📄 LayerSync: Self-aligning Intermediate Layers
#生成模型 #扩散模型 #流匹配 #自监督学习
✅ 7.5/10 | 前25% | #生成模型 | #扩散模型 | #流匹配 #自监督学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yasaman Haghighi (EPFL, 与Bastien van Delft共同第一作者)
- 通讯作者:Alexandre Alahi (EPFL)
- 作者列表:Yasaman Haghighi (EPFL VITA实验室), Bastien van Delft (EPFL VITA实验室), Mariam Hassan (EPFL VITA实验室), Alexandre Alahi (EPFL VITA实验室)
💡 毒舌点评
亮点:本文用一个极其简单(对齐两个层的特征)且零开销的插件,就在多个模态上实现了显著的训练加速和质量提升,堪称扩散模型领域的“高效内部教练”,实用价值很高。短板:所谓的“内部强层指导弱层”缺乏坚实的理论分析,层的选择(如“避开最后20%”)更像是经验性的“土方子”,其有效性边界和内在机理有待更深入的剖析。
🔗 开源详情
- 代码:论文提供代码仓库链接:
https://github.com/vita-epfl/LayerSync.git。 - 模型权重:论文中未提及公开训练好的模型权重。
- 数据集:使用公开数据集(ImageNet, MTG-Jamendo, HumanML3D, CLEVRER, MixKit),获取方式遵循各数据集原有许可,论文中未特别说明。
- Demo:论文中未提及在线演示。
- 复现材料:提供了非常详细的超参数设置表(表18,19)、模型架构细节(表20)、算法伪代码(算法1)以及计算资源描述。复现信息充分。
- 引用的开源项目:论文中引用并依赖以下开源项目/模型:SiT, Stable Diffusion VAE, Stable Audio Open VAE, DINOv2, MDM等。
📌 核心摘要
- 解决的问题:扩散模型(如DiT/SiT)训练成本高昂。已有工作通过将模型内部表征与外部强大预训练模型(如DINOv2, VLM)对齐来加速训练,但这种方法依赖外部模型、引入计算开销且跨领域泛化能力有限。
- 方法核心:提出LayerSync,一种自包含、即插即用的正则化方法。核心思想是利用扩散模型自身深度网络中表征质量的异质性,将语义信息更丰富的深层块(强层)的输出作为目标,通过最大化相似度(如余弦相似度)来对齐并指导浅层块(弱层)的表征学习,从而实现模型内部的自我提升。
- 与已有方法相比的新意:与依赖外部模型的对齐方法(如REPA, REED)不同,LayerSync无需任何外部模型或数据,计算开销几乎为零。与另一种自包含方法Dispersive Loss(鼓励表征分散)相比,LayerSync提供了更直接的定向学习信号(强层对齐弱层)。
- 主要实验结果:
- 图像生成(ImageNet 256x256):使用LayerSync的SiT-XL/2模型,训练800 epochs后FID达到1.89(使用CFG),比基线SiT-XL/2的2.06降低了8.3%,在纯自监督生成方法中达到SOTA。相比基线SiT-XL/2,训练160 epochs时的FID(8.29)已低于基线训练1400 epochs时的FID(8.3),实现了超过8.75倍的训练加速。相比Dispersive Loss,在相同epoch下FID改进幅度平均高出约20个百分点。
