计算效率与精度的良好平衡。例如,在颗粒合成任务中(图1,表1),SCRAPL的参数误差(65.7‰)比全树JTFS(42.4‰)略高,但计算成本仅为JTFS的约1/4(图1横轴),同时远优于多种多尺度谱损失(MSS)方法(误差在195‰-370‰)。
- 实际意义:使散射变换这类具有强感知先验的损失函数能够用于训练大规模音频模型(如DDSP),特别是在处理非确定性、有时间不对齐的音频合成任务时,提供了优于传统谱损失的梯度信号。
- 主要局限性:SCRAPL的精度上限受限于全树散射变换;对于信号中能量较低、路径稀疏的成分(如鼓声的衰减部分),其优化效果不佳(表9);θ-importance sampling启发式方法目前仅适用于可微分信号处理(DDSP)框架。
🏗️ 模型架构
SCRAPL并非一个神经网络模型,而是一个随机优化算法框架,用于高效计算散射变换损失。其核心流程如下:
- 输入:一个参考音频信号
x,一个自编码器F(由编码器Ex和解码器/合成器D组成),以及预定义的散射变换Φ。 - 随机路径采样:在每次迭代中,根据分布
π(可以是均匀分布或θ-importance sampling分布)从P条可能的散射路径中随机采样一条路径p。 - 计算单路径损失与梯度:计算仅针对路径
p的散射损失L_φp_x的梯度g = ∇(L_φp_x ∘ F)(w)。 - P-Adam更新:将梯度
g输入P-Adam优化器。P-Adam为每条路径维护独立的一阶矩估计mp和二阶矩估计vp,并根据路径p上次被采样的时间(k - τp)/P来调整衰减系数,从而实现对非独立同分布梯度的平滑。 - P-SAGA更新:维护一个访问过的路径集合
Γ及其对应的更新梯度历史ĝγ。P-SAGA利用这些历史信息对当前梯度进行修正:g_SAGA = g_current - ĝp + g_avg,其中g_avg是历史梯度的平均值。此步骤旨在降低方差,加速收敛。 - 权重更新:使用修正后的梯度
