📄 MARS-Sep: Multimodal-Aligned Reinforced Sound Separation
#语音分离 #强化学习 #跨模态 #基准测试
✅ 7.5/10 | 前25% | #语音分离 | #强化学习 | #跨模态 #基准测试
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zihan Zhang(浙江大学)
- 通讯作者:Tao Jin(浙江大学)
- 作者列表:Zihan Zhang(浙江大学)、Xize Cheng(浙江大学)、Zhennan Jiang(中国科学院自动化研究所)、Dongjie Fu(浙江大学)、Jingyuan Chen(浙江大学)、Zhou Zhao(浙江大学)、Tao Jin(浙江大学)
💡 毒舌点评
亮点:这篇论文巧妙地将大语言模型对齐的核心思想——基于人类偏好的强化学习(RLHF)——“移植”到了声音分离任务中,并设计了与之匹配的多模态奖励模型和渐进式微调策略,为解决“分离干净但语义不匹配”的“指标困境”提供了新思路。短板:论文在与生成式分离模型(如FlowSep)对比时,虽然指出了自身在指标稳定性上的优势,但在某些语义相似度指标(如CLAP score)上并未全面超越,且声称的“一致性增益”在部分设置(如MUSIC数据集的音频查询)中较为微弱,对方法的普适优势论述可再严谨。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/mars-sep/MARS-Sep。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用公开数据集VGGSound和MUSIC,论文中未提及是否发布其预处理后的“clean+”子集。
- Demo:提供分离样本在线演示页面:https://mars-sep.github.io/。
- 复现材料:附录详细给出了训练细节(B部分)、SI-SDR计算(C部分)、RL训练细节(D部分)和所有超参数设置,复现信息充分。
- 引用的开源项目:依赖ImageBind作为多模态编码器,使用museval工具计算SDR指标。
📌 核心摘要
- 问题:通用声音分离存在“指标困境”,即模型在优化信噪比(SDR)等信号指标时,可能保留语义上不相关的干扰声,导致输出与用户查询意图不符。
- 核心方法:本文提出MARS-Sep,一个强化学习(RL)框架。它将声音分离重新定义为随机决策过程:基础分离模型作为“策略”,输出时频掩码;一个经过渐进对齐的多模态编码器作为“奖励模型”,评估分离音频与查询(文本/音频/图像)的语义一致性;通过基于裁剪信任区域的策略优化(类似PPO)来最大化奖励。
- 创新点:1)首创性地将查询条件声音分离形式化为受多模态奖励引导的RL问题。2)设计了分解Beta分布掩码策略,便于探索与利用的平衡。3)引入渐进式对齐训练,逐步增强ImageBind编码器的跨模态判别能力,为RL提供稳定可靠的奖励信号。
- 主要实验结果:在VGGSound-clean+和MUSIC-clean+两个数据集上,在文本、音频、图像及组合查询等多种条件下,MARS-Sep相比强基线(如OmniSep, AudioSep)均取得一致提升。例如,在VGGSound-clean+文本查询任务中,MARS-Sep的CLAP分数为9.03±0.94,高于OmniSep的8.98±0.89;SI-SDRi为4.55±0.44,高于OmniSep的4.38±0.48。消融研究证实了RL和渐进对齐策略的各自贡献。
