📄 LadderSym: A Multimodal Interleaved Transformer for Music Practice Error Detection
#音乐理解 #错误检测 #多模态模型 #Transformer
🔥 8.0/10 | 前25% | #音乐理解 | #多模态模型 | #错误检测 #Transformer
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Benjamin Shiue-Hal Chou (Purdue University)
- 通讯作者:未明确说明(根据论文惯例,Yung-Hsiang Lu 的邮箱在作者列表最后,可能为通讯作者,但论文中未明确标注“Corresponding author”)
- 作者列表:Benjamin Shiue-Hal Chou¹, Purvish Jajal¹, Nicholas John Eliopoulos¹, James C. Davis¹, George K. Thiruvathukal², Kristen Yeon-Ji Yun¹, Yung-Hsiang Lu¹ ¹Purdue University ²Loyola University Chicago
💡 毒舌点评
亮点:论文不仅提出了有效的模型,还非常务实地构建并发布了首个真实初学者演奏错误数据集(附录A.7),并利用模型辅助标注(“human-in-the-loop”),这比单纯刷点更能推动领域发展。短板:虽然实验指标提升显著,但对“交织对齐”这一核心架构创新的理论分析不够深入,例如,为何这种特定交替的交叉注意力结构优于其他混合融合方案(如CLIP式的单次对齐或Flamingo式的逐层条件注入),论述略显表面。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/ben2002chou/Ladder_SYM (论文中提及)。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:
- 合成数据集MAESTRO-E和CocoChorales-E:论文中说明是公开可用的(引用自Chou et al., 2025),但未直接提供下载链接。
- 真实初学者数据集:论文中详细描述了其构建过程(附录A.7),并称其为“the largest publicly available dataset of real-world, annotated beginner performances”,但未明确说明当前是否公开及获取方式。
- Demo:论文中提到“Demo examples of model outputs are available at: our demo page.”,但未提供具体URL。
- 复现材料:提供了极其详细的附录,涵盖:训练超参数(表7)、模型输入/输出格式(附录A.2, A.3)、数据集生成算法(算法1)、训练过程、评估指标细节、统计检验结果、注意力可视化、以及可复现性声明(包括随机种子设置)。复现指南非常完善。
- 引用的开源项目:
- MT3 (Gardner et al., 2022):用于音频预处理和输出格式。
- EfficientTTMs (Jajal et al., 2024):用于模型组件代码改编(MIT许可)。
- Polytune (Chou et al., 2025):作为基线,并借鉴其训练流程(BSD 3-Clause,非商业)。
