📄 Deep Learning with Learnable Product-Structured Activations
#端到端 #音频分类 #模型评估 #开源工具
✅ 7.5/10 | 前25% | #音频分类 | #端到端 | #模型评估 #开源工具
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Saanjali Maharaj(University of Toronto)
- 通讯作者:未明确标注,根据署名顺序推断为Prasanth B. Nair(University of Toronto)
- 作者列表:Saanjali Maharaj(University of Toronto)、Prasanth B. Nair(University of Toronto)
💡 毒舌点评
LRNNs通过将乘积结构激活函数“可学习化”,确实为表示高阶交互提供了一个理论上优雅、实验上高效的框架,特别是在信号表示任务上超越了SIREN等知名方法。然而,其每层的计算开销(涉及大量小MLP)和内存占用(中间乘积项)不容小觑,论文对此的优化策略(如核融合)仅停留在概念层面,并未给出实际性能数据,这在实际部署时可能成为瓶颈。
🔗 开源详情
- 代码:论文提供了代码仓库链接:
https://github.com/dacelab/lrnn。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中使用的图像(Cameraman, Retina, ImageNet, DIV2K, Kodak, Parrot)、音频、PDE数据集和CT数据集,未说明是否公开或如何获取。
- Demo:论文中未提及在线演示。
- 复现材料:论文在附录B和各实验章节提供了详细的架构规格、超参数和训练流程。复现材料主要依赖这些文本描述和提供的代码仓库。
- 论文中引用的开源项目:PyTorch深度学习框架。
📌 核心摘要
- 要解决什么问题:现代神经网络受限于固定的激活函数,难以自适应地学习任务相关的表示,尤其在捕捉高阶特征交互和控制频谱偏差(如对高频信号的表示)方面存在不足。
- 方法核心是什么:提出深层低秩分离神经网络(LRNNs),其核心是为每个神经元设计“可学习的乘积结构激活函数”。具体地,输入先经过线性投影,然后通过多个可学习的、参数化的小型单变量函数变换,最后将这些变换结果相乘,形成一个高度灵活的非线性激活。
