📄 Learnable Fractional Superlets with a Spectro-Temporal Emotion Encoder for Speech Emotion Recognition
#语音情感识别 #时频分析 #端到端 #音频分类
✅ 7.5/10 | 前25% | #语音情感识别 | #时频分析 | #端到端 #音频分类
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Alaa Nfissi (Concordia University, Concordia Institute for Information Systems Engineering; Université TÉLUQ, Data Science Laboratory (DOT-Lab))
- 通讯作者:Brian L. Mishara (University of Québec at Montréal, Psychology Department; Center for Research and Intervention on Suicide, Ethical Issues and End-of-Life Practices)(根据作者列表顺序及机构性质推断)
- 作者列表:Alaa Nfissi(Concordia University, Université TÉLUQ)、Wassim Bouachir(Université TÉLUQ, Data Science Laboratory (DOT-Lab))、Nizar Bouguila(Concordia University, Concordia Institute for Information Systems Engineering)、Brian L. Mishara(University of Québec at Montréal, Psychology Department; Center for Research and Intervention on Suicide, Ethical Issues and End-of-Life Practices)
💡 毒舌点评
这篇论文将经典的信号处理理论(Superlet)与现代可微学习框架结合得堪称教科书级别,数学推导和实验设计都非常严谨扎实,特别是那张展示学习到的分数阶分布与频率关系的可视化图(图5)非常直观地展示了模型的“可解释性”。但其短板在于,以“紧凑”为名的STEE编码器在搭配LFST前端后,实际计算开销(FLOPs、延迟、显存)远高于STFT、LEAF等基线(见附录表5),这使得“高效”二字在实时或资源受限场景下需要打上问号,论文在“效率-性能”权衡的讨论上稍显不足。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/alaaNfissi/LFST-for-SER。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:IEMOCAP和EMO-DB是公开的标准数据集;NSPL-CRISE是私有数据集,论文中未说明其公开获取方式。
- Demo:未提供在线演示。
