📄 Learning multimodal dictionary decompositions with group-sparse autoencoders
#跨模态 #音频检索 #稀疏自编码 #对比学习 #多模态模型
✅ 7.5/10 | 前25% | #跨模态 | #稀疏自编码 | #音频检索 #对比学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Chiraag Kaushik (Georgia Institute of Technology, School of Electrical and Computer Engineering)
- 通讯作者:未说明
- 作者列表:Chiraag Kaushik (Georgia Institute of Technology, School of Electrical and Computer Engineering), Davis Barch (Dolby Laboratories), Andrea Fanelli (Dolby Laboratories)
💡 毒舌点评
本文精准地识别了稀疏自编码器(SAE)在多模态嵌入分解中的核心痛点——“字典分裂”,并通过一个直观的理论定理和一项巧妙的工程改进(群稀疏损失+交叉模态掩码)给出了系统性的解决方案,实验部分在图像-文本和音频-文本两个场景中均显示出稳健的增益。然而,其理论证明(定理1)的假设略显理想化,且对于“群稀疏损失”为何能如此有效地对抗SAE内置偏置的理论机制探讨尚浅,更像是一种经验性的成功,缺乏更深层的原理解释。
📌 核心摘要
这篇论文旨在解决标准稀疏自编码器(SAE)应用于对齐的多模态嵌入空间(如CLIP、CLAP)时出现的“字典分裂”问题,即学到的稀疏特征大多仅对单一模态激活,破坏了跨模态语义对齐。作者首先理论上证明,在对齐的嵌入空间中,一个分裂的字典总能被改进为一个对齐更好的非分裂字典。为此,他们提出了“群稀疏自编码器”,核心创新在于两点:1)在训练损失中引入针对成对样本的群稀疏正则项(L2,1范数),强制不同模态的嵌入产生相似的稀疏编码结构;2)引入交叉模态随机掩码,进一步迫使TopK激活选择共享子集。实验在CLIP(图像/文本)和CLAP(音频/文本)嵌入上进行,结果显示:相比标准SAE,其方法显著增加了双模态激活的神经元数量(死神经元减少),提升了新提出的“多模态单义性分数(MMS)”,并在多个零样本跨模态任务上取得了大幅性能提升(如在CIFAR-10上从0.657提升至0.842)。该工作首次将SAE应用于音频/文本嵌入空间(CLAP),并展示了如何利用学到的多模态字典进行概念级别的检索控制和线性探测器的可解释性分析。
