📄 Continuous Audio Language Models
#音频生成 #音乐生成 #自回归模型 #流匹配 #语音合成
🔥 9.5/10 | 前10% | #音频生成 #音乐生成 | #自回归模型 #流匹配 | #音频生成 #音乐生成
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Simon Rouard(Kyutai;IRCAM-CNRS Sorbonne Univ.)
- 通讯作者:未说明(论文未明确指定,通常对应邮箱作者为Simon Rouard和Alexandre Défossez)
- 作者列表:Simon Rouard(Kyutai;IRCAM-CNRS Sorbonne Univ.),Manu Orsini(Kyutai),Axel Roebel(IRCAM-CNRS Sorbonne Univ.),Neil Zeghidour(Kyutai),Alexandre Défossez(Kyutai)
💡 毒舌点评
这篇论文的亮点在于其系统性思维,它没有孤立地提出一个新模块,而是为“连续音频生成”这个目标设计了一整套涵盖编码、建模、采样和蒸馏的完整流水线(CALM),并通过“Pocket TTS”将学术想法落到了实处。然而,其短板在于音乐生成的实验数据集规模(400K歌曲)相比工业级模型仍显局促,这或许限制了其在最复杂音乐场景下潜力的完全展现,且论文未公开其训练数据集。
🔗 开源详情
- 代码:论文中提及了代码仓库链接:github.com/kyutai-labs/pocket-tts (用于Pocket TTS)。主论文代码链接在摘要中提及为:iclr-continuous-audio-language-models.github.io。
- 模型权重:明确提供了开源的“Pocket TTS”模型权重(100M参数),可在上述GitHub仓库获取。对于论文中的大型实验模型(如1.35B音乐模型),未提及是否开源。
- 数据集:论文详述了训练所用的数据集名称(如Emilia, LAION-Disco-12M等)和规模,但未提供统一的下载链接,部分数据集可能是公共的,部分可能为内部或受限数据集。
- Demo:摘要中提到了示例音频网站 iclr-continuous-audio-language-models.github.io。
- 复现材料:提供了极其详尽的附录,包括:表14(VAE超参数)、表15(模型与训练超参数)、各任务的具体数据处理细节(附录D、F、G)、消融实验(表6, 表10)、补充实验(表7, 表8, 表9, 表11, 表12, 表13)、以及人类评估方法详细说明(附录H)。
- 论文中引用的开源项目:论文主要基于并引用了以下开源项目/模型:Mimi (Défossez et al., 2024b), WavLM (Chen et al., 2021b), Helium-1 (Kyutai, 2025), Mistral 7B (Jiang et al., 2023), CLAP (Elizalde et al., 2023), SentencePiece (Kudo & Richardson, 2018), fairseq (Ott et al., 2019), Whisper (Radford et al., 2022)。
📌 核心摘要
- 要解决什么问题:现有音频语言模型(ALM)依赖有损的离散音频令牌(如RVQ),导致生成高质量音频必须生成更多令牌,从而在保真度和计算成本之间存在根本矛盾。
- 方法核心是什么:提出连续音频语言模型(CALM),在VAE的连续潜空间中进行自回归建模。核心是一个大型因果Transformer(长上下文)处理带噪声的历史潜变量,一个轻量Transformer(短上下文)处理干净的近期潜变量,两者结合后条件化一个小型一致性模型(MLP),以单步生成下一个干净的连续潜变量。
- 与已有方法相比新在哪里:完全避免了有损量化,用一致性模型替代了离散模型的RQ-Transformer头或扩散模型的多步采样头,实现了质量与效率的同步提升。创新性地提出了“噪声长上下文+干净短上下文”的双Transformer设计、潜在分类器引导(Latent CFG)和潜在蒸馏(Latent Distillation)等技术。
- 主要实验结果如何:在语音延续、文本到语音(TTS)和音乐延续任务上全面超越了最先进的离散模型基线。
- TTS任务(表3):CALM模型WER为1.81,优于F5-TTS的2.42和DSM的1.95,声学质量MUSHRA得分61.1。
- 音乐延续任务(表4):CALM一致性模型(4步)的FAD(0.71)优于32-RVQ RQ-Transformer基线(1.06),整体推理速度提升1.9倍,采样头速度提升5.4倍。
- 语音延续任务(表2):CALM在声学质量和有意义性上均超越8-RVQ RQ-Transformer。
- 消融研究(表