📄 CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition
#语音识别 #多语言 #分布鲁棒优化 #基准测试 #开源工具
🔥 8.0/10 | 前25% | #语音识别 | #分布鲁棒优化 | #多语言 #基准测试
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Martijn Bartelds(斯坦福大学计算机科学系),Ananjan Nandi(斯坦福大学计算机科学系) (论文注明两位作者贡献均等)
- 通讯作者:Dan Jurafsky(斯坦福大学计算机科学系)
- 作者列表:
- Martijn Bartelds(斯坦福大学计算机科学系)
- Ananjan Nandi(斯坦福大学计算机科学系)
- Moussa Koulako Bala Doumbouya(斯坦福大学计算机科学系)
- Dan Jurafsky(斯坦福大学计算机科学系)
- Tatsunori Hashimoto(斯坦福大学计算机科学系)
- Karen Livescu(丰田芝加哥理工学院)
💡 毒舌点评
本文精准地诊断了Group DRO在CTC训练中失效的病因——损失值因序列长度和语言特性变得“不可比”,并开出了对症的“药方”(CTC-DRO),在多个语言集上实现了最差语言性能的显著提升,是一次理论动机清晰、工程实现扎实、效果立竿见影的应用创新。然而,CTC-DRO的疗效目前主要验证于6个语言一组的设定,当语言组规模扩大到几十甚至上百时,其权重的平滑机制和“最差语言”的定义是否依然有效,可能需要更严苛的检验;此外,该方法本质上是“优化权衡”,提升最差性能的同时,部分设置下最优语言的性能有轻微波动(尽管统计不显著),这在追求绝对平均或帕累托最优的场景下需谨慎考量。
🔗 开源详情
- 代码:论文提供了公开的代码仓库链接:https://github.com/Bartelds/ctc-dro。
- 模型权重:论文提到“newly trained models are publicly available”,并指向了上述GitHub仓库。
- 数据集:实验使用公开基准ML-SUPERB 2.0,论文详细描述了如何从原始数据中构建实验语言集(附录D),数据本身需从原始来源获取。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了极详细的复现信息,包括:
- 算法伪代码(Algorithm 1)。
- 详尽的实验设置:模型架构(XLS-R, MMS)、训练超参数(学习率、batch duration、梯度累积、epoch数、ηq、α)、评估指标。
- 数据集划分的具体语言列表(表4)和统计信息(表5, 表6)。
- 附录中包含更多开发集结果、消融实验细节、训练时间分析等。
- 论文中引用的开源项目:论文基于XLS-R和MMS预训练模型,使用ML-SUPERB 2.0基准,并提及了ESPnet工具包(用于讨论,非核心依赖)。
📌 核心摘要
- 问题:现代深度学习模型常在特定子群体上表现不佳。在多语言自动语音识别(ASR)中,不同语言的性能差异显著。分布鲁棒优化(Group DRO)旨在最小化最差组损失,但在ASR中因广泛使用的CTC损失受输入长度及语言声学特性影响,导致各组损失不可比,使Group DRO失效甚至恶化性能。
- 方法:提出CTC-DRO算法。核心改进有二:一是采用“长度匹配批处理”,确保每个语言组的损失是在大致相同的音频总时长下计算,缓解CTC损失随长度缩放的问题;二是引入“平滑最大化目标”,通过修改组权重更新规则,防止权重过度集中于损失持续偏高的组,从而使权重分布更均衡稳定。