🏗️ 模型架构
本文提出的“掩码群稀疏自编码器(MGSAE)”架构是对标准TopK稀疏自编码器的改进。其核心数据流与组件如下:
- 输入:成对的多模态嵌入向量
(x, y),来自对齐的嵌入空间(如CLIP),维度为d。 - 编码器:
- 两个模态共享编码器权重
Wenc,但使用独立的偏置项b0和b1。 - 对每个模态的输入,先进行线性变换
Wenc(x - b0) + b。 - 关键步骤(交叉模态随机掩码):在应用TopK激活前,对上述线性变换的输出施加一个共享的随机掩码(概率为
p),将部分特征置零。这迫使TopK操作在每次迭代中只能从剩余的特征子集中选择,从而促进两个模态在相同特征维度上产生激活。 - 应用TopK稀疏激活函数
Π,仅保留最大的K个激活值,得到稀疏码zx和zy。
- 两个模态共享编码器权重
- 解码器:
- 共享解码器权重
Wdec。 - 利用稀疏码重建原始嵌入:
ˆx = Wdec zx + b0,ˆy = Wdec zy + b1。
- 共享解码器权重
- 损失函数:
- 重建损失:标准的L2损失,衡量重建嵌入与原始嵌入的差异。
- 群稀疏损失
Lgs:作用于稀疏码对(zx, zy),计算公式为Lgs(zx, zy) = ||[zx; zy]||_{2,1} = Σ_i sqrt(z_{x,i}^2 + z_{y,i}^2)。这一范数鼓励对应坐标i的值z_{x,i}和z_{y,i}同时为零或同时为非零,即联合稀疏性。 - 总损失:
L = L_recon_x + L_recon_y + λ * Lgs。
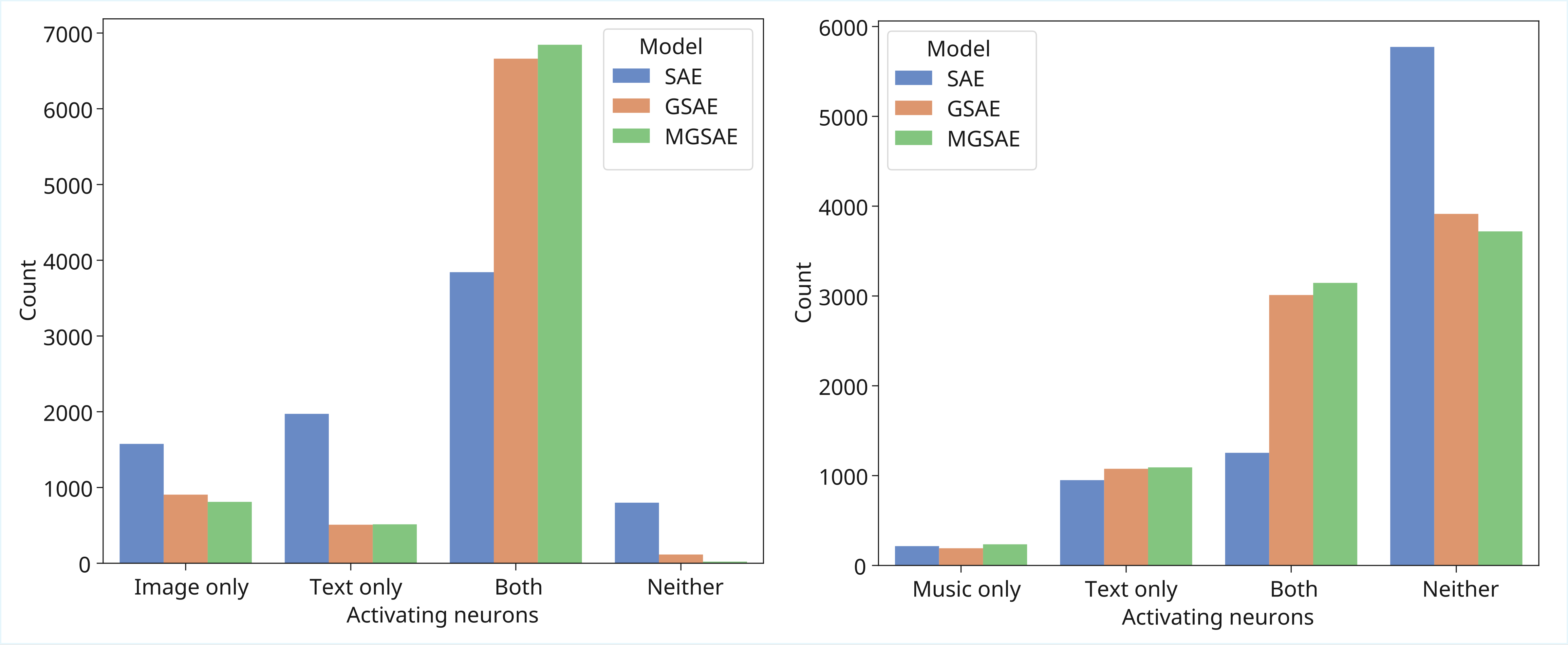 图2 直观展示了该流程:来自预训练编码器的对齐嵌入,分别经过共享的SAE编码器(含掩码和TopK),产生稀疏码,再经共享的线性SAE解码器重建,损失由重建损失和群稀疏损失组成。
图2 直观展示了该流程:来自预训练编码器的对齐嵌入,分别经过共享的SAE编码器(含掩码和TopK),产生稀疏码,再经共享的线性SAE解码器重建,损失由重建损失和群稀疏损失组成。
💡 核心创新点
针对多模态SAE的理论保证(定理1):
- 是什么:证明了在对齐嵌入空间中,若存在一个模态分裂字典,则必然存在另一个非分裂字典,在保持重建能力的同时,能严格改善模态间的编码对齐。
