📄 Knowing When to Quit: Probabilistic Early Exits for Speech Separation Networks
#语音分离 #概率模型 #线性RNN #计算效率
✅ 7.0/10 | 前25% | #语音分离 | #概率模型 | #线性RNN #计算效率
学术质量 6.5/7 | 选题价值 7.5/2 | 复现加成 7.0 | 置信度 中
👥 作者与机构
- 第一作者:Kenny Falkær Olsen (Technical University of Denmark, WS Audiology)
- 通讯作者:未说明
- 作者列表:Kenny Falkær Olsen (Technical University of Denmark, WS Audiology), Mads Østergaard (WS Audiology), Karl Ulbæk (WS Audiology), Søren Føns Nielsen (WS Audiology), Rasmus Malik Høegh Lindrup (WS Audiology), Bjørn Sand Jensen (Technical University of Denmark), Morten Mørup (Technical University of Denmark)
💡 毒舌点评
这篇论文在“让网络学会聪明地偷懒”这件事上做得很漂亮,提出的概率早退框架优雅地将性能评估融入训练和推理,为嵌入式设备部署提供了坚实的理论工具。然而,这种优雅的代价是复杂的数学和略显繁琐的退出条件实现,而且论文在WSJ0-2mix这个最常用的基准上并没有刷新记录,更像是在展示一种“能力”而非追求极致性能。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:所用数据集(WSJ0-2mix, Libri2Mix, WHAM!, WHAMR!, DNS2020)均为公开数据集,论文中引用了生成脚本或官方来源。
- Demo:未提供在线演示。
- 复现材料:论文附录(C, D, E, F)提供了详细的架构描述、数据集说明、训练设置和超参数,这构成了重要的复现材料。
- 论文中引用的开源项目:引用了用于数据集生成的Python仓库(pywsj0-mix, LibriMix)和PyTorch框架。
📌 核心摘要
- 问题:当前先进的语音分离/增强网络(如SepFormer)计算量固定,无法根据输入音频的简单程度(如安静、非重叠)动态调整计算资源,限制了其在移动设备、助听器等资源受限场景的应用。
- 方法核心:提出概率性早退框架PRESS,通过联合建模目标语音和误差方差(使用Student t似然),使网络能在每个早期退出点预测出重建质量的概率分布。由此推导出可解释的、基于期望信噪比(SNR)的早退出条件,允许用户设置目标SNR和置信度阈值来动态决定计算深度。
- 新意:与现有早退方法(依赖固定损失权重或启发式停止条件)相比,PRESS的退出条件直接源自概率模型,具有可解释性(目标SNR)和校准性(置信度)。为实例化该框架,设计了基于线性RNN的PRESS-Net架构,支持多点退出且保持高性能。
- 主要实验结果:在WSJ0-2mix、Libri2Mix、WHAM!、WHAMR!和DNS2020数据集上验证了PRESS。模型在静态退出点性能与SOTA基线(如SepReformer)有竞争力(例如PRESS-12(M)在WSJ0-2mix最终出口达24.36dB SI-SNRi)。动态早退可根据目标SNR节省大量计算(见图3),且退出条件在校准后良好(图5)。消融实验(表1)证明了概率似然和联合置换训练的有效性。
- 实际意义:为在异构设备上部署高性能语音模型提供了一种动态、高效、可解释的解决方案,有助于平衡性能与能耗/延迟。