- MIDI-DDSP (Wu et al., 2022):用于从MIDI合成训练音频。
- AST (Gong et al., 2021):其编码器配置被LadderSym的编码器层数所参考。
- 论文中未提及开源计划:未明确提及未来开源模型权重、更新数据集或提供在线可交互Demo的计划。
📌 核心摘要
- 问题:音乐练习者需要工具来检测演奏错误(遗漏、多余、错音),但现有方法存在两个主要局限:1) 晚期融合(如Polytune)限制了对齐与跨模态比较能力;2) 仅用音频表示乐谱会在并行音符处产生频率歧义。
- 方法:提出LadderSym,包含两大核心创新:1) Ladder编码器:一种两流交织的Transformer编码器,在每层前使用交叉注意力对齐模块,让音频表示在流间频繁交互并实现对齐,同时保持两流的非对称特征提取能力。2) Sym提示:将符号化乐谱(如MIDI token序列)作为提示(prompt)输入到T5解码器,为解码器提供无歧义的参考,减少对模糊音频乐谱的依赖。
- 新意:Ladder编码器通过交织的交叉注意力实现频繁且细粒度的流间对齐,不同于晚期融合(仅单层融合)或早期融合(全程参数共享);将符号乐谱作为解码器提示是解决音频歧义的直接而有效的方法,与纯音频或纯符号输入形成对比。
- 实验结果:在合成数据集MAESTRO-E上,遗漏音符F1从Polytune的26.8%提升至56.3%,多余音符F1从72.0%提升至86.4%;在CocoChorales-E上,遗漏音符F1从51.3%提升至61.7%,多余音符F1从46.8%提升至61.4%。在精心策展的真实初学者数据集上,LadderSym的遗漏音符F1(78.5%)显著优于Polytune(63.9%)。消融实验证实了交织编码和符号提示各自的贡献。
- 意义:1) 实际应用:模型可作为辅助标注工具,加速真实错误数据集的构建,解决“鸡生蛋”问题,惠及音乐教育。2) 方法论启示:其“频繁跨模态对���”和“非对称特征提取”的架构思想可能启发其他需要精细序列比较的任务,如强化学习奖励建模和人类技能评估。
- 局限性:1) 遗漏音符检测仍是最挑战的类别,尤其在密集和弦段落。2) 在片段边界,持续音符的尾巴可能被误标为多余音符。3) 模型设计用于局部速度偏差,不适用于速度大幅变化的对齐。
🏗️ 模型架构
LadderSym的整体架构可分为两个主要阶段:编码器阶段和解码器阶段。其核心输入是乐谱音频和练习音频,输出是标记了“正确”、“遗漏”、“多余”的音符序列。
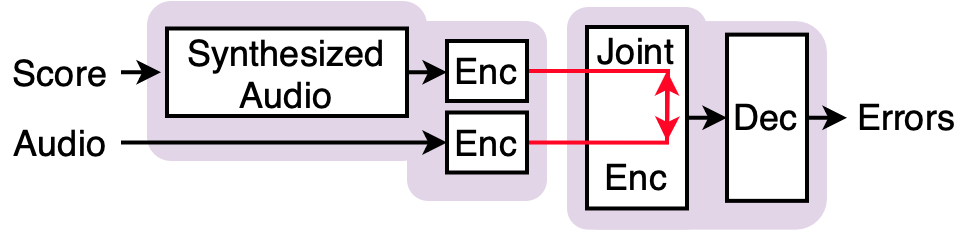 图3:LadderSym 架构:乐谱音频和练习音频分别输入Ladder编码器。编码器由多层组成,每一层都包含两个流(流A、流B)和一个交织的交叉注意力对齐模块。对齐后的两流特征被拼接(Concat),作为上下文(Context)输入到T5解码器。解码器的输入还包括一个由符号乐谱生成的“Sym提示”(Sym Prompt),置于序列起始。解码器以自回归方式生成类似MIDI的token序列,每个音符被标记为正确、遗漏或多余。
图3:LadderSym 架构:乐谱音频和练习音频分别输入Ladder编码器。编码器由多层组成,每一层都包含两个流(流A、流B)和一个交织的交叉注意力对齐模块。对齐后的两流特征被拼接(Concat),作为上下文(Context)输入到T5解码器。解码器的输入还包括一个由符号乐谱生成的“Sym提示”(Sym Prompt),置于序列起始。解码器以自回归方式生成类似MIDI的token序列,每个音符被标记为正确、遗漏或多余。