- 创新:与直接应用Group DRO相比,CTC-DRO首次系统性地解决了CTC损失在多语言场景下的不可比性问题。其平滑更新目标可通过拉格朗日乘数法证明,仍能保证权重与损失成正比,但调整更平滑。
- 实验结果:在ML-SUPERB 2.0基准的五个语言集上进行评估。CTC-DRO在平衡与不平衡数据设置下均优于基线模型和标准Group DRO。关键结果如下:
- 最差语言字符错误率(CER)相对基线最高降低47.1%。
- 平均CER相对基线最高降低32.9%。
- 标准Group DRO在超过一半的设置中反而提升了最差语言CER和平均CER。
关键结果表格(平衡数据设置):
设置 模型 ηq α 最差语言CER (↓) 平均CER (↓) 1 MMS 基线 - - 60.8% 23.4% 1 MMS Group DRO 10⁻⁴ - 86.6% 30.5% 1 MMS CTC-DRO 10⁻⁴ 1.0 56.8% 22.9% 2 XLS-R 基线 - - 68.8% 19.0% 2 XLS-R Group DRO 10⁻⁴ - 58.8% 21.6% 2 XLS-R CTC-DRO 10⁻⁴ 0.5 45.0% 15.8% 消融实验显示,移除平滑目标或长度匹配批处理都会导致性能大幅下降。
- 意义:CTC-DRO以极小的计算开销,有效提升了多语言ASR的公平性,对促进数字包容性有积极作用。其思想可推广至其他损失不可比的群组鲁棒优化场景(如医疗AI)。
- 局限:性能差距虽被缩小但未完全消除;算法性能依赖于预定义的语言组划分;在极端不平衡数据下效果需进一步验证。
🏗️ 模型架构
论文提出的CTC-DRO并非一个新的神经网络模型架构,而是一种用于优化现有基于CTC的ASR模型的训练算法。其核心是修改了Group DRO的优化流程。
整体流程与组件: CTC-DRO算法(Algorithm 1)在标准的CTC微调流程(使用如XLS-R/MMS等预训练编码器+Transformer层+CTC解码头)基础上,插入了两个关键修改:
长度匹配批处理器:
- 功能:创建训练批次时,确保同一批次内的所有样本来自同一个随机选定的语言组,并且该批次中所有音频样本的总时长接近一个预设的固定值(约50秒)。
- 如何工作:迭代地添加同一语言组的语音样本到批次中,直到总时长达到或略微超过目标值。
- 动机:CTC损失值随输入序列长度增加而增大。固定批次总时长可以使得不同语言组在相似的数据量(时间)上计算损失,从而使组间损失更具可比性。
平滑最大化目标(组权重更新器):
- 功能:替代标准Group DRO中的Hedge算法权重更新规则,用于计算每个语言组的训练权重
qg。 - 内部结构(公式10):
qg ← qg · exp(ηq Lg / (qg + α)) / Σ_g'(qg' · exp(ηq Lg' / (qg' + α)))。 - 关键参数:引入平滑超参数
α。当α → 0时,更新更倾向于使权重均匀;当α → ∞时,退化为原始Group DRO更新。 - 数据流:算法在处理完一批来自每个组的数据后,计算该组损失的滑动平均值
Lg,然后使用上述规则更新组权重qg。更新后的权重用于计算下一个批次训练的加权损失。
- 功能:替代标准Group DRO中的Hedge算法权重更新规则,用于计算每个语言组的训练权重
数据流:
输入语音 (x, y) → 预训练编码器(如XLS-R) → Transformer层 → CTC输出头 → 计算CTC损失 ℓi。在训练循环中,长度匹配批处理器确保每批数据来自同一组且时长相近。所有组的损失被收集、平均后,用于平滑最大化目标更新组权重 qg。模型参数通过基于这些组加权损失的梯度进行更新。