- 音频生成(MTG-Jamendo):使用LayerSync的SiT-XL模型,在650 epochs时FAD(CLAP)为0.199,相比基线的0.251降低了20.7%。收敛速度提升约23%。
- 人体运动生成(HumanML3D):使用LayerSync的MDM模型,在600K迭代后FID为0.4801,相比基线的0.5206降低了7.7%。
- 表示分析:在相同生成质量(FID)下,使用LayerSync的模型在分类(+32.4%)和语义分割(+63.3%)任务的线性探测精度上远超基线模型,表明其学到了更优质、更同质化的内部表征。
- 实际意义:提供了一种简单、通用且高效的扩散模型训练加速方案,可无缝应用于不同模态(图像、音频、视频、运动),为降低生成模型训练门槛、推动其广泛应用提供了新思路。
- 主要局限性:对齐的层对选择依赖启发式规则(如避开最后20%的解码层、保证一定距离),其最优策略可能因架构而异;缺乏对“为何此对齐有效”的理论解释;虽然实验跨领域,但在更复杂任务(如高分辨率视频生成)上的大规模验证尚不充分。
🏗️ 模型架构
本文的核心贡献并非提出新的生成模型架构,而是为现有的扩散/流匹配Transformer架构(如SiT) 提供一个即插即用的训练正则化模块。
整体流程与核心组件:
- 基础生成模型:采用基于Transformer的扩散或流匹配模型(如SiT)。输入数据(如图像块)经过线性投影后,被送入一系列Transformer块(Block)进行处理。模型学习预测一个速度场(公式1),用于引导从噪声到数据的反向过程。
- 内部表示层次:论文观察到,训练收敛后,这些Transformer块的内部表示质量呈现层次化。深层块(在解码块之前)的语义信息通常更丰富(图4),且块之间会自然形成三个功能群组:局部特征提取、全局特征整合和解码(图2)。
- LayerSync正则化模块:这是插入训练流程的一个额外损失项,不改变模型架构。
- 输入:同一次训练迭代中,同一个输入样本
x经过模型前向传播后,提取出的两个不同层的特征图:一个“弱层”k的特征f^k_θ(x)和一个“强层”k'(k' > k)的特征f^{k'}_θ(x)。 - 处理:对两个特征图在patch维度上进行L2归一化,然后计算它们之间所有patch的余弦相似度,并对所有patch取平均。
- 输出:一个标量损失值(公式2),其目标是最大化这两个层特征的相似度。
- 交互方式:该损失
L_LayerSync与原始的生成损失(如速度预测损失L_velocity)相加,形成总损失(公式3)。超参数λ控制其权重。在反向传播时,强层k'的特征被stop_gradient操作,即只将其作为不动的目标,仅更新弱层k的参数。
- 输入:同一次训练迭代中,同一个输入样本
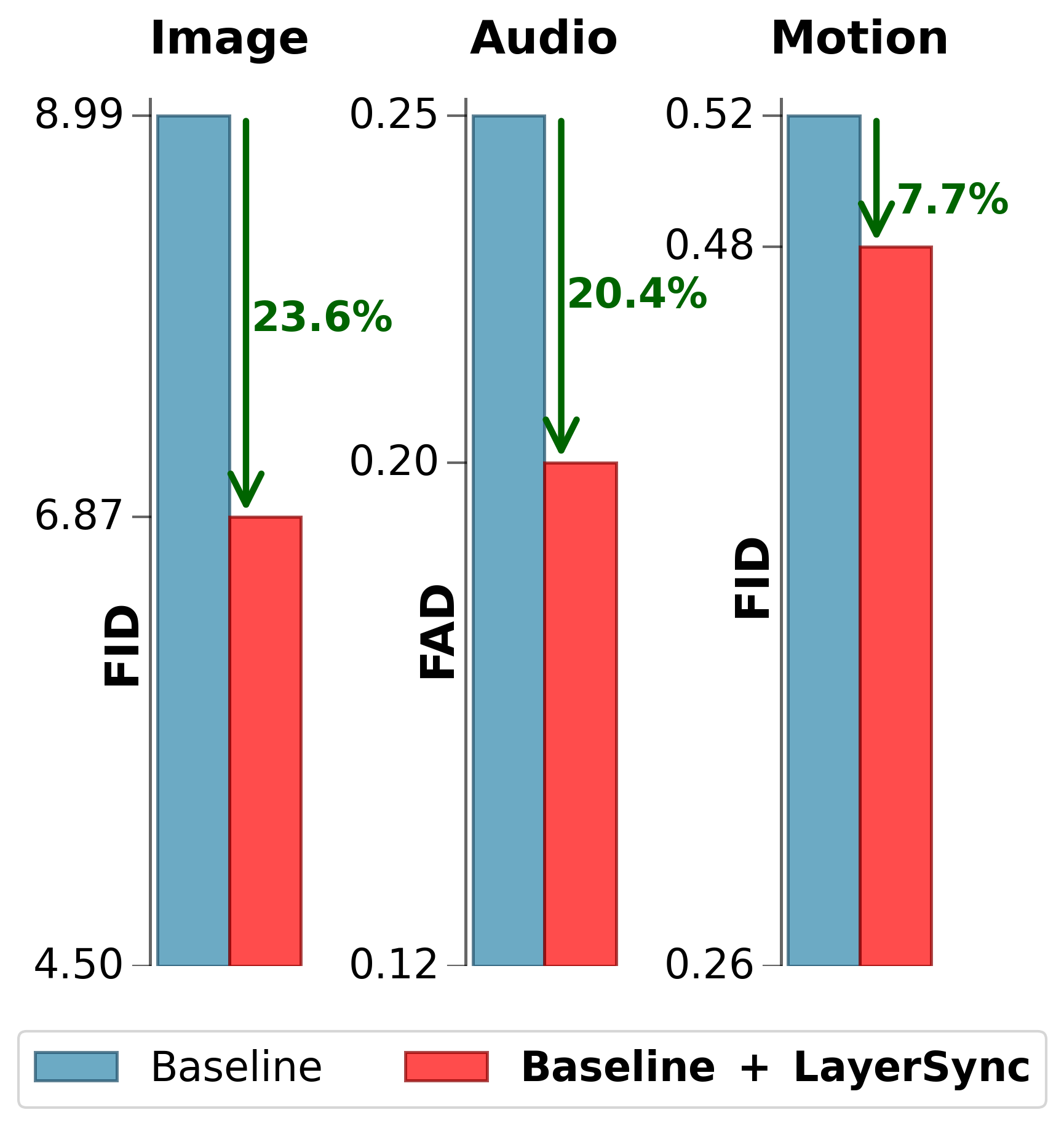 图2显示,收敛后的Transformer块自然分成三个相关性高的功能组:初始的局部特征组、中间的全局特征组和最终的解码组。LayerSync的对齐通常选择在“全局特征组”内部或跨组进行。
图2显示,收敛后的Transformer块自然分成三个相关性高的功能组:初始的局部特征组、中间的全局特征组和最终的解码组。LayerSync的对齐通常选择在“全局特征组”内部或跨组进行。
关键设计选择与动机:
- 选择Transformer块层进行对齐:动机来源于对模型内部表征层次性的观察(图4),即利用“强”层来指导“弱”层。
- 排除最后20%的块作为目标层:因为这些块主要负责解码,其低级特征不适合作为语义指导目标。