- 与已有方法相比新在哪里:与固定激活函数(ReLU, SIREN)相比,LRNN的激活函数本身是可学习的,并且其乘积结构天然擅长建模特征间的乘性/高阶交互。与同样使用可学习激活函数的KANs相比,LRNN通过结构化的乘积形式,在理论上能以更少的参数缓解维数灾难,并在实践中训练更稳定。
- 主要实验结果如何:在多个基准测试上达到或超越SOTA。图像表示:在1000张ImageNet图像上,LRNN-SPDER在40dB PSNR目标上达到100%成功率,远超SIREN(1.8%)和SPDER(26.4%)。音频表示:MSE比基线低3-11倍。PDE求解:误差比SIREN低两个数量级,且参数减少8倍。稀疏CT重建:PSNR(29.13 dB)和SSIM(0.7455)均为最优。
- 实际意义是什么:为构建更高效、表达能力更强的神经网络提供了一种新的通用构建块。在需要高精度信号表示(如医学成像、科学计算)和处理高维数据交互的任务中具有显著优势。
- 主要局限性是什么:计算和内存开销相对较高,特别是反向传播时需要存储大量中间乘积项;虽然提供了优化思路(如核融合、混合精度),但未给出具体实现和验证;架构的有效性高度依赖于单变量组件函数的设计(如使用周期激活函数)。
🏗️ 模型架构
LRNN是对MLP的推广,其核心是引入了“乘积结构激活函数”的神经元。
- 完整输入输出流程:输入向量
x经过多层LRNN变换,最终通过线性层输出预测值ŷ。每一层LRNN接收上一层的输出ϕ(k-1),通过线性投影得到多个中间向量zℓ,(k),然后对每个向量zℓ,(k)应用独立的乘积结构激活函数φ(k)ℓ得到标量,所有这些标量构成当前层的输出向量ϕ(k)。 - 主要组件:
- 线性投影层:
Wℓ,(k)和bℓ,(k),将输入投影到̄dk维空间。 - 可学习乘积结构激活函数:
φ(k)ℓ(zℓ,(k)) = ∏ⱼ (1 + γ gℓ,(k)ⱼ (zℓ,(k)ⱼ))。这是核心创新点。其中gℓ,(k)ⱼ是可学习的单变量函数(通常用一个小MLP实现),γ = ̄dk^{-1/2}是用于控制方差的缩放因子。 - 层归一化(LayerNorm):应用于每层LRNN的输出向量
ϕ(k)之后,用于稳定深层网络的训练。 - 输出层:线性映射
Sout将最后一层输出映射到目标维度。
- 线性投影层:
- 数据流与交互:输入
x经过层内线性投影,产生多个低维表示zℓ。每个zℓ的每个维度zⱼ独立通过一个小的单变量网络gⱼ,然后所有维度的输出相乘(∏)并加上偏移1,形成一个激活值。这种乘积操作是LRNN捕捉高阶交互的关键。层内不同神经元(ℓ)的投影和激活函数是独立的。 - 关键设计选择及动机:
(1 + γ gⱼ)结构:1确保初始化时输出为1(零偏移),便于训练;展开后自动包含常数项、加性项和所有高阶乘积项,模拟了函数的ANOVA分解。γ缩放因子用于控制梯度方差,实现类似Xavier初始化的稳定效果(如引理1所示)。- 单变量组件函数可学习:赋予每个神经元极高的灵活性,使其能自适应地学习特定投影方向上的最优非线性变换。
- 乘积而非求和:与MLP中特征的加法组合不同,乘积组合能更高效地表示特征间的交互关系,尤其在频谱分析中能产生丰富的组合频率(如引理2所示)。
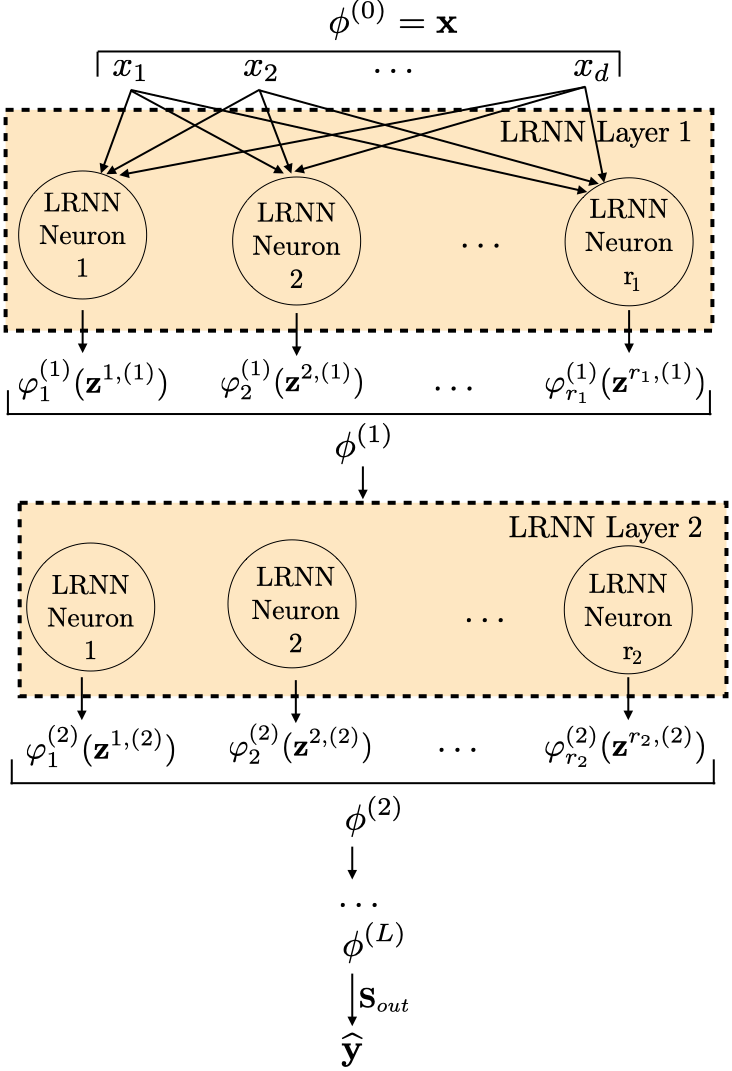 图10展示了深层LRNN的架构。输入
图10展示了深层LRNN的架构。输入 x 经过多个LRNN层的堆叠,每层包含线性投影和基于乘积结构的可学习激活函数,最后通过输出层得到预测。
💡 核心创新点
- 可学习乘积结构激活函数:这是本文最核心的创新。将传统神经网络的固定激活函数(如ReLU)替换为由多个可学习单变量函数乘积构成的函数。它是什么:
φ(z) = ∏(1 + γ gⱼ(zⱼ))。之前局限:固定激活函数缺乏任务适应性;KAN虽可学习但优化不稳定。如何起作用:乘积结构天然建模高阶交互,每个gⱼ可自适应学习。收益:在信号表示等任务上展现出远超固定激活函数的表达能力和参数效率。 - 扎实的理论分析框架:为LRNN提供了坚实的理论基础。是什么:证明了通用逼近定理(定理1),分析了对低秩结构函数能缓解维数灾难(定理2),阐明了LRNN能自适应控制频谱偏差(引理2)。之前局限:许多新架构缺乏理论支撑。如何起作用:将函数逼近理论与深度学习结合,将LRNN的表达能力与低秩分解理论联系起来。收益:增强了方法的可信度,并为理解和设计此类架构提供了理论指导。
- 自适应频谱偏差控制机制:LRNN在配合周期激活函数时表现出独特的优势。是什么:单个LRNN神经元通过乘积操作,能从其
̄d个基频中合成出2^̄d - 1个组合频率(引理2)。之前局限:MLP通过加法叠加频率,需要更多参数。如何起作用:乘积结构在频域对应卷积,天然产生丰富的和差频。收益:能以更少参数更高效地表示包含复杂谐波关系的信号(如音频、高频图像),实验中在音频任务上MSE降低3-11倍。
🔬 细节详述
- 训练数据:
- 图像表示:使用Cameraman(256×256灰度)、Retina(256×256 RGB)、DIV2K数据集(下采样后训练)、Kodak和Parrot高分辨率图像、以及1000张ImageNet图像(256×256)。