g_SAGA和学习率αk更新网络权重w。 - θ-importance sampling初始化(可选):在训练开始前,通过分析损失函数相对于合成器参数
θ的曲率(海森矩阵最大特征值),为每条路径p计算一个采样概率πp。这使得梯度信号能更集中地作用于对最终参数估计最重要的路径。
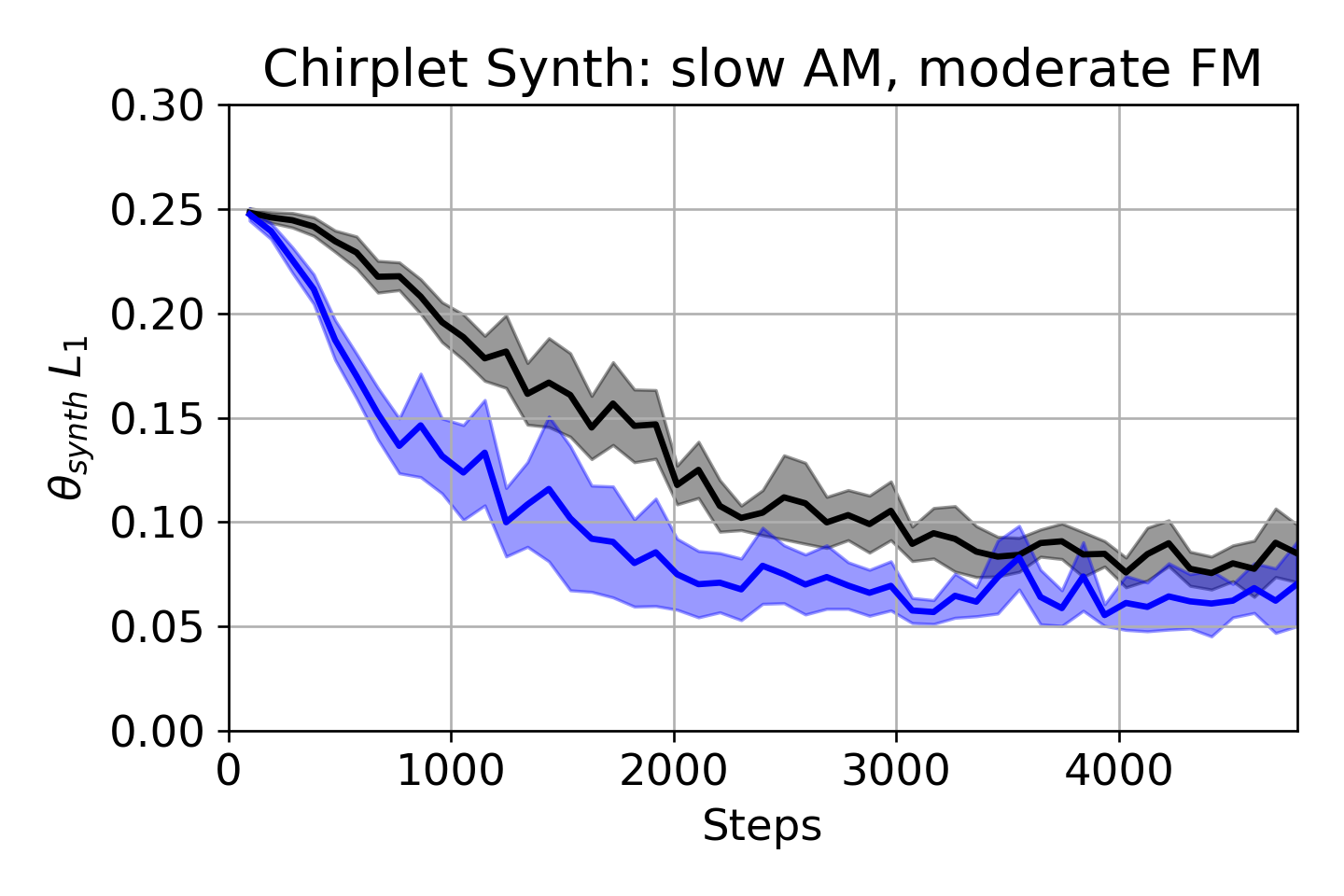 图1: SCRAPL算法伪代码(Algorithm 1)。清晰展示了随机路径采样(draw an integer… according to π)、P-Adam和P-SAGA的交替更新过程。
图1: SCRAPL算法伪代码(Algorithm 1)。清晰展示了随机路径采样(draw an integer… according to π)、P-Adam和P-SAGA的交替更新过程。
💡 核心创新点
- 随机路径采样近似:将计算所有
P条路径的损失梯度,简化为每次迭代随机计算一条路径的梯度。这直接将每次迭代的计算复杂度从O(P)降至O(1),是效率提升的根本。 - 路径自适应优化器(P-Adam & P-SAGA):针对随机采样梯度非独立同分布的特性,提出了两个定制优化器。P-Adam解决了不同路径梯度统计特性不同的问题;P-SAGA通过引入历史梯度记忆,有效降低了单路径梯度估计的方差,二者结合显著提升了收敛稳定性和速度。
- θ-importance sampling:为可微数字信号处理(DDSP)任务设计了一种架构感知的路径采样分布初始化方法。它通过分析合成器参数空间与散射路径空间的敏感度关系,预先计算出更能反映参数
θ变化的路径,使训练初期的梯度信号更有效。 - 理论支撑:论文证明了(命题3.1)在均匀采样下,SCRAPL梯度是全树散射梯度的无偏估计,为该方法的合理性提供了理论保证。
🔬 细节详述
- 训练数据:
- 颗粒合成:5120个样本(60%/20%/20%划分)。
- Chirplet合成:5120个样本(60%/20%/20%划分)。
- TR-808:681个真实鼓机采样(来自
