📄 Instilling an Active Mind in Avatars via Cognitive Simulation
#数字人生成 #扩散模型 #多模态模型 #音视频 #大语言模型
🔥 8.0/10 | 前25% | #数字人生成 | #扩散模型 | #多模态模型 #音视频
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jianwen Jiang(字节跳动)
- 通讯作者:Jianwen Jiang(字节跳动)
- 作者列表:Jianwen Jiang(字节跳动)、Weihong Zeng(字节跳动)、Zerong Zheng(字节跳动)、Jiaqi Yang(字节跳动)、Chao Liang(字节跳动)、Wang Liao(字节跳动)、Han Liang(字节跳动)、Weifeng Chen(字节跳动)、Xing Wang(字节跳动)、Yuan Zhang(字节跳动)、Mingyuan Gao(字节跳动)
💡 毒舌点评
亮点:首次系统地将认知科学的“双系统理论”引入数字人生成框架,通过LLM模拟“慢思考”来规划语义动作,显著提升了生成动画的上下文一致性和表现力,思路新颖且实验验证充分。 短板:框架依赖一个可能产生20-30秒延迟的LLM推理模块,且生成模型本身基于现有MMDiT架构改进,核心创新更偏向系统级整合而非底层模型架构突破;此外,所有实验在闭源环境下进行,代码和模型的缺失严重影响了结果的可独立验证性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文中详细描述了数据筛选流程,但未提及是否公开数据集。
- Demo:未提供在线演示链接。
- 复现材料:论文附录中提供了详细的实现细节(超参数、训练阶段)、数据筛选工具、评估指标和MLLM使用的提示词模板,复现材料在文本层面较为充分。
- 引用的开源项目:依赖Whisper(音频特征提取)、SyncNet(数据筛选)、RAFT(光流计算)、Q-align(质量评估)、PySceneDetect和PaddleOCR(视频预处理)。
📌 核心摘要
