📄 PACE: Pretrained Audio Continual Learning
#音频分类 #持续学习 #预训练 #参数高效微调
🔥 8.5/10 | 前25% | #音频分类 | #持续学习 | #预训练 #参数高效微调
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Chang Li*(清华大学心理与认知科学系)
- 通讯作者:Liyuan Wang†(清华大学心理与认知科学系)
- 作者列表:Chang Li(清华大学心理与认知科学系)、Kanglei Zhou(清华大学心理与认知科学系)、Liyuan Wang†(清华大学心理与认知科学系)
💡 毒舌点评
亮点在于其开创性地为预训练音频模型的持续学习建立了首个系统性基准,并深刻剖析了音频域区别于视觉域的独特挑战(如严重的表示偏移),问题定位准、分析透彻。短板则是所提出的PACE方法涉及多个阶段和组件(如FSA、MSA、边界正则化),整体框架略显复杂,其在更极端的跨域(如从音乐到语音)或超大规模任务序列下的泛化能力和计算开销有待进一步验证。
🔗 开源详情
- 代码:论文在“Reproducibility statement”中承诺“upon acceptance”发布代码库,但未提供具体链接。论文中未提及当前可用的代码链接。
- 模型权重:未提及公开的预训练或适配后的模型权重。
- 数据集:论文中使用的6个CL基准均为公开数据集(ESC-50, UrbanSound8K, SC2, TIMIT, VocalSet),但论文中未说明是否提供了额外的划分或处理脚本。
- Demo:未提及在线演示。
- 复现材料:提供了极其详细的训练细节(附录D)、超参数敏感性分析(附录E.6)、算法伪代码(附录B)和数据集统计(表5),为复现提供了充分信息。
- 论文中引用的开源项目:引用了多个开源工具和模型,包括预训练音频模型EAT(Chen et al., 2024)、SSLAM(Alex et al., 2025),以及持续学习方法RanPAC(McDonnell et al., 2023)、ACL(Zhuang et al., 2022)、LoRASub(Liu & Chang, 2025)等。
- 总结:论文中提及了明确的开源计划,并提供了详实的复现指南,但具体的代码和权重发布需等待论文接收。
📌 核心摘要
- 问题:预训练音频模型(PTMs)在现实世界中数据分布持续变化的场景下,直接应用现有的视觉域持续学习(CL)方法(如PEFT)性能会严重下降。根本原因在于音频骨干网络更强调低层频谱细节而非结构化语义,导致严重的“上游-下游表示不对齐”,引发跨会话的剧烈表示偏移和灾难性遗忘。
- 方法核心:提出PACE框架,分三阶段解决上述问题。阶段1:改进的首次适应(FSA),通过限制头部学习率、后期层LoRA适配和替换解析分类器,稳定地适配第一个任务,避免表示饱和。阶段2:自适应多会话子空间正交PEFT,允许骨干网络在后续会话中进行受控适应,同时通过梯度投影到先前表示的零空间来约束表示漂移。阶段3:骨干网络固定,进入稳定期。
- 新在何处:首次系统构建了音频CL基准;首次深入分析了音频CL特有的挑战(表示饱和与偏移);提出了首个专门针对音频PTMs特性的、兼顾可塑性与稳定性的统一CL框架PACE,融合了音频特定的PEFT策略、子空间投影和基于时频掩码的边界感知正则化。
- 实验结果:在3个粗粒度(ESC-50, US8K, SC2)和3个细粒度(TIMIT-2, TIMIT-3, VocalSet)共6个音频CL基准上,PACE大幅超越所有基线方法。在细粒度任务上优势尤为明显,如在TIMIT-2上比次优基线RanPAC高5.32%,在VocalSet上高6.26%。PACE将性能与联合训练上界的差距显著缩小(例如,在ESC-50上差距仅0.75%,在VocalSet上差距从13.8%降至7.57%)。关键消融实验验证了FSA、MSA、梯度投影和边界正则化的必要性。
- 实际意义:为构建能够持续适应新环境、新说话人、新声音的健壮、可扩展的音频智能系统(如语音助手、智能环境监测)提供了理论基础和有效方法。
- 主要局限性:框架的多阶段设计和多个超参数(如Nstop, ρlayer)增加了部署和调优的复杂性。方法对计算资源(特别是早期阶段的骨干网络适应)有一定要求。对于领域差距极大(如从环境声到音乐)的超复杂CL序列的有效性有待验证。