- 实际意义:该方法能产生语义更准确、听感更干净的声音分离结果,更符合用户意图,有望提升下游任务(如语音识别、内容理解)的性能。
- 主要局限性:训练过程引入了RL的复杂性,需调优更多超参数(如β分布浓度κ、KL系数λ_KL);奖励模型依赖预训练的ImageBind,其能力上限可能影响最终性能;在部分设置下,与基线的提升幅度有限。
🏗️ 模型架构
MARS-Sep的整体架构(如图1所示)是一个强化学习循环系统,包含三个核心组件:基础策略(策略网络)、奖励模型和优化过程。
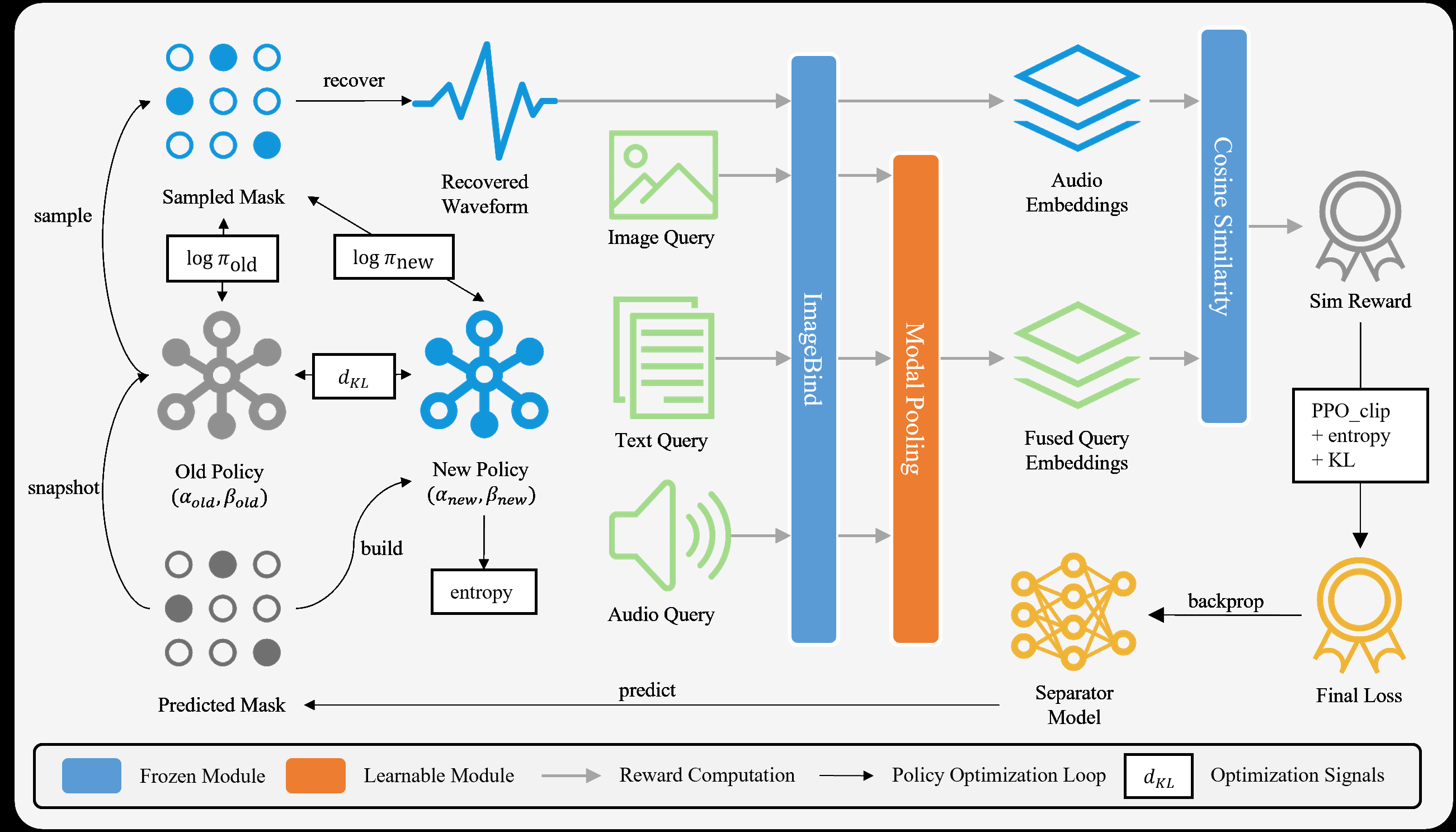 图1:MARS-Sep的强化学习循环。分离器从Beta分布策略中生成随机掩码动作,冻结的快照作为旧策略用于稳定优化。多模态奖励(来自音频、文本、视觉嵌入)指导策略更新,熵和KL正则化增强探索和稳定性。
图1:MARS-Sep的强化学习循环。分离器从Beta分布策略中生成随机掩码动作,冻结的快照作为旧策略用于稳定优化。多模态奖励(来自音频、文本、视觉嵌入)指导策略更新,熵和KL正则化增强探索和稳定性。
基础策略 (πθ):即声音分离模型本身。它接收状态S,包括混合音频的频谱图X和用户查询Q(文本、音频或图像)。策略网络(基于U-Net的Separate-Net)输出一个确定性掩码提议Pθ(X, Q) ∈ [0, 1]^{H×W×K}。为将其转化为随机策略,每个时频-频率bin的掩码值被参数化为一个因子化Beta分布 πθ(M|X, Q) = ∏{h,w,k} Beta(M{h,w,k}; α_{h,w,k}, β_{h,w,k}),其中α = 1 + κPθ, β = 1 + κ(1 - Pθ)。通过重参数化采样,从该分布中采样掩码M,与混合频谱结合后重建波形ŷ。
偏好奖励模型 (R):基于微调后的多模态编码器(ImageBind)。它接收分离音频ŷ的嵌入ϕ_a(ŷ),以及由目标音频y⋆、文本查询t⋆和视频帧v⋆通过多模态低秩双线性池化(MLBP) 融合而成的目标嵌入z⋆。奖励值R = sim(ϕ_a(ŷ), z⋆),即两者间的余弦相似度。MLBP显式建模了模态间的乘性交互,确保奖励反映联合多模态一致性,而非单一模态匹配。
优化过程:采用PPO风格的裁剪信任区域策略梯度进行更新。训练时,从旧策略π_θ_old采样掩码M,计算奖励R和优势A(通过移动平均基线b和可选的组相对归一化)。然后通过最小化损失函数L_RL(θ) = -J_clip(θ)来更新策略θ,其中J_clip包括裁剪的重要性比率、熵正则化H(πθ)和KL散度惩罚KL(πθ || π_θ_old)。更新后,将当前策略快照为新的旧策略。此设计无需价值网络,直接关联策略更新与多模态奖励。
 图2:用于声源判别和分离的渐进式微调策略。编码器保持冻结,任务特定的头逐步解冻,每个阶段都从前一阶段的最佳检查点开始。后两个阶段使用部分前序阶段的配对数据进行训练,以避免灾难性遗忘。
图2:用于声源判别和分离的渐进式微调策略。编码器保持冻结,任务特定的头逐步解冻,每个阶段都从前一阶段的最佳检查点开始。后两个阶段使用部分前序阶段的配对数据进行训练,以避免灾难性遗忘。
💡 核心创新点
- 将声音分离重新定义为受多模态奖励引导的强化学习问题:突破了传统监督学习直接回归掩码的范式,将分离目标转化为最大化语义对齐的决策过程。这使得优化目标直接针对最终用户意图(语义一致性),而不仅仅是信号保真度。
- 设计了因子化Beta分布掩码策略:将掩码生成从确定性预测变为在[0,1]区间上的随机采样。通过浓度参数κ控制探索-利用权衡,早期鼓励探索,后期趋向于二值掩码,更好地适应分离任务特性。
