📄 Generative Adversarial Post-Training Mitigates Reward Hacking in Live Human-AI Music Interaction
#音乐生成 #强化学习 #生成模型
🔥 8.0/10 | 前50% | #音乐生成 | #强化学习 | #生成模型
学术质量 5.5/7 | 选题价值 1.2/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Yusong Wu(Mila, Quebec Artificial Intelligence Institute, Université de Montréal)
- 通讯作者:Natasha Jaques(University of Washington),Cheng-Zhi Anna Huang(Massachusetts Institute of Technology)(论文中明确标注这两位为共同资深作者 Equal contribution as senior authors)
- 作者列表:
- Yusong Wu(Mila, Université de Montréal)
- Stephen Brade(Massachusetts Institute of Technology)
- Aleksandra Teng Ma(Georgia Institute of Technology)
- Tia-Jane Fowler(University of Washington)
- Enning Yang(McGill University)
- Berker Banar(Independent Researcher)
- Aaron Courville(Mila, Université de Montréal)
- Natasha Jaques(University of Washington)
- Cheng-Zhi Anna Huang(Massachusetts Institute of Technology)
💡 毒舌点评
亮点:本文将强化学习后训练中“奖励黑客”这个时髦但棘手的问题,在一个要求极高的实时音乐交互场景中具象化,并提出了一个巧妙且工程上可行的对抗性解决方案(GAPT),实验设计从离线到真人验证非常扎实。 短板:核心方法(对抗训练+RL)并非独创,本文的价值更多在于针对音乐交互场景的细致适配与验证,其提出的两阶段更新策略虽有效但偏“炼丹”,对解决一般性奖励黑客问题的理论贡献有限,且任务领域相对垂直。
🔗 开源详情
- 代码:提供GitHub仓库链接:https://github.com/lukewys/realchords-pytorch