🏗️ 模型架构
PACE是一个分阶段的统一框架,旨在重新对齐预训练音频骨干网络的表示以适应持续学习目标。
 图4:PACE框架。Stage 1执行带LoRA的首次适应,随后进行解析推断。Stage 2引入子空间正交PEFT,通过LoRA减法和梯度投影实现。边界感知正则化在前两个阶段进行。Stage 3固定骨干网络。蓝色:冻结;橙色:调整;箭头:适应路径。
图4:PACE框架。Stage 1执行带LoRA的首次适应,随后进行解析推断。Stage 2引入子空间正交PEFT,通过LoRA减法和梯度投影实现。边界感知正则化在前两个阶段进行。Stage 3固定骨干网络。蓝色:冻结;橙色:调整;箭头:适应路径。
整体流程与组件:
- 输入:原始音频信号经过STFT和梅尔滤波转换为时频图 x。
- 骨干网络与输出:预训练骨干网络 f(·)(如EAT, 基于ViT的12层Transformer)提取表示 z = f(x),分类头 g(·) 预测类别概率 ŷ = g(z)。
- 阶段1:改进的首次适应(FSA):
- 目标:在第一个任务 T1 上稳定适配,为后续任务奠定基础,避免“表示饱和”。
- 关键组件:
- 受限头部学习:先以较低学习率 ηhead 训练临时分类头 h1 Ehead 个epoch(骨干冻结),再以较大学习率 ηbb 固定头部 h1,仅调整骨干网络深层(l ≥ Ltune)的LoRA参数(A_l1, B_l1) E0 个epoch。这种非对称训练迫使骨干吸收大部分梯度。
- 后期层LoRA:通过CKA分析确定阈值 ρlayer(默认为0.94),选择表示偏移开始超过此阈值的层 Ltune 作为可调层的起点,冻结更浅层以保留预训练的通用声学特征。
- 解析分类器:FSA完成后,丢弃临时头 h1,改用无需存储样本的递归解析分类器 ϕ1(·)。该分类器基于随机投影和二阶统计量(自相关矩阵 R_t 和权重 W_t)通过闭式解更新决策边界,确保稳定性。
- 阶段2:自适应多会话子空间正义PEFT(MSA):
- 目标:在后续任务 (t=2到T3) 中进行渐进式适应,桥接细粒度任务中的严重语义鸿沟,同时防止对旧知识的破坏。
- 关键组件:
- 会话特定LoRA:每个新会话 t 添加新的LoRA参数 (A_t, B_t),更新模型权重为 W_t = W_0 + Σ_{τ=0}^{t-1} B_τ A_τ + B_t A_t。 梯度投影:为计算当前会话的更新梯度 g_original,先构造“遗忘模型” W_unlearn = W_0 - Σ_{τ=0}^{t-1} B_τ A_τ,提取当前会话特征并计算其未中心化协方差矩阵,通过SVD得到主要子空间的投影算子 PU_t。将 g_original 投影到该子空间,得到 g_update = PU_t g_original,确保更新最小化影响旧样本的表示。
- 停止准则:当累积处理样本数超过阈值 N_stop 时,停止骨干适应,进入阶段3。
- 阶段3:骨干固定:
- 冻结骨干网络所有参数,后续新任务仅通过解析分类器 ϕ_t(·) 进行增量学习。
- 边界感知正则化(应用于阶段1和2):
- 目标:缓解新旧类别表示重叠问题,增大类间距。
- 机制:对当前任务的每个样本 xi,t,使用时频掩码生成扰动样本 ˜x_ki,t。识别那些在临时模型下容易被扰动误分类的“边界样本”构成集合 B_t。在训练中,通过损失 L_reg 拉动样本特征向其类中心 µ(xc) 靠近,同时推离最近的边界点 b∈B_t,以增强类内紧凑性和类间可分性。
数据流:输入音频 -> 频谱图 -> 骨干网络(在阶段1、2可部分适应) -> 表示 z -> (阶段1用临时头 h1 训练;之后) -> 解析分类器 ϕ_t -> 预测 ŷ。
💡 核心创新点
首个系统性音频持续学习基准与问题剖析:
- 是什么:构建了涵盖粗细粒度、语音/环境声/音乐的6个音频CL基准,并首次系统揭示了音频CL的独特挑战。
- 之前局限:音频CL研究零散,缺乏统一基准;直接套用视觉CL方法效果差,但原因不明。
- 如何起作用/收益:通过对比实验(如图1, 图2)明确指出,音频PTM因强调频谱细节导致严重的表示偏移,且存在“表示饱和”和“表示偏移”两大问题,为后续方法设计提供了明确靶点。
