📄 From Natural Alignment to Conditional Controllability in Multimodal Dialogue
#语音合成 #多模态模型 #基准测试 #数据集
✅ 6.5/10 | 前25% | #语音合成 | #数据集 | #多模态模型 #基准测试
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Zeyu Jin(清华大学计算机科学与技术系)
- 通讯作者:Xiaoyu Qin(清华大学计算机科学与技术系)、Jia Jia(清华大学计算机科学与技术系 / BNRist,清华大学)
- 作者列表:
- Zeyu Jin(清华大学计算机科学与技术系)
- Songtao Zhou(清华大学计算机科学与技术系)
- Haoyu Wang(清华大学计算机科学与技术系)
- Minghao Tian(Rice University)
- Kaifeng Yun(清华大学深圳国际研究生院)
- Zhuo Chen(ByteDance)
- Xiaoyu Qin(清华大学计算机科学与技术系)
- Jia Jia(清华大学计算机科学与技术系 / BNRist,清华大学)
💡 毒舌点评
亮点在于其“基建”思维,为多模态对话生成这个嘈杂的领域,搭建了一套清晰的“路标”(任务定义)、“高速公路”(大规模标注数据集)和“考题”(跨模态一致性基准)。短板则是论文止步于“出题”和“阅卷”,并未提出一个能在这条新路上跑得更快的“新车”(统一的端到端生成模型),实验部分更多地是在证明现有模型“考不及格”。
🔗 开源详情
- 代码:论文在“ETHICS STATEMENT”中承诺:“Our experimental code and data curation pipeline will be made publicly available upon acceptance of the paper.” 但未提供具体仓库链接。
- 模型权重:论文中提到的基线模型(如Higgs-Audio-V2, Dia)是外部开源项目��但本文未贡献新的生成模型权重。
- 数据集:论文承诺开源MM-DIA和MM-DIA-BENCH。获取方式应是根据提供的标注(时间戳、转录、风格标签等)自行对齐公开的影视内容。
- Demo:未提及(论文中未提及在线演示链接)。
- 复现材料:论文提供了详尽的附录,包括数据处理细节、验证结果、指标解释等,有利于复现。
- 论文中引用的开源项目:
- 生成模型基线:Higgs-Audio-V2 (Boson AI), Dia (Nari Labs), CosyVoice, Zero-Shot Dialogue Generation (ZSDG), MoonCast, Har-moniVox。
- 视频生成基线:FLOAT, MultiTalk, Sonic, Wan-2.2, HunyuanVideo。
- 工具/模型:Gemini 2.5-pro (Google), Qwen2.5-VL-7B, GPT-5 (OpenAI), Insightface (用于人脸识别),以及语音质量评估工具(如UTMOS)。
- 开源情况总结:论文承诺将在接受后开源核心数据集和处理代码,但目前尚未提供。论文本身严重依赖上述引用的开源模型和工具进行实验和标注。
📌 核心摘要
- 问题:当前多模态对话生成研究主要关注单模态(如语音或视觉)的内容真实性,而忽略了跨模态(语音、视觉、文本)在交互风格(如情感、关系、互动模式)上的系统性对齐与精细可控性,导致生成内容的表达力和可控性不足。