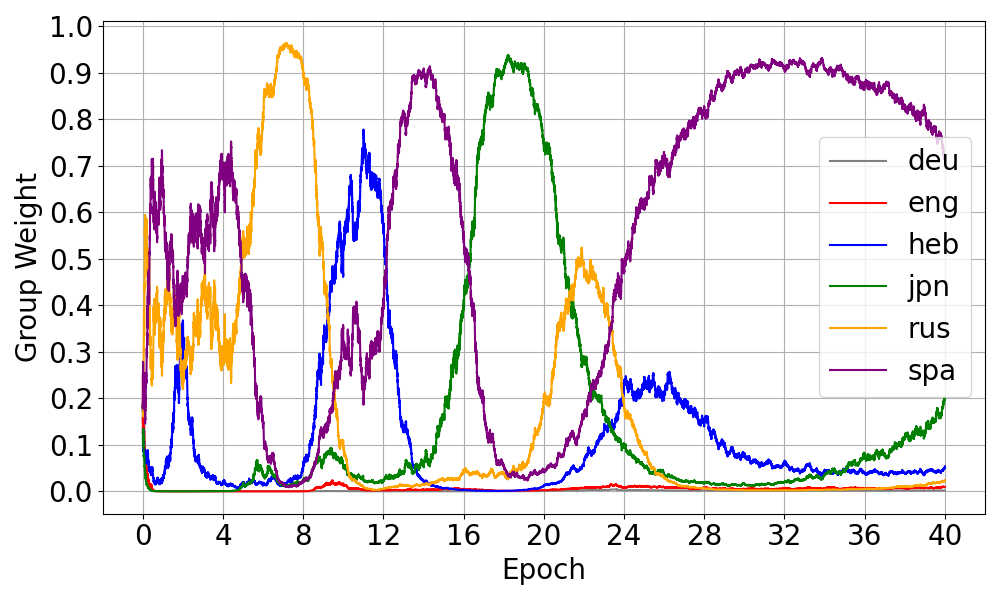 图2直观展示了平滑目标的作用。训练过程中,标准Group DRO的权重剧烈波动,常出现某个语言权重接近1,其他接近0的情况;而CTC-DRO的权重分布则平滑、稳定得多,能持续关注所有语言(包括表现最差的)。
图2直观展示了平滑目标的作用。训练过程中,标准Group DRO的权重剧烈波动,常出现某个语言权重接近1,其他接近0的情况;而CTC-DRO的权重分布则平滑、稳定得多,能持续关注所有语言(包括表现最差的)。
💡 核心创新点
- 针对CTC损失的长度匹配批处理策略:认识到CTC损失值随音频长度固有增长,导致不同长度分布的语言组损失不可比。通过构造总音频时长相近的批次,从数据层面缓解了这一问题,是使Group DRO在CTC框架下有效工作的先决条件。
- 平滑的组权重最大化目标:从理论上分析了标准Group DRO权重更新(
exp(ηq * Lg))在损失持续偏高组上过度累积权重的缺陷。提出了一个新的最大化目标Σ_g log(qg + α) Lg,其对应的更新规则(公式10)在保证权重与损失正相关的前提下,使更新量与当前权重成反比,从而防止任何组权重的过度膨胀,实现了更稳定、均衡的组间关注。 - 理论与实验的紧密闭环:不仅提出了方法,还通过拉格朗日乘数法从理论上证明了新目标下最优权重
qg仍与损失Lg正相关(公式17)。同时,通过在标准基准(ML-SUPERB 2.0)上的消融实验(表3)和权重轨迹分析(图2),充分验证了每个组件的有效性。
🔬 细节详述
- 训练数据:
- 数据集:ML-SUPERB 2.0。覆盖141种语言,来自15个语料库,包含多样的域、说话风格和录音环境。
- 实验设置:随机选取5个语言集,每个集包含6种语言-语料库对。每个语言的平衡训练数据为1小时,开发集和测试集各10分钟。前两个语言集还评估了使用更多可用训练数据的不平衡设置。
- 损失函数:
- 基础损失:CTC损失(公式6),用于预测字符序列和语言ID的联合任务。
- 优化目标:CTC-DRO最小化组加权CTC损失的加权和:
min_θ Σ_g qg * Lg,其中qg由平滑最大化目标动态调整。Lg是在长度匹配批次上计算的、该组所有样本损失之和的平均值。
- 训练策略:
- 优化器:未明确提及,但沿用基准模型设置。
- 学习率:基准模型的学习率在开发集上调优,CTC-DRO和Group DRO模型使用相同的学习率(10⁻⁴)。
- Batch Size:采用基于音频时长的批大小,约50秒音频/批(具体值因GPU内存而异,见表13)。
- 梯度累积:跨16个批次累积梯度。
- 训练轮数:40个epoch,保留开发集损失最低的检查点。
- 关键超参数:
- DRO相关:
ηq(组权重学习率)∈ {10⁻³, 10⁻⁴},α(平滑参数)∈ {0.1, 0.5, 1}。在开发集上网格搜索选择最佳组合。 - 批时长目标:约50秒(具体值见表13)。
- DRO相关:
- 训练硬件:单卡 NVIDIA RTX A6000 GPU。
- 推理细节:未详细说明解码策略,应与基线模型一致(CTC beam search)。
- 正则化:无额外正则化技巧提及。
📊 实验结果
- 主要Benchmark与指标:ML-SUPERB 2.0基准,主要指标为字符错误率(CER,↓越低越好),次要指标为语言识别准确率(LID,↑越高越好)。报告最差语言CER(主要优化目标)和平均CER。
