📄 LLM2Fx-Tools: Tool Calling for Music Post-Production
#音乐信息检索 #大语言模型 #多模态模型 #数据集 #音频效果
🔥 8.0/10 | 前25% | #音乐信息检索 | #大语言模型 #多模态模型 | #大语言模型 #多模态模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:SeungHeon Doh(KAIST, Sony AI)
- 通讯作者:Junghyun Koo(Sony AI)
- 作者列表:SeungHeon Doh(KAIST, Sony AI), Junghyun Koo(Sony AI), Marco A. Martínez-Ramírez(Sony AI), Woosung Choi(Sony AI), Wei-Hsiang Liao(Sony AI), Qiyu Wu(Sony Group Corporation), Juhan Nam(KAIST), Yuki Mitsufuji(Sony AI, Sony Group Corporation)
💡 毒舌点评
亮点:论文构建了一个从数据集到模型框架再到评估体系的完整闭环,首次将LLM的结构化工具调用能力系统地引入音乐效果链生成任务,实现了生成效果链、链式思考和自然语言响应的统一,思路清晰且工程化程度高。短板:实验评估基本在可控的单乐器场景下进行,离真实世界复杂的多轨音乐制作(如混音)仍有距离;效果链生成的“一对多”固有模糊性问题在评估中未被充分考量,可能高估了模型在真实场景下的精确性。
🔗 开源详情
- 代码:论文中未提及公开的代码仓库链接。
- 模型权重:未提及公开的模型权重。
- 数据集:提出了LP-Fx数据集,但未提供公开下载链接。论文中描述了其生成流程,理论上可复现。
- Demo:提供了在线演示链接:https://seungheondoh.github.io/llm2fx-tools-demo/
- 复现材料:提供了详细的训练策略(两阶段)、学习率、batch size、优化步数、LoRA配置等。附���中给出了完整的数据生成提示词和评估提示词。但未提供预训练检查点或配置文件。
- 论文中引用的开源项目:Pedalboard (音频效果器库), dasp-pytorch (用于基线DeepAFx-ST)。