主要组件:
输入与预处理:
- 音频输入:乐谱音频和练习音频均被分割为固定长度(2.145秒)的片段,计算梅尔频谱图(512个梅尔频带),并通过ViT patch embedding转换为token序列(每段512个token)。这遵循了MT3和Polytune的预处理流程。
- 符号提示(Sym Prompt):乐谱的MIDI表示被token化为与模型输出相同词汇表的token序列,包含时间、音高、标签(此处全为“正确”)等信息。该序列作为前缀提示(prompt)输入解码器。
Ladder编码器:
- 设计动机:克服Polytune晚期融合的缺陷(仅最后一层交互),同时避免早期融合的参数共享导致的特征提取能力受限问题。它旨在实现“频繁对齐”与“非对称特征提取”。
- 内部结构:编码器由多层(论文中为12层)交织模块构成。每个模块的核心是一个交叉注意力对齐模块(Cross-Attention Alignment Module)和一个Transformer编码块(ViT Block)。
- 数据流(以第i层为例,见公式1-3及图5):
a. 首先,流
ref(乐谱音频)的表示P_ref(i)经过交叉注意力(CA),查询来自流prac(练习音频)的表示P_prac(i),得到对齐后的增量,并通过加性融合(直接相加)更新流ref:P_ref(i+1) = ViT_ref( P_ref(i) + CA(P_prac(i), P_ref(i)) )。注意,这里交叉注意力的查询是P_ref(i),键值是P_prac(i),即让乐谱流去关注练习流。 b. 然后,更新后的流ref表示P_ref(i+1)被用作交叉注意力的键值,查询来自原始流prac表示P_prac(i),对练习流进行对齐更新:P_prac(i+1) = ViT_prac( P_prac(i) + CA(P_ref(i+1), P_prac(i)) )。 c. 这种交替方向的对齐和处理,在每一层都实现了两个流之间的信息交互与对齐。最终,两流的最终表示被拼接:H_fused = Concat(P_final_ref, P_final_prac)。 - 关键设计:交叉注意力模块的学习使得两流token能相互关注,从而隐式学习时间对齐(如图4所示,学习到的注意力图模式与DTW对齐路径相似)。ViT块专注于流内的特征提取。这种设计解耦了对齐与特征提取。
T5解码器与Sym提示:
- 解码器接收编码器的融合特征
H_fused作为上下文,同时以符号乐谱的token序列作为提示(Prompt)进行初始化。 - 它以自回归方式生成输出序列:
[SOS, Time, Label, On, Note, ... , EOS]。其中Label可以是“正确”、“遗漏”或“多余”。
- 解码器接收编码器的融合特征
💡 核心创新点
交织对齐的Ladder编码器:
- 是什么:一种双流Transformer编码器,通过在每层嵌入交替方向的交叉注意力加性融合模块,实现流间频繁、细粒度的信息交互与对齐。
- 之前局限:晚期融合(如Polytune)仅在编码器最后一层进行融合,限制了流间对齐的深度和质量;早期融合(全连接)通过参数共享实现交互,但限制了各流学习不同特征的能力(非对称性)。
- 如何起作用:每一层的交叉注意力模块强制一个流去关注另一个流的表示,从而实现时间对齐。加性融合保留了流自身的特征,随后的标准ViT块进行流内特征提取。这种交替结构实现了对齐与特征提取的解耦。