- 与基线/SOTA对比:
- 主要结果:CTC-DRO在所有5个语言集上,均优于基线(标准CTC微调)和标准Group DRO。在平衡数据设置下(表1),CTC-DRO将最差语言CER降低了最高47.1%(设置2,XLS-R),平均CER降低了最高32.9%(设置5,XLS-R)。标准Group DRO则经常产生负面影响(最差语言CER平均上升,平均CER全部上升)。
- 不平衡数据结果:趋势一致。在设置2(XLS-R)中,最差语言CER相对基线降低47.1%。
关键结果表格(平衡数据设置,续):
设置 模型 ηq α 最差语言CER (↓) 平均CER (↓) LID (↑) 5 MMS 基线 - - 90.0% 26.0% 96.3% 5 MMS Group DRO 10⁻⁴ - 62.2% 29.2% 67.0% 5 MMS CTC-DRO 10⁻³ 1.0 57.5% 24.3% 90.5% 5 XLS-R 基线 - - 114.8% 29.9% 89.0% 5 XLS-R Group DRO 10⁻⁴ - 92.9% 36.8% 57.7% 5 XLS-R CTC-DRO 10⁻⁴ 0.1 71.5% 23.8% 91.0%
- 消融实验:
- 表3的消融实验清晰表明,移除长度匹配批处理(
-Dur)或平滑目标(-Smooth)都会导致性能显著下降。移除平滑目标的影响尤其严重(平均CER恶化超过300%),证明了其关键性。
- 表3的消融实验清晰表明,移除长度匹配批处理(
- 细分结果与分析:
- 权重稳定性分析:图2(以及附录中的图3、图4)显示,Group DRO的组权重训练过程极不稳定,而CTC-DRO权重分布平滑、稳定,最差语言(如日语)的权重能持续保持较高水平。
- 对最优语言影响:分析表明,CTC-DRO并未显著降低表现最好语言的性能(平衡数据下,基线最优语言平均CER为3.0%,CTC-DRO为3.7%,t检验p=0.19无显著差异)。
- 扩展性:附录H的18语言实验表明,CTC-DRO在更多语言组上依然有效(最差语言CER降低最高23.7%)。
- 相关图表:
 图3显示MMS模型上,CTC-DRO同样实现了权重的稳定分布,与图2的XLS-R模型结论一致。
图3显示MMS模型上,CTC-DRO同样实现了权重的稳定分布,与图2的XLS-R模型结论一致。
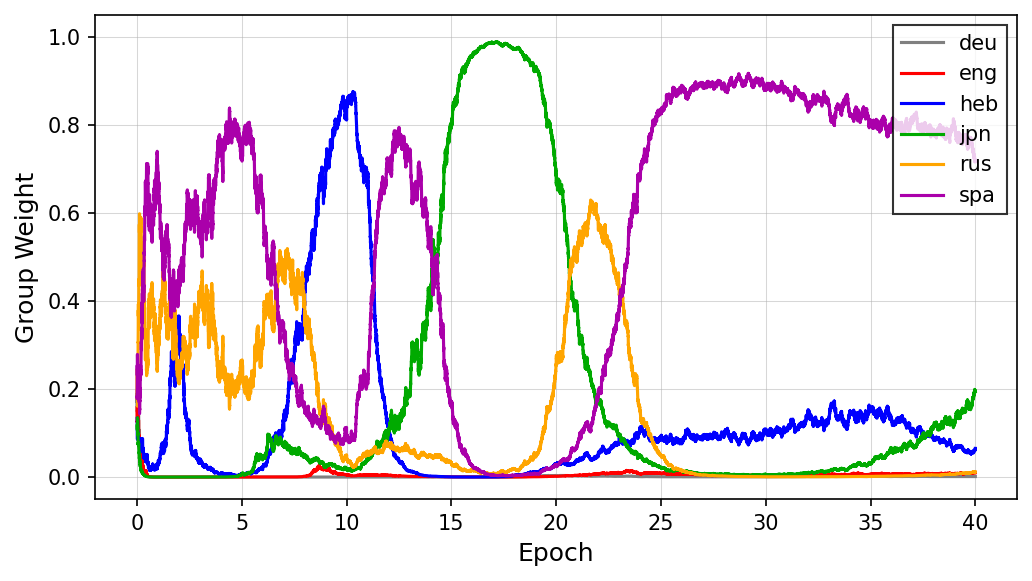 图4进一步证实CTC-DRO的稳定性在不同语言集上具有泛化能力。
图4进一步证实CTC-DRO的稳定性在不同语言集上具有泛化能力。
⚖️ 评分理由
- 学术质量(6.0/7):创新性(2/2):提出了针对性强且��颖的改进点(长度匹配、平滑目标),有效解决了具体场景下的实际问题。技术正确性(1.5/2):算法设计合理,理论推导正确,实验设计严谨。实验充分性(1.5/2):在标准基准上进行了全面实验,包含消融、多组对比、扩展性验证和错误分析。证据可信度(1/1):结果数字明确,对比清晰,消融实验和可视化有力支持了结论。
- 选题价值(1.5/2):前沿性(0.5/0.5):关注AI公平性这一重要前沿方向,特别是在多语言语音技术领域。潜在影响(0.5/0.5):对促进技术普惠、服务小语种社区有积极意义。实际应用空间(0.5/1):CTC-DRO计算开销小,易于集成到现有训练流程,实用性强。读者相关性(0/0):对语音识别领域的研究者和工程师有直接参考价值。
- 开源与复现加成(0.5/1):论文提供了完整的代码仓库、预训练模型链接、详细的算法描述和超参数设置,复现门槛低,属于高质量的开源工作。