📌 核心摘要
- 问题:音乐后期制作中,从音频反向工程或风格迁移来确定合适的效果器链(Fx-chain)及其参数,需要专业经验且耗时耗力。
- 核心方法:本文提出LLM2Fx-Tools,一个多模态LLM框架,利用链式思考(CoT)分解任务,并通过工具调用生成可执行的效果器链。模型以预处理后的干声、参考音频和指令作为输入,输出CoT推理、工具调用序列(效果器及参数)和自然语言回复。
- 创新点:与传统回归或微分优化方法相比,该框架能动态选择效果器类型、确定顺序,并提供可解释的推理过程;将任务从单模态音频预测扩展到多模态指令跟随。
- 实验结果:在LP-Fx数据集的反向工程任务中,LLM2Fx-Tools在效果器分类准确率(80%)和排序相关性(Spearman ρ=0.56)上显著优于基线;在听觉测试(MUSHRA)中,其得分(62.8)显著高于No Fx(39.1)、DeepAFx-ST(54.8)等方法。消融实验表明CoT和专用损失函数(NTL)对性能有显著贡献。
- 实际意义:为音乐制作提供了可解释、可控制的自动化工具,降低了非专业用户的专业门槛,并展示了LLM作为音乐生产助手的潜力。
- 主要局限:评估限于单乐器,未验证多轨混音场景;依赖Fx-Removal和归一化获得“伪干声”来解释预测;数据集规模有限;未评估对未知效果器模块的泛化能力。
🏗️ 模型架构
LLM2Fx-Tools是一个端到端的多模态自回归生成框架,旨在将音频输入转化为结构化的工具调用。
整体流程:输入包含自然语言指令、干声音频和参考音频。模型输出依次为:链式思考(CoT)、工具调用序列(Fx-chain)和自然语言回复。生成的工具调用可交由工具环境(实际的DSP效果器模块)执行,以变换新音频。
核心组件:
- 音频编码器 (Fx-Encoder++):采用对比学习预训练的专用音频编码器,提取音频的效果器相关表示。论文移除了其分类头,直接使用中间层的patch embedding。
- 音频-语言适配器:一个基于Transformer的跨模态对齐模块。它接收音频编码器的输出,通过线性投影层将其映射到语言模型的嵌入空间,并利用32个可学习的查询向量通过交叉注意力聚合信息,最终生成固定数量的音频token(e_audio)。