- 复现材料:论文提供了极其详细的训练协议、超参数设置(表8)和算法伪代码(算法1-3),并在附录中提供了符号表、梯度推导和复杂度分析,复现信息非常充分。
- 引用的开源项目:论文依赖于PyTorch等标准深度学习框架,未明确引用其他特定的开源模型或工具作为其核心依赖。
📌 核心摘要
这篇论文旨在解决传统语音情感识别(SER)前端(如STFT、小波变换)时频分辨率权衡固定、无法自适应数据的问题。其核心方法是提出可学习分数阶Superlet变换(LFST),一个完全可微的时频前端,它能联合优化频率网格、每个频带的基循环数和分数阶权重,从而在连续的分数阶域中学习最优的时频分析策略。此外,论文设计了相位一致性(κ)通道和可学习非对称硬阈值(LAHT)模块来增强表示,并集成了一个紧凑的光谱-时间情感编码器(STEE)。与已有方法相比,LFST首次将分数阶Superlet理论转化为端到端可学习的模块,并提供了连续、稳定的数学框架。实验在三个标准数据集(IEMOCAP, EMO-DB, NSPL-CRISE)上进行,LFST+STEE系统在准确率、宏F1等指标上均达到了当时的最佳水平(例如,在IEMOCAP上Acc=0.875, F1=0.868;在EMO-DB上Acc=0.914, F1=0.904)。该工作的实际意义在于为语音/音频分析提供了一个数学基础扎实、可解释性强的可学习时频前端替代方案。主要局限性在于其计算成本显著高于基于FFT的前端,且评估主要集中在受控实验设置中,未与大规模自监督模型(如wav2vec 2.0)在相同预训练范式下直接比较。
🏗️ 模型架构
本文的系统由两大部分组成:可学习分数阶Superlet变换(LFST)前端和光谱-时间情感编码器(STEE)。
 LFST前端(图1):接收原始波形
LFST前端(图1):接收原始波形 x 作为输入。其核心是为每个频率带 f_i 和阶数 o(从1到O)学习一组Softmax权重 w_{i,o},这些权重在离散阶数上形成一个凸组合,从而定义一个有效阶数 o_eff。对于每个 (f_i, o) 组合,使用一个由学习到的 c_1(f_i) 决定的DC校正Morlet小波进行卷积,得到复数响应 W_{i,o}。所有阶数的响应通过对数域加权几何平均聚合,得到最终的幅度图 S。同时,通过加权单位相量求和得到相位一致性图 κ,用于衡量跨阶的相位对齐程度。S 和 κ 作为双通道输入传递给STEE。LFST还包含一个可学习非对称硬阈值(LAHT)模块,仅对幅度图 S 进行稀疏化去噪。此外,频率网格和基循环数 c_1 也是可学习的参数。
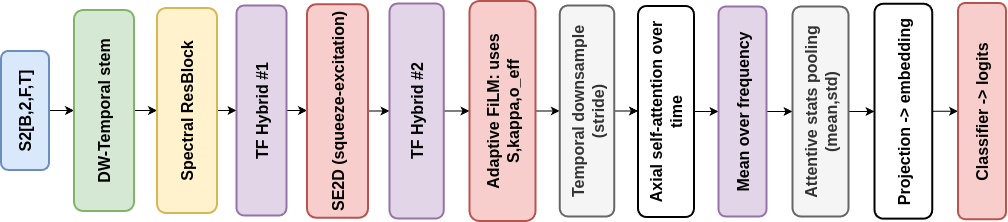 STEE编码器(图2):接收双通道TF图
STEE编码器(图2):接收双通道TF图 S2 = [S, κ]。其处理流程为:1) 时间深度卷积主干:沿时间维度进行深度卷积,捕获局部时序模式;2) 频谱残差块:沿频率维度进行深度卷积,捕获跨频带相关性;3) TF混合残差块与SE模块:并行使用时间和频率方向的深度卷积分支,融合后接Squeeze-and-Excitation通道注意力;4) 自适应FiLM频率门控(图3):利用 S 和 κ 的时序统计量以及 o_eff 生成逐频率的通道调制因子,实现内容感知;5) 时间下采样与轴向自注意力:在时间维度下采样后,沿时间轴应用局部多头自注意力;6) 注意力统计池化与投影:在时间维度进行注意力加权的均值和标准差池化,拼接后投影得到最终的情感嵌入,再通过线性分类器输出类别。