- 问题:当前数字人视频生成模型虽然能生成流畅动画,但主要基于低层音频线索(如口型)进行反应式同步,缺乏对高层语义(如情感、意图、语境)的理解,导致生成的动作缺乏逻辑一致性和丰富性。
- 方法核心:提出一个模拟人类“双系统”认知的框架。系统2:利用多模态大语言模型(MLLM)对输入(图像、音频、文本)进行推理,生成结构化的高层动作计划(推理文本)。系统1:设计一个专门的多模态扩散变换器(MMDiT),其核心是伪最后帧(PLF) 策略和对称的音频分支融合,以鲁棒地整合MLLM生成的文本指导与音频等反应式信号,同时避免模态冲突。
- 创新点:a) 首个将数字人问题置于认知科学双系统理论下建模的工作;b) 使用MLLM进行显式的语义规划;c) 提出伪最后帧(PLF)策略,通过时序外推能力维持身份一致性,避免了传统参考图条件带来的运动伪影;d) 设计了多模态预热训练策略以优化多分支融合。
- 实验结果:在多项指标上达到SOTA。在CelebV-HQ肖像任务上,FID(31.320)和FVD(45.771)优于或接近OmniHuman-1;在CyberHost全身任务上,HKV(72.113)显著高于OmniHuman-1(47.561),表明手势动态性更强。用户研究(40人)显示,在整体质量、上下文自然度上显著优于多个学术和商业基线。消融研究证明,去除系统2推理会降低动作丰富度(HKV从168.9降至122.4),而PLF和多模态预热对图像质量、运动和身份一致性至关重要。
- 实际意义:为创建具有“主动心智”、能根据语境进行逻辑反应的智能数字人提供了新范式,有望应用于虚拟伴侣、交互式娱乐、影视制作等领域。
- 主要局限性:a) 引入LLM推理带来约20-30秒的额外延迟;b) 框架的有效性部分依赖所选用的特定MLLM;c) 当前评估主要在单人或简单多人场景,复杂交互场景的鲁棒性有待进一步验证;d) 模型和代码未开源。
🏗️ 模型架构
整体框架模拟“双系统”认知,流程如图2所示。