- 方法核心:提出了一套从电影/电视剧中自动提取对话、并进行细粒度交互风格标注的数据处理流水线。基于此构建了大规模多模态对话数据集MM-DIA,并定义了可控多模态对话生成(MDG)任务,将其形式化为带显式/隐式条件变量的条件生成问题。同时,建立了专门评估跨模态风格一致性的基准MM-DIA-BENCH。
- 创新点:
- 首次针对“对话表达力”而非“对话内容”构建大规模多模态数据集。
- 提出两种互补的表达力标注范式:结构化“情感三元组”和自由风格描述。
- 建立了首个专门评估音频-视频风格一致性的对话生成基准MM-DIA-BENCH。
- 实验结果:
- 在风格可控语音合成(Task 1)上,使用MM-DIA微调基线模型(如Higgs-Audio-V2)能显著提升性能。例如,WER从31.25降至4.45,指令遵循度(Human-MOS)从3.11提升至4.13(见表4)。
- 在视觉条件语音合成(Task 2)和语音驱动对话视频生成(Task 3)上,现有模型(如HarmoniVox、Wan-2.2)在MM-DIA-BENCH上暴露出明显的跨模态风格对齐不足(如指令遵循度、自发性得分较低),揭示了现有技术的局限(见表5,表6)。
- 实际意义:为可控多模态对话生成提供了标准化的定义、高质量的数据基础和严格的评估工具,有望推动该领域从“内容生成”向“可控交互生成”演进,对电影配音、虚拟人交互等应用有潜在价值。
- 局限性:工作重心在于数据集和评估框架的构建,未提出一个能统一处理多模态输入输出的端到端生成模型;数据集来源于影视作品,与真实日常对话可能存在域差距;部分依赖Gemini等大型多模态模型进行标注,引入了潜在偏差。
🏗️ 模型架构
本文并非提出一个新的神经网络模型架构,而是定义了多模态对话生成(MDG)的任务框架和数据处理流水线。其“架构”体现在:
- 数据处理流水线架构(如图2所示):
- 输入:原始的电影/电视视频、音频、字幕文件。
- 步骤1:多源字幕校准与同步:将ASR输出与多源未校准字幕对齐,生成校准后的时间戳和转录文本。
- 步骤2:多模态对话提取:采用容忍性场景分割算法(引入缓冲机制的动态关键帧池,如算法1所示)和VLM/LLM结合,从长视频中连贯地提取对话片段。
- 步骤3:句子级细粒度标注:使用Gemini-2.5-pro等模型进行说话人归因、非言语声音标注、说话人可见性检测。
- 步骤4:对话级表达力标注:同样使用Gemini-2.5-pro,为每段对话生成“情感三元组”(关系、互动模式、情感基调)和自由风格描述。
- 输出:带有丰富多模态标注的对话片段(文本、音频、视频、风格标签)。
- MDG任务架构:将MDG统一建模为条件概率分布
P(Y | C, Z),其中C是多模态上下文(文本、音频、视觉),Z是风格控制变量(显式如文本提示,隐式如视觉特征),Y是生成的多模态内容。具体实例化为三个子任务(图1):- Task 1(显式控制):基于文本和风格提示生成对话语音
A。 - Task 2(隐式控制):基于视觉关键帧和文本生成对话语音
A。 - Task 3(隐式控制):基于对话音频和文本生成对话视频
V。
- Task 1(显式控制):基于文本和风格提示生成对话语音
💡 核心创新点
- 面向“表达力”的标注范式创新:提出“情感三元组”和“自由描述”两套互补的标注体系,超越了传统的离散情感标签,能刻画角色关系、互动动态和情感流转等连续、复杂的交互属性,为细粒度可控生成提供了语义基础。
- 大规模、高质量多模态对话数据集(MM-DIA):构建了首个专注于对话级表达力的多模态数据集(360+小时,5.47万段对话)。其创新在于:a) 数据源为富有表现力的影视作品;b) 包含句子级和对话级多维度标注(如说话人、非言语声音、情感动态);c) 提供完整的音视频同步内容。