- 收益:在MAESTRO-E上,仅Ladder编码器(无Sym提示)相比Polytune就显著提升了所有类别的F1(表5),尤其是在遗漏音符检测上。注意力图分析(图8)显示模型学到了有意义的对齐模式。
符号乐谱提示策略:
- 是什么:将乐谱的符号化表示(如MIDI token)作为提示,输入到自回归解码器的起始位置。
- 之前局限:仅将乐谱合成为音频输入(Polytune),会在并行音符(和弦)处产生频率重叠和歧义,导致模型难以分辨具体音符,影响错误检测(尤其是遗漏音符)。
- 如何起作用:为解码器提供了一个清晰、无歧义的乐谱参考(每个音符的起始时间、音高明确)。解码器在生成每个音符的标签时,可以直接参考此提示,而不仅仅依赖于可能模糊的音频上下文。
- 收益:消融实验(表5)证明,在Polytune上使用“提示+音频”输入比“仅音频”或“仅提示”性能都好。结合Ladder编码器和Sym提示的LadderSym在所有基准上取得最佳成绩。
构建并利用真实错误数据集:
- 是什么:作者策展了一个包含20首初学者钢琴演奏的公开数据集,其中包含真实、非脚本化的演奏错误,并进行了精细的注释。
- 之前局限:缺乏大规模、真实的演奏错误数据集,现有评估主要依赖合成数据(MAESTRO-E, CocoChorales-E),模型泛化性存疑。
- 如何起作用:该数据集用于在无微调情况下评估模型的泛化能力。同时,论文展示了利用LadderSym作为“辅助标注工具”的“人在回路”工作流(附录A.7.2),以加速真实数据集的构建。
- 收益:LadderSym在真实数据集上的遗漏音符F1(78.5%)远超Polytune(63.9%),证明了其改进的实用性和泛化能力。这为解决领域内的“鸡生蛋”数据问题提供了可行路径。
🔬 细节详述
- 训练数据:
- 合成数据:MAESTRO-E(钢琴,1000+轨道,200k+错误)、CocoChorales-E(13种乐器,40k+轨道,25k+错误)。由MAESTRO和CocoChorales语料库的MIDI数据通过算法1注入错误后,用MIDI-DDSP合成音频生成。
- 真实数据:20首初学者钢琴曲,由三位初学者录制,包含161个注释错误(75个错音,51个多余,35个遗漏)。使用数字钢琴直录,���保音频干净。
- 预处理:音频分段(2.145秒)、计算STFT频谱图(2048 FFT, 128 hop, 512 mel bins)、ViT patch化(16x16 patches)。符号乐谱被token化为与输出同词汇的序列。
- 数据增强:使用了“token shuffling”(对输出token进行排列,不改变语义)作为数据增强策略(附录A.4)。
- 损失函数:
- 加权交叉熵损失:用于处理正确、遗漏、多余音符之间的类别不平衡问题。遗漏/多余音符的损失权重被设为10(表7)。
- 训练策略:
- 优化器:AdamW。
- 学习率:采用余弦退火调度(Cosine Annealing),从 2e-4 衰减至 1e-4。
- Batch Size:MAESTRO-E为48个频谱段/批,CocoChorales-E为96个频谱段/批(因其音符密度较低)。
- 训练轮数:300 epochs。
- 精度:使用bf16-mixed混合精度训练以平衡效率与稳定性。
- 随机种子:使用PyTorch Lightning的
seed_everything(365)确保可复现性。
- 关键超参数:
- 编码器:12层Transformer,维度768。
- 解码器:8层T5解码器。编码器输出(768维)被线性投影至512维以匹配解码器维度。