- 音频表示:使用四个音频片段:bach(古典音乐)、counting(男性语音)、reggae(雷鬼音乐)、reading(女性语音)。
- PDE求解:使用高频Poisson PDE基准(频率参数n=2和4)。
- CT重建:使用一张256×256的胸部CT图像。
- 损失函数:论文中未明确说明,根据任务推断,图像/音频/PDE任务通常使用均方误差(MSE) 作为损失函数。
- 训练策略:
- 优化器:所有实验统一使用Adam优化器。
- 学习率:LRNN通常为
1e-3,基线模型(SIREN, SPDER)为1e-4(遵循作者推荐)。LRNN在Cameraman实验中使用了StepLR调度器(步长100,衰减因子0.8)。 - Batch Size:未在正文中说明。
- 训练步数:图像任务通常为1000步;大规模ImageNet鲁棒性实验为1000轮(epoch)。
- 关键超参数:
- LRNN特有:分离秩
r(控制模型宽度/表达力,如106),投影宽度̄d(如16),组件函数MLP结构(如单层、1个隐藏神经元)。 - 通用:组件函数内使用的激活类型(如SPDER:
sin(x)√|x|,SIREN:sin(x))。
- LRNN特有:分离秩
- 训练硬件:所有实验在单块NVIDIA 4090 GPU上完成。
- 推理细节:未提及特殊解码策略,为标准前向传播。
- 正则化与稳定技巧:
- 方差控制初始化:缩放因子
γ = ̄d^{-1/2}保证激活和梯度的方差稳定(引理1)。 - 层归一化(LayerNorm):在深层LRNN中,对每层输出应用LayerNorm是保证稳定收敛的关键(附录C.2消融研究显示去除后误差增大两个数量级)。
- 方差控制初始化:缩放因子
📊 实验结果
主要结果对比表格:
| 任务 | 模型 | 指标 | 数值 | 备注 |
|---|---|---|---|---|
| 图像表示 (Cameraman) | LRNN-SPDER | PSNR | 107.94 dB | 显著优于所有基线 |
| SPDER | PSNR | 49.0 dB | ||
| SIREN | PSNR | 35.27 dB | ||
| WIRE | PSNR | 36.04 dB | ||
| ReLU | PSNR | 14.40 dB | ||
| 图像表示 (ImageNet, 40dB目标) | LRNN-SPDER | 成功率 | 100% | 1000张图像,3次随机种子 |