samplesfrommars.com),训练/验证/测试集约425/128/128。 - 数据增强:论文未明确提及特定数据增强方法。
- 损失函数:核心损失是基于散射系数的均方误差。具体形式为
L_Φ_x(˜x) = 1/P * Σ_p ||φp(x) - φp(˜x)||²。SCRAPL在训练中仅计算随机采样路径p对应的损失L_φp_x(˜x) = ||φp(x) - φp(˜x)||²。评估时使用全树散射损失(JTFS Loss)和参数L1损失(P-Loss)。 - 训练策略:
- 优化器:Adam (β1=0.9, β2=0.999, weight decay=0.01)。SCRAPL的P-Adam在其基础上增加了路径级动量。
- 学习率:颗粒和Chirplet实验为固定学习率(1e-5 或 1e-4);TR-808实验从1e-4线性衰减至1e-5。
- Batch size:颗粒/Chirplet为32;TR-808为8。
- 训练轮数:颗粒/Chirplet为200/50个epoch;TR-808为50个epoch。
- 关键超参数:
- 散射变换参数:
J=12, Q1=8, Q2=2(时间层),Jfr=3/5, Qfr=2(频率层),T=4096/2048(时间窗),F=1/8(频率归一化),路径数P=315/483。 - θ-importance sampling:使用
N_IS个样本(16-320)预计算采样分布π,并通过幂迭代法(最多20步)近似最大特征值。
- 散射变换参数:
- 训练硬件:实验在单卡 NVIDIA RTX A5000 GPU 上进行。训练时长未在主文中详细说明,但图2显示了基于墙钟时间的对比。
- 推理细节:解码器是预定义的、非学习性的合成器(颗粒合成器、Chirplet合成器、TR-808 DDSP合成器)。编码器是轻量级CNN,输出合成器参数
θ。 - 正则化技巧:使用了Dropout(概率0.25-0.5),并在SCRAPL算法中内置了P-SAGA作为方差减少技术。
📊 实验结果