- 大语言模型 (Qwen3-4B):作为核心推理引擎。输入序列由指令token、分隔符token、干声音频embedding、参考音频embedding拼接而成。模型以自回归方式生成CoT、工具调用JSON和回复文本。采用LoRA进行高效微调。
- 工具环境 (T):由9个非微分的音频效果器模块(如压缩器、混响、均衡器等)组成,论文未提供其内部实现细节。
数据流:干声(x_dry)和参考音频(x_ref) → Fx-Encoder++ → 适配器 → e_audio_dry, e_audio_ref。与指令token拼接 → LLM → 生成CoT, 工具调用序列C, 回复。
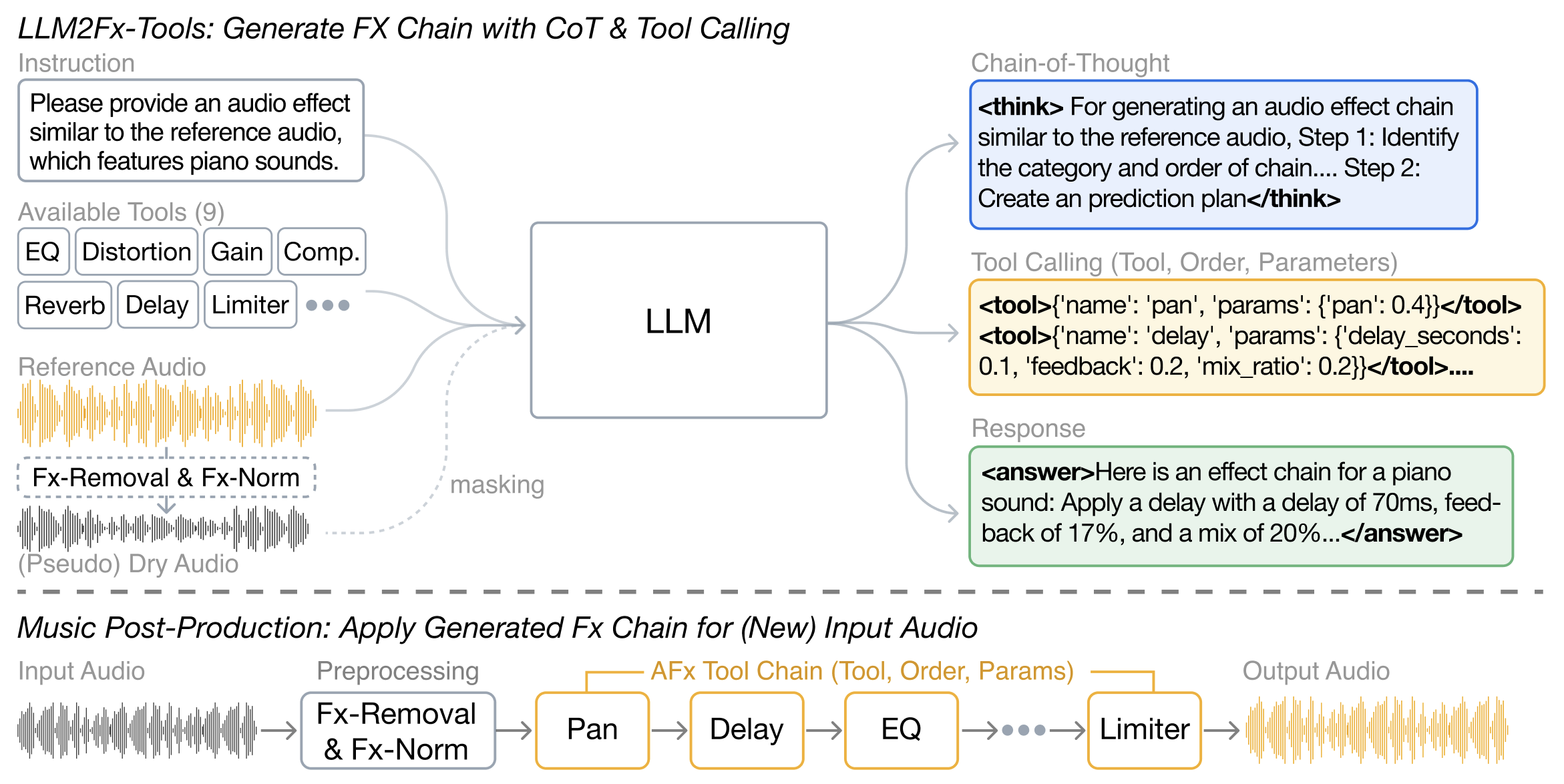 图1:展示了整体框架。输入(指令、工具集、参考音频、伪干声)经过预处理(Fx-Removal, Fx-Norm)后输入LLM,输出CoT、工具调用和回复。工具调用结果可应用于新音频。
图1:展示了整体框架。输入(指令、工具集、参考音频、伪干声)经过预处理(Fx-Removal, Fx-Norm)后输入LLM,输出CoT、工具调用和回复。工具调用结果可应用于新音频。
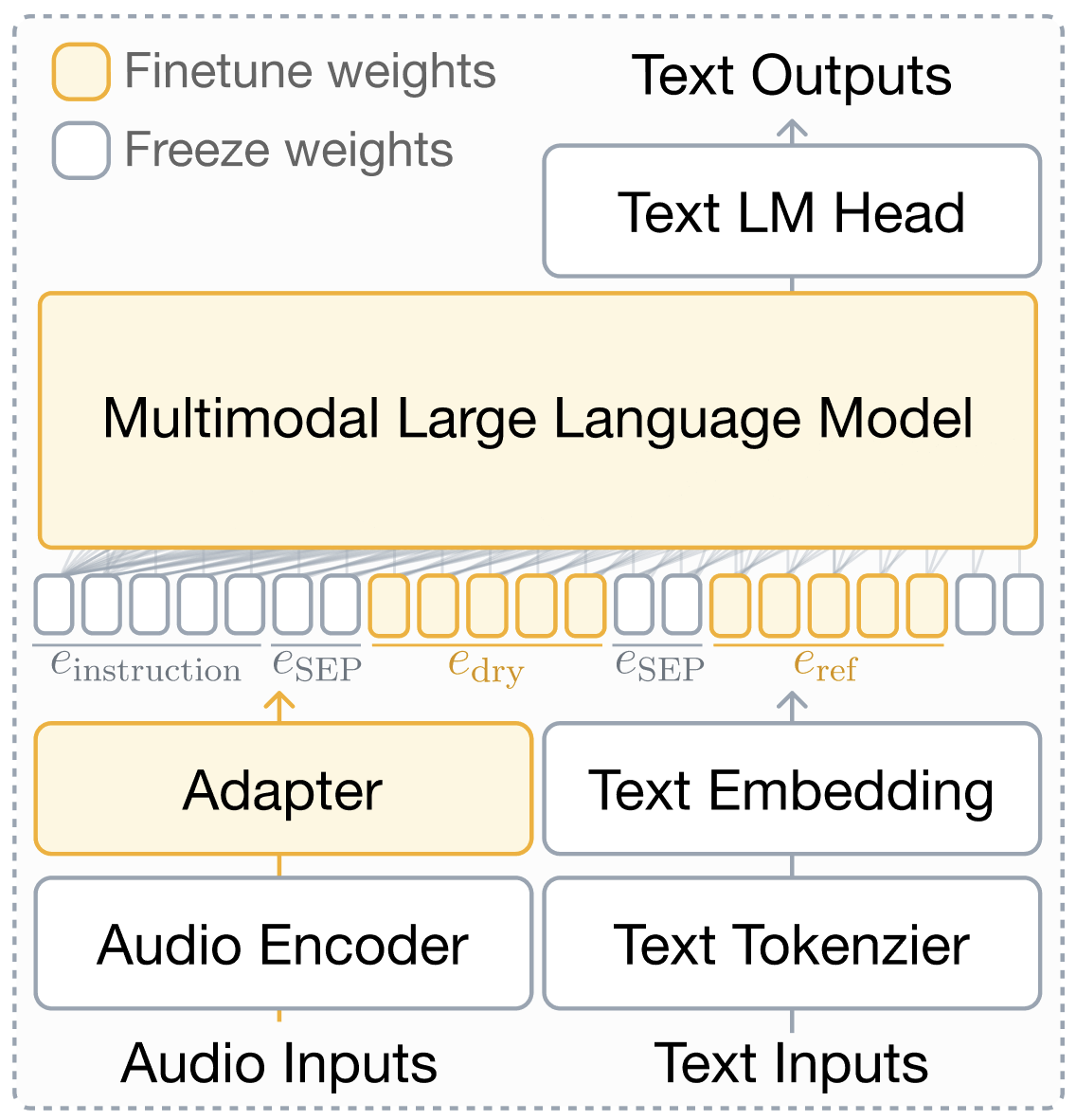 图2:展示了多模态自回归生成架构。音频通过编码器和适配器转化为与文本token拼接的序列,输入LLM进行生成。
图2:展示了多模态自回归生成架构。音频通过编码器和适配器转化为与文本token拼接的序列,输入LLM进行生成。
💡 核心创新点
- 音乐生产领域的结构化工具调用:首次将LLM的工具调用范式应用于音频效果链生成。将每个DSP效果器视为一个“工具”,LLM输出符合特定格式的JSON调用(含效果器名、参数),实现了从自然语言/音频到可执行程序代码的转换,增强了可控性。
- 专用于Fx-chain规划的链式思考(CoT):设计了四步CoT推理流程:1)用户输入分析,2)效果器选择,3)处理顺序确定,4)参数规划。这使得复杂的生成过程可分解、可解释,提升了推理准确性和透明度。
- 多模态指令跟随的Fx-chain估计:将任务从纯音频驱动(输入干声和湿声,预测Fx-chain)扩展到多模态(加入自然语言指令),允许用户指定效果器类型、音乐风格等,实现定制化生成。
- 专用数据集LP-Fx与生成流程:构建了首个包含结构化CoT和工具调用的大规模对话数据集(约10万条)。其四阶段生成流程(音频对合成、指令对话生成、CoT生成、LLM-as-a-judge过滤)确保了数据质量。