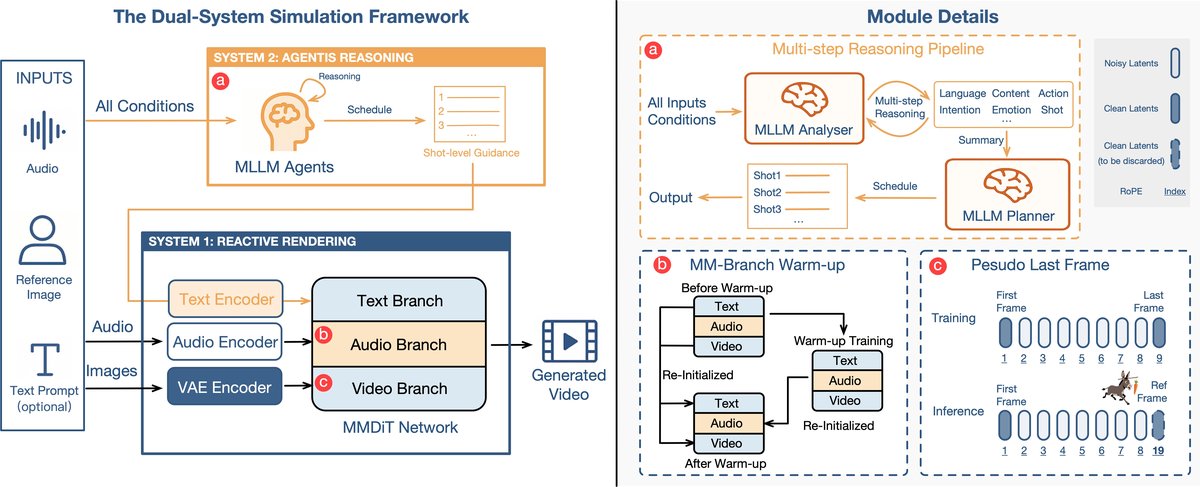 系统2(审慎控制):由MLLM智能体驱动,包含分析器和规划器两个阶段。输入角色的参考图像、音频片段和可选文本提示。分析器通过逐步引导式提问,推断语音内容、情感状态和意图,并输出结构化的JSON总结。规划器基于此总结,制定一个详细、连贯的动作计划(作为“时间表”),以推理文本形式输出。该模块为下游生成提供高层语义指导。
系统1(反应渲染):基于多模态扩散变换器(MMDiT)骨干网络,用于最终视频合成。其关键设计包括:
系统2(审慎控制):由MLLM智能体驱动,包含分析器和规划器两个阶段。输入角色的参考图像、音频片段和可选文本提示。分析器通过逐步引导式提问,推断语音内容、情感状态和意图,并输出结构化的JSON总结。规划器基于此总结,制定一个详细、连贯的动作计划(作为“时间表”),以推理文本形式输出。该模块为下游生成提供高层语义指导。
系统1(反应渲染):基于多模态扩散变换器(MMDiT)骨干网络,用于最终视频合成。其关键设计包括:
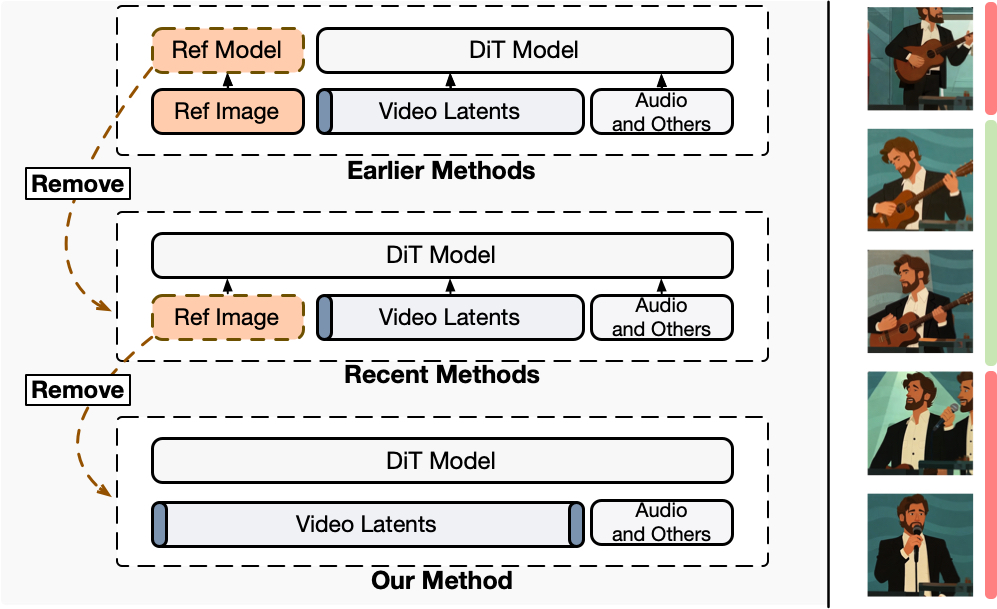
- 伪最后帧(PLF)策略:这是对传统参考图条件化方式的革新。训练时,模型概率性地以真实视频的首帧和末帧作为条件(各0.1概率丢弃)。推理时,将用户参考图置于“末帧”位置,但将其位置编码(RoPE)移位到固定时间距离之外。这样,参考图作为身份引导但不在生成序列中强制复现,避免了运动伪影,如图3所示。
- 对称融合与模态预热:MMDiT架构包含对称的视频、文本和音频分支。所有模态的token在变换器块内通过拼接后进行共享的自注意力,实现深度联合建模。为解决多模态联合训练时的干扰(如音频信号淹没文本指导),提出两阶段多模态预热(MM-Warmup)策略。第一阶段训练完整的三分支模型;第二阶段用初始化权重进行微调,让各分支先适应其职责。 数据流:系统2的推理文本与音频特征(Whisper编码)一同输入MMDiT。音频特征通过专门的对称音频分支处理。模型在潜空间(预训练的3D VAE)中操作,采用流匹配目标训练,并可自回归生成长视频。
💡 核心创新点
- 基于双系统理论的框架设计:首次将认知科学的“系统1(反应)”和“系统2(审慎)”类比应用于数字人生成,识别出现有方法仅模拟系统1的局限,并提出通过MLLM显式模拟系统2来规划高层语义动作,这是在问题定义和系统设计上的根本性创新。