论文在三个任务上验证了SCRAPL的有效性,关键结果如下:
表1:无监督颗粒合成声音匹配任务结果(θsynth L1相对误差 ‰↓)
| 方法 | θsynth L1 ‰ ↓ | θdensity L1 ‰ ↓ | θslope L1 ‰ ↓ |
|---|---|---|---|
| JTFS | 42.4 | 65.8 | 19.0 |
| SCRAPL | 65.7 ± 4.2 | 72.6 ± 6.3 | 58.7 ± 7.5 |
| MSS Linear | 370 ± 0.52 | 499 ± 0.84 | 241 ± 0.28 |
| MS-CLAP | 166 ± 8.2 | 81.9 ± 9.0 | 250 ± 8.2 |
| PANNs | 159 ± 4.4 | 80.3 ± 4.2 | 238 ± 5.5 |
| P-loss (监督) | 20.5 ± 0.20 | 24.7 ± 0.31 | 16.3 ± 0.31 |
结论:SCRAPL在精度上显著优于所有MSS变体和预训练嵌入损失(MS-CLAP, PANNs),其综合误差(65.7‰)接近全树JTFS(42.4‰),而计算成本仅为后者的小部分(图1)。
图1: 计算成本(横轴)与合成器参数误差(纵轴)的帕累托前沿图。SCRAPL位于JTFS(高精度,高成本)和MSS(低成本,低精度)之间,形成了新的折衷点。
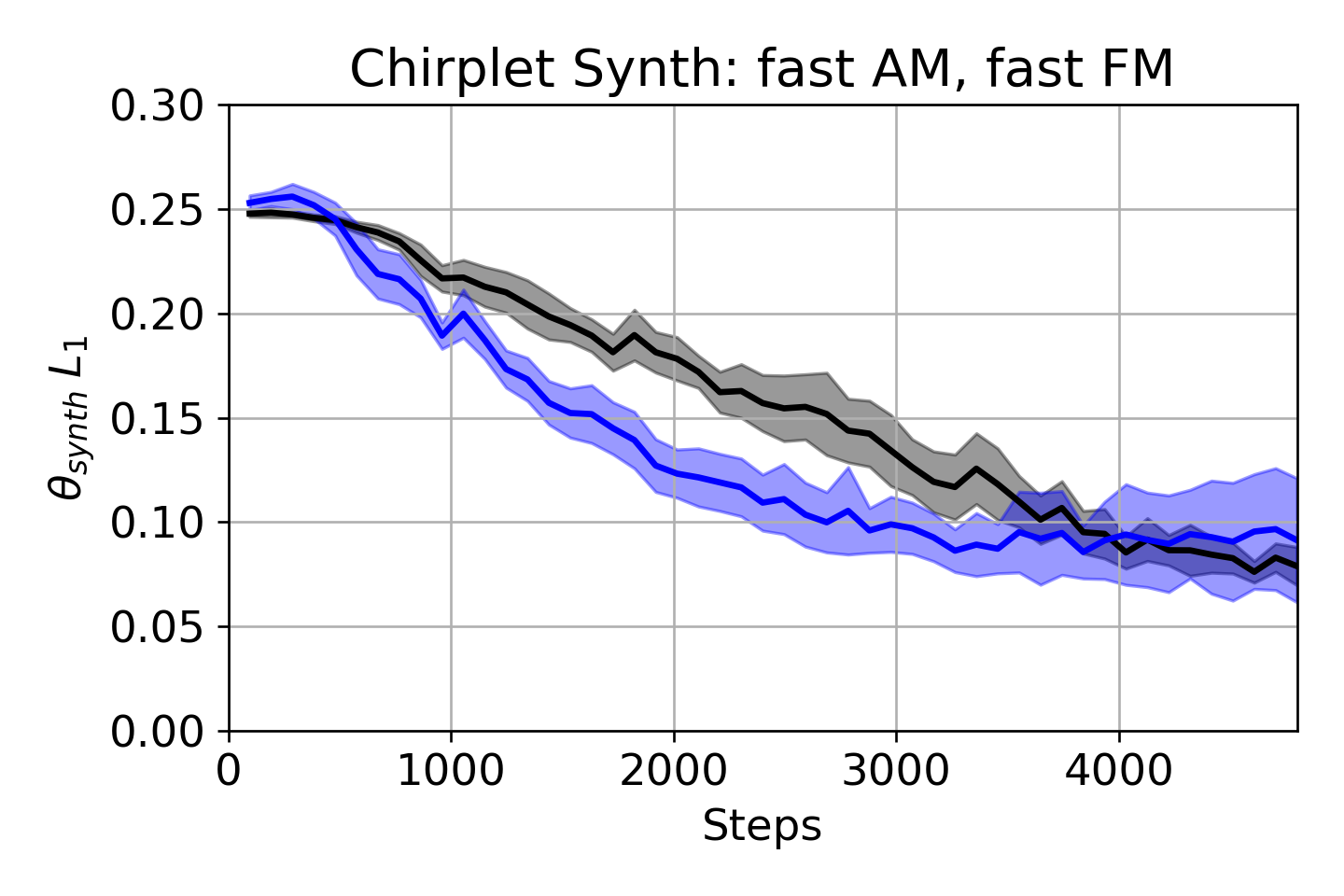 图2: (右)颗粒合成任务的验证损失随优化步数的变化。SCRAPL收敛速度快于全树JTFS,且最终精度远高于MSS等方法。
图2: (右)颗粒合成任务的验证损失随优化步数的变化。SCRAPL收敛速度快于全树JTFS,且最终精度远高于MSS等方法。
表2:SCRAPL组件消融实验(颗粒合成任务)
| 方法 | Test θsynth L1 ‰ ↓ | Validation Total Var. ↓ | Validation Conv. Steps ↓ |