- 提出了渐进式多模态编码器对齐策略:为解决奖励信号可能不可靠的问题,设计了三阶段课程学习(见图2)逐步微调ImageBind编码器:1)音频-文本对齐建立语义锚点;2)音频-音频对比增强类别判别力;3)音频-视觉对齐整合视觉上下文。此策略显著提升了编码器在存在干扰时的判别能力,为RL提供了稳定、信息丰富的奖励信号。
🔬 细节详述
- 训练数据:在VGGSound(大规模,300+类别)和MUSIC(小规模,乐器)数据集上训练和评估。具体为VGGSound-clean+和MUSIC-clean+子集。预处理细节:音频采样率16kHz,长度65535样本(约4秒);STFT参数:滤波器长度1024,窗长1024,跳长256;图像调整为224x224。未提及具体的数据增强方法。
- 损失函数:主要优化目标为RL损失L_RL(θ) = -J_clip(θ),包含裁剪的策略梯度目标、熵正则化项H(πθ)和KL惩罚项KL(πθ || π_θ_old)。渐进式对齐阶段使用对比损失:第一阶段为对称InfoNCE损失(公式7);第二阶段结合InfoNCE、三元组损失和一致性损失(公式8);第三阶段在InfoNCE和三元组损失基础上,加入前两阶段的损失以防止遗忘(公式9)。
- 训练策略:优化器Adam,β1=0.9, β2=0.999,学习率2e-4,权重衰减0.01。批次大小128,训练200,000步。使用warmup和梯度裁剪(阈值1.0)。训练在单卡NVIDIA A100(40GB)上进行。MARS-Sep的RL训练需约8小时/epoch(10k步),是基线OmniSep(约4小时)的2倍。
- 关键超参数:Beta分布浓度参数κ默认为9;PPO裁剪范围ε=0.2;熵系数λ_H默认0.2;KL系数λ_KL默认0.1(也可设为0)。奖励计算使用EMA基线(β=0.92),并启用组相对优势归一化(GRPO)。
- 推理细节:推理时直接使用策略网络输出的掩码提议(均值)或进行一次采样(未明确说明,但通常RL训练后模型可用确定性推理)。实时因子(RTF)与基线OmniSep相当(约0.08-0.12秒/批次)。
- 正则化/稳定技巧:KL散度惩罚防止策略更新过大;熵正则化鼓励探索;梯度裁剪;渐进式微调避免灾难性遗忘。
📊 实验结果
论文在VGGSound-clean+和MUSIC-clean+数据集上,针对文本、音频、图像及组合查询四种设置,与多个基线方法进行了对比。
表1:VGGSound-clean+数据集对比结果
| 方法 | 查询类型 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|---|
| LASS-Net | 文本 | 3.98±1.02 | 7.63±0.85 | 4.24±1.00 | 4.25±0.76 | 5.12±0.71 |
| CLIPSEP-NIT | 文本 | 2.71±0.87 | 4.58±1.37 | 13.60±0.68 | 2.41±0.53 | 7.97±0.94 |
| AudioSep | 文本 | 6.26±0.87 | 8.69±0.90 | 12.85±0.92 | 4.01±0.59 | 8.21±0.96 |
| OmniSep | 文本 | 6.70±0.66 | 9.04±0.98 | 13.61±0.77 | 4.38±0.48 | 8.98±0.89 |
