📄 Query-Guided Spatial–Temporal–Frequency Interaction for Music Audio–Visual Question Answering
#音频问答 #多模态模型 #时频分析 #跨模态
✅ 7.0/10 | 前25% | #音频问答 | #多模态模型 | #时频分析 #跨模态
学术质量 6.0/7 | 选题价值 0.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kun Li (University of Twente, Netherlands; 工作完成于 IT University of Copenhagen, Denmark)
- 通讯作者:Sami Sebastian Brandt (IT University of Copenhagen, Denmark)
- 作者列表:Kun Li(University of Twente, IT University of Copenhagen)、Michael Ying Yang(University of Bath)、Sami Sebastian Brandt(IT University of Copenhagen)
💡 毒舌点评
亮点:本文最大的优点在于“系统性”和“针对性”——它没有孤立地提出一个模块,而是构建了一个从早期查询引导到中期时空频交互、再到后期上下文推理的完整流水线,并且为每个阶段都找到了扎实的动机(例如,用频率特征解决视觉模糊问题)。短板:尽管在总分上超越了前作,但在Visual QA(特别是位置相关问题)子任务上仍略逊于使用了对象检测器等先验知识的方法(如QA-TIGER),这暗示其“纯频率视角”在需要精细空间推理的场景中可能存在天花板,创新性更多体现在对已知技术的巧妙整合与优化上。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/lik1996/QSTar。
- 模型权重:论文未明确提及是否公开预训练模型权重。
- 数据集:实验主要基于公开的MUSIC-AVQA和AVQA数据集,论文中提供了数据集的基本信息和来源引用。
- Demo:论文中未提及在线演示。
- 复现材料:论文在附录和实验部分详细说明了训练设置(优化器、学习率、batch size、epoch数)、模型配置(特征维度、所用预训练模型)和硬件环境(NVIDIA H100 GPU),提供了充分的复现信息。
- 引用的开源项目:依赖的开源项目/模型包括:CLIP(视觉和文本特征提取)、VGGish(音频特征提取)、AST(频率音频特征提取)、Token Merging(视觉token压缩)。
📌 核心摘要
- 问题:现有音视频问答(AVQA)方法主要关注视觉处理,音频仅作为补充,且文本问题信息通常在最后阶段才融合,导致音视频对齐不充分,难以处理视觉线索微弱(如乐手动作细微)但音频特征鲜明的音乐场景。
- 方法核心:提出了查询引导的空间-时间-频率交互(QSTar)框架。核心包括三个模块:1)查询引导多模态关联模块(QGMC),在早期利用问题特征分别增强音频和视觉表征;2)空间-时间-频率交互模块(STFI),在空间和时间维度上增强视觉,并引入AST模型提取频率特征,在时间-频率维度上增强音频;3)查询上下文推理块(QCR),通过提示注入任务相关的语言上下文,指导最终融合与预测。
- 创新点:a) 将查询引导从“后期融合”提前至“全程引导”,从特征学习阶段就开始模态特异性优化;b) 引入频率域建模(通过AST),明确利用乐器独特的频谱指纹来区分听觉相似但视觉不同的事件;c) 设计基于提示的查询上下文推理,为最终决策提供结构化的语言约束。
- 主要实验结果:在MUSIC-AVQA基准测试上,QSTar平均准确率达到78.98%,超越之前最佳方法QA-TIGER(77.62%)1.36个百分点。具体地,在Audio QA(尤其是比较类问题)和Audio-Visual QA(尤其是比较和时序类问题)上提升显著,分别高出QA-TIGER 2.05%和2.24%。消融研究证实,移除任一主要模块(QGMC, STI, TFI, QCR)或任何阶段的查询引导都会导致性能下降。
- 实际意义:该方法推动了在音视频理解任务中,如何更深度、更早期地融合语言查询信息,以及如何有效利用音频的频域特性,为处理类似多模态问答任务提供了新的设计思路。
- 主要局限性:a) 在需要精确空间定位的Visual QA子任务上,性能仍略低于使用了专门视觉感知模块(如对象检测)的方法;b) 当前模型处理固定长度视频片段,可能难以直接扩展到需要长时记忆的更长视频;c) 频率域建模目前仅应用于音频,未探索视觉信号的频率域处理(如微动作捕捉)。