|---|---|---|---|
| SCRAPL (无优化技巧) | 99.7 ± 8.2 | 5.30 ± 0.25 | 10 906 ± 1170 |
| + P-Adam | 87.4 ± 15 | 6.98 ± 0.25 | 8006 ± 697 |
| + P-SAGA | 73.8 ± 13 | 3.46 ± 0.15 | 7296 ± 683 |
| + θ-IS (完整SCRAPL) | 65.7 ± 4.2 | 3.27 ± 0.12 | 6014 ± 642 |
结论:P-Adam、P-SAGA和θ-IS每项技术都带来了性能、稳定性(Total Var.降低)和收敛速度(Steps减少)的逐次提升。
表3:θ-importance sampling效果(Chirplet合成任务,θAM L1 ‰↓)
| 合成器配置 (θAM, θFM) | 均匀采样 | θ-IS采样 | 改进幅度 |
|---|---|---|---|
| Slow AM, Slow FM | 124 ± 10 | 77.7 ± 6.7 | -37% |
| Slow AM, Mod. FM | 111 ± 20 | 55.5 ± 4.1 | -50% |
| Fast AM, Mod. FM | 122 ± 22 | 54.9 ± 3.5 | -55% |
| Fast AM, Fast FM | 108 ± 12 | 81.5 ± 12 | -25% |
结论:θ-IS显著提升了所有配置下对合成器参数的匹配精度,尤其在AM/FM调制范围较慢时效果更明显。
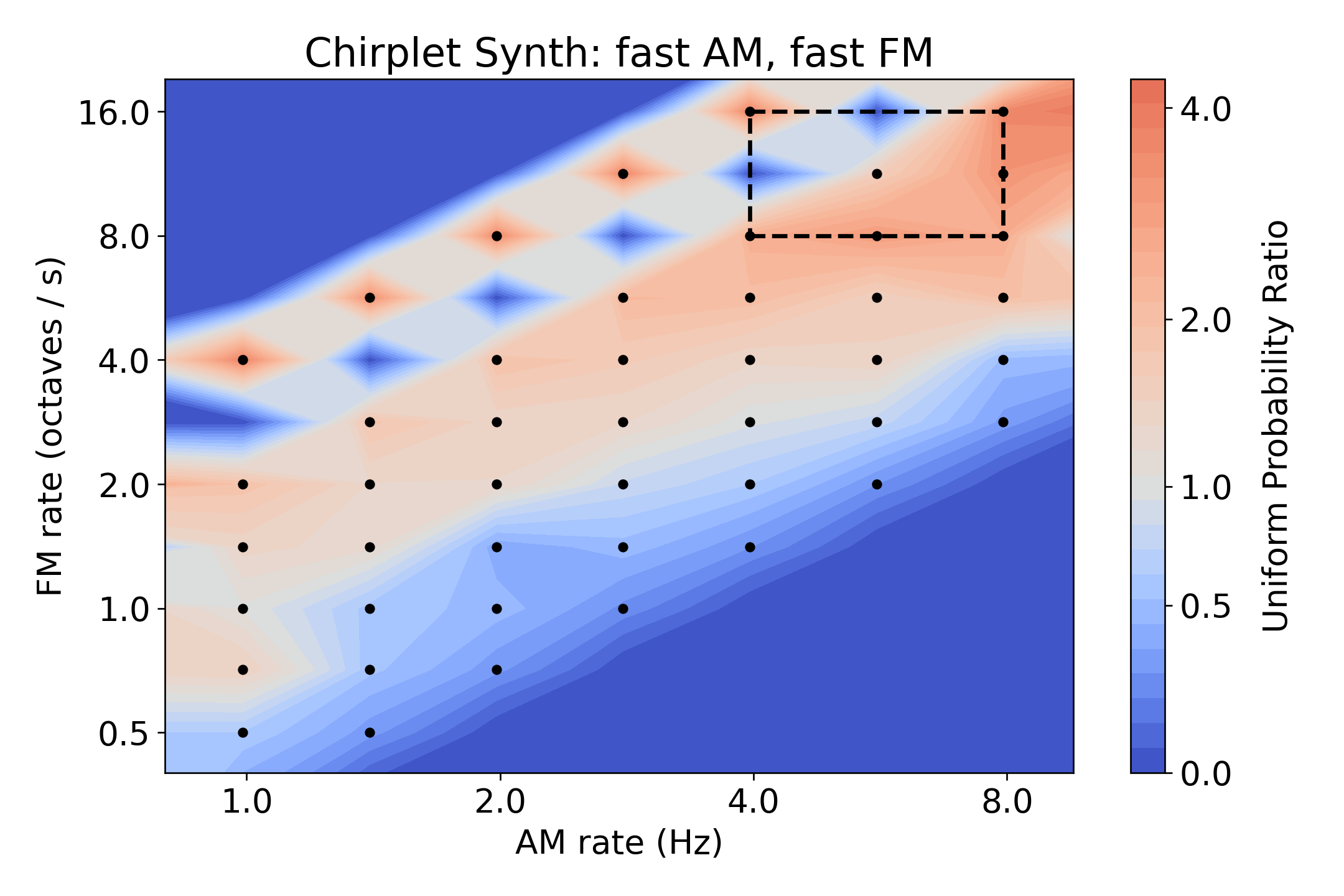 图6: θ-IS为四种Chirplet合成器配置计算的路径采样概率分布(纵轴为概率比,1.0代表均匀采样)。黑色点为JTFS路径的AM/FM中心频率,虚线框标出了合成器的参数范围。可见高概率路径集中在对应合成器参数范围内的区域,直观验证了θ-IS的有效性。