- 之前局限:此前观察到“分裂字典”现象,但未明确这是SAE优化目标(仅重建损失)带来的隐性偏差,还是线性表示假设本身在多模态下的根本限制。
- 如何起作用:该定理从理论上支持了通过修改训练目标(如增加对齐约束)来引导SAE学习多模态字典的可能性。
- 收益:为提出群稀疏损失等正则化方法提供了理论动机和信心。
提出“多模态单义性分数(MMS)”评估指标:
- 是什么:衡量单个SAE神经元在成对模态上的语义一致性和多模态激活程度。它计算该神经元激活的所有跨模态样本对之间的余弦相似度的加权平均值。
- 之前局限:已有的单义性指标(如Pach et al. 2025的MS分数)通常针对单模态或简单地将不同模态的激活分开计算,无法直接量化一个概念在跨模态上的对齐程度。
- 如何起作用:通过计算跨模态激活样本间的相似度并赋予高权重,MMS直接奖励那些既语义连贯(相似样本激活)又多模态(不同模态样本共同激活)的神经元。
- 收益:提供了一个量化评估多模态字典质量的关键工具,实验证明MGSAE的MMS分数显著优于基线SAE(见图4)。
群稀疏损失与交叉模态掩码的协同设计:
- 是什么:同时采用两种技术来对抗分裂偏置:1)在损失函数中加入显式的群稀疏正则项,直接惩罚跨模态稀疏编码的不一致;2)在编码过程中加入随机掩码,通过结构化的输入扰动,从优化路径上鼓励共享的激活模式。
- 之前局限:标准SAE仅优化重建损失,容易为每个模态找到独立的、更简单的表示路径,导致特征分裂。
- 如何起作用:群稀疏损失是直接约束,掩码是间接引导。两者结合,在优化过程中形成了更强的、指向多模态解的偏置。
- 收益:实验表明,同时使用两者(MGSAE)的效果优于仅使用群稀疏损失(GSAE),在减少死神经元、提升MMS分数和零样本任务性能上均达到最佳。
🔬 细节详述
- 训练数据:
- CLIP设置:CC3M图像-文本对数据集(约330万对)。预处理为归一化的单位向量嵌入。
- CLAP设置:JamendoMaxCaps音乐-文本对数据集。使用专为音乐微调的CLAP检查点获取嵌入。
- 评估时使用对应数据集的验证集(如CC3M val, MusicBench)。
- 损失函数:见上文模型架构部分。
λ为群稀疏损失权重,通过交叉验证选择(在CLIP设置中为0.05)。 - 训练策略:
- 优化器:Adam。
- 学习率:依据Gao et al. (2024) 的缩放法则选择。
- 批大小:128。
- 训练步数:CLIP设置25000步;CLAP设置10000步。