🏗️ 模型架构
QSTar是一个端到端的多模态问答网络,整体流程如下:
输入表示:
- 视觉:将视频分成T个1秒片段,每个片段用预训练CLIP提取帧级特征(Fv)和经Token Merging压缩的块级特征(Fp)。
- 音频:同样分成T段,每段用VGGish提取特征(Fa)。
- 文本:问题用CLIP文本编码器提取句子级(Fsentence)和词级(Fw)特征。
查询引导多模态关联模块(QGMC,黄色区域):
- 功能:利用问题特征(Fw)在早期分别增强音频(Fa)和视觉(Fv)特征,使其与查询语义对齐。
- 内部流程: a. 自增强:对Fv、Fa、Fw分别应用多头自注意力(SA),强化模态内关联。 b. 捕获:用增强后的Fw作为查询(Query),Fv和Fa作为键(Key)和值(Value),进行交叉注意力(CA),分别得到问题引导的视觉和音频语义,聚合为查询引导上下文Fqg。 c. 传播:用原始的Fv和Fa作为查询,反向关注Fqg,将上下文信息传播回各模态,得到Fvq和Faq。最后通过残差连接和FFN,得到增强后的特征F’vq和F’aq。
- 设计动机:克服以往方法在后期才融合文本信息的问题,实现“问题感知”的早期特征学习。
空间-时间-频率交互模块(STFI,紫色区域):
- 功能:在空间、时间、频率三个维度上,进一步增强已查询引导的音频和视觉特征。
- 子模块1:空间-时间交互(STI): a. 空间交互:用块级视觉特征(Fp)作为查询,关注增强后的音频特征(F’aq),定位与声音相关的视觉区域。 b. 时间交互:计算F’aq与F’vq的点积和softmax,捕捉音频与视觉在时间上的动态对齐关系。 c. 将空间和时间结果拼接后经FFN,得到空间-时间增强的视觉特征Fvi。
- 子模块2:时间-频率交互(TFI): a. 引入预训练的Audio Spectrogram Transformer(AST),从原始音频波形提取富含频率信息的特征Fast。 b. 频率注意力:将Fast在时间上平均,与词级问题特征(Fw)结合,计算频率注意力权重,高亮与问题相关的频谱带,得到F’ast。 c. 将F’ast与F’aq拼接后经卷积块融合,得到时间-频率增强的音频特征Fai。
- 设计动机:STI处理视觉的空间冗余和时间对齐;TFI专门解决视觉模糊场景(如乐手动作小),利用AST捕捉乐器独特的频谱“指纹”。
查询上下文推理块(QCR,绿色区域)与预测:
- 功能:在最终预测前,注入任务相关的语言上下文进行精炼。
- 流程: a. 上下文构建:预设与音乐问答相关的提示词(如“乐器类型”、“持续时间”、“位置”等),编码为Fprompt,并与句子级问题特征(Fsentence)拼接,经SA得到查询上下文Fqc。 b. 上下文推理:用Fqc作为查询,分别通过CA关注和精炼空间-时间视觉特征(Fvi)和时间-频率音频特征(Fai),得到最终特征Ffv和Ffa。 c. 预测:将Ffv和Ffa拼接、通过全连接层和tanh得到Fav。最后用Fav与Fsentence进行逐元素相乘,得到最终答案logit,通过分类得到答案。
- 设计动机:借鉴提示学习,为模型提供明确的推理框架,增强语义对齐。
💡 核心创新点
- 全流程查询引导机制:创新性地将问题信息从特征学习初期(QGMC)贯穿至特征增强(STFI中的频率注意力)和最终推理(QCR),全程引导模型关注与问题相关的音视频内容。局限性:以往方法多在后期融合查询,导致多模态表征冗余。
- 融合频率域的细粒度交互:明确引入AST提取音频的频率域特征,并设计频率注意力使其与问题关联,有效利用了乐器独特的频谱特性来区分视觉相似的场景。局限性:以往方法主要使用VGGish等时域特征,难以区分视觉相似但音色不同的乐器。
- 基于提示的查询上下文推理块:设计了一个结构化的推理模块,将任务关键属性(如乐器类型、时序)作为提示,为最终决策提供明确的语言上下文约束。局限性:以往方法的最终推理缺乏这种结构化的语言指导。
🔬 细节详述
- 训练数据:主要在MUSIC-AVQA数据集上训练,该数据集包含40K+ QA对和9288个音乐相关视频。数据增强未提及,采用标准数据集划分。还在AVQA数据集上进行了评估。
- 损失函数:未明确说明,根据任务性质,推测为标准的交叉熵损失用于答案分类。
- 训练策略:使用AdamW优化器,初始学习率1e-4,每10个epoch衰减0.1。批次大小64,训练30个epoch。
- 关键超参数:所有特征投影到512维。模型可训练参数约13.2M,计算量约2.43G FLOPs(见表4)。