- 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:使用了Hooktheory、POP909、Nottingham、Wikifonia等公开数据集,论文附录B.2提供了获取途径或说明。
- Demo:提供音频示例页面:https://realchords-GAPT.github.io
- 复现材料:论文详细说明了模型架构、训练细节、超参数、奖励函数构成、评估指标,并在附录中提供了更多结果(如奖励模型性能、不同随机种子的稳定性、长序列评估),复现指导非常充分。
- 引用的开源项目:论文中引用的开源项目包括PPO算法、LLaMA风格Transformer、RoPE位置编码、CLIP风格对比学习等,但未在开源链接部分列出具体依赖库。
- 论文中未提及模型权重的公开计划。
📌 核心摘要
- 问题:在实时人机音乐协作(如即兴合奏)中,使用强化学习(RL)后训练生成式模型以提升适应性时,模型会过度优化相干性奖励,导致输出多样性崩溃,表现为重复、简单的和弦进行,此现象被称为“奖励黑客”。
- 方法核心:提出生成对抗性后训练(GAPT)。在基于策略的RL优化中,额外训练一个判别器来区分策略生成的轨迹与真实数据轨迹。策略除了优化原有的音乐相干性奖励,还需最大化判别器给出的“真实度”评分,以此作为正则化信号,防止策略崩溃。
- 创新之处:不同于标准GAN,GAPT采用两阶段自适应判别器更新策略:预热阶段固定间隔更新,正式阶段仅当对抗性奖励超过阈值时才更新判别器,以稳定训练。相比单纯使用KL散度惩罚,对抗训练能更有效地在保持输出多样性的同时学习适应性。
- 实验结果:在固定旋律模拟、学习到的旋律智能体交互以及与12位专家音乐家的真实交互用户研究中,GAPT相比基线(仅MLE训练、仅RL训练)显著提升了输出多样性(Vendi Score)和音乐和谐度(note-in-chord ratio),并获得了更高的用户适应速度、控制感与能动性评分。例如,在固定旋律测试集上,GAPT的多样性分数(26.645)远高于ReaLchords(20.968),和谐度(0.497)也略高。
- 实际意义:为构建更自然、更具响应性和创造性的实时人机音乐交互系统提供了有效方法,其思想也可能推广至其他需要平衡奖励优化与输出多样性的序列生成任务(如对话)。
- 主要局限性:方法的有效性验证集中于特定的旋律-和弦伴奏任务,对更复杂的多声部音乐或通用文本生成任务的泛化能力未探讨。对抗训练本身增加了超参数和训练复杂性。
🏗️ 模型架构
论文涉及多个协同工作的模型组件,主要架构图见图1。
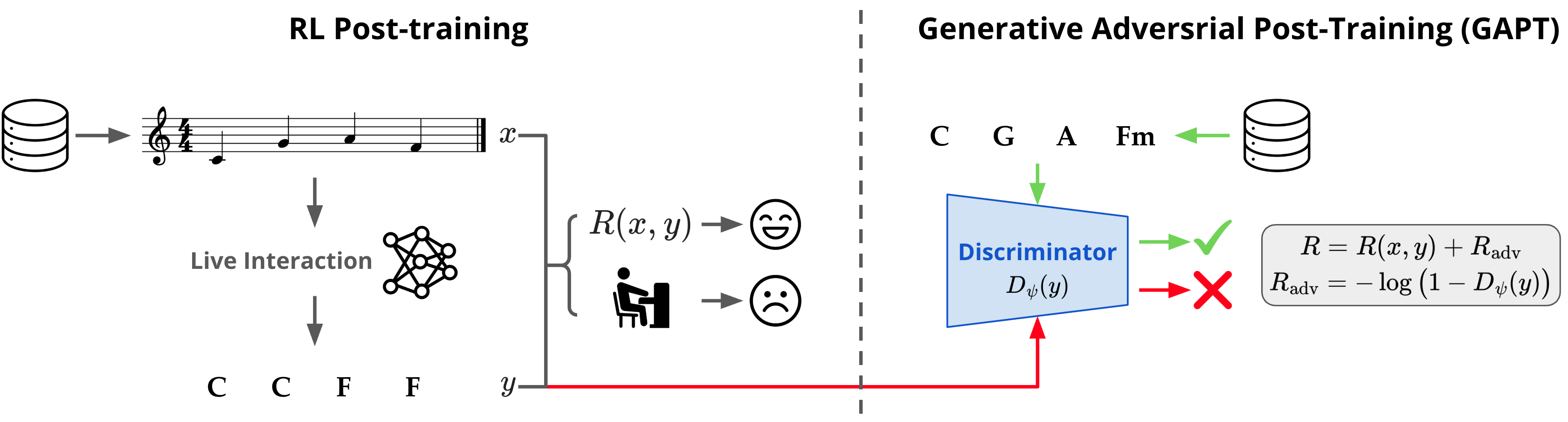