🔬 细节详述
- 训练数据:
- 音频源:MedleyDB,筛选后得到2119条原始音频,来自116个多轨录音,涵盖9种流派、80种乐器。
- 效果器环境:9个模块(3个自定义,6个来自Pedalboard库),共26个参数。
- LP-Fx数据集:约10万条对话。训练集99,900条,测试集900条。按效果器链长度(1-9)分层构建,确保平衡。每个样本包含:用户指令、干/湿音频对、工具调用序列、CoT、回复。
- 数据增强:在预训练阶段使用随机效果器采样;在训练时应用干声遮蔽(概率p_masking)以应对盲估计场景。
- 损失函数:
- 交叉熵损失(L_CE):标准的下一个token预测损失,仅在目标序列(CoT、工具调用、回复)上计算。
- 数字token损失(L_NTL-WAS):一种回归式损失,用于参数预测。计算预测数值分布与真实数值之间的Wasserstein-1距离,惩罚数值偏差。
- 总损失:L_total = L_CE + λ * L_NTL。λ为平衡超参数,论文未说明具体数值。
- 训练策略:采用两阶段训练。
- 阶段一(模态对齐预训练):仅使用音频和Fx-chain对,冻结LLM,仅训练适配器。学习率1e-4,批大小32,训练10万步。
- 阶段二(LLM微调):使用完整对话数据,同时更新适配器和通过LoRA微调LLM(秩128, alpha 256)。学习率5e-5,批大小16,训练40万步。
- 关键超参数:
- LLM基础模型:Qwen3-4B。
- LoRA:rank=128, alpha=256。
- 适配器查询向量数量:32。
- 干声遮蔽概率p_masking:论文未说明。
- 训练硬件:未说明。
- 推理细节:采用自回归解码。论文未说明具体的解码策略(如采样温度、beam size)。
📊 实验结果
主要评估任务与结果:
- 反向工程(Reverse Engineering):给定干声和参考声,预测Fx-chain。
表2:Fx-chain估计结果