💡 核心创新点
- 可学习的分数阶Superlet变换(LFST):将传统的、参数固定的整数/分数阶Superlet理论,重构为一个端到端可微、可学习的前端。通过Softmax权重在连续阶数域进行凸组合,实现了分辨率权衡的平滑、数据驱动学习,避免了离散阶数的“带状”伪影。
- 相位一致性(κ)通道的显式引入:在基于小波的时频表示中,显式计算并利用跨阶的相位一致性信息。这为编码器提供了超越纯幅度的、关于信号结构一致性(如谐波、瞬态)的补充特征,在噪声环境下尤其有价值。
- 可学习非对称硬阈值(LAHT):设计了一个平滑的、可微的阈值化模块,对时频激活进行稀疏化和去噪,同时保持可微分性,允许端到端训练。其非对称设计提供了更大的灵活性。
- 紧凑的光谱-时间情感编码器(STEE):设计了一个轻量但结构精巧的编码器,有效融合了学习到的双通道时频表示(S, κ)及其侧信息(o_eff),通过深度可分离卷积、自注意力和注意力池化,在参数量不大的情况下实现了强大的表示学习。
🔬 细节详述
- 训练数据:使用了三个数据集:IEMOCAP(约12小时,10039条,4类情感)、EMO-DB(535条,7类情感,德语)、NSPL-CRISE(2999条,5类情感,电话录音,来自国家自杀预防生命线)。预处理包括重采样至16/8kHz,峰值归一化,以及批量内的零填充和掩码。
- 损失函数:采用Focal Loss(γ=2),并引入类别平衡权重(
α_y ∝ 1/freq(y))以处理类别不平衡问题。 - 训练策略:使用AdamW优化器(学习率1e-3,权重衰减1e-4),采用余弦学习率衰减。训练使用混合精度,并进行梯度裁剪(±1.0)。批大小根据数据集调整。
- 关键超参数:LFST有96个对数间隔的频率带,最大阶数O=8,小波窗长L=1024,带宽常数ksd=5。STEE的基础通道数C=128,时间卷积核kt=9,频率卷积核kf=5,自注意力头数4,窗口128,Dropout率0.10。
- 训练硬件:论文未在正文中明确说明训练使用的具体GPU型号和训练时长(仅在附录I提及在NVIDIA A100上运行)。
- 推理细节:推理时对变长输入进行批量填充并使用掩码,确保LFST和STEE只处理有效区域。未提及特殊的解码策略或温度设置。
- 正则化技巧:除了Dropout,还使用了Batch Normalization、梯度裁剪、Focal Loss的类平衡以及LAHT的稀疏化效果。
📊 实验结果
主要结果: 论文在三个标准数据集上报告了分类报告和SOTA比较,显示LFST+STEE取得了领先性能。
| 数据集 | 方法 | 准确率 (%) | 宏F1 (%) |
|---|---|---|---|
| IEMOCAP | Li et al. | 81.6 | 82.1 |
| (D2) | LFST+STEE (ours) | 87.5 | 86.8 |
| EMO-DB | Liu et al. | 89.13 | 89.4 |
| (D3) | LFST+STEE (ours) | 91.4 | 90.4 |
| NSPL-CRISE | Li et al. | 68.7 | 69.3 |