- 其他变体(BatchTopK SAE)也遵循相同训练设置以保证公平对比。
- 关键超参数:
- 原始嵌入维度
d = 512。 - 字典扩展因子 = 16,故字典维度
p = 16 * 512 = 8192。 - 稀疏度
K = 32。 - 随机掩码概率
p:通过交叉验证选择(CLIP为0.2,CLAP为0.1)。 - 群稀疏参数
λ:CLIP和CLAP设置均为0.05。
- 原始嵌入维度
- 训练硬件:未说明。
- 推理细节:在零样本任务评估中,使用学得的SAE对输入嵌入进行编码得到稀疏码
z,然后使用z与另一模态嵌入的稀疏码计算余弦相似度进行分类或检索。 - 正则化技巧:除了群稀疏损失,还使用了TopK本身作为强稀疏性约束。论文未提及使用L1正则化或Dropout等其他技巧。
📊 实验结果
论文在多个任务和数据集上验证了MGSAE的有效性。
- 零样本跨模态分类性能(CLIP嵌入):
模型 CIFAR-10 CIFAR-100 ImageNet SAE - TopK 0.657 0.418 0.303 BatchTopK SAE 0.657 0.277 0.178 Matryoshka SAE 0.587 0.166 0.185 GSAE (ours) 0.808 0.526 0.354 MGSAE (ours) 0.842 0.554 0.373 CLIP ViT B/16 (原嵌入) 0.916 0.687 0.686
关键结论:所有标准SAE变体性能大幅下降,而群稀疏变体(GSAE, MGSAE)性能显著提升,MGSAE达到最佳,在CIFAR-10上比标准SAE高出近20个百分点。
- 零样本音频/文本任务性能(CLAP嵌入):
模型 GTZAN 流派分类 NSynth 乐器分类 FMACaps 检索 (MRR) SAE - TopK 0.376 0.265 0.023 GSAE (ours) 0.705 0.303 0.050 MGSAE (ours) 0.672 0.354 0.061 LAION CLAP (原嵌入) 0.710 0.339 0.075
关键结论:在音频任务上,群稀疏变体同样远超标准SAE。在GTZAN分类上,GSAE几乎追平原嵌入性能。这是首次将SAE应用于音频-文本嵌入空间的工作。
多模态神经元与死神经元分析(图3):
 关键结论:标准SAE(黄色)大量神经元仅对单一模态激活,且有相当数量的死神经元(Neither)。GSAE(绿色)和MGSAE(蓝色)显著增加了“Both”(双模态激活)的神经元数量,并大幅减少了“Neither”(死神经元)。MGSAE效果最优。