- 跨模态风格一致性评估基准(MM-DIA-BENCH):针对现有基准忽视对话级跨模态对齐的问题,专门构建了309段高表现力双人对话基准,确保说话人可见,用于评估生成语音或视频在情感、互动模式上是否与上下文(另一模态)保持风格一致。
- 对MDG任务的形式化与分类:首次清晰地将多模态对话生成定义为条件生成问题,并区分“显式控制”(自然语言提示)和“隐式控制”(跨模态线索推断)两种范式,为研究提供了清晰的问题框架。
🔬 细节详述
- 训练数据:
- MM-DIA:来自200+部电影和9部电视剧的原始视频,最终提取360.26小时、54,700个对话片段。数据经过了字幕校准、多模态对话提取、多维度标注。数据增强未明确说明。
- MM-DIA-BENCH:从MM-DIA中筛选的309段高表现力、说话人可见的双人对话。
- 损失函数:论文未明确说明其任务1-3所使用的生成模型的具体损失函数,因其主要验证基于现有预训练模型(如Higgs-Audio-V2, Dia-1.6B)在MM-DIA上微调的效果。
- 训练策略:
- 对于语音合成实验(Task 1),采用对预训练模型进行监督微调(SFT) 的方式。
- 未提供具体的学习率、warmup、batch size、优化器、训练步数等细节(论文中未明确说明)。
- 关键超参数:未提供模型的具体参数规模、层数等细节(论文中未明确说明)。
- 训练硬件:未说明(论文中未提及)。
- 推理细节:未明确说明推理时的具体解码策略、温度等(论文中未明确说明)。
- 正则化或稳定训练技巧:未明确说明(论文中未提及)。
- 标注工具细节:使用Gemini-2.5-pro进行对话级表达力标注,并进行了人工验证(表8显示其完整性高、幻觉率低)。使用Qwen 72B,缓冲区大小b=3进行场景分割,以平衡性能和速度(表9)。
📊 实验结果
主要实验分为三部分,对应三个任务:
- 任务1:风格可控对话语音合成(显式控制)
- 基准模型:Dia-Base, Higgs-Audio-V2-Base 及其SFT版本。
- 测试集:Test (MM-DIA子集), Hard (高表现力子集), OOD (域外)。
- 关键结果(Description控制,Test集):见下表(表4)
| 模型 | WER↓ | UTMOS↑ | sa-SIM↑ | cp-WER↓ | Human-MOS 质量↑ | Human-MOS 指令遵循↑ | Gemini 指令遵循↑ |
|---|---|---|---|---|---|---|---|
| Dia-Base | 19.99 | 2.27 | 0.389 | 51.71 | 2.41 | 2.50 | 3.81 |
| Higgs-Audio-V2-SFT | 4.45 | 3.28 | 0.447 | 33.77 | 4.44 | 4.13 | 4.71 |
- 结论:在MM-DIA上微调后,Higgs-Audio-V2的WER大幅下降(31.25→4.45),指令遵循度显著提升,证明了MM-DIA对增强风格可控性的有效性。
- 任务2:视觉条件对话语音合成(隐式控制)
- 基准模型:HarmoniVox, Cascaded VLM (Gemini/GPT) + Higgs-Audio-SFT。
- 测试集:MM-DIA-BENCH(133段)。
- 关键结果:见下表(表5)
| 模型 | WER↓ | UTMOS↑ | sa-SIM↑ | cp-WER↓ | 标签召回率↑ | Gemini 指令遵循↑ |
|---|---|---|---|---|---|---|
| HarmoniVox | 21.22 | 3.57 | 0.62 | 30.98 | 40.47 | 2.41 |
