📄 PrismAudio: Decomposed Chain-of-Thought and Multi-dimensional Rewards for Video-to-Audio Generation
#音频生成 #强化学习 #扩散模型 #多模态模型 #基准测试
✅ 7.0/10 | 前25% | #音频生成 | #强化学习 | #扩散模型 #多模态模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Huadai Liu(香港科技大学、阿里巴巴集团通义实验室)
- 通讯作者:Wei Xue(香港科技大学)
- 作者列表:Huadai Liu(香港科技大学、阿里巴巴集团通义实验室)、Kaicheng Luo(阿里巴巴集团通义实验室)、Wen Wang(阿里巴巴集团通义实验室)、Qian Chen(阿里巴巴集团通义实验室)、Peiwen Sun(香港中文大学)、Rongjie Huang(香港中文大学)、Xiangang Li(阿里巴巴集团通义实验室)、Jieping Ye(阿里巴巴集团通义实验室)、Wei Xue(香港科技大学)
💡 毒舌点评
亮点在于将“分解的链式思维”与“多维强化学习奖励”进行耦合的框架设计思路,清晰且有效,为解决多目标生成中的“目标纠缠”提供了新颖且可解释的方案。短板是,其提出的全新AudioCanvas基准数据集虽然是必要的,但作为“裁判员”的同时,自己也是“运动员”,这使得核心结论的公信力部分依赖于数据集构建的客观性,且报告的部分指标(如在某些空间或美学指标上超越了真实音频)需要更谨慎的解释。
🔗 开源详情
- 代码:论文承诺将开源完整训练脚本和配置文件,但当前未提供代码仓库链接。
- 模型权重:论文承诺将公开所有模型权重(音频基础模型、微调后的VideoLLaMA2等),但未提供下载地址。
- 数据集:论文承诺将公开AudioCanvas基准数据集,但未说明具体获取方式。
- Demo:论文未提及在线演示。
- 复现材料:附录D提供了极其详细的实现细节,包括训练各阶段的GPU型号、数量、时长、批大小、学习率等超参数,以及CoT生成和微调的提示词模板,复现信息非常充分。
- 论文中引用的开源项目:VideoPrism, T5-Gemma, VideoLLaMA2, Gemini 2.5 Pro(API), MS-CLAP, Synchformer, Meta Audiobox Aesthetics, StereoCRW, Stability AI的音频工具。
📌 核心摘要
- 要解决什么问题:视频到音频生成需要同时优化语义一致性、时间同步性、美学质量和空间准确性四个维度,但现有方法使用单一损失函数导致目标相互纠缠,且缺乏与人类偏好对齐。
- 方法核心是什么:提出PrismAudio框架,首次将强化学习引入视频到音频生成。其核心是将生成前的推理过程分解为四个专门的链式思维模块(语义、时间、美学、空间),并为每个模块设计对应的奖励函数,通过多维强化学习进行联合优化。
- 与已有方法相比新在哪里:1) 首次在V2A中使用分解式CoT与多维RL奖励对应,解决目标纠缠并提升可解释性。2) 提出Fast-GRPO算法,通过随机窗口的混合ODE-SDE采样,在保证性能的同时大幅降低RL训练开销。3) 构建了更严谨、场景更多样的AudioCanvas基准数据集。
- 主要实验结果如何:在自建的AudioCanvas基准和VGGSound测试集上,PrismAudio在所有四个感知维度上均达到了SOTA水平。例如,在AudioCanvas上,与基线ThinkSound相比,语义对齐度(CLAP)从0.48提升至0.52,时间同步性(DeSync)从0.80大幅改善至0.36,美学质量(CE)从4.10提升至4.26,空间误差(CRW)从22.82降低至12.87。消融实验证明分解式CoT优于单体式CoT,多维度奖励优于单维度奖励。
- 实际意义是什么:为生成高质量、可控且与人类感知对齐的视频配音提供了一个新范式。其分解式推理框架和高效RL训练方法对其他多模态生成任务也有参考价值。