- 主要局限性:1) 概率模型和退出条件的计算与实现较为复杂;2) 模型的校准依赖于在完整长度数据上的微调;3) 当前退出条件需在所有说话人上同时满足,粒度较粗;4) 虽性能有竞争力,但未在所有基准上显著超越最强的静态大模型。
🏗️ 模型架构
论文提出了PRESS-Net架构,其设计目标是支持高效早退出并保持高重建质量。整体流程遵循编码器-分离器-解码器模式,关键创新在于分离器的深层堆叠设计和在多个中间层设置独立退出点。
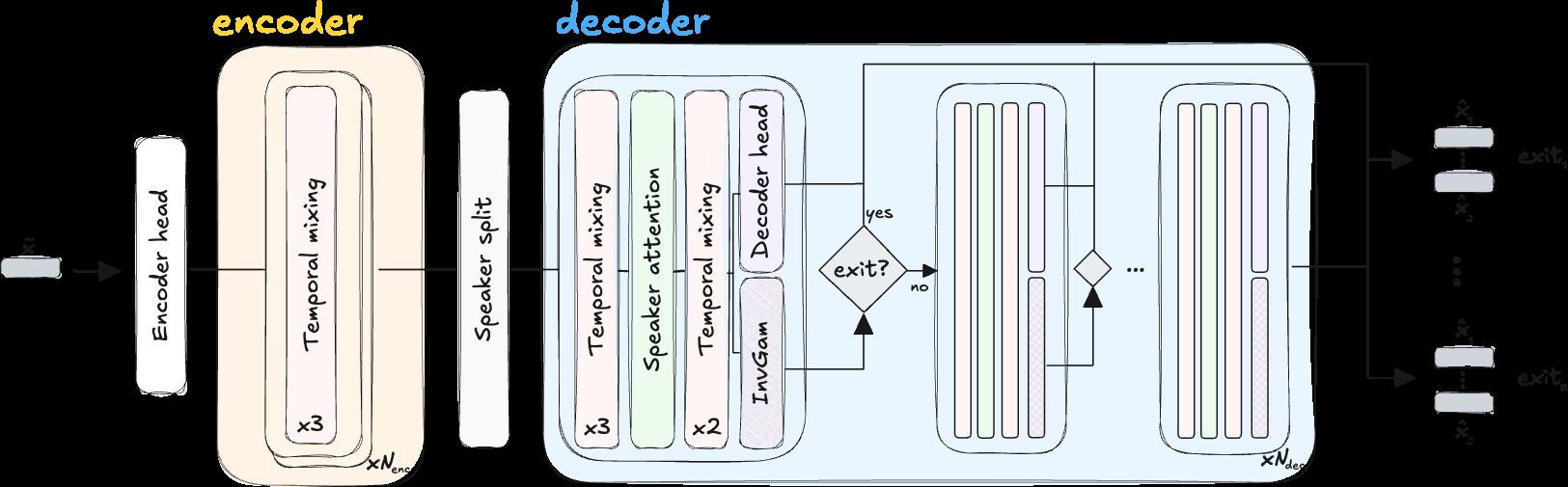 图2详解:架构包含三个主要部分:
图2详解:架构包含三个主要部分:
- 编码器头:将输入时域音频
x ∈ R^T通过一维卷积(核大小16,步长4)、GELU、RMSNorm和线性层,映射为低维特征R^(D_model × T/P)。 - 早分割模块:这是架构的核心。首先经过
N_Enc层线性RNN块处理混合语音,然后通过SpeakerSplit模块将特征沿通道维度分割为S个独立的说话人表示。之后进入解码器栈。 - 带早退出的解码器栈:包含
N_Dec层,主要由线性RNN块和说话人注意力块(以5:1比例)构成。关键点在于,在每一层(或每几层)之后都可以放置一个早期退出点E_i。每个退出点包含两个独立组件:- 独立解码器头:将该层的潜在表示重建为该出口对应的估计源信号。
- 逆伽马参数化块:预测该出口对应的误差方差参数
α_i, β_i,用于计算概率早退出条件(见下文“核心创新点”)。 数据流:编码器输出 → 线性RNN处理 → 早分割 → 解码器栈处理,栈中每一层都可同时输出一路重建结果和一组分布参数。
关键设计选择与动机:
- 基于SepReformer但使用线性RNN:借鉴了SepReformer的“早分割”思想,但将主要计算单元替换为线性RNN(如minGRU、RG-LRU)。因为分离器未进行下采样,时间分辨率高,使用自注意力成本过高。线性RNN通过并行化扫描可高效处理长序列。
- 多退出点设计:每个退出点都拥有独立的解码和参数预测能力,使网络能在不同深度输出质量递增的估计,并量化其不确定性。
- 无下采样的分离器:确保中间特征可直接被解码器头处理,避免因上采样引入额外伪影,支持高质量的早期重建。
- LayerScale与RMSNorm:用于稳定深层网络的训练。
💡 核心创新点
概率性早退出(Probabilistic Early Exit)框架:
- 是什么:将网络输出建模为目标语音
x_j的预测值b_x_i和误差方差σ^2_i,假设误差服从高斯分布,方差服从共轭逆伽马先验。边际化后得到Student t似然(公式2,3)。 - 之前局限:传统早退方法依赖固定损失权重(如重建损失+计算惩罚)或启发式停止准则(如输出变化率),这些条件与任务性能指标(如SNR)脱节,且权衡在训练时固定。
- 如何起作用:通过建模方差,网络能预测每个退出点的重建质量不确定性。由此推导出三个基于条件均值的SNR-like分布(公式8,9,10),它们近似为Gamma分布。将它们组合成一个统一的退出条件(公式11,12):只有当所有说话人至少满足一个SNR条件(SNR, SNRi, SNRref)且置信度
p超过阈值时,才允许退出。 - 收益:提供了直接可解释的退出标准(如“达到22dB SNR置信度90%”),并允许在推理时根据资源需求或质量要求动态调整。
- 是什么:将网络输出建模为目标语音
支持概率早退出的PRESS-Net架构:
- 是什么:一个基于线性RNN的编码器-早分割-解码器架构,在解码器栈中集成了多个独立的解码头和逆伽马参数化块。
- 之前局限:许多SOTA架构(如SepFormer)是为固定计算设计的,添加中间退出点可能破坏表示学习或引入质量下降。
- 如何起作用:架构深度支持在多个层级输出高质量重建,且每个出口的预测独立。通过联合置换训练(所有退出点共享说话人置换),确保了不同出口估计的一致性。
- 收益:在引入早退能力的同时,不损害最终出口的性能(表1d,e消融),甚至通过更稳定的训练(早退作为辅助任务)可能带来微小提升。