| MARS-Sep (ours) | 文本 | 6.91±0.68 | 9.14±1.00 | 13.73±0.77 | 4.55±0.44 | 9.03±0.94 |
| OmniSep | 音频 | 7.15±0.65 | 11.65±1.02 | 11.84±0.81 | 4.35±0.52 | 8.60±0.91 |
| MARS-Sep (ours) | 音频 | 7.33±0.67 | 11.63±1.00 | 12.00±0.84 | 4.36±0.50 | 8.91±0.91 |
| OmniSep | 图像 | 6.66±0.65 | 10.00±1.05 | 13.73±0.76 | 4.43±0.50 | 8.79±0.89 |
| MARS-Sep (ours) | 图像 | 6.93±0.67 | 10.18±1.04 | 13.41±0.72 | 4.57±0.47 | 9.19±0.91 |
| OmniSep | 组合 | 7.79±0.72 | 10.76±1.00 | 14.53±0.93 | 5.16±0.47 | 8.85±0.92 |
| MARS-Sep (ours) | 组合 | 7.93±0.75 | 10.65±1.00 | 14.49±0.95 | 5.20±0.45 | 9.22±0.90 |
表2:MUSIC-clean+数据集对比结果
| 方法 | 查询类型 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|---|
| OmniSep | 文本 | 12.37±0.85 | 17.51±1.16 | 17.96±0.90 | 9.18±0.79 | 5.41±0.98 |
| MARS-Sep (ours) | 文本 | 12.91±0.93 | 17.61±1.17 | 18.28±0.93 | 9.85±0.82 | 6.18±0.93 |
| OmniSep | 音频 | 10.37±0.86 | 17.76±1.05 | 14.51±0.88 | 7.18±1.07 | 5.39±1.01 |
| MARS-Sep (ours) | 音频 | 11.73±0.88 | 19.65±1.14 | 15.25±0.86 | 8.38±1.03 | 5.64±1.06 |
| OmniSep | 图像 | 13.03±0.96 | 18.97±1.16 | 17.88±1.00 | 10.21±0.89 | 6.53±1.03 |
| MARS-Sep (ours) | 图像 | 13.64±1.06 | 19.24±1.16 | 18.05±1.06 | 10.70±0.89 | 6.94±1.06 |
| OmniSep | 组合 | 13.29±0.96 | 19.55±1.17 | 17.88±0.96 | 10.22±0.89 | 6.35±1.05 |
| MARS-Sep (ours) | 组合 | 13.89±0.98 | 19.90±1.18 | 17.99±0.97 | 10.78±0.81 | 6.82±0.99 |
关键结论:MARS-Sep在绝大多数设置下取得了最佳的SDR、SI-SDRi和CLAP分数,表明其在信号保真度和语义一致性上的全面优势。SIR/SAR指标上与OmniSep各有胜负,但差距较小。
表3:与生成式方法的CLAP分数对比
| 方法 | 数据集 | CLAPt score (%) | CLAPa score (%) |
|---|---|---|---|