- MLLM智能体驱动的语义规划:利用MLLM的推理能力,将多模态输入转化为结构化、分镜头的动作计划(推理文本)。这超越了简单的文本到动作映射,提供了具备逻辑连贯性和情感深度的“大脑”指令,使生成动画能贴合语境(如根据“吞下蓝药丸”台词做出相应手势)。
- 伪最后帧(PLF)条件化策略:巧妙地重新设计了参考图的作用。通过训练时使用原生视频帧、推理时移位位置编码的“伪最后帧”,将参考图从必须复现的“条件”转变为引导身份的“目标”,从而解除了对动态运动的约束,有效解决了身份保持与运动丰富性之间的矛盾,如图8和图9所示。


- 多模态预热训练策略:针对MMDiT多分支融合训练中容易产生的模态干扰问题,提出了分两阶段训练的策略,为各分支提供更强的先验初始化,促进了模态间的有效分工与协作,提升了整体合成质量。
🔬 细节详述
- 训练数据:使用15,000小时视频数据,经过多阶段筛选(使用PySceneDetect、PaddleOCR、Q-align、Raft光流、SyncNet)。最终数据以上半身和中景镜头为主,室内场景占45%。对于唇音相关性差的数据(约70%),丢弃音频并采用音频丢弃策略训练。微调阶段使用100小时高质量子集。
- 损失函数:论文未明确说明,但提到采用流匹配(Flow Matching) 目标进行训练,这类似于基于变分的扩散目标。
- 训练策略:三阶段训练:1) 音频分支预热(~18k GPU小时,A100等效);2) 主训练阶段(~43k GPU小时);3) 高质量数据微调(~6k GPU小时)。优化器为AdamW,学习率5e-5,全局批量大小256,梯度裁剪范数1.0。
- 关键超参数:模型基于MMDiT架构,生成120帧(24fps),480p分辨率。在多模态注意力中,每个视觉token仅与其时间上最近的5个音频和文本token进行注意力计算以提升效率。
- 训练硬件:A100等效GPU,总训练时长约67k GPU小时。
- 推理细节:生成120帧后,使用单独的超分模型上采样至720p。长视频自回归生成,使用前一段的最后5帧作为下一段的初始条件,并应用RoPE位置偏移(值为30)。系统2的MLLM推理延迟约20-30秒。