针对音频特性的改进首次适应(Improved FSA):
- 是什么:一种结合受限头部学习、深层LoRA适配和解析分类器的首次任务学习策略。
- 之前局限:传统FSA或全量微调会扭曲预训练表示,导致饱和(粗粒度)或过拟合(细粒度),如图3和表1所示。
- 如何起作用/收益:非对称训练和后期层适配精准微调与任务相关的语义特征,同时冻结浅层通用特征。解析分类器避免了参数化头部带来的偏差累积。实验表明(表3),该策略显著提升了首次任务性能并为后续学习保留了更好的可塑性。
自适应多会话子空间正交PEFT:
- 是什么:一种允许多会话渐进适应骨干网络,同时通过梯度投影约束更新方向以保护旧表示的技术。
- 之前局限:固定骨干的解析分类器在细粒度任务上因上游-下游不匹配而性能受限(表1)。简单的多会话微调则导致灾难性遗忘(图9c)。
- 如何起作用/收益:利用当前任务数据计算特征子空间,并将更新梯度投影至该子空间(与旧表示空间正交),实现了“在需要的地方学习,不干扰已学好的部分”。与边界正则化结合,在VocalSet上相比仅用FSA提升了6.26%(表4, 图7),有效平衡了稳定性与可塑性。
基于频谱的边界感知扰动:
- 是什么:一种通过生成时频掩码扰动样本来近似决策边界,并利用对比损失增大类间距的正则化方法。
- 之前局限:持续学习中新类容易侵入旧类决策边界,造成混淆。
- 如何起作用/收益:通过拉近类内特征、推离边界点,使表示空间更结构化。消融实验显示(表4),移除该正则化导致在细粒度任务上性能下降,尤其在VocalSet上下降3.33%。可视化(图8)表明其比加性噪声更有利于保持流形结构。
🔬 细节详述
- 训练数据:
- 预训练数据:AudioSet-2M(约5000小时音频),用于EAT模型预训练。
- CL评估数据集:
- 粗粒度:ESC-50(50类环境声,2000样本,分10会话), UrbanSound8K/US8K(10类城市声,8732样本,分5会话), Speech Commands V2/SC2(35类关键词,105k样本,分7会话)。
- 细粒度:TIMIT-2/3(将630位说话人重构为315/210个任务,每任务2/3位说话人), VocalSet(16类歌唱技巧,分8会话)。
- 所有数据集按8:2划分训练/测试集。
- 损失函数:
- 主要损失:交叉熵损失 L_ce,用于分类。
- 正则化损失:边界感知正则化损失 L_reg(公式8),包含一个裕量δ,并计算特征到类中心距离与到边界点距离的差值。
- 总损失为 L_ce 与 L_reg 的加权和(论文未明确给出权重,可能默认为1或通过超参调节)。
- 训练策略:
- FSA阶段:
- Stage A:对所有层进行PEFT更新 E0 epoch,用于探测CKA。
- Stage B:以小学习率 η_head = 0.01 训练临时头 h1 E_head=1 epoch。
- Stage C:固定 h1,以较大学习率 η_bb = 0.05 仅对深层(l >= L_tune)进行LoRA适配 E0 epoch。
- MSA阶段:对每个新会话,以 η_bb 更新骨干,当累积样本数 > N_stop=220 时停止骨干适应。
- 优化器:论文未明确说明,可能使用AdamW等常见优化器。
- Batch Size:24。
- 训练Epoch数 (E0):按数据集不同,ESC-50:10, US8K:15, SC2:1, TIMIT-2/3:30, VocalSet:6(见表5)。
- FSA阶段:
- 关键超参数:
- LoRA秩 r:未明确说明。
- 层冻结阈值 ρ_layer:0.94。
- SVD能量阈值 ρ_svd:0.99。
- MSA停止阈值 N_stop:220。
- 边界扰动生成:扰动样本数 N_p=20,掩码比例未明确,误分类阈值 ρ_p=0.3。
- 正则化损失裕量 δ:0.25。
- 解析分类器随机投影维度 D_proj:8192。
- 训练硬件:NVIDIA A800 GPU。 推理细节:使用解析分类器 ϕ_t 进行推断,公式为 ŷ = W_proj z * W_t。
- 正则化/稳定技巧:包括骨干网络分阶段冻结/适应、梯度投影、基于样本数量的停止准则、边界感知正则化��
📊 实验结果