| ZeroSep | MUSIC-clean+ | 20.02 ± 15.14 | 22.86 ± 18.55 |
| FlowSep | MUSIC-clean+ | 10.67 ± 14.17 | 39.25 ± 29.86 |
| MarsSep (Ours) | MUSIC-clean+ | 6.18 ± 0.93 | 21.56 ± 1.08 |
| ZeroSep | VGGSOUND-clean+ | 15.91 ± 14.17 | 22.65 ± 19.98 |
| FlowSep | VGGSOUND-clean+ | 8.84 ± 13.27 | 56.07 ± 19.57 |
| MarsSep (Ours) | VGGSOUND-clean+ | 9.03 ± 0.94 | 18.70 ± 1.23 |
关键结论:生成式方法(ZeroSep, FlowSep)的CLAP分数方差极大,表明其输出语义一致性不稳定。MARS-Sep的方差小得多,提供了更可靠的语义对齐。
消融实验亮点(表11):在VGGSound-clean+文本查询设置下,“RL+渐进式微调”(完整模型)的CLAP分数为9.03±0.94,显著高���仅RL(8.96±0.90)、仅微调(5.48±0.95)和基线(8.98±0.89)的设置。证明了两者的协同增益。
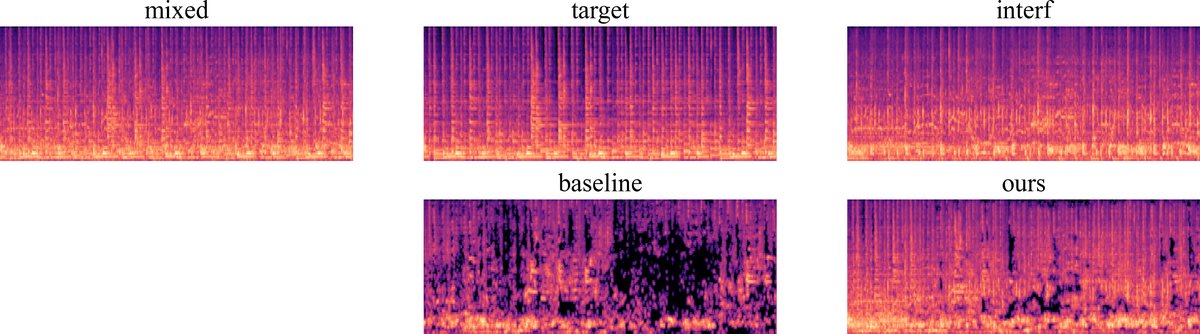 图3:在VGGSOUND-clean+数据集上,不同查询模态的分离音频log-mel谱图。目标源为“cattle bovinae cowbell”。从左到右:(a) “cattle bovinae cowbell”与“tap dancing”的混合;(b) 真实“cattle bovinae cowbell”;(c) 干扰“tap dancing”;(d) 基线模型文本查询分离;(e) 本文模型文本查询分离。
结论:图3直观显示,MARSSep的分离结果更好地保留了目标源的谐波结构和时域连续性,同时更有效地抑制了干扰成分(如“tap dancing”的块状缺失),佐证了其在语义一致性和信号保真度上的提升。
图3:在VGGSOUND-clean+数据集上,不同查询模态的分离音频log-mel谱图。目标源为“cattle bovinae cowbell”。从左到右:(a) “cattle bovinae cowbell”与“tap dancing”的混合;(b) 真实“cattle bovinae cowbell”;(c) 干扰“tap dancing”;(d) 基线模型文本查询分离;(e) 本文模型文本查询分离。
结论:图3直观显示,MARSSep的分离结果更好地保留了目标源的谐波结构和时域连续性,同时更有效地抑制了干扰成分(如“tap dancing”的块状缺失),佐证了其在语义一致性和信号保真度上的提升。
⚖️ 评分理由
- 学术质量:6.0/7:创新性强,将RL和偏好对齐引入音频分离是新颖且合理的尝试。技术细节扎实,Beta掩码、渐进对齐设计有明确动机。实验充分,在主流数据集和多种查询类型下进行了广泛对比和消融。证据可信度高,提供了定量结果、定性谱图、用户研究(附录)和效率分析。扣分点在于与最新生成式方法的对比角度可更深入,部分基线较老。
- 选题价值:1.5/2:选题紧扣音频处理核心挑战(语义对齐),融合了强化学习与多模态学习的前沿思想,对音频、语音、多模态社区均有参考价值,应用前景明确。
- 开源与复现加成:0.5/1:提供了代码仓库和项目主页,训练/评估超参数、硬件信息详细,复现门槛较低。但未提及是否发布预训练模型权重。