- 正则化/稳定技巧:MM-Warmup策略用于稳定多模态训练;音频丢弃用于处理弱相关数据;PLF策略本身也是一种防止身份伪影的正则化手段。
📊 实验结果
主要定量对比(与SOTA方法比较):
- CelebV-HQ肖像任务:
方法 IQA↑ ASE↑ Sync-C↑ FID↓ FVD↓ SadTalker 2.953 1.812 3.843 36.648 171.848 Loopy 3.780 2.492 4.849 33.204 49.153 OmniHuman-1 3.875 2.656 5.199 31.435 46.393 Ours 3.817 2.663 5.053 31.320 45.771 - CyberHost全身任务:
方法 IQA↑ ASE↑ Sync-C↑ FID↓ FVD↓ HKC↑ HKV↑ FantasyTalking 3.892 2.738 3.548 52.332 47.052 0.838 18.845 MultiTalk 3.822 2.681 6.868 37.308 32.783 0.817 62.753 OmniHuman-1 4.142 3.024 7.443 31.641 27.031 0.898 47.561 Ours 4.144 3.030 7.243 31.160 27.642 0.875 72.113 注:加粗为最优结果。
消融研究(基于自建单人测试集,150例):
| 消融项 | IQA↑ | ASE↑ | Sync-C↑ | HKC↑ | HKV↑ |
|---|---|---|---|---|---|
| 完整模型 | 4.790 | 3.901 | 4.087 | 0.571 | 168.912 |
| 去除多步推理 | 4.795 | 3.901 | 3.853 | 0.576 | 157.638 |
| 去除分析器 | 4.793 | 3.910 | 4.278 | 0.572 | 148.381 |
| 无推理(仅系统1) | 4.784 | 3.885 | 3.507 | 0.544 | 122.376 |