- 模型总参数量:LadderSym为172M,Polytune为192M。
- 训练硬件:在单个NVIDIA A100-80GB GPU上训练。
- 推理细节:采用自回归解码,论文未提及具体解码策略(如beam search),推测为贪心或束搜索。论文报告了编码器延迟和解码器首个token延迟(表3),显示LadderSym在编码速度上优于Polytune(97ms vs 129ms)。
- 正则化技巧:除了加权损失,未明确提及Dropout等正则化方法。
📊 实验结果
主要定量结果对比
| 模型/方法 | 数据集 | 正确音符 F1 | 遗漏音符 F1 | 多余音符 F1 |
|---|---|---|---|---|
| LadderSym (Ours) | MAESTRO-E | 94.4% | 54.7% | 86.4% |
| Polytune (SOTA) | MAESTRO-E | 90.1% | 26.8% | 72.0% |
| 显式对齐基线 | MAESTRO-E | 43.5% | 6.6% | 39.9% |
| LadderSym (Ours) | CocoChorales-E | 97.7% | 61.7% | 61.4% |
| Polytune (SOTA) | CocoChorales-E | 95.4% | 51.3% | 46.8% |
| 显式对齐基线 | CocoChorales-E | 36.7% | 7.7% | 23.5% |
关键发现:
- LadderSym在所有类别和数据集上全面超越了Polytune和显式对齐基线。在MAESTRO-E上,遗漏音符F1提升近一倍(26.8% → 54.7%),多余音符F1提升14.4个百分点(72.0% → 86.4%)。CocoChorales-E上也取得显著提升。
- 在真实初学者数据集上(无微调),LadderSym同样表现更优,遗漏音符F1为78.5%(Polytune为63.9%),多余音符F1为81.6%(Polytune为80.6%)。
消融实验
| 实验类型 | 变体 | MAESTRO-E 遗漏/多余 | CocoChorales-E 遗漏/多余 | 结论 |
|---|---|---|---|---|
| 输入配置消融 (基线: Polytune) | 仅音频 | 26.8% / 72.0% | 46.8% / 51.3% | 基线 |
| 仅提示 | 24.3% / 62.5% | 44.6% / 45.8% | 符号提示单独效果一般 | |
| 提示+音频 | 46.7%↑ / 81.7%↑ | 56.1%↑ / 58.1%↑ | 多模态组合效果最佳 | |
| 编码器设计消融 (基线: Polytune) | 3层联合编码器 | 36.1% / 75.3% | 56.8% / 59.6% | 早于单层融合有效 |
| 仅自注意力 (无交叉注意力) | 33.8% / 74.6% | 54.6% / 56.2% | 交叉注意力对齐是关键 | |
| Ladder编码器 | 46.0%↑ / 82.0%↑ | 61.0%↑ / 62.3%↑ | 交织对齐效果最优 | |
| 最终模型 | LadderSym (Ladder + 提示) | 54.7%↑ / 86.4%↑ | 61.7%↑ / 61.4%↓ | 在更具挑战的MAESTRO-E上组合效果最佳;在CocoChorales-E上“多余”音符略低于无提示的Ladder |
模型效率对比
| 模型 | 编码器延迟 (s) | 解码器首token延迟 (s) | 最差情况token延迟 (ms) |