- 主要局限性是什么:框架复杂度较高,依赖于多个预训练模型(如VideoLLaMA2、各种奖励模型)。实验中报告的部分客观指标(如空间/美学)超越了真实音频,这可能源于对不完美代理指标的过度优化,其实际感知质量需结合主观评估看。新提出的AudioCanvas基准的有效性和广泛接受度有待社区检验。
🏗️ 模型架构
PrismAudio的整体架构可分为三个主要阶段,建立在一个基于流匹配的扩散Transformer音频基础模型之上。
 图1: PrismAudio框架概览
图1: PrismAudio框架概览
阶段一:CoT感知的音频基础模型 这是生成的核心。输入为静默视频和文本条件,输出为立体声音频。
- 视频编码器:采用VideoPrism(一个在大规模视频数据上预训练的ViT架构),替代传统的CLIP编码器,以捕获更丰富的视频语义、动作和环境信息。
- 文本编码器:采用T5-Gemma,一个结合了LLM推理能力的编码器-解码器架构,能够更好地理解和处理结构化的链式思维文本。
- 生成模型:基于DiT(Diffusion Transformer)和流匹配。它接收视频特征、文本条件和可选的同步性特征(来自Synchformer),通过注意力机制融合后,生成音频潜在表示。视频特征通过“门控加法+交叉注意力”的双策略融合,同步性特征通过“门控加法”融合。
阶段二:分解的多维链式思维推理 这是PrismAudio的独特设计,将推理过程结构化、专门化。
- CoT数据构建:首先使用Gemini 2.5 Pro为视频-音频对生成包含四个维度的CoT描述。然后,使用一个文本LLM将其转换成四个独立的模块化文本。
- VideoLLaMA2微调:使用上述数据微调VideoLLaMA2(一个开源视频语言模型),使其能够根据静默视频输入,直接生成四个专门的CoT模块:语义CoT、时间CoT、美学CoT、空间CoT。这四个模块按顺序拼接,形成最终的多维CoT文本条件,用于指导音频基础模型的生成。
阶段三:Fast-GRPO多维度强化学习后训练 这是优化阶段,利用多个奖励信号来对齐人类偏好。
- 多维奖励函数:设计了四个与CoT维度对应的奖励:语义奖励(MS-CLAP)、时间奖励(Synchformer)、美学奖励(Meta Audiobox Aesthetics)、空间奖励(StereoCRW)。
- Fast-GRPO优化器:这是GRPO算法在流匹配模型上的高效实现。其核心是“混合采样器与随机窗口调度”:
- 对于每个训练批次,随机选取一个优化窗口
W(ℓ),窗口大小w远小于总步数T。 - 在窗口内,采样使用SDE(随机微分方程),以引入随机性并便于计算策略概率;在窗口外,使用确定性的ODE采样,以提高效率。
- 这种混合采样在理论上保持了最终数据分布的等价性,使得奖励计算有效。
- 对于每个训练批次,随机选取一个优化窗口
- 优化目标:对每个提示
c,用旧策略采样一组N个音频候选,计算每个候选的加权总奖励,再通过组内归一化计算优势值A_i。最终目标是最大化窗口内的策略梯度,带有PPO风格的裁剪和KL散度正则化,以防止奖励欺骗。
💡 核心创新点
- 分解式链式思维与多维奖励对应框架:首次将V2A生成的推理过程显式地分解为四个正交的感知维度(语义、时间、美学、空间),并为每个维度设计专门的奖励信号进行强化学习优化。这从根本上解决了以往方法中多目标纠缠和缺乏人类偏好对齐的问题,同时保持了推理的可解释性。
- Fast-GRPO算法:针对流匹配模型应用GRPO时全步SDE采样效率低下的问题,提出一种混合ODE-SDE采样策略。通过仅在随机放置的、较小的窗口内使用SDE进行探索和策略更新,而在其余步骤使用高效ODE,将每样本的策略评估次数从O(T)降至O(w),实现了高效的多维强化学习训练。
- AudioCanvas基准数据集:构建了一个更严谨、更具挑战性的V2A评估基准。它包含3,177个经过严格人工过滤的高质量视频,覆盖300个单事件类别和501个多事件样本,并提供了由Gemini 2.5 Pro生成并经验证的结构化CoT标注,弥补了现有基准在模态对齐、场景复杂度和标注丰富性上的不足。
🔬 细节详述