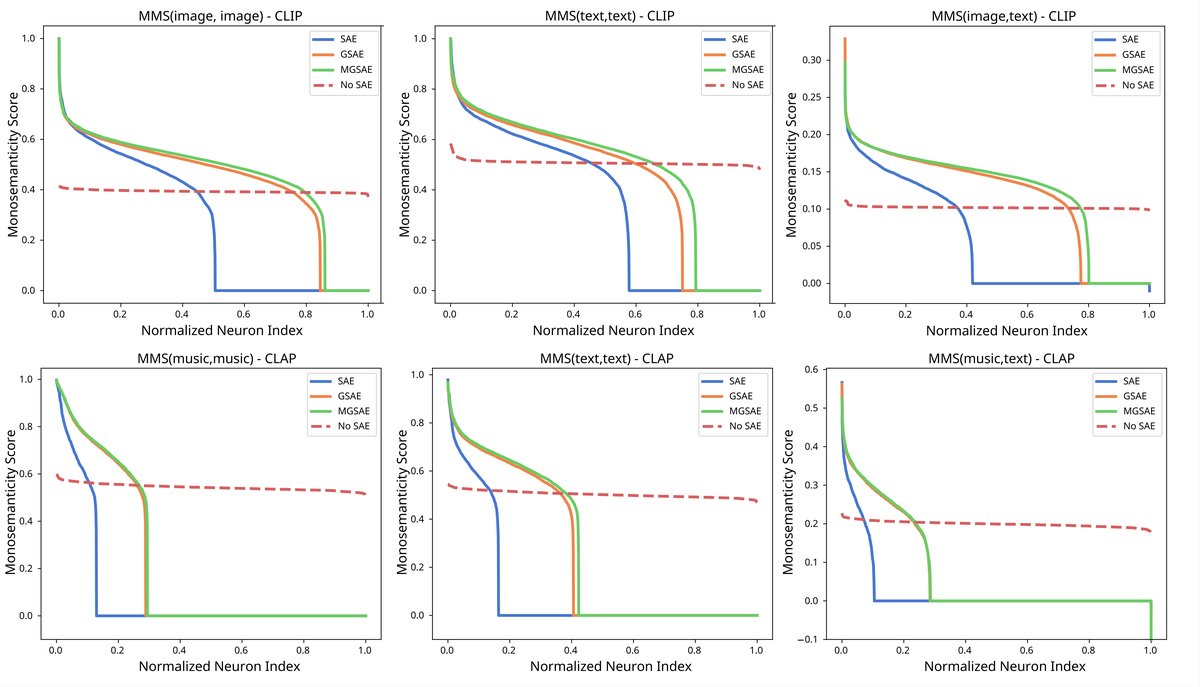
关键结论:标准SAE(黄色)大量神经元仅对单一模态激活,且有相当数量的死神经元(Neither)。GSAE(绿色)和MGSAE(蓝色)显著增加了“Both”(双模态激活)的神经元数量,并大幅减少了“Neither”(死神经元)。MGSAE效果最优。多模态单义性分数(MMS)分析(图4):
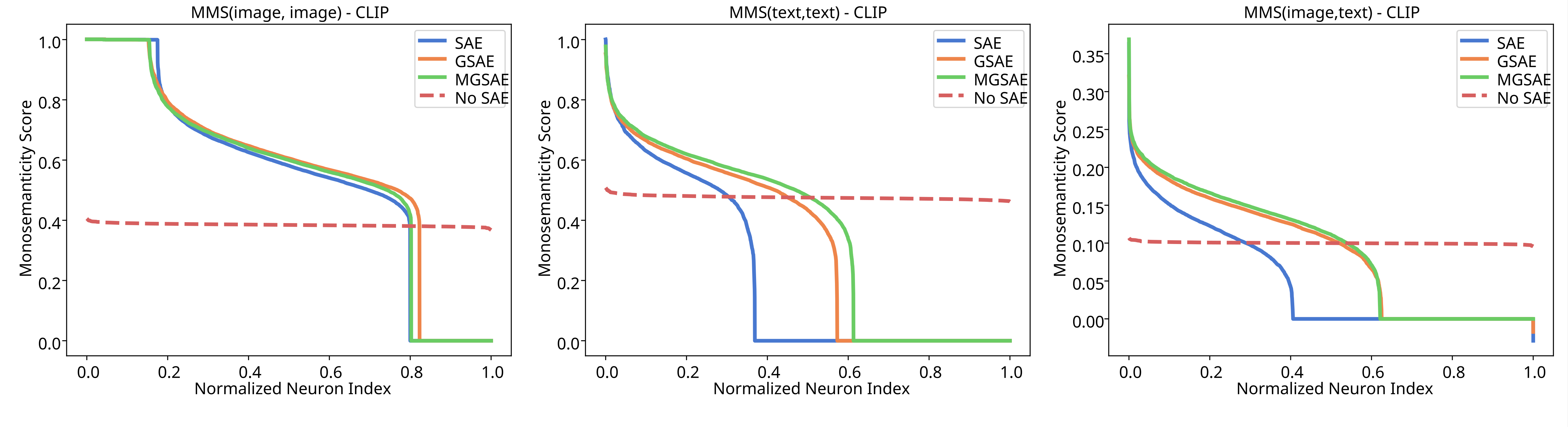 关键结论:标准SAE(橙线)大部分神经元的MMS分数(尤其是跨模态的
关键结论:标准SAE(橙线)大部分神经元的MMS分数(尤其是跨模态的MMS(image, text))接近零。而GSAE(绿线)和MGSAE(蓝线)的大量神经元获得了高MMS分数,表明它们学到了更多既语义连贯又多模态的概念。消融实验(附录表3):在不同扩展因子和K值下,MGSAE的零样本性能(ImageNet)始终最优,证明了方法的鲁棒性。K值增大时,所有模型性能提升。
可解释性案例研究(图5):在CelebA“金发”分类任务中,基于MGSAE字典的概念分析能正确识别“金发”、“金发女孩”等关键概念,并揭示“女孩”、“女人”等潜在混淆因素。而标准SAE的分析结果包含“仙人掌”、“北极熊”等无关概念,表明其字典的多模态语义质量不足。
⚖️ 评分理由
- 学术质量:6.5/7。本文提出了一个定义明确且重要的实际问题(多模态SAE的分裂字典),提供了理论定理作为动机,设计了创新且有效的解决方案(群稀疏损失+掩码),并引入了新的评估指标(MMS)。实验设计严谨,在两个不同的多模态场景(图像-文本、音频-文本)中验证了方法,结果一致且增益显著。扣分点在于理论定理的假设较强(完美对齐、精确K稀疏分解),且对方法有效性的深层原因(如与优化景观的关系)探索不足。
- 选题价值:1.5/2。研究神经网络表示的可解释性是前沿方向,而将SAE扩展到多模态并解决其核心缺陷,对理解和控制多模态大模型(如CLIP, CLAP)具有直接的实际意义。工作对音频/语音研究者也有价值,因为CLAP是音频-语言对齐的重要模型,且该方法首次将其应用于音频嵌入的分解。
- 开源与复现加成:0.0/1。论文详细说明了实验设置、超参数和使用的开源库(Marks et al., 2024的SAE库),并提供了详尽的附录。但论文中未明确提及是否开源自己的代码、模型权重或训练脚本,因此无法给予加成。依赖外部开源项目,但未给出自己的复现保证。