| SPDER | 成功率 | 26.4% | ||
| SIREN | 成功率 | 1.8% | ||
| 音频表示 (bach) | LRNN-SPDER | MSE | 0.10e-4 | 基线MSE降低3-11倍 |
| SPDER | MSE | 1.12e-4 | ||
| SIREN | MSE | 1.21e-4 | ||
| PDE求解 (n=2) | LRNN | MSE | 远低于SIREN | 16k参数LRNN优于132k参数SIREN |
| SIREN | MSE | ~1e-4 (参考线) | 参数132k | |
| KAN1/KAN2 | MSE | 更高 | 参数未知,误差高于LRNN1-2个数量级 | |
| 稀疏CT重建 | LRNN | PSNR / SSIM | 29.13 / 0.7455 | 最佳,且无伪影 |
| WIRE | PSNR / SSIM | 28.83 / 0.6413 | ||
| SIREN | PSNR / SSIM | 27.46 / 0.6877 |
关键消融实验:
- 组件激活函数:在Cameraman图像上,LRNN使用SPDER激活(107.94 dB)远优于使用ReLU(14.40 dB)或Tanh(14.42 dB),证明周期性激活对高频表示至关重要。
- LayerNorm:在bach音频上,使用LayerNorm的LRNN最终MSE为3.58e-5,去除后恶化至2.41e-2,表明其对深层LRNN的稳定性不可或缺。
- 参数共享:比较灵活(Flex)与共享激活(SA)变体,Flex在高保真度任务中表现更优,SA在参数较少时效率略高。
图表结果说明:
图2 (Scaling Laws):展示了在图像表示任务上,LRNN-SPDER(2层)在相同参数量下PSNR持续高于3层/5层的SPDER和MLP模型,体现了优越的参数效率。
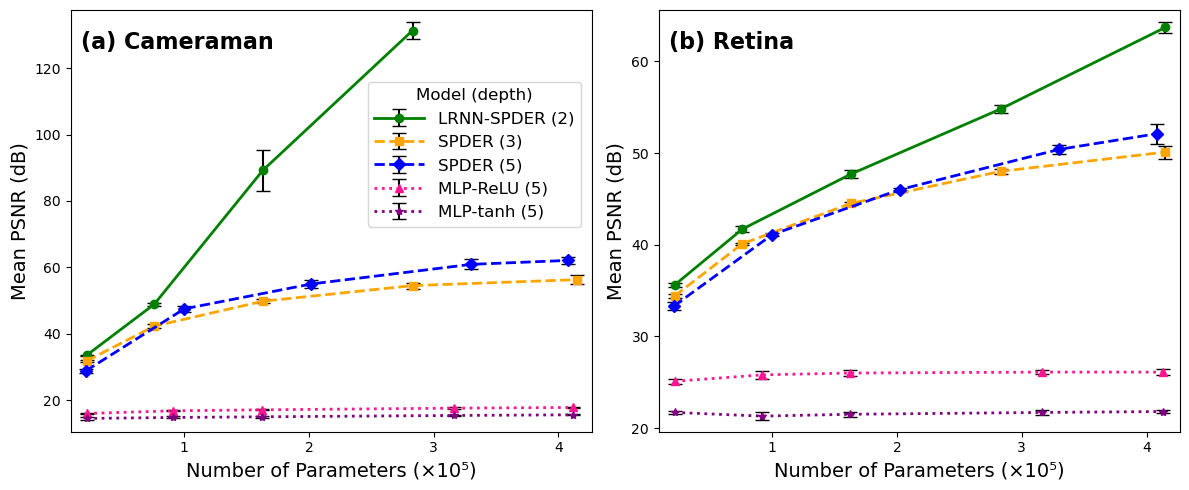 图2:LRNN-SPDER在图像表示任务上的缩放定律。在相同参数量下,LRNN的性能(PSNR)始终优于更深的SPDER和MLP基线。
图2:LRNN-SPDER在图像表示任务上的缩放定律。在相同参数量下,LRNN的性能(PSNR)始终优于更深的SPDER和MLP基线。图4 (ImageNet Robustness):大规模鲁棒性测试显示,LRNN在所有PSNR目标上成功率最高,尤其在40dB的高要求下达到100%,而基线模型几乎失败。