方法 Fx-chain Planning (Acc.↑/Corr.↑/MAE↓) Perceptual Dist. (L/R↓/M/S↓) DSP AF↓ Embedding Sim. (AFx-Rep↑/FxEnc↑) No Fx - 13.11 / 13.49 14.82 0.50 / 0.30 Random Fx 52% / -0.01 / 0.39 8.07 / 8.90 13.70 0.41 / 0.34 Regression 55% / -0.03 / 0.20 3.81 / 4.12 9.20 0.62 / 0.64 MultiTask 61% / 0.00 / 0.23 3.17 / 3.39 8.39 0.63 / 0.66 DeepAFx-ST - 1.75 / 2.06 3.95 0.62 / 0.66 Gemini 2.5 Flash 78% / 0.54 / 0.32 3.42 / 4.24 14.97 0.56 / 0.50 LLM2Fx-Tools 80% / 0.56 / 0.23 3.13 / 3.27 8.29 0.68 / 0.67 w/o CoT 67% / 0.49 / 0.24 3.34 / 3.38 8.39 0.64 / 0.66 w/o NTL 73% / 0.51 / 0.32 3.69 / 3.52 8.47 0.61 / 0.63 w/o MST 76% / 0.55 / 0.25 3.21 / 3.32 8.30 0.67 / 0.64
关键结论:LLM2Fx-Tools在效果器选择和排序上优势巨大。DeepAFx-ST在感知距离上最优,但受限于可微分效果器库。消融实验显示CoT对规划能力提升最大,NTL对参数精度提升显著。
- 音频效果风格迁移(盲估计):仅从参考音频盲估计Fx-chain,应用于新输入音频。
表3:音频效果风格迁移结果
方法 DSP AF↓ Embedding Sim. (AFx-Rep↑/FxEnc↑) No Fx 8.69 0.24 / 0.43 Random Fx 15.22 0.14 / 0.19 Regression 7.83 0.24 / 0.31 MultiTask 7.62 0.29 / 0.46 DeepAFx-ST 10.50 0.26 / 0.49 Gemini 2.5 Flash 9.00 0.24 / 0.27 LLM2Fx-Tools 7.41 0.35 / 0.49
关键结论:LLM2Fx-Tools在跨数据集泛化中表现最佳,证明了其鲁棒性。Gemini 2.5 Flash在此任务上失败,印证了其参数估计能力弱。
- 自然语言生成:评估CoT和回复质量。