|---|---|---|---|
| Polytune | 0.129 ± 0.024 | 0.00786 ± 0.0356 | 136.86 ± 0.0596 |
| LadderSym | 0.0971 ± 0.0398 | 0.00787 ± 0.0201 | 104.97 ± 0.0599 |
| Ladder | 0.0972 ± 0.0452 | 0.00801 ± 0.0364 | 105.21 ± 0.0816 |
LadderSym在参数更少(172M vs 192M)的情况下,编码器延迟和生成延迟均优于Polytune。
注意力模式可视化 论文提供了多张注意力图来分析模型行为。
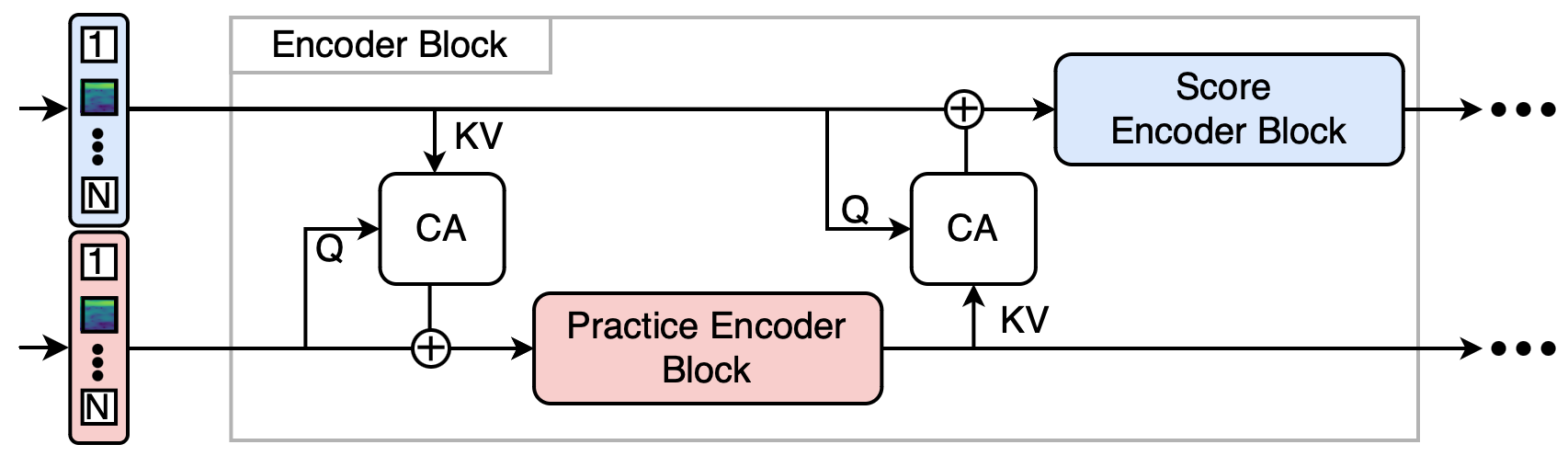 图8:LadderSym 交叉注意力图:展示了不同层中练习流(y轴)对乐谱流(x轴)的注意力分布(已按音高维度平均)。浅色表示注意力值高。早期层显示出清晰的对角线结构,表明模型在学习时间对齐;深层则转向更抽象的对应关系。这证明了交织对齐模块的有效性。
图8:LadderSym 交叉注意力图:展示了不同层中练习流(y轴)对乐谱流(x轴)的注意力分布(已按音高维度平均)。浅色表示注意力值高。早期层显示出清晰的对角线结构,表明模型在学习时间对齐;深层则转向更抽象的对应关系。这证明了交织对齐模块的有效性。
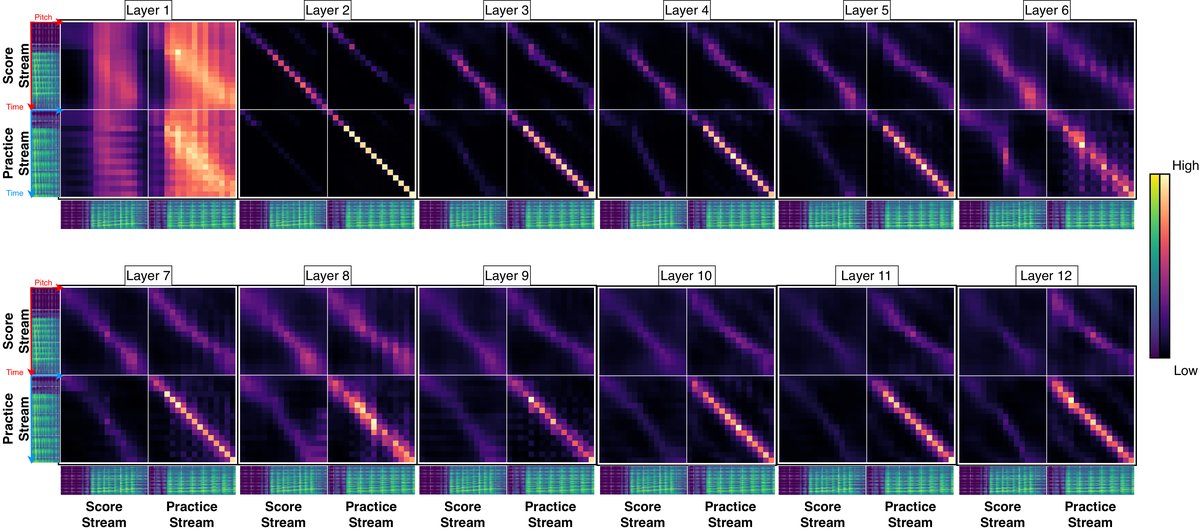 图9:第一层交叉注意力图(不同错误场景):展示了在“遗漏”、“多余”、“错音”等不同错误类型下,第一层注意力图均呈强对角线模式,表明错误类型的区分可能发生在更深层。
图9:第一层交叉注意力图(不同错误场景):展示了在“遗漏”、“多余”、“错音”等不同错误类型下,第一层注意力图均呈强对角线模式,表明错误类型的区分可能发生在更深层。
⚖️ 评分理由
- 学术质量 (6.5/7):
- 创新性 (2.0/2.5):提出了针对性的架构改进(交织对齐编码器、符号提示),动机明确,解决的是现有SOTA方法的实际缺陷,而非空中楼阁。创新点清晰且有一定深度。
- 技术正确性 (2.0/2.5):设计合理,实验充分验证了每个组件的有效性。公式、图表清晰。未发现明显的实验漏洞或逻辑错误。
- 实验充分性 (1.5/1.5):实验设计全面:1)与SOTA和强基线在主流合成基准上对比;2)进行详尽的消融实验(输入配置、编码器设计);3)引入并评估真实世界数据集;4)进行多乐器(14种)结果分析;5)提供统计显著性检验。证据链完整。
- 证据可信度 (1.0/0.5):所有关键结论均有实验数据支撑。轻微扣分是因为论文中未提供置信区间或误差棒(尽管有统计检验),且CocoChorales-E上“多余音符”结果的小幅下降未被完全解释。
- 选题价值 (1.0/2):
- 前沿性与潜在影响 (0.5/1.0):属于音乐信息检索领域的应用研究,非最前沿的基础模型工作。其影响主要局限于音乐教育辅助工具这一垂直领域。
- 实际应用空间与读者相关性 (0.5/1.0):有明确的实际应用(音乐练习反馈、数据集标注)。对于音频/音乐处理领域的研究者有参考价值,但与广义语音大模型等热门方向的读者相关性中等。
- 开源与复现加成 (0.8/1):非常充分。提供了代码仓库、详细的训练细节(超参数、调度器)、完整的数据集构建流程、评估指标定义、复现所需的随机种子。这大大降低了复现门槛,是论文的一大优点。唯一小缺憾是未明确提及是否公开模型权重。