📄 Discovering and Steering Interpretable Concepts in Large Generative Music Models
#音乐生成 #音频大模型 #稀疏自编码器 #模型评估 #模型解释性
✅ 7.5/10 | 前25% | #音乐生成 | #稀疏自编码器 | #音频大模型 #模型评估
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Nikhil Singh(Dartmouth College)、Manuel Cherep(MIT)(共同第一作者)
- 通讯作者:未说明
- 作者列表:Nikhil Singh(Dartmouth College), Manuel Cherep(MIT), Pattie Maes(MIT)
💡 毒舌点评
亮点在于将大语言模型可解释性领域的前沿方法(稀疏自编码器)成功移植到音乐生成模型,并提出了一个完整的、可扩展的概念发现与引导框架,具有方法论上的开创性。短板在于实验规模局限于单一模型家族(MusicGen),且自动化评估依赖CLAP等外部模型,其评估结果的可靠性有待更全面的人工验证支撑,部分技术细节(如SAE训练策略)也未完全公开。
📌 核心摘要
- 问题:大型音乐生成模型(如MusicGen)能生成高质量音乐,但其内部表示如同“黑箱”,缺乏可解释性。我们需要理解模型内部“学到”了哪些音乐概念,以及这些概念是否与人类音乐理论一致或能揭示新的音乐规律。
- 方法核心:提出一个多阶段流水线:首先,从音乐语料库中提取预训练MusicGen模型的残差流激活;其次,使用稀疏自编码器(SAEs)对这些高维激活进行降维和稀疏化,以发现潜在的、可解释的特征;最后,通过自动标注(使用多模态LLM如Gemini和预训练音频分类器)和人类验证来为这些特征命名,并通过干预残差流来测试特征的可引导性。
- 创新点:这是首次将稀疏自编码器技术应用于音频/音乐领域的生成模型;构建了一个可扩展的、无需监督的概念发现与自动评估流水线;不仅发现了与已知音乐理论(如流派、乐器)一致的特征,还发现了一些理论上未明确编码但感知上连贯的“涌现”规律(如特定电子音效、单音纹理)。
- 主要实验结果:在MusicGen-Large模型上,通过SAE发现了数千个可过滤的特征。人类验证中,基于Essentia分类器的标签获得的人类置信度(3.96/5)高于基于Gemini的标签(3.19/5)。引导实验表明,约15-35%的测试特征能成功引导生成内容向目标概念靠拢,听觉测试(10名参与者)显示66%的情况下,SAE引导的版本比基线或随机引导版本更易被识别为目标概念。结果表明,模型的深层编码了更易解释的特征,且大模型的特征组织更具层次性。
- 实际意义:为理解生成式AI的“音乐理解”提供了实证工具,架起了模型内部表示与人类音乐概念之间的桥梁,有望促进更透明、可控的AI音乐创作,并为音乐理论研究提供新视角。
- 主要局限性:研究主要针对无条件生成(未使用文本提示),未探讨文本条件下的概念表示;自动化评估指标(CLAP分数)可能不完全反映人类对音乐概念的理解;引导实验的成功率有待提高,且引导可能导致生成质量下降。
🏗️ 模型架构
该论文的核心并非提出一个新的生成模型,而是一个用于分析和引导现有模型(MusicGen)内部表示的方法流水线。其整体架构如图1所示。
完整流程分为三个主要阶段:
激活提取与数据集构建:
- 输入:一个大型音乐语料库(论文中使用MusicSet,约16万段音频)。
- 处理:将音频输入预训练的MusicGen模型(MusicGen-Large或MusicGen-Small),并提取其多个Transformer层的残差流激活向量。
- 输出:一个“激活数据集”,包含每段音频在不同层、不同时间步的激活向量。
特征发现与过滤:
- 核心组件 - 稀疏自编码器(SAE):这是一个关键创新。SAE接收残差流激活
x(维度d),通过编码器h = ReLU(Wex + be)映射到一个更高维(扩张因子ε)的潜在空间h(维度ε·d)。接着应用k-稀疏投影Pk,仅保留激活值最高的k个特征,其他置零,得到稀疏编码z。解码器ˆx = Wdh + bd尝试从z重建原始激活x。训练目标是使重建误差最小化,同时通过k和ε强制潜在表示稀疏且信息丰富。 - 数据流:原始激活