- 训练数据:
- 预训练:使用WavCaps、AudioCaps和VGGSound数据集。
- CoT微调:使用VGGSound数据集,并通过微调的VideoLLaMA2生成多维CoT标注。
- RL后训练:同样使用VGGSound数据集。
- AudioCanvas基准:包含3,177个视频,从大规模候选池中经自动过滤(排除简单场景)和专家手动筛选得到,确保高质量和复杂性。
- 损失函数:
- 音频基础模型预训练:流匹配损失(未详细说明具体形式)。
- Fast-GRPO后训练:目标函数为
J(θ) = Ec,ℓ,{xi}~πθold [ (1/N)Σ_i (1/w)Σ_{t∈W(ℓ)} min( r_i t(θ) A_i, clip(r_i t(θ), 1-ε, 1+ε) A_i) ],其中A_i是基于四个奖励加权和组内归一化的优势值,并加入KL散度正则化(权重0.04)。
- 训练策略:
- VAE微调:24张A800 GPU,batch size 144,训练50万步。
- 音频基础模型预训练:8张A100 GPU,batch size 256,训练10万步,使用EMA和AMP。学习率1e-4,CFG dropout 0.1。
- CoT微调:配置同预训练。
- Fast-GRPO后训练:8张A800 GPU,学习率1e-5,训练约5天(相比全SDE-GRPO约8天提速1.6倍)。
- VideoLLaMA2微调:8张A800 GPU,AdamW优化器,学习率2e-5,batch size 128,训练10个epoch,冻结视频/音频编码器,只微调视频投影层和LLM。
- 关键超参数:
- Fast-GRPO:KL ratio=0.04,noise level=0.7,group size=16,SDE steps(w)=2,sampling steps(T)=24。
- 模型大小:PrismAudio总参数518M(小于ThinkSound的1.3B和MMAudio的1.03B)。
- 训练硬件:如上所述,主要使用NVIDIA A800和A100 GPU。
- 推理细节:生成立体声音频,采样率44.1kHz,推理时间(生成9秒音频)约0.63秒(论文表1),使用24步采样。推理时使用分类器无关引导(CFG)。
- 正则化:Fast-GRPO中使用KL散度正则化防止奖励欺骗;训练中使用Dropout(0.1)和EMA。
📊 实验结果
论文在VGGSound测试集(域内)和AudioCanvas基准(域外)上进行了全面评估。
主要对比结果(域内:VGGSound测试集)
| 方法 | 参数量 | 语义 (CLAP↑) | 时间 (DeSync↓) | 美学 (PQ↑) | 空间 (CRW↓) | 分布 (FD↓) | 主观 (MOS-Q↑) | 推理时间(s) |
|---|---|---|---|---|---|---|---|---|
| ThinkSound | 1.3B | 0.43 | 0.55 | 6.15 | 13.47 | 1.17 | 4.05±0.55 | 1.07 |
| MMAudio | 1.03B | 0.40 | 0.46 | 5.94 | - | 2.17 | 3.95±0.51 | 1.30 |
| PrismAudio (w/o CoT-RL) | 518M | 0.42 | 0.51 | 6.17 | 10.29 | 1.14 | 4.02±0.48 | 0.63 |
| PrismAudio (Ours) | 518M | 0.47 | 0.41 | 6.38 | 7.72 | 1.08 | 4.21±0.35 | 0.63 |
关键结论:PrismAudio在所有指标上超越基线,且参数更少、推理更快。去掉CoT-RL的基础模型本身已很强大,CoT-RL带来了进一步显著提升(如MOS-Q提升4.7%)。
主要对比结果(域外:AudioCanvas基准)
| 方法 | 语义 (CLAP↑) | 时间 (DeSync↓) | 美学 (CE↑) | 空间 (CRW↓) | 分布 (FD↓) | 主观 (MOS-Q↑) |