- 在线策略模型(Online Policy, πθ):一个基于解码器(Decoder-only)的Transformer模型(LLaMA风格,8层,8头,隐藏维度512)。其任务是接收自回归的旋律流
x,并实时生成对应的和弦序列y。输入输出遵循在线约束πθ(yt | x<t, y<t),即生成当前和弦时不能看到当前的旋律token,只能看到历史旋律和已生成的和弦历史。 - 离线基线模型(Offline Model, ϕω):一个编码器-解码器(Encoder-Decoder)的Transformer,用于计算KL正则化项。它能在编码阶段看到完整的输入旋律
x,其输出作为策略模型的“锚点”。 - 判别器(Discriminator, Dψ):另一个独立的Transformer编码器(8层,8头,隐藏维度512)。它接收一个和弦轨迹序列
y(或x, y对,但论文主实验仅用y),输出一个0到1的标量,表示该轨迹来自真实数据分布的概率。它被训练来区分策略生成的轨迹(负样本)和数据集中的真实轨迹(正样本)。 - 奖励模型(Reward Models):包括对比学习模型和判别模型。对比学习模型使用两个独立的编码器(旋律编码器和和弦编码器)将输入编码为嵌入向量,通过计算余弦相似度得到全局和谐信号。判别模型则是一个分类器,输入完整的旋律-和弦对,输出其“真实性”概率。
- 数据流与交互:训练时,策略模型
πθ对给定的旋律x生成在线轨迹y。该轨迹与数据集中的真实轨迹一起用于更新判别器Dψ。Dψ输出的“真实度”评分被转换为对抗性奖励Radv。最终,策略模型πθ通过PPO算法,最大化由相干性奖励、规则惩罚和对抗性奖励组成的总奖励,并同时最小化与离线模型ϕω的KL散度。整个系统通过两阶段自适应更新判别器来保持稳定。
💡 核心创新点
- 提出生成对抗性后训练(GAPT)框架:将对抗性学习(GAN)思想融入序列生成模型的RL后训练流程中。通过训练一个判别器提供基于“数据真实度”的奖励信号,与任务奖励形成互补约束,共同对抗奖励黑客,迫使模型在优化任务目标的同时保持输出分布的自然性。
- 设计两阶段自适应判别器更新策略:为了解决对抗训练不稳定的经典问题,引入了预热期和基于置信度的更新门控。第一阶段固定频率更新判别器以进行预热;第二阶段仅当近期对抗性奖励的滑动平均超过阈值时才更新判别器。此策略平衡了判别器与策略的学习速度,防止了梯度消失或振荡。
- 在实时音乐交互场景验证并解决奖励黑客:专注于“在线旋律-和弦伴奏”这一高要求场景(需实时适应、保持多样性),明确诊断了仅使用相干性奖励导致的输出多样性崩溃问题。通过GAPT方法,在保持甚至提升和谐度的同时,显著恢复了输出多样性,这一点通过客观指标和专家用户主观评价得到双重验证。