- 排除最前几个块:因为专注于局部特征的早期块被认为对性能和泛化有重要贡献。
- 强弱层之间保持最小距离:确保两者在语义上存在足够的差距,使对齐有意义。
💡 核心创新点
- 自包含的内部表征对齐范式:创新性地提出利用模型自身不同深度层之间的表征质量差异,将深层的强表征作为内部监督信号来训练浅层的弱表征。这摆脱了对外部预训练模型(如DINOv2)的依赖,实现了真正的自监督和零额外开销(图1a)。
- 领域无关的通用加速框架:验证了该自对齐思想在图像、音频、视频和人体运动生成等多个不同模态的扩散模型训练中均有效,展示了强大的泛化能力。这是首次有自包含方法被证明能跨领域无缝加速扩散模型训练。
- 与现有方法的互补性:实验表明,LayerSync可以与依赖外部模型的表示对齐方法(如REPA)结合使用,并带来进一步的性能提升(表5)。这表明内部结构对齐与外部语义注入是两个互补的改进维度。
🔬 细节详述
- 训练数据:
- 图像:ImageNet 256x256。遵循ADM的预处理流程。数据增强未具体说明。
- 音频:MTG-Jamendo数据集,55,000首歌曲。随机采样10秒片段,采样率44.1kHz。条件信息为流派和乐器标签。
- 人体运动:HumanML3D数据集,包含44,970个运动注释和文本描述。
- 视频:CLEVRER(从零训练),MixKit(微调Wan2.1模型)。
- 损失函数:
- 主损失:流匹配/扩散模型的速度预测损失(公式1,
L_velocity),即预测速度场与真实速度场的均方误差。 - 正则化损失:LayerSync损失(公式2),
L_LayerSync = - (1/N) Σ cos_sim(f^k, stop_grad(f^{k'}))。负号表示最大化相似度。 总损失:L = L_velocity + λ L_LayerSync。λ是权重超参数,实验中对SiT-B/L/XL分别设为0.3/0.2/0.2(表18)。
- 主损失:流匹配/扩散模型的速度预测损失(公式1,
- 训练策略:
- 优化器:AdamW。
- 学习率:恒定
1e-4(图像生成)。 - Batch size:图像生成为256,音频生成为1024。
- 训练时长:图像生成从80到1400 epochs不等;音频为465-650 epochs;运动生成为600K迭代。
- 调度策略:未提及学习率调度,使用恒定学习率。
- 关键超参数:
- 模型大小:SiT-B/2 (130M), SiT-L/2 (458M), SiT-XL/2 (675M) 参数。
- 架构:SiT-XL/2有28个Transformer层,隐藏维度1152,16个注意力头(表20)。
- 对齐层选择:对SiT-XL通常对齐层8和16(表18)。消融实验(表11,12)展示了不同选择的影响。
- 训练硬件:
- 图像:使用4个GH200 GPU,batch size 256。
- 音频:使用64个GH200 GPU。
- 人体运动:使用1个H100 GPU。
- 推理细节:
- 采样器:图像生成使用ODE Heun方法(主要实验)或SDE Euler-Maruyama方法(表1部分结果)。采样步数250。
- 引导:主要实验不使用Classifier-Free Guidance(CFG)。表2中的对比实验使用了CFG,引导尺度未统一说明。
- 正则化/稳定训练技巧:LayerSync本身即为一种正则化技巧。对特征进行L2归一化后再计算相似度。
📊 实验结果
主要Benchmark与结果:
图像生成(ImageNet 256x256, 无CFG):