|---|---|---|---|---|---|---|
| ThinkSound | 0.48 | 0.80 | 4.10 | 22.82 | 1.95 | 3.79±0.58 |
| MMAudio | 0.46 | 0.43 | 3.97 | - | 3.59 | 3.88±0.45 |
| PrismAudio (w/o CoT-RL) | 0.42 | 0.44 | 3.81 | 15.30 | 2.10 | 3.91±0.35 |
| PrismAudio (Ours) | 0.52 | 0.36 | 4.26 | 12.87 | 1.92 | 4.12±0.28 |
关键结论:在更复杂的域外数据上,PrismAudio的优势更加明显,CoT-RL的贡献被放大(如CLAP从0.42提升至0.52,DeSync从0.44降至0.36)。
关键消融实验
- CoT推理策略消融(AudioCanvas):
方法 CLAP↑ DeSync↓ CE↑ CRW↓ Baseline (No CoT) 0.42 0.44 3.81 15.30 Random CoT 0.44 0.41 3.78 13.79 Monolithic CoT 0.46 0.38 3.79 13.02 MultiCoT (Ours) 0.52 0.36 4.26 12.87
- 结论:结构化的CoT推理至关重要,随机排列的CoT效果差。分解式MultiCoT全面优于单体式CoT,尤其在语义和美学上优势明显。
- 多维度奖励消融(AudioCanvas):
奖励焦点 CLAP↑ DeSync↓ PQ↑ CE↑ CRW↓ FD↓ Baseline (No RL) 0.47 0.42 6.45 3.81 15.30 1.90 Semantic Only 0.54 0.58 6.62 3.93 11.89 1.84 Temporal Only 0.46 0.35 6.39 3.63 13.08 1.68 Aesthetic Only 0.46 0.42 7.06 3.92 13.51 4.50 Spatial Only 0.47 0.42 6.44 3.72 11.88 1.77 Multi-dimensional (Ours) 0.52 0.36 6.68 4.26 12.87 1.92
- 结论:单维度优化会导致严重的“目标纠缠”(如仅优化美学时,FD分布指标大幅恶化)。多维度奖励是唯一能实现所有维度平衡提升的方案。
 图2: Fast-GRPO与Flow-GRPO训练收敛曲线对比
图2: Fast-GRPO与Flow-GRPO训练收敛曲线对比
- 结论:Fast-GRPO收敛速度远快于Flow-GRPO(200步 vs 600+步),且最终奖励分数更高(~0.51 vs ~0.47),证明了其高效性和优化效果。
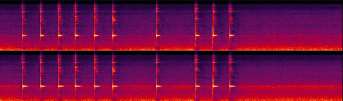 图3: 定性比较案例
图3: 定性比较案例
- 结论:在尤克里里场景中,PrismAudio保留了更清晰的谐波和高频细节(美学质量高);在铁匠场景中,其瞬态响应(锤击声)更准确、时间同步更好。
⚖️ 评分理由
- 学术质量:5.5/7。创新性明确,提出了解耦CoT与多维RL奖励的完整框架。Fast-GRPO有扎实的理论推导和混合采样创新。实验全面,设计了针对性消融。扣分点在于:1) 核心实验大量依赖自建的AudioCanvas基准,缺乏第三方验证;2) 部分消融实验(如美学/空间奖励单独消融)的完整数据在正文中未充分展示(表格13被截断),需依赖附录;3) 某些客观指标(如空间PQ/CE)超越真实值,其与感知质量的真实关联需要更严谨论证。
- 选题价值:1.5/2。选题处于多模态生成前沿,视频到音频生成需求日益增长。其“分解-多维优化”的思想具有普适性。1.5分是因为该任务相对语音合成或图像生成更为垂直,受众面稍窄。
- 开源与复现加成:0.0/1。论文给出了明确的开源承诺和详细的复现说明(附录D),这是加分项。但当前提供的文本中未包含实际的开源链接(代码、模型、数据),因此无法给予额外分数。