| (D1) | LFST+STEE (ours) | 76.9 | 76.6 |
关键消融实验: 为了验证组件贡献,在NSPL-CRISE数据集上进行了消融研究:
| 变体 | 准确率 (%) | F1 (%) |
|---|---|---|
| LFST without κ (保留LAHT) | 67.2 | 66.9 |
| LFST without LAHT (保留κ) | 74.3 | 74.1 |
| LFST (完整模型: κ + LAHT) | 76.9 | 76.6 |
结果显示,相位一致性通道κ的贡献巨大(提升约9.7个百分点),而LAHT模块带来了进一步的增益(约2.6个百分点),证明了两个模块的有效性和互补性。
受控前端对比(使用相同STEE编码器):
| 方法 | NSPL (Acc/F1) | IEMOCAP (Acc/F1) | EMO-DB (Acc/F1) |
|---|---|---|---|
| STFT+STEE | 73.1 / 72.7 | 84.8 / 84.0 | 89.0 / 88.2 |
| LEAF+STEE | 72.5 / 72.1 | 84.9 / 84.1 | 89.0 / 88.2 |
| LFST+STEE | 76.9 / 76.6 | 87.5 / 86.8 | 91.4 / 90.4 |
该对比在控制下游模型容量的前提下,证实了LFST前端本身带来的性能提升。
模型解释性可视化:
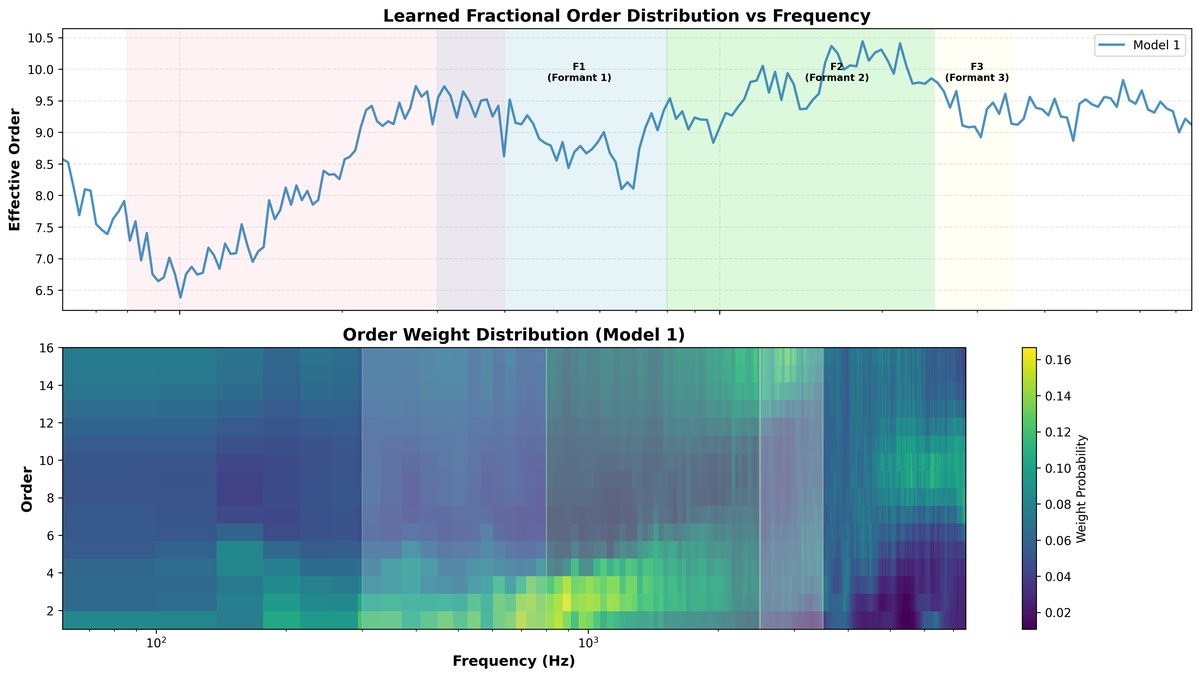 图5展示了模型学习到的有效阶数
图5展示了模型学习到的有效阶数 o_eff 随频率的变化以及完整的阶数权重分布热图。结果表明:1) 阶数分配在频率上是非均匀的;2) 在中高频(元音/共振峰区域)有效阶数较高,意味着模型学习到在此区域需要更精细的频率分辨率;3) 在低频(基频区域)有效阶数较低,意味着模型倾向于更好的时间精度以捕获韵律动态。
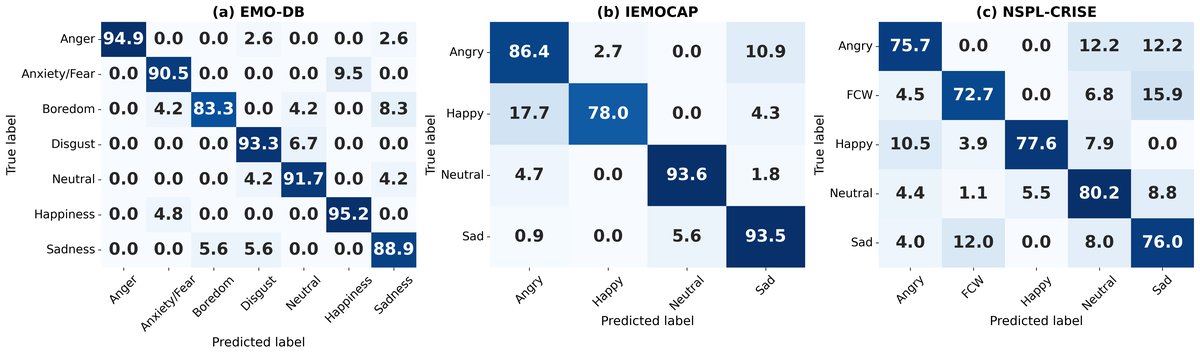 图4展示了三个数据集的混淆矩阵。IEMOCAP中Happy与Angry存在混淆;EMO-DB中各类别表现均衡;NSPL-CRISE作为电话语音,性能有所下降,主要混淆发生在FCW(恐惧/担忧)与Sad/Neutral之间。
图4展示了三个数据集的混淆矩阵。IEMOCAP中Happy与Angry存在混淆;EMO-DB中各类别表现均衡;NSPL-CRISE作为电话语音,性能有所下降,主要混淆发生在FCW(恐惧/担忧)与Sad/Neutral之间。
⚖️ 评分理由
- 学术质量:5.5/7。创新性体现在将经典理论成功转化为现代可学习模块,并加入了相位信息等有价值的设计。技术实现正确,数学推导严谨。实验充分,在多个数据集和受控对比中验证了方法的有效性,消融实验设计合理。但整体更偏向于对现有概念的优秀系统集成和应用,而非提出全新的理论或模型范式。
- 选题价值:1.5/2。语音情感识别是一个重要且活跃的研究领域。该工作提出的可学习时频前端思路具有通用性,可能启发其他音频分析任务。研究问题明确,方法与任务契合度高。
- 开源与复现加成:0.5/1。论文提供了开源代码链接,且技术细节(附录)描述得极其详尽,几乎达到了“手把手”教学的程度,复现友好度极高。扣分点在于未提及模型权重和非公开数据集的获取方式。