图6: θ-IS为四种Chirplet合成器配置计算的路径采样概率分布(纵轴为概率比,1.0代表均匀采样)。黑色点为JTFS路径的AM/FM中心频率,虚线框标出了合成器的参数范围。可见高概率路径集中在对应合成器参数范围内的区域,直观验证了θ-IS的有效性。
表4:Roland TR-808声音匹配任务部分结果(JTFS Audio Distance↓, FAD↓)
| 方法 | MSS Log. + Linear | JTFS (↓) | FAD (EnCodec) ↓ |
|---|---|---|---|
| Micro | Meso | Micro | |
| JTFS | 617±46 | 622±45 | 490±28 |
| SCRAPL | 857±42 | 879±42 | 1050±50 |
| MSS Lin. | 611±15 | 724±37 | 779±31 |
结论:在真实鼓机任务上,全树JTFS仍是最优的。SCRAPL在保持时间不变性方面优于MSS(尤其在未对齐的Meso设置下),但在JTFS距离和FAD指标上仍有差距。SCRAPL能更好匹配瞬态(表8),但对衰减部分匹配较差(表9)。
⚖️ 评分理由
- 学术质量:6.5/7。创新性强,提出了一个解决实际计算瓶颈的完整优化框架(随机采样+定制优化器+启发式采样)。技术正确性有理论(无偏性证明)和实验双重支撑。实验非常充分,在三种不同合成器任务上进行了全面对比、消融和分析。证据可信,统计量(CI)和多次随机运行保证了结论的可靠性。
- 选题价值:1.5/2。选题切中要害,解决了散射变换从理论工具走向大规模训练的关键障碍。对音频处理(特别是需要感知损失的生成、逆问题)领域有明确的推动价值。与音频/语音社区高度相关。
- 开源与复现加成:0.8/1。论文提供了代码仓库链接(https://christhetree.github.io/scrapl/),包含了可复现的实验设置、超参数(附录E)、预训练模型和音频示例。复现信息非常详细,但未提及是否开源了所有预训练模型权重。