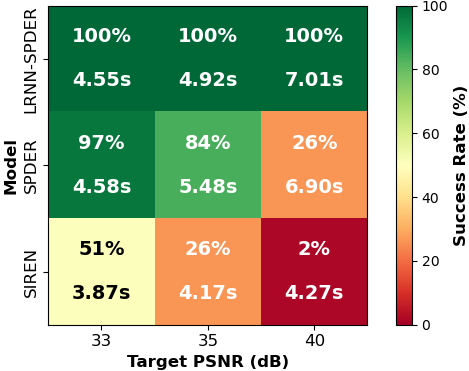 图4:在1000张ImageNet图像上达到不同PSNR目标的成功率。LRNN在所有目标上表现最佳,尤其在40dB时达到100%成功率。
图4:在1000张ImageNet图像上达到不同PSNR目标的成功率。LRNN在所有目标上表现最佳,尤其在40dB时达到100%成功率。图7 (Audio Error):显示LRNN-SPDER在时域和频域的绝对误差均远低于SIREN和SPDER,且收敛更快,频谱保真度更高。
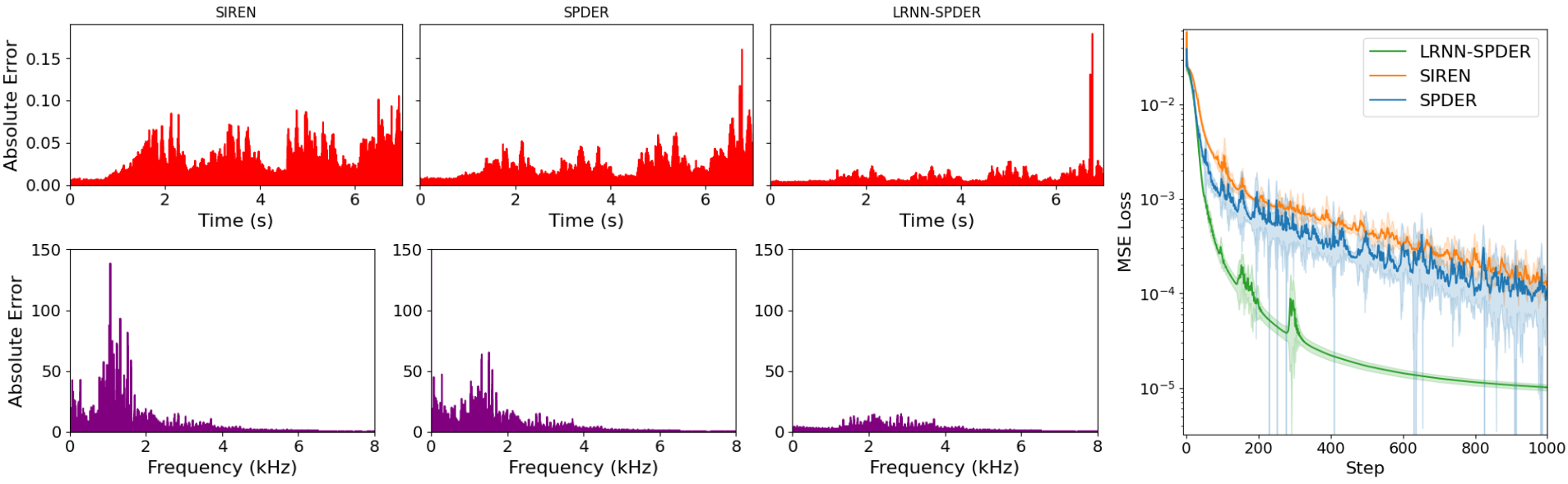 图7:bach音频表示任务的误差分析。LRNN-SPDER在时域和频域的绝对误差均显著低于基线模型。
图7:bach音频表示任务的误差分析。LRNN-SPDER在时域和频域的绝对误差均显著低于基线模型。图8 (PDE Benchmark):在Poisson PDE任务中,LRNN的MSE曲线远低于SIREN和MLP,且在低参数量时就达到了极低误差。
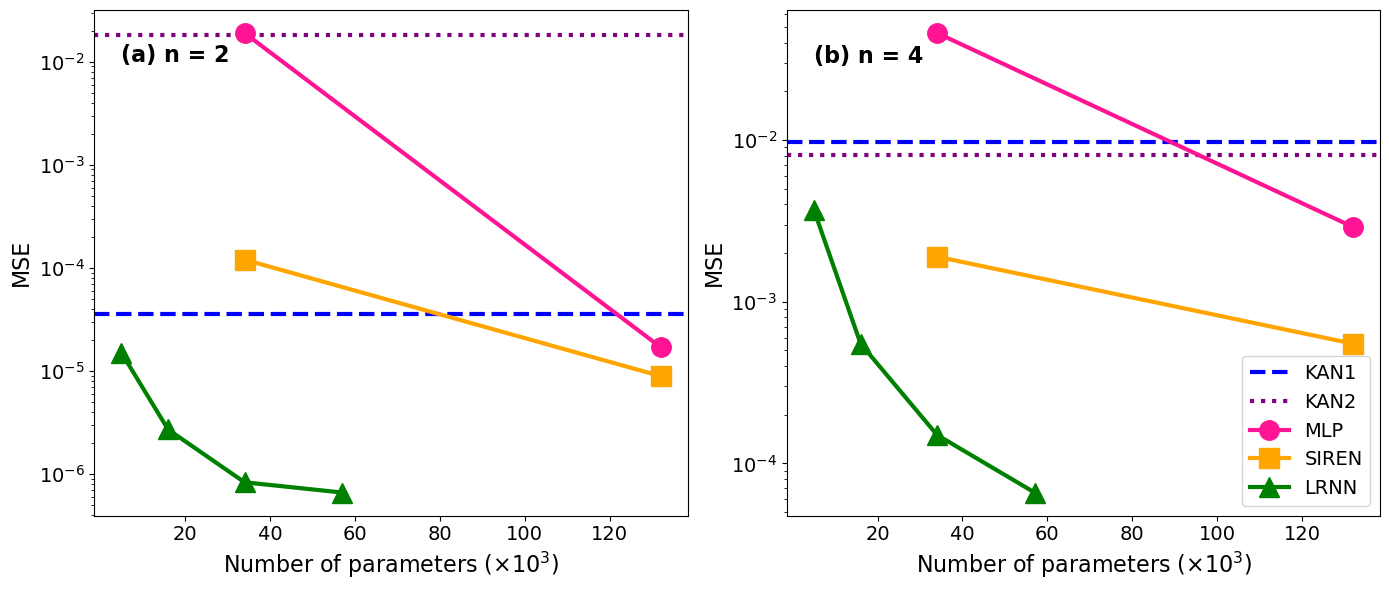 图8:Poisson PDE基准测试结果。LRNN在所有频率下均实现了比SIREN和MLP低几个数量级的误差。
图8:Poisson PDE基准测试结果。LRNN在所有频率下均实现了比SIREN和MLP低几个数量级的误差。
⚖️ 评分理由
- 学术质量:6.5/7:创新性强,提出了从函数分解���论衍生的全新神经网络架构;技术分析严谨,提供了从初始化、通用性到频谱特性的完整理论证明;实验极其充分,横跨四个不同领域,并与多个SOTA方法对比;消融研究清晰地验证了关键设计选择。扣分点在于对架构本身训练开销的分析和优化策略缺乏实验验证。
- 选题价值:1.5/2:研究的是深度学习的基础构建块——神经网络架构,具有很高的前沿性和通用性,潜在影响广泛。然而,论文的核心贡献是通用架构创新,虽然实验包含音频任务,但主要目标是展示架构的通用能力,而非专门解决音频/语音领域的特定问题,因此对音频/语音读者的直接相关性和针对性略弱。
- 开源与复现加成:0.0/1:论文提供了公开的代码仓库链接(
https://github.com/dacelab/lrnn),表明了复现的意愿。但未提及是否提供预训练模型权重、具体数据集的获取方式或完整的训练配置文件。虽然文中提到了关键超参数,但完整的复现材料(如训练脚本、详细配置)是否完备未知,因此给予中等加成(0分)。