📄 MIAM: Modality Imbalance-Aware Masking for Multimodal Ecological Applications
#多模态模型 #掩码策略 #物种分布建模 #多模态物种分类 #生态学
✅ 7.5/10 | 前25% | #物种分布建模 | #掩码策略 | #多模态模型 #多模态物种分类
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Robin Zbinden, Wesley Monteith-Finas(*表示同等贡献)(瑞士洛桑联邦理工学院 - EPFL)
- 通讯作者:Robin Zbinden(robin.zbinden@epfl.ch)(瑞士洛桑联邦理工学院 - EPFL)
- 作者列表:Robin Zbinden(瑞士洛桑联邦理工学院 - EPFL), Wesley Monteith-Finas(瑞士洛桑联邦理工学院 - EPFL), Gencer Sumbul(瑞士洛桑联邦理工学院 - EPFL), Nina van Tiel(瑞士洛桑联邦理工学院 - EPFL), Chiara Vanalli(瑞士洛桑联邦理工学院 - EPFL), Devis Tuia(瑞士洛桑联邦理工学院 - EPFL)
💡 毒舌点评
亮点: 论文提出了一个原则性的掩码策略设计框架(完整支持、角落优先、不平衡感知),并通过数学公式化(混合乘积Beta分布)优雅地实现了这一点,有效解决了多模态学习中的模态不平衡问题,为生态学等数据不完整场景提供了强大的工具。 短板: 方法在相对简单的双模态数据集(SatBird)上优势不明显,表明其主要价值体现在模态数量多且存在显著不平衡的复杂场景;动态调整机制引入了额外的超参数(λ, κ)和基于验证集性能的在线调整,可能增加实际应用中的调参负担和训练不稳定性。
🔗 开源详情
- 代码: 是,提供了GitHub仓库链接:https://github.com/zbirobin/MIAM
- 模型权重: 是,提供了HuggingFace模型权重链接:https://huggingface.co/zbirobin/MIAM
- 数据集: 论文中使用了公开数据集GeoPlant和TaxaBench,并给出了数据划分的代码,但未说明数据集本身的获取链接(假设可从原数据集出处获取)。
- Demo: 未提及。
- 复现材料: 论文在附录A.1中提供了详细的训练设置(优化器、学习率、批大小、模型结构),A.3中描述了基线细节,并给出了数据划分的Python代码。超参数敏感性分析见附录A.4.1。
- 论文中引用的开源项目: 使用了verde库进行空间交叉验证,AdamW优化器,以及来自Sastry et al. (2025)的预训练编码器(TaxaBench实验)。
📌 核心摘要
- 要解决什么问题: 生态学等领域的多模态数据常存在缺失(模态级或内模态级)和模态不平衡(主导模态抑制其他模态的学习)问题。现有的数据掩码策略(如静态、均匀分布)无法充分探索输入组合空间,也未能有效缓解模态不平衡。
- 方法核心是什么: 提出MIAM(Modality Imbalance-Aware Masking),一种动态掩码策略。其核心是使用混合乘积Beta分布来定义掩码概率,该分布在单位超立方体上具有完整支持,并优先采样靠近角落(即大多数模态同时可见或同时被遮蔽)的点。同时,MIAM通过基于各模态独立性能(sm)和学习速度(dm)的系数动态调整分布参数,对主导模态施加更高的遮蔽概率,以促进对劣势模态的学习。
- 与已有方法相比新在哪里:
- 新框架: 首次将多模态掩码策略形式化为超立方体上的概率分布,并明确了三个关键设计原则:完整支持、角落优先、不平衡感知。
- 新机制: 提出了角落锚定的混合乘积Beta分布,能灵活且优先地采样输入组合的角落。更重要的是,引入了基于性能和学习速度的动态不平衡调整机制(ρ_sm / ρ_dm),比OPM等仅依赖静态性能分数的方法更能响应训练动态。
- 新效果: MIAM能同时实现细粒度(token级)和跨模态的遮蔽,并支持对任意输入子集的鲁棒预测和贡献分析。
- 主要实验结果如何:
- 在GeoPlant数据集(3模态)上,MIAM在平均AUC上比次优基线(OPM)高出2.3个百分点(86.1% vs 83.8%),在最具挑战性的卫星图像单模态评估中大幅缩小了与Oracle模型的差距(80.1% vs 81.4%)。
- 在TaxaBench数据集(5模态)上,MIAM在平均Top-1准确率上取得最佳成绩(38.7%),显著优于OPM(31.2%)。
- 消融研究证实了每个设计原则(角落优先、不平衡感知)带来的性能提升,特别是对受模态不平衡影响的模态。
- 贡献分析揭示了重要的生态学信号,如卫星图像的Red和NIR波段(用于计算NDVI)以及包含极端气候事件(如2003年欧洲热浪)的时间序列的重要性(见图5)。
- 实际意义是什么: MIAM提升了多模态生态模型在数据不完整情况下的预测鲁棒性和准确性。其支持的细粒度贡献分析(跨模态和内模态)能够提供可解释的生态学见解,识别关键的环境预测因子和时间/空间信号,有助于理解物种分布驱动因素和生态过程。
- 主要局限性是什么: 方法的效果依赖于超参数λ和κ的调整;动态调整依赖于验证集上的性能分数,在自监督学习等无标签场景下需要设计替代指标(如重建损失)。此外,在模态数量少(如双模态)且不平衡不显著的数据集上,优势可能不明显。
🏗️ 模型架构
MIAM本身不是一个独立的模型架构,而是一种应用于多模态Transformer模型的训练时数据掩码策略。其工作流程如下:
- 输入表示: 每个样本由M个模态组成,每个模态m包含Tm个token(高维向量)。这些token通过各自的分词器生成。
- 掩码生成: 在每个训练批次,MIAM为每个模态m生成一个掩码概率pm。这些概率构成向量p = (p1, …, pM),它从一个动态调整的混合乘积Beta分布中采样。该分布由两部分构成:
- 角落锚定分布: 由2^M个混合成分组成,每个成分是一个乘积Beta分布,其概率质量集中分布在超立方体的一个角落附近。角落(0,…,0)和(1,…,1)被赋予更高的权重(见公式3)。
- 不平衡感知调整: 每个角落成分的Beta分布参数(α或β)会被模态不平衡系数(ρ_sm / ρ_dm)动态调整(见公式5)。性能好且学习稳定(高ρ_sm/ρ_dm)的模态会被分配更高的遮蔽概率(Beta分布的参数调整使其集中在1附近)。
- 掩码应用: 对于模态m中的每个token,以概率pm独立地将其替换为一个可学习的“掩码嵌入”。
- 融合与预测: 将所有token(部分已掩码)输入一个标准的Transformer编码器进行跨模态交互。Transformer的输出经平均池化后通过一个线性层产生预测(如分类或回归)。
关键设计选择与动机:
- Token级独立掩码: 模型需要处理任意子集,而非仅模态级缺失。
- Beta分布: 相比均匀分布,Beta分布能灵活地将概率质量集中在0或1附近,从而自然实现“角落优先”。
- 动态调整: 固定分布无法适应训练过程中各模态学习动态的变化。通过监控每个模态的独立性能(sm)和学习速度(dm = |∇sm|),可以识别主导模态并增强对其的遮蔽,迫使模型关注其他模态。