可校准的误差方差建模与长序列泛化:
- 是什么:发现使用短时长(4秒)训练的模型在全长度音频上校准不佳(图5a,b)。通过在全长度训练数据上微调,模型的
σ^2预测变得良好校准(图5c,d),且性能提升(表2最后几行)。 - 之前局限:多数模型在固定长度片段上训练,对不同长度泛化时,其不确定性估计可能不可靠。
- 如何起作用:微调使模型学习到更全局的误差统计规律,使其预测的方差分布更贴近真实误差分布。
- 收益:保证了概率退出条件的可靠性,使理论分布与实际误差分布匹配,是实用化的关键。
- 是什么:发现使用短时长(4秒)训练的模型在全长度音频上校准不佳(图5a,b)。通过在全长度训练数据上微调,模型的
🔬 细节详述
- 训练数据:
- 语音分离:WSJ0-2mix(20k训练,8kHz),Libri2Mix(train-100集),WHAM!(WSJ0-2mix+噪声),WHAMR!(WHAM!+混响)。
- 语音增强:DNS Challenge 2020(动态生成0-20dB信噪比混合信号,16kHz)。
- 预处理:未详述。数据增强为动态混合(SNR均匀采样)。
- 损失函数:核心是Student t似然(公式2,3)。优化其对数似然(公式3),通过最大化似然来同时优化预测
b_x_i和方差参数α_i, β_i。使用utterance-level permutation invariant training (uPIT) 为目标分配说话人。当使用多个退出点时,所有退出点共享相同的置换,总损失为所有退出点和所有说话人的似然之和。 - 训练策略:
- 优化器:AdamW (
β1=0.9,β2=0.99, weight decay=0.01)。 - 学习率:基础率
5e-4,随模型宽度D按比例调整(D_old/D_new)。采用线性warmup(5000步)和线性衰减至零的调度(straight-to-zero)。 - Batch Size:1。
- 训练步数:最多600万步。
- 梯度裁剪:L2范数超过1时裁剪。
- 优化器:AdamW (
- 关键超参数:
- PRESS-4 (S):
D=64,编码器层N_Enc=8,解码器层N_Dec=12,4个退出点(每3个解码器块一个),参数量3.57M。 - PRESS-12 (M):
D=128,N_Enc=4,N_Dec=24,12个退出点(每2个解码器块一个),参数量3.66M。 - 编码器卷积核大小16,步长
P=4(8kHz)或8(16kHz)。
- PRESS-4 (S):
- 训练硬件:未详细说明型号,但使用了NVIDIA Ampere架构或更高(H100, A100, A40, A10, RTX 4090, RTX 4070 Ti)。PRESS-4训练约2-3天,PRESS-12训练约6天。
- 推理细节:处理变长音频。早退出决策基于公式(12),可调整目标SNR
t和置信度p。对于分块似然,退出决策在每个块上进行。 - 正则化/稳定训练技巧:使用LayerScale(初始化γ=1e-5)稳定深层网络训练。使用RMSNorm。对全长度数据进行微调以改善校准和性能。
📊 实验结果
主要Benchmark结果(语音分离): 论文在WSJ0-2mix, Libri2Mix, WHAM!, WHAMR!四个数据集上进行了评估,使用SI-SNRi和SDRi作为主要指标。
| 模型 | WSJ0-2mix SI-SNRi | Libri2Mix SI-SNRi | WHAM! SI-SNRi | WHAMR! SI-SNRi | 参数量(M) | GMAC/s(G/s) |
|---|---|---|---|---|---|---|
| SepFormer (S) | 20.4 | 19.2 | 14.7 | 14.0 | 26.0 | 86.9 |
| SepReformer (S) | 23.0 | 20.6 | 17.3 | - | 4.5 | 21.3 |