| Cascaded GPT + Higgs | 5.79 | 3.44 | 0.48 | 14.58 | 52.17 | 3.52 |
- 结论:级联方法优于端到端模型,但与任务1的显式控制相比,跨模态指令遵循度下降(例如,从4.71降至3.52),揭示了隐式风格推断的挑战。
- 任务3:语音驱动对话视频生成
- 基准模型:涵盖SI2V(如FLOAT, MultiTalk, Sonic)和T2V(如Wan-2.2, HunyuanVideo)家族。
- 测试集:MM-DIA-BENCH(133段)。
- 关键结果:见下表(表6)
| 模型 | FVD↓ | LSE-C↑ | LSE-D↓ | 关系准确率↑ | 互动模式准确率↑ | Gemini 指令遵循↑ |
|---|---|---|---|---|---|---|
| MultiTalk (SI2V) | 124.54 | 5.31 | 8.80 | - | - | 4.63 |
| Wan-2.2 T2V | 300.09 | - | - | 53.66% | 18.70% | 3.27 |
| Ground Truth | - | 6.28 | 8.33 | 100% | 100% | 4.90 |
- 结论:当前系统均无法充分解决对话视频生成问题。SI2V管道在连贯性上较好,但依赖关键帧;T2V管道能捕捉部分高层语义,但在关系/互动模式的准确性上表现很差(如互动模式准确率仅18.70%),指令遵循度也远低于真实数据。
实验相关图表:
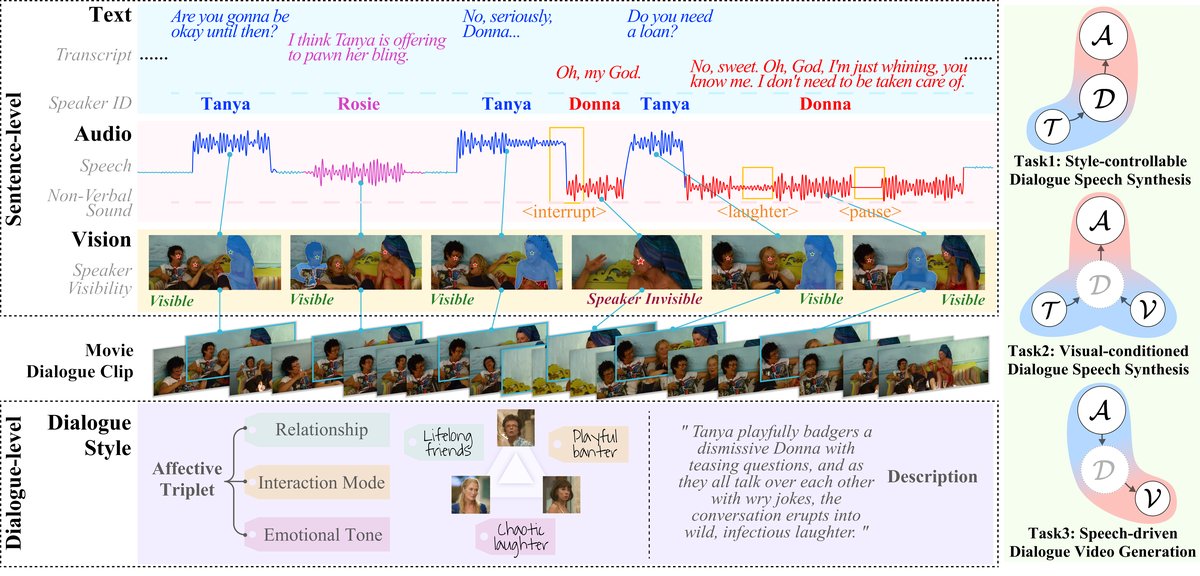 图1说明:展示了MM-DIA数据集中的对话片段及其层级标注(句子级和对话级)。右侧展示了MDG框架下的三个任务:显式控制(T1)、隐式视觉控制(T2)、隐式音频控制(T3)。
图1说明:展示了MM-DIA数据集中的对话片段及其层级标注(句子级和对话级)。右侧展示了MDG框架下的三个任务:显式控制(T1)、隐式视觉控制(T2)、隐式音频控制(T3)。
 图2说明:详细展示了从原始影视数据到最终标注对话片段的完整处理流程,包括字幕校准、多模态对话提取、细粒度标注等步骤。
图2说明:详细展示了从原始影视数据到最终标注对话片段的完整处理流程,包括字幕校准、多模态对话提取、细粒度标注等步骤。
 图3说明:展示了MM-DIA数据集中双人性别、关系类型、互动模式的分布情况,体现了数据的多样性和与真实社交互动的一致性。
图3说明:展示了MM-DIA数据集中双人性别、关系类型、互动模式的分布情况,体现了数据的多样性和与真实社交互动的一致性。
 图4说明:展示了多源字幕校准中可能出现的问题案例,以及校准后的效果。
图4说明:展示了多源字幕校准中可能出现的问题案例,以及校准后的效果。
⚖️ 评分理由
- 学术质量(5.5/7):创新性(3/4):主要贡献在于系统性的数据工程和任务/评估框架定义,而非模型算法本身的突破。技术正确性与实验充分性(2.5/3):数据处理方法设计严谨,实验对比了多种基线,在三个不同任务上进行了评估,指标全面(结合了语音质量、对话质量、跨模态一致性和人类评估),结论具有说服力。证据可信度高,但部分依赖商业模型(Gemini)进行标注和评估。
- 选题价值(1.5/2):选题处于多模态AI的前沿,直击当前对话生成系统“可控性”不足的痛点。为后续研究提供了关键的数据和评估基础设施,具有较高的潜在影响力。与语音研究者的相关性在于其将语音合成置于更丰富的多模态交互上下文中。
- 开源与复现加成(0.5/1):论文明确承诺开源核心贡献(数据集和代码),这对社区复现和推动领域发展价值巨大。但当前未提供具体链接,因此加成有限。