- 全面的多层次评估体系:设计了从易到难的三种评估设置:固定旋律模拟、与学习到的旋律智能体交互、与真实音乐家的实时交互。这种渐进式评估更全面地证明了方法在适应性、协作性和用户体验上的优越性。
🔬 细节详述
- 训练数据:使用了三个流行/民谣音乐数据集:Hooktheory(约21,000对)、POP909(909对)、Nottingham(1,019对)。通过随机移调(±6半音)进行数据增强。评估使用了未参与训练的Wikifonia数据集(502对)。
- 损失函数:策略优化目标为KL正则化的PPO目标:
max_θ E[R(x,y) - β DKL(πθ || ϕω) + γ H(πθ)]。总奖励R(x,y)是三项加权求和(默认权重均为1):对比和谐奖励Rcoh、规则惩罚Rrules(包括无效输出、静音、提前终止、重复惩罚)和对抗性奖励Radv = -log(1-Dψ(y))。判别器使用带标签平滑(α=0.1)的二元交叉熵损失训练。 - 训练策略:PPO训练1000步,Actor学习率5e-7,Critic学习率9e-6,使用Adam优化器(β1=0.9, β2=0.95)。采用线性warmup(100步)后接余弦衰减。批量大小384,迷你批量大小48。熵系数γ=0.01,KL系数β=0.001。判别器学习率9e-5,同样采用线性warmup和余弦衰减。判别器在Phase 1(前200步)每5次PPO更新后更新一次,共更新40次;在Phase 2(后800步)采用自适应更新,当最近3次PPO更新的平均对抗奖励 > 1.0时才更新,共更新27次。
- 关键超参数:在线/判别器模型:8层,8头,隐藏维度512。离线模型:编码器-解码器各8层。最大序列长度T=256帧(十六分音符)。用户研究BPM=80,采样温度0.8。
- 训练硬件:论文未明确说明。
- 推理细节:在实时系统中,采用客户端-服务器架构,生成音乐块以保持缓冲(前瞻4拍,提交4拍)。推理温度0.8。
- 正则化技巧:使用了KL散度正则化、熵正则化、判别器标签平滑,以及两阶段自适应更新策略来稳定对抗训练。
📊 实验结果
主要评估结果(固定旋律模拟)
| 系统 | 测试集和谐度 (↑) | 测试集多样性 (↑) | 外部分布和谐度 (↑) | 外部分布多样性 (↑) |
|---|---|---|---|---|
| Online MLE | 0.368 | 29.491 | 0.362 | 16.401 |
| ReaLchords | 0.484 | 20.968 | 0.475 | 8.417 |
| GAPT w/o Adv. | 0.476 | 20.814 | 0.447 | 8.034 |
| GAPT | 0.497 | 26.645 | 0.470 | 11.295 |