| SepReformer (M) | 24.2 | 22.0 | 17.8 | - | 17.3 | 81.3 |
| PRESS-4 @ 4 (S) | 22.91 | 20.04 | 16.49 | 14.54 | 3.4 | 11.3 |
| PRESS-12 @ 8 (M) | 23.47 | 20.42 | 16.57 | 14.67 | 15.6 | 54.4 |
| PRESS-12 @ 12 (M) | 24.28 | 20.88 | 16.65 | 14.69 | 22.4 | 79.7 |
| PRESS-12 @ 12 (M) + FT | 24.36 | 21.29 | 17.49 | 15.67 | 22.4 | 79.7 |
关键结论:
- 性能竞争力:PRESS模型在最终出口性能上与同级别的SOTA静态模型(如SepReformer S/M)相当,有时甚至略优(如PRESS-12(M)在WSJ0-2mix上)。微调(+FT)后,性能进一步提升,在WHAMR!上达到15.67dB,优于SepReformer。
- 动态计算优势:图3显示,PRESS模型可以在不同计算预算(GMAC/s)下提供灵活的性能点,其动态早退曲线(使用退出条件)比静态模型的“计算-性能”曲线更优。
- 退出条件有效性:图4展示了不同目标SNR(20,25,30dB)下的“遗憾”(regret)。概率退出策略(动态)的遗憾接近于“神谕”(oracle,总能恰好在达到目标时退���)策略,远优于随机退出(uniform)和静态退出(static)策略。
- 校准的重要性:图5表明,微调前模型在完整长度数据上校准不佳(CRPS较高),微调后校准改善(CRPS下降),且性能提升(表2)。表1f显示,仅用更多4秒片段微调无法达到同样效果。
语音增强结果(DNS2020):
| 模型 | SI-SDR | STOI | WB-PESQ | # Params (M) | GMAC/s (G/s) |
|---|---|---|---|---|---|
| ZipEnhancer | 22.22 | 98.65 | 3.81 | 11.34 | 133.5 |
| PRESS-12 @ 8 (M) | 21.98 | 96.97 | 3.10 | 14.95 | 53.7 |
| PRESS-12 @ 12 (M) | 22.15 | 97.13 | 3.10 | 18.14 | 78.3 |
| 结论:PRESS在增强任务上性能接近专门的增强模型,但计算效率(GMAC/s)显著更高,证明了其框架的通用性和效率优势。 |
关键消融实验(表1):
- (a) 使用SI-SNR损失 vs. 使用Student t似然:性能接近,表明t似然可作为有效替代。
- (b) 使用简单正态似然:性能明显下降,说明对误差进行对数建模(t似然隐含)很重要。
- (c) 联合置换 vs. 逐出口置换:联合置换性能远好于逐出口置换,表明说话人一致性对早退出至关重要。
- (d,e) 退出点数量(4,6,12):增加出口数量不损害性能,为更大模型设计提供了依据。
- (f) 用4秒片段微调 vs. 全长度数据微调:后者带来显著提升,前者无效,证明了全长度数据对校准的必要性。
⚖️ 评分理由
- 学术质量:6.0/7:论文贡献清晰,将概率建模与早退出紧密结合,技术方案新颖且合理。实验设计全面,包含多个数据集、任务、大量消融和校准分析,证据扎实。主要不足是方法实现复杂,且未在所有SOTA上实现性能超越,更侧重展示框架能力。
- 选题价值:1.5/2:针对语音模型在资源受限设备上部署的关键痛点(动态计算、能效),提出了优雅的理论解决方案。概率可解释的退出条件具有实用价值。与音频/语音社区的相关性高。
- 开源与复现加成:-0.5/1:论文提供了极其详尽的训练细节和架构说明,理论上高度可复现。但完全未提及代码、模型权重或训练脚本的开源计划,对于这类复杂的新框架,这大幅增加了独立复现的难度和成本,因此扣分。