模型 参数量 Epochs FID↓ 与基线相比改进 SiT-B/2 130M 80 36.19 - + Dispersive 130M 80 32.45 -10.3% + LayerSync 130M 80 30.00 -17.1% SiT-XL/2 675M 800 8.99 - + Dispersive 675M 800 8.08 -10.1% + LayerSync 675M 800 6.87 -23.6% SiT-XL/2 (w/ SDE) 675M 1400 8.3 - + LayerSync 675M 160 8.29 与基线1400 epochs相当,实现>8.75x加速 图像生成(ImageNet 256x256, 有CFG)系统级对比:
模型 Epochs FID↓ SiT-XL/2 (基线) 1400 2.06 + REPA 800 1.80 + Dispersive ≥1200 1.97 + LayerSync 800 1.89 + LayerSync* 800 1.49 音频生成(MTG-Jamendo):
方法 Epochs FAD (CLAP)↓ SiT-XL (基线) 650 0.251 + LayerSync 650 0.199 (-20.7%) 人体运动生成(HumanML3D):
方法 Iter. FID↓ R-Precision↑ MDM (基线) 600K 0.5206 0.7202 + LayerSync 600K 0.4801 (-7.7%) 0.7454 (+3.4%) 表示质量分析:在相同生成FID下,使用LayerSync训练的模型在Tiny ImageNet分类和PASCAL VOC分割的线性探测平均精度上显著优于基线模型(图4)。
 图4显示,使用LayerSync(蓝色虚线)的模型在所有层的分类(a)和分割(b)精度均高于基线(红色虚线),且与DINOv2的对齐度(c)也更高。最佳性能层发生了偏移。
图4显示,使用LayerSync(蓝色虚线)的模型在所有层的分类(a)和分割(b)精度均高于基线(红色虚线),且与DINOv2的对齐度(c)也更高。最佳性能层发生了偏移。
- 消融实验:
- 层选择鲁棒性:随机选择对齐层对,FID的��准差仅为0.8(表6),表明方法对超参数不敏感。
- 权重λ鲁棒性:在0.1到0.7的范围内,FID和IS的波动很小(表7)。
- 计算开销对比:与EMA方法SRA相比,LayerSync的FLOPs减少25.5%,训练速度快40.5%(表15)。
- 与外部方法组合:LayerSync与REPA结合,在相同训练步数下性能优于单独使用REPA(表5)。
 图3直观展示了LayerSync生成质量的提升,尤其在细节和一致性上。
图3直观展示了LayerSync生成质量的提升,尤其在细节和一致性上。
⚖️ 评分理由
- 学术质量:5.5/7:创新性良好,提出了一个巧妙的自对齐思想。技术实现正确、简洁。实验非常充分,覆盖多模态、多种模型规模,并包含深入的消融分析和内部表示研究。证据可信度高。主要扣分在于理论贡献偏弱,核心机制解释更多依赖实证观察而非原理推导。
- 选题价值:1.5/2:选题聚焦于扩散模型训练效率这一核心问题,具有高前沿性和广泛的实际应用价值。方法通用性强,潜力大。对于关注音频生成的读者,本文证实了该技巧在音频领域的有效性,具有参考价值。
- 开源与复现加成:+0.5:论文明确承诺开源代码,并提供了详尽的实验设置、超参数和算法描述,为复现奠定了良好基础。代码链接已提供,但权重和完整训练细节待开源。