表4:自然语言生成结果
模型 Params Multimodal Reasoning TC Success IF Quality CoT Quality Qwen 2.5 Omni 7B ✓ ✗ 0.2% 1.46 N/A Qwen 3 4B ✗ ✓ 73.7% 2.89 2.30 Gemini 2.5 Flash N/A ✓ ✓ 100% 3.39 3.03 LLM2Fx-Tools 4B ✓ ✓ 99.8% 3.50 3.05
关键结论:LLM2Fx-Tools的工具调用成功率接近Gemini 2.5 Flash,且在指令跟随和CoT质量上更优,体现了领域微调的价值。
- 主观评估(MUSHRA测试):
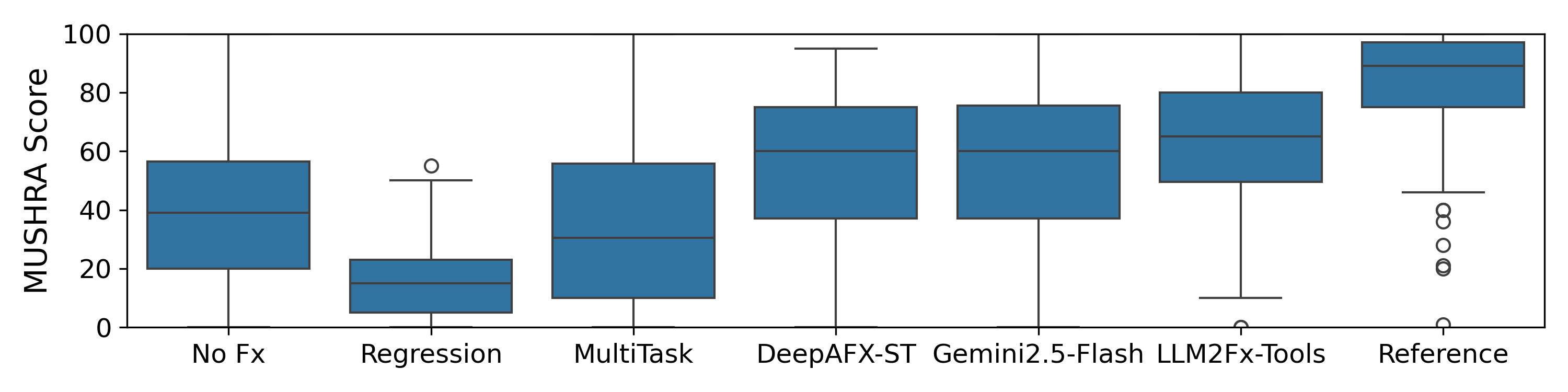 图4:展示了主观评分。LLM2Fx-Tools (62.8) 显著高于Gemini 2.5 Flash (56.5)、DeepAFx-ST (54.8) 和 No Fx (39.1)。Regression (16.2) 和 MultiTask (34.9) 得分低于No Fx,表明错误的效果应用比不加效果更差。
图4:展示了主观评分。LLM2Fx-Tools (62.8) 显著高于Gemini 2.5 Flash (56.5)、DeepAFx-ST (54.8) 和 No Fx (39.1)。Regression (16.2) 和 MultiTask (34.9) 得分低于No Fx,表明错误的效果应用比不加效果更差。
⚖️ 评分理由
- 学术质量:6.0/7:创新性良好,首次系统性地将LLM工具调用引入该领域;技术实现正确且完整;实验设计全面,覆盖多个任务和基线,并提供了详实的消融实验;证据可信度高。扣分点在于基线对比中,DeepAFx-ST在感知指标上仍有优势,且评估场景(单乐器)相对受限,限制了结论的普适性。
- 选题价值:1.5/2:选题前沿,探索了LLM在垂直专业领域(音乐制作)的应用,具有实际应用潜力。对于音频技术研究者而言是一个有价值的交叉方向。但应用场景相对专门,对广大语音/音频领域读者的直接相关性中等。
- 开源与复现加成:0.5/1:论文提供了详尽的实验细节、数据集描述和超参数,并给出了Demo链接。然而,缺乏开源的代码、预训练模型权重和完整的LP-Fx数据集下载,使得完全复现存在较高门槛。