x→ SAE编码器 → 稀疏编码z→ SAE解码器 → 重建激活ˆx。训练损失为||x - ˆx||²₂。 - 特征过滤:训练好的SAE的每个潜在维度对应一个“特征”。论文定义了基于特征在验证集上激活频率(
ri)的过滤规则,剔除从未激活(ri=0)、过度普遍(ri > 0.25)或过度罕见(0 < ri < 0.01)的特征。
- 核心组件 - 稀疏自编码器(SAE):这是一个关键创新。SAE接收残差流激活
特征标注与引导:
- 标注:为每个过滤后的特征,找出其Top-10激活最高的音频片段。然后使用两种自动方法标注:
- 生成式标注:将Top-10音频拼接后输入多模态大模型(如Gemini Flash 1.5),请求其发现共通的音乐模式并给出标签、置信度和描述。
- 分类器式标注:使用预训练的Essentia音频分类模型(如流派、情绪、乐器标签)对特征激活的音频进行分类,取高频标签。
- 一致性评估:使用CLAP模型计算自动标签与特征激活音频之间的语义对齐度(CLAP分数),作为标签质量的量化指标。
- 引导:若要引导模型生成某个特征(如“合成器流行”),在生成过程中,将该特征对应的SAE解码器权重向量
Wd,j按一定强度α·β加到当前层的残差流激活x上,即x′ = x + α · β · Wd,j,从而偏置生成过程。
- 标注:为每个过滤后的特征,找出其Top-10激活最高的音频片段。然后使用两种自动方法标注:
💡 核心创新点
- 首次将稀疏自编码器(SAE)应用于音频/音乐生成模型的可解释性研究。之前SAE主要用于分析语言模型(如GPT)的内部表示。该工作成功将这一前沿解释工具扩展到多模态音频领域,为理解音乐生成模型打开了一扇新窗。
- 构建了可扩展的、无需监督的音乐概念自动发现与评估流水线。相较于传统的探针(Probing)方法需要预设概念,该方法能够发现模型自发形成的概念,包括那些人类理论尚未明确描述的“涌现”规律。流水线整合了激活提取、特征发现、多策略自动标注(生成式与分类器式)和量化评估(CLAP)。
- 提供了大规模实证证据,揭示大型音乐生成模型内部概念表示的组织规律。研究发现:a) 模型的深层比浅层编码了更易解释、更符合人类概念的特征;b) 模型规模(Large vs. Small)不仅影响特征数量,更影响特征在不同层之间的分化程度和可提取性;c) 发现了大量与已知音乐概念(如流派、乐器、音色)对齐的特征,以及一些新颖的、未被理论充分描述的规律性。
🔬 细节详述
- 训练数据:使用MusicSet数据集,包含约16万段约10秒的音频,源自MTG-Jamendo, MusicCaps, MusicBench。数据为无条件音频。
- 损失函数:稀疏自编码器的训练损失为重建均方误差(MSE),即
Ex[||x - D(E(x))||²₂],其中隐含通过k-稀疏投影实现L1稀疏约束。 - 训练策略:论文未详细说明SAE的具体训练优化器、学习率、batch size等细节。仅提及实验了扩张因子
ε ∈ {4, 32}和稀疏水平k ∈ {32, 100}。 - 关键超参数:目标生成模型为MusicGen-Large(d=2048)和MusicGen-Small(d=1024)。提取激活的层为模型深度的25%、50%、75%位置以及早期(第2层)和晚期(倒数第二层)。SAE的关键超参数是扩张因子
ε和稀疏度k。过滤阈值为θmax=0.25,θmin=0.01。 - 训练硬件:使用AWS RES,训练在4x NVIDIA L40s GPU节点上进行。部分实验(如CLAP计算)在128核Intel Xeon CPU节点上并行化。
- 推理细节:引导实验在“Simple melody”中性提示下进行,引导强度
α ∈ {0.0, 1.0},β为特征最大激活强度。 - 正则化技巧:SAE通过强制稀疏性(k-sparse projection)作为一种正则化,鼓励发现可重用的“原子”概念。
📊 实验结果
主要发现与数据:
- 特征统计与过滤:过滤后,在MusicGen-Large不同配置下可发现数百至数千个特征,而在MusicGen-Small上通常不超过100个。具体数据见下表(基于论文Table 1)。
| 模型 | 扩张因子(ε) | 稀疏度(k) | 层 (L) | 保留特征数 |
|---|---|---|---|---|
| MusicGen Large | 4 | 100 | 2 | 407 |
| 32 | 100 | 2 | 2344 | |
| 32 | 100 | 24 | 412 | |
| 32 | 100 | 46 | 177 | |
| MusicGen Small | 32 | 100 | 2 | 59 |
| 32 | 100 | 22 | 17 |
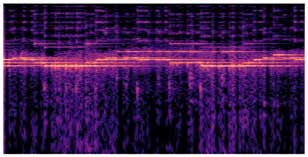
概念质量评估(CLAP分数):图3显示了自动标签与特征音频的CLAP对齐分数随模型深度的变化。对于MusicGen-Large,更深的层产生更高CLAP分数的特征,表明其特征更易于与人类概念对齐。
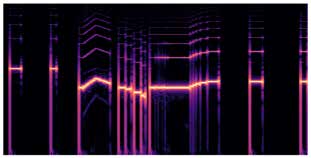
自动标注方法对比:图4展示了所有SAE中特征的最大CLAP分数分布。Essentia分类器标签和Gemini生成标签都能获得较好的对齐分数,但没有单一策略占据绝对优势。
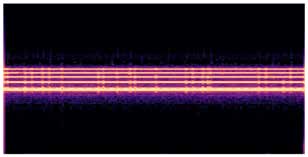 人类验证:对400个特征进行的A/B测试显示,参与者对Essentia标签的信心(3.96/5,71%评分>4)高于对Gemini标签的信心(3.19/5,47%评分>4)。
人类验证:对400个特征进行的A/B测试显示,参与者对Essentia标签的信心(3.96/5,71%评分>4)高于对Gemini标签的信心(3.19/5,47%评分>4)。特征引导效果:下表(基于论文Table 4.6)显示了不同SAE配置下,具有积极引导改善(引导后CLAP分数提高)的特征比例。
| 模型 | ε | k | 层 | 引导改善比例 |
|---|---|---|---|---|
| MGL | 32 | 100 | 24 | 96/408 (23.5%) |
| MGL | 32 | 100 | 36 | 46/131 (35.1%) |
| MGL | 32 | 100 | 46 | 27/177 (15.3%) |
| MGL | 32 | 32 | 24 | 44/149 (29.5%) |
| MGL | 32 | 32 | 36 | 39/135 (28.9%) |
| MGL | 32 | 32 | 46 | 16/71 (22.5%) |
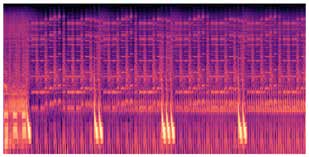
听觉引导测试:10名参与者对Top-50可引导特征进行三选一匹配测试(基线、随机引导、SAE引导)。结果SAE引导版本被选中66/100次,基线和随机引导各17次,差异极其显著(χ² = 48.02, p < .0001)。图5展示了引导效果示例。
⚖️ 评分理由
- 学术质量:6.5/7:论文在方法论上具有显著的创新性,首次将SAE引入音乐生成模型解释领域。技术正确性高,流水线设计合理,结合了多种自动化评估手段。实验充分性好,提供了跨模型、跨层、跨SAE配置的广泛实验,并包含了定量指标(CLAP分数)、定性示例和人类评估。证据可信度较强,但自动化评估指标(CLAP)的效度存在一定局限,人类评估规模有限。
- 选题价值:1.0/2:选题位于AI可解释性与AI生成式艺术的交叉点,具有前沿性。它为理解生成式AI如何“理解”复杂非结构化数据(音乐)提供了实证工具,潜在影响深远,可用于提升模型透明度和可控性。但研究聚焦于特定的音乐生成模型,应用场景相对垂直,与广大音频/语音读者的直接相关性中等。
- 开源与复现加成:0.0/1:论文提供了项目主页链接(musicdiscovery.media.mit.edu),但未明确提供代码、模型权重或处理后的数据集的公开访问方式。论文详细描述了方法流程,但部分关键训练细节(如SAE优化器参数)缺失,这影响了完全复现的可能性。因此,此项加成暂无。