主要基准结果(表2):PACE在所有6个音频CL基准上取得最佳性能。
| 方法 | ESC-50 | US8K | SC2 | TIMIT-2 | TIMIT-3 | VocalSet |
|---|---|---|---|---|---|---|
| 联合训练上界 (LoRA) | 96.50 | 98.07 | 95.91 | 95.22 | 95.22 | 76.65 |
| 基线最优 (RanPAC/ACL) | 92.50 | 97.08 | 90.53 | 85.63 | 89.92 | 62.82 |
| PACE (Ours) | 95.75 | 97.49 | 91.87 | 90.95 | 94.05 | 69.08 |
与SOTA差距:在最具挑战性的细粒度VocalSet上,PACE比次优基线RanPAC高出6.26个百分点。在TIMIT-2上高出5.32个百分点。与联合训练上界的差距从基线的约13.8%(VocalSet)缩小到7.57%。
关键消融实验(表3, 表4):
- 改进FSA的有效性(表3):在粗粒度任务上,相比无FSA和朴素FSA,本文提出的FSA策略显著提升性能(例如在SC2上从81.22%提升至91.87%)。
- PACE各组件贡献(表4):在细粒度任务上,移除MSA、边界正则化或梯度投影均导致性能明显下降。例如在VocalSet上,移除梯度投影导致性能从69.08%暴跌至58.55%。
可视化分析:
- 表示偏移对比(图1):音频域(SC2)的会话间表示偏移(Shift=21.029)远大于视觉域(ImageNet-R, Shift=0.053)。
- 跨会话遗忘热图(图9):完整PACE方法能维持各会话的高准确率,而移除MSA或梯度投影会导致严重的跨会话遗忘(如图9c中会话1准确率从100%降至7.9%)。
- 边界扰动效果(图8):时间-频谱掩码(图8b)比加性噪声(图8a)能更好地保持数据流形结构和类一致性。
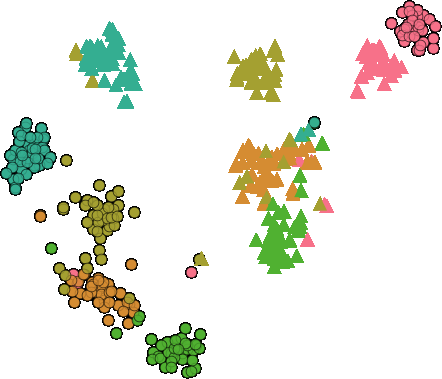 图1:在SpeechCommands V2(音频)和ImageNet-R(视觉)上的t-SNE可视化,显示音频域存在显著更强的表示偏移。
图1:在SpeechCommands V2(音频)和ImageNet-R(视觉)上的t-SNE可视化,显示音频域存在显著更强的表示偏移。
 图2:(a)和(b)显示了在图像和音频基准上,PEFT-FT方法在音频域性能下降更严重。(c)显示尽管PEFT-FT具有强可塑性,但大的表示偏移导致严重遗忘。
图2:(a)和(b)显示了在图像和音频基准上,PEFT-FT方法在音频域性能下降更严重。(c)显示尽管PEFT-FT具有强可塑性,但大的表示偏移导致严重遗忘。
 图3:(a)(b)显示RanPAC在粗粒度数据集上FSA对后续任务准确率提升有限,表明表示饱和。(c)显示冻结浅层能改善性能。
图3:(a)(b)显示RanPAC在粗粒度数据集上FSA对后续任务准确率提升有限,表明表示饱和。(c)显示冻结浅层能改善性能。
 图9:(a)PACE维持高准确率。(b)无MSA性能下降。(c)无梯度投影导致灾难性遗忘。
图9:(a)PACE维持高准确率。(b)无MSA性能下降。(c)无梯度投影导致灾难性遗忘。
 图10:ESC-50(粗粒度)和TIMIT(细粒度)的频谱图及PEFT-FT下的预测轨迹,展示细粒度任务的识别难度和遗忘严重性。
图10:ESC-50(粗粒度)和TIMIT(细粒度)的频谱图及PEFT-FT下的预测轨迹,展示细粒度任务的识别难度和遗忘严重性。
⚖️ 评分理由
- 学术质量:6.5/7:创新性明确,首次系统研究音频CL并提出完整解决方案PACE。技术路线正确,从问题分析到方法设计逻辑严谨。实验非常充分,覆盖多样基准、全面基线对比和详尽消融。证据可信,可视化支持有力。扣分点在于框架复杂度和未验证的极端场景泛化能力。
- 选题价值:1.8/2:音频持续学习是预训练模型实用化的核心挑战,具有高前沿性和广阔应用前景(如智能家居、自适应语音识别)。选题精准且重要。
- 开源与复现加成:0.5/1:论文明确承诺将开源所有基准、复现基线和代码,并提供了详细的算法伪代码(算法1)、超参数设置(附录D)和实验细节,复现友好度高。但当前仅提供论文,因此给予中等加分。