- 训练硬件:单张NVIDIA H100 GPU。
- 推理细节:未提及特殊解码策略,答案从预定义词汇表中分类预测。
- 正则化或稳定训练技巧:未具体说明,但使用了常见的FFN、残差连接和层归一化(隐含在Transformer和FFN中)。
📊 实验结果
主要基准与指标:在MUSIC-AVQA和AVQA数据集上进行评估,主要指标为答案准确率(Accuracy (%))。
与SOTA方法的对比:
| 方法 | Audio QA (Avg) | Visual QA (Avg) | Audio-Visual QA (Avg) | 总体平均 (Avg) |
|---|---|---|---|---|
| TSPM (Li et al., 2024a) | 76.91 | 83.61 | 73.51 | 76.79 |
| QA-TIGER (Kim et al., 2025) | 78.58 | 85.14 | 73.74 | 77.62 |
| QSTar (ours) | 80.63 | 84.17 | 75.98 | 78.98 |
| 表1(节选):QSTar与顶尖方法在MUSIC-AVQA测试集上的准确率对比。 |
关键结论:QSTar在总体平均准确率上超越之前SOTA(QA-TIGER)1.36%,在Audio QA和Audio-Visual QA类型上优势尤为明显,特别是在比较(Comparative)和时序(Temporal)问题上。
关键消融研究:
| 移除的模块/组件 | 总体平均准确率 (Avg) | 相对于完整模型的下降 |
|---|---|---|
| 完整模型 QSTar | 78.98 | - |
| w/o QGMC | 76.80 | -2.18% |
| w/o QCR | 78.19 | -0.79% |
| w/o STI | 77.80 | -1.18% |
| w/o TFI | 77.41 | -1.57% |
| 表2(节选):主要模块消融研究。 |
其他重要消融:
- 查询引导时机:移除早期(Beginning)引导导致下降1.05%,证明早期引导的重要性(表3)。
- 提示策略:使用作者提出的统一提示(QCR)优于不加提示、转换问题为陈述、使用视频标题或生成式提示等策略(表9)。
与大语言模型的对比:零样本评估的GPT-4o、Qwen2.5-Omni等大模型在该任务上表现不佳(平均准确率~54%),远低于QSTar。微调后的VideoLLaMA2也显著落后于QSTar,尤其在比较类问题上差距近20%(见表1)。
效率分析:
| 方法 | 可训练参数 (M) | 计算量 (G FLOPs) | 平均准确率 (%) |
|---|---|---|---|
| TSPM | 6.22 | 1.42 | 76.79 |
| QA-TIGER | 14.51 | 2.70 | 77.62 |
| QSTar (ours) | 13.20 | 2.43 | 78.98 |
| 表4:效率对比。QSTar在参数和计算量与QA-TIGER相当的情况下,准确率更高。 |
实验结果图表:
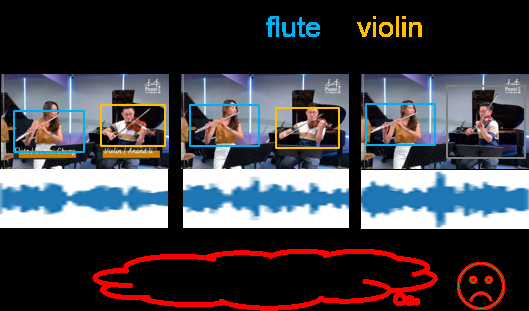
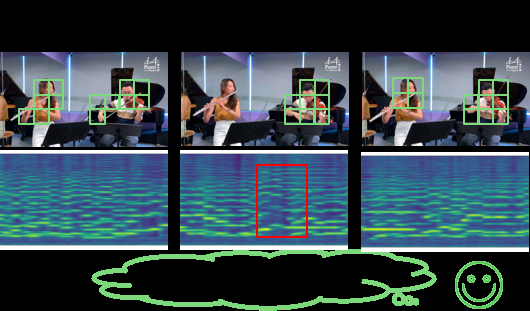 图3(a):展示QSTar在复杂多乐器场景(如大提琴视觉不明显时)优于QA-TIGER的示例。图3(b):可视化QSTar在关键时间戳上关注的视觉区域和音频频率动态,例如能正确识别单簧管持续演奏而巴松管停止。
图3(a):展示QSTar在复杂多乐器场景(如大提琴视觉不明显时)优于QA-TIGER的示例。图3(b):可视化QSTar在关键时间戳上关注的视觉区域和音频频率动态,例如能正确识别单簧管持续演奏而巴松管停止。
⚖️ 评分理由
- 学术质量(6.0/7):论文提出了一个逻辑严密、动机充分的框架,通过模块化设计和详尽的消融研究,在特定基准上取得了SOTA结果,技术正确性和实验充分性高。扣分点在于创新更多是针对性的模块集成与优化,而非提出新的基础原理;在视觉子任务上未完全取胜,显示了方法侧重点的局限性。
- 选题价值(0.5/2):音乐音视频问答是一个有价值的多模态挑战,但应用场景相对垂直和特定。对于专注于语音、通用音频处理的广大读者而言,直接关联性较弱。频率域分析的思路对多模态研究有启发价值。
- 开源与复现加成(0.5/1):论文明确提供了代码仓库(https://github.com/lik1996/QSTar),并详细描述了训练过程、数据集和超参数,极大方便了其他研究者的验证和拓展工作,这是显著的加分项。