| Ground Truth | 0.727 | 27.922 | 0.784 | 10.962 |
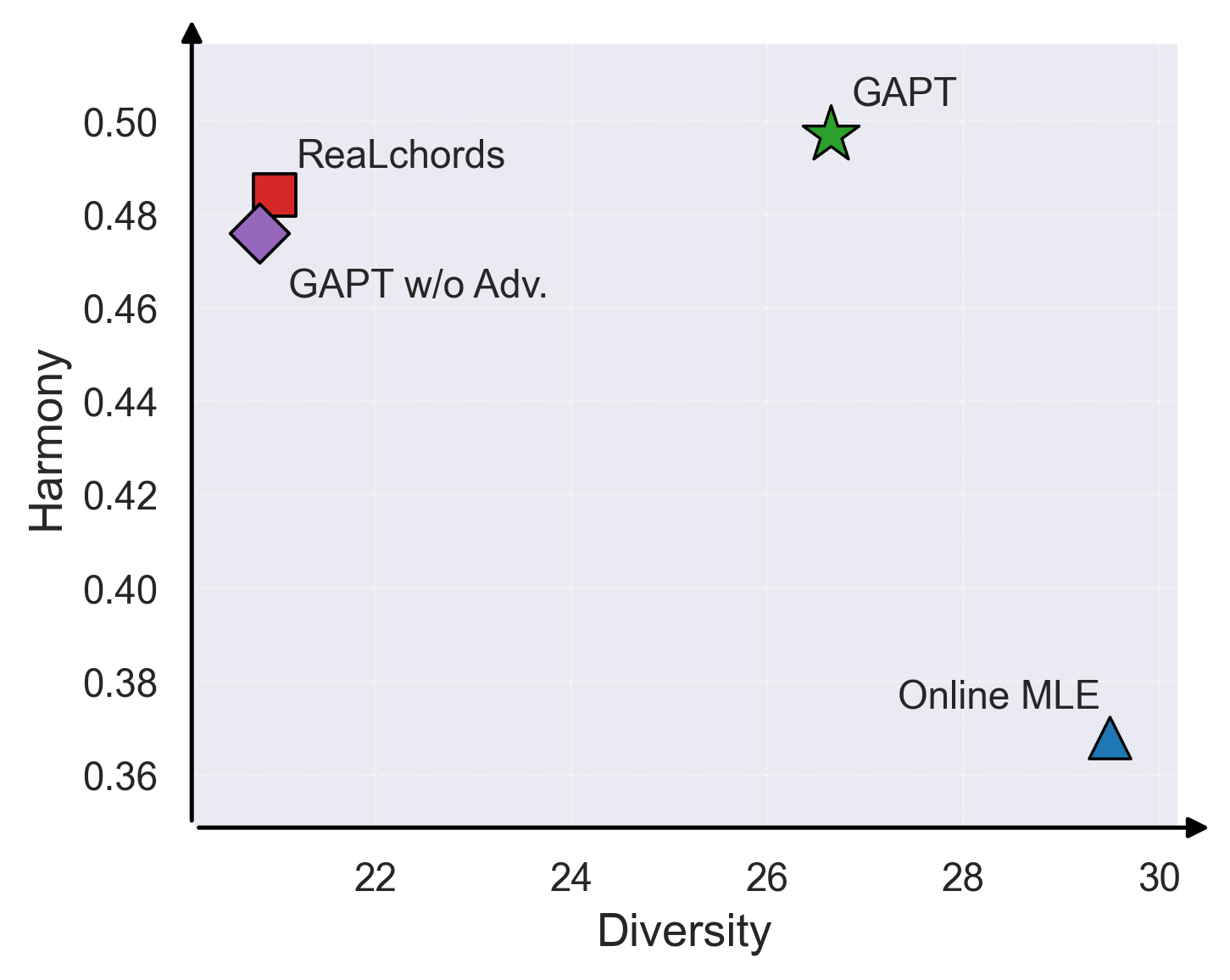
- 图4结论:在测试集(a)和外部数据集(b)上,GAPT方法在“和谐度-多样性”权衡上明显优于基线,更接近真实数据(Ground Truth)的Pareto前沿。t-SNE可视化(c)也显示GAPT生成的和弦覆盖了更广的特征空间。
与旋律智能体交互及用户研究结果
| 系统 | 旋律智能体交互和谐度 | 旋律智能体交互多样性 | 用户交互和谐度 | 用户交互多样性 |
|---|---|---|---|---|
| Online MLE | 0.650 | 18.071 | 0.448 | 12.465 |
| ReaLchords | 0.626 | 7.480 | 0.462 | 9.786 |
| GAPT w/o Adv. | 0.540 | 5.658 | N/A | N/A |
| GAPT | 0.648 | 12.914 | 0.467 | 11.794 |
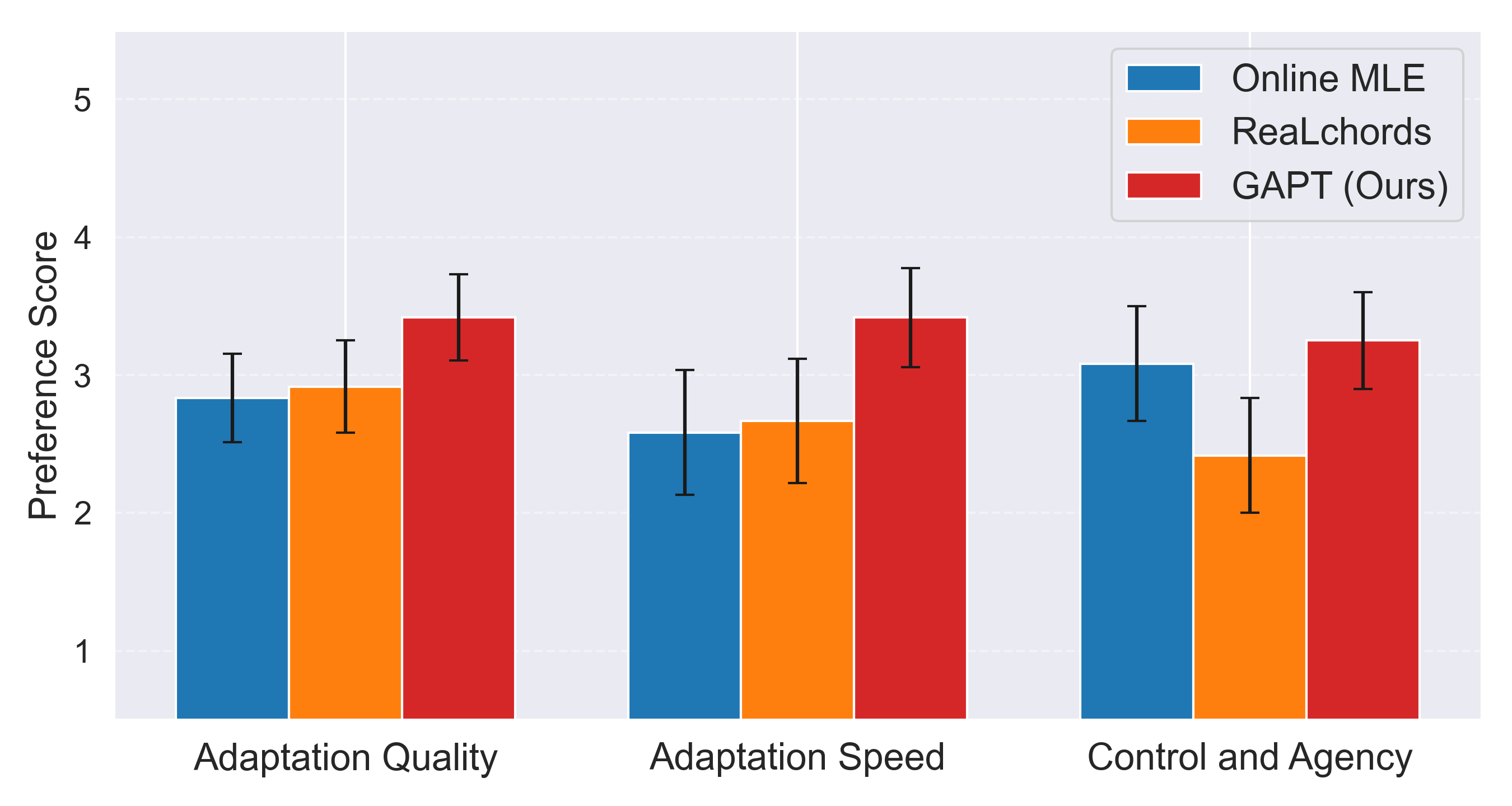
- 图3结论:在12位专家音乐家的实时交互研究中,GAPT在“适应速度”和“控制与能动性”两个指标上显著优于ReaLchords (p < 0.05),在所有三个指标上均取得最高平均分。
消融实验亮点
- 奖励权重消融(表7):移除规则惩罚会导致明显的奖励黑客(生成无效序列,和谐度/多样性不可用)。过度强调任一奖励项(和谐度、规则、对抗性)都会导致性能下降。
- RL目标消融(表8):在GRPO算法上应用GAPT,同样能恢复多样性,表明方法对不同的RL优化器具有鲁棒性。
- 判别器输入消��(表9):仅使用和弦轨迹
y作为判别器输入,比使用旋律-和弦对(x, y)效果更好,后者可能因过拟合特定配对而削弱了判别器的泛化能力。
⚖️ 评分理由
- 学术质量:5.5/7:创新性明确,将对抗训练用于RL后训练的奖励黑客缓解是一个有趣且有效的思路。技术实现合理,两阶段更新策略设计巧妙。实验设计全面严谨,从模拟到真人研究层层递进,证据可信。但核心思想(对抗+RL)并非首创,贡献主要在于针对音乐场景的适配与验证。
- 选题价值:1.2/2:选题聚焦于实时人机音乐交互这一具体但重要的问题,该问题对AI音乐创作的实用化至关重要。解决奖励黑客是当前AI对齐领域的热点,具有理论参考价值。应用空间明确,但相对垂直于音乐生成子领域。
- 开源与复现加成:1.0/1:论文提供了完整的代码仓库、音频示例、详细的模型架构、训练超参数、奖励模型细节和训练动态图,并说明了数据集信息。复现条件非常充分,达到了最高加成标准。