| 使用交叉注意力 | 4.745 | 3.856 | 3.263 | 0.558 | 116.317 |
| 无多模态预热 | 4.752 | 3.866 | 3.993 | 0.549 | 164.080 |
| 使用参考图 | 4.772 | 3.896 | 3.982 | 0.559 | 160.889 |
| 无参考图与伪帧 | 4.682 | 3.878 | 4.141 | 0.564 | 160.986 |
主观用户研究(40人):在最佳选择任务中,本文方法以33%的得票率位居第一,超过OmniHuman-1(22%)、MultiTalk(18%)等。与商业系统的GSB成对比较显示强烈偏好。消融研究表明,加入推理模块使GSB分数从-0.29提升至+0.29,运动不自然度(MU)从0.58降至0.37。
关键图表说明:
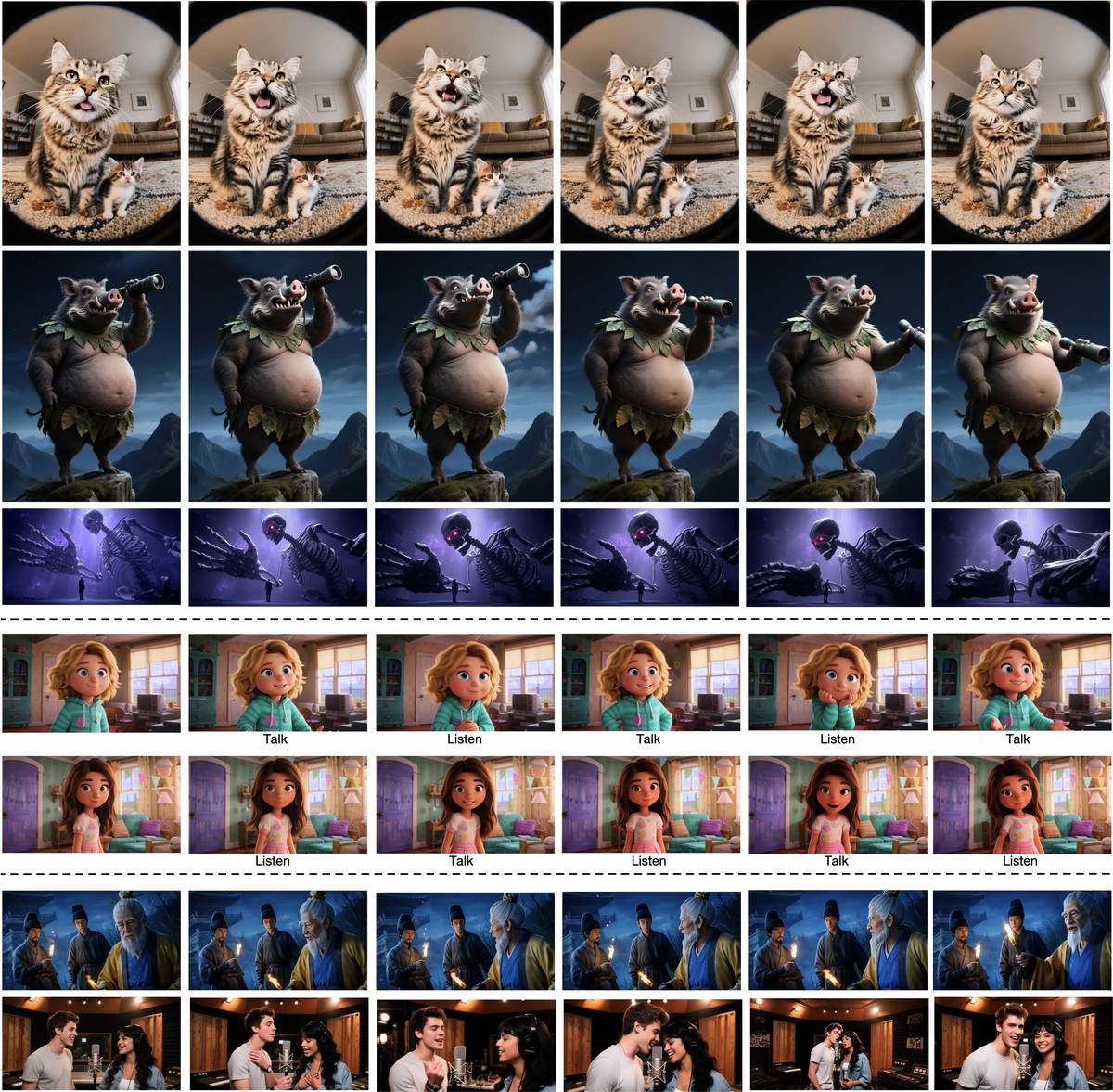 展示了模型对非人类主体、对话轮替和多人协调行为的生成能力,验证了系统2规划在复杂场景下的有效性。
展示了模型对非人类主体、对话轮替和多人协调行为的生成能力,验证了系统2规划在复杂场景下的有效性。
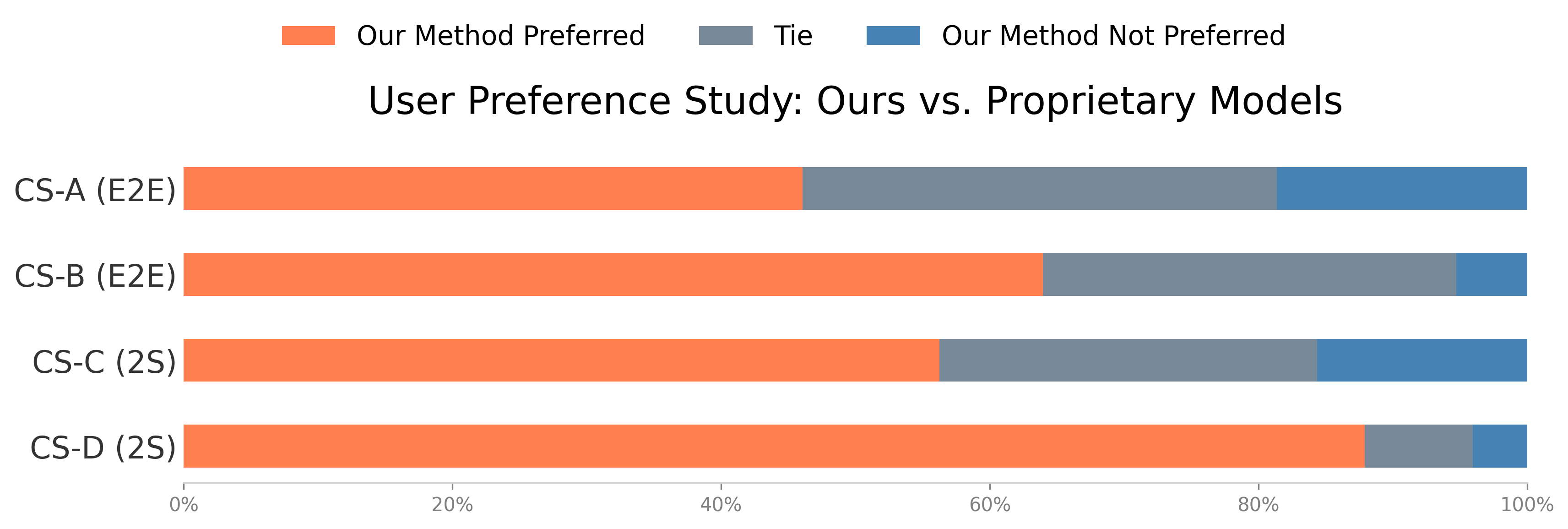 展示了在学术基线和商业系统对比中,用户对本方法的显著偏好。
展示了在学术基线和商业系统对比中,用户对本方法的显著偏好。
 展示了系统2从分析输入到生成动作计划的具体步骤,证明了其上下文理解能力。
展示了系统2从分析输入到生成动作计划的具体步骤,证明了其上下文理解能力。
⚖️ 评分理由
- 学术质量:6.0/7。创新性强(系统框架、PLF策略),技术方案完整且针对明确问题(模态冲突、运动伪影),实验充分(多基准、多指标、消融、用户研究),证据可信。主要扣分点在于核心生成网络非完全原创,且LLM推理延迟是实际应用的限制。
- 选题价值:1.5/2。选题前沿(智能数字人),聚焦于提升生成内容的语义一致性和表现力,潜在影响广泛,与音频驱动的跨模态生成领域高度相关。
- 开源与复现加成:0.5/1。论文提供了详尽的训练细节、架构描述和评估方法,具有较高的文本复现指导价值。但代码、模型和数据均未开源,显著降低了实际可复现性。