- 混合成分与权重: 鼓励��型同时学习从“几乎无输入”到“几乎全输入”的极端情况,提升鲁棒性和贡献分析能力。
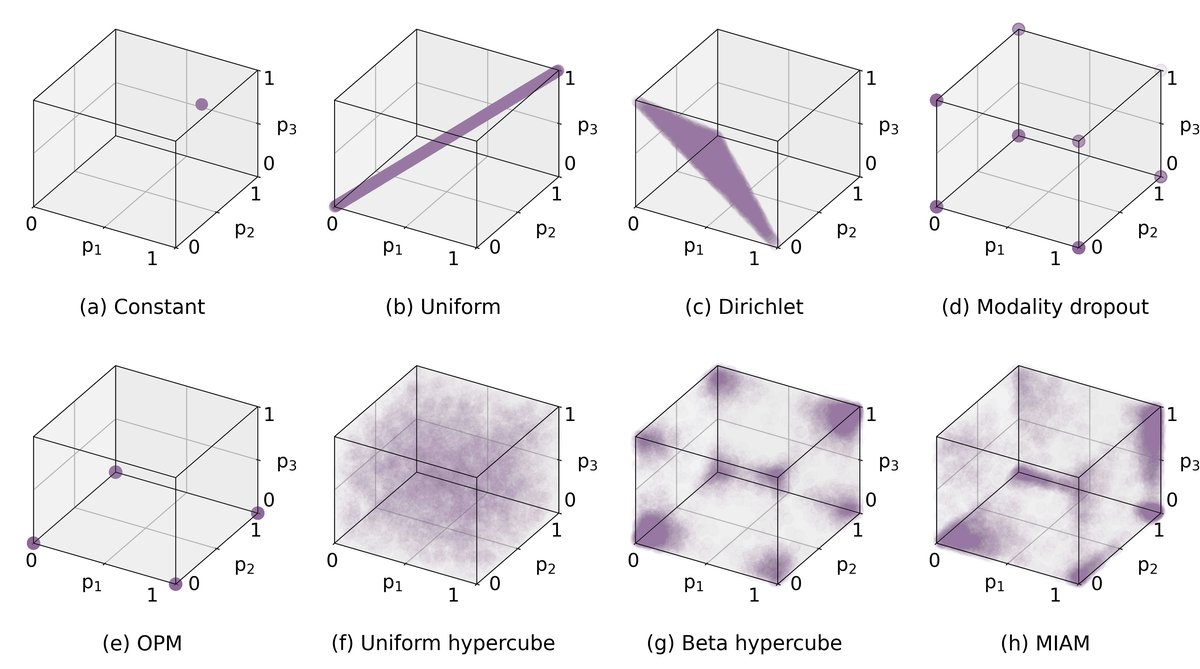 图2:MIAM概览。(a) 每个模态的token以概率pm被掩码,pm从混合乘积Beta分布中采样。(b) 分布参数由ρ_sm和ρ_dm调节,它们基于各模态的性能sm和其绝对导数dm计算。性能高且稳定的模态(高ρ_sm/ρ_dm)会被更频繁地掩码。
图2:MIAM概览。(a) 每个模态的token以概率pm被掩码,pm从混合乘积Beta分布中采样。(b) 分布参数由ρ_sm和ρ_dm调节,它们基于各模态的性能sm和其绝对导数dm计算。性能高且稳定的模态(高ρ_sm/ρ_dm)会被更频繁地掩码。
💡 核心创新点
- 形式化掩码策略为超立方体分布并设计新原则: 首次明确提出了有效掩码策略应满足的三个关键特性(完整支持、角落优先、不平衡感知),为后续研究提供了理论框架。这是方法论层面的创新。
- 角落锚定的混合乘积Beta分布: 这是一个灵活且可解释的概率分布构造方法。它解决了现有策略(如均匀、Dirichlet)在覆盖输入空间和强调关键配置(全有或全无)方面的不足。通过调整混合权重和Beta参数,可以定制掩码偏好。
- 基于性能与学习动态的不平衡感知机制: 创新地将模态性能(sm)和瞬时学习速度(dm)结合,生成自适应调整系数。这比仅依赖静态性能分数(如OPM)更全面,能更好地区分“强大且稳定”的主导模态与“正在快速学习”的模态,实现更精细的训练调控。
🔬 细节详述
- 训练数据:
- GeoPlant: 用于物种分布建模。包含3个模态:1)表格环境变量(48个token),2)Sentinel-2卫星图像(100个token),3)时间序列(气候+Landsat, 76+126个token)。数据按空间块交叉验证划分为训练(70%)、验证(15%)、测试(15%)。任务为多标签分类(1783个物种)。
- TaxaBench: 用于多模态物种分类。包含5个模态,每个模态1个token(来自预训练编码器):地面图像、卫星图像、音频、环境表格、地理位置。数据划分为训练(80%)、验证(10%)、测试(10%)。任务为单标签分类(199个物种)。
- 损失函数:
- GeoPlant: 使用加权二元交叉熵损失。
- TaxaBench: 使用标准交叉熵损失。
- 训练策略:
- 优化器:AdamW,权重衰减0.01。
- 学习率:0.001,使用无调度策略。
- 批大小:128。
- 训练轮数:100,使用基于验证AUC的早停。
- 基础模型:3层Transformer,8头注意力,token维度192。
- 关键超参数(MIAM):
- κ (Beta分布锐度): 10。
- λ (不平衡影响强度): GeoPlant设为3, TaxaBench设为1。
- 角落权重wc: 角落(0,…,0)和(1,…,1)各占1/4,其余2^M-2个角落均分剩余1/2。
- 训练硬件: 未说明。
- 推理细节: 推理时,模型可以处理任意输入子集。对于评估,同一个训练好的模型在不同输入子集上运行,无需重新训练。
- 正则化或稳定训练技巧: 使用dropout率0.1;MIAM本身的动态掩码也是一种有效的正则化。
📊 实验结果
主要基准与指标: 在GeoPlant上评估AUC(多标签分类),在TaxaBench上评估Top-1准确率(多分类)。
与最强基线对比:
- GeoPlant (AUC): MIAM平均AUC 86.1%,比次优方法OPM (83.8%) 高2.3%,接近Oracle (87.2%)。在最具挑战性的卫星图像单模态测试中,MIAM (80.1%) 远高于OPM (81.1%?),接近Oracle (81.4%)。
- TaxaBench (Top-1 Accuracy): MIAM平均准确率38.7%,优于Dirichlet (37.4%) 和Uniform (37.7%),显著优于OPM (31.2%)。
关键消融实验:
- 移除ρ_sm或ρ_dm成分会导致性能下降,平均AUC从85.4%降至约84.8-84.9%(见表5)。移除ρdm对卫星图像单模态性能影响最大(从80.1%降至76.4%)。
- 使用均匀角落权重wc会略微降低性能(平均AUC从85.4%降至85.2%)。
- 从均匀超立方体到Beta超立方体再到MIAM的演进,持续提升了受劣势模态(卫星图像)的性能(见图4左)。
不同条件下的细分结果:
- 模态不平衡感知: 图1显示,忽略不平衡的策略(Uniform, Constant等)在卫星图像单模态上性能甚至低于单模态模型。MIAM有效缓解了此问题。
- 模型规模影响: 在更大模型(6层256维,12层512维)上,MIAM仍保持平均性能领先,但整体性能因过拟合可能下降(见表6)。
- 自监督预训练实验: 在GeoPlant上,MIAM在SSL预训练后用于线性探测时,平均AUC达79.5%,优于Uniform (79.3%) 和Dirichlet (77.0%)(见表10)。
图表引用与说明:
- 图1 (icassp-img://oljjAkgZN4/0.jpg): 展示了模态不平衡问题。在GeoPlant上,忽略不平衡的掩码策略(如Uniform)在卫星图像单模态上性能差。MIAM通过自适应调整,使单模态性能接近Oracle。
- 图3 (icassp-img://oljjAkgZN4/2.png): 可视化了不同掩码策略在3维超立方体上的分布。MIAM的分布(h)对劣势模态3(被频繁掩码)的分布更集中于角落,且权重偏向两端。
- 图4 (icassp-img://oljjAkgZN4/3.png): 左图显示消融研究:从均匀超立方体到Beta超立方体再到MIAM,逐步提升卫星图像模态性能。右图显示MIAM的不平衡系数在训练中的动态变化,与验证性能波动对应。
- 图5 (icassp-img://oljjAkgZN4/4.png): 展示贡献分析:(a) 卫星图像的Red和NIR波段组合性能最高,符合NDVI计算原理。(b) 包含2003年热浪的更长时间序列显著提升性能,凸显极端事件的重要性。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文提出了一个清晰、原则性强的方法框架,并通过数学公式严谨地实现了三个设计原则。实验在两个有代表性的生态数据集上进行,与多种基线对比充分,消融研究细致,有力地证明了方法的有效性。主要不足在于方法在简单场景下优势不明显,且动态调整机制增加了复杂性。整体创新扎实,技术正确,实验充分。
- 选题价值:1.5/2 - 选题针对多模态学习中普遍存在的模态不平衡和数据缺失问题,尤其在生态学这一重要交叉领域具有明确的应用价值。方法不仅提升预测性能,还支持可解释的生态学发现,潜在影响较好。但相对于通用视觉-语言等主流多模态任务,生态学应用领域相对垂直。
- 开源与复现加成:0.5/1 - 论文明确提供了代码仓库链接(https://github.com/zbirobin/MIAM)和模型权重链接,复现信息(数据集划分代码、超参数、训练设置)在附录中给出较为详细。但模型规模和硬件细节未说明。开源透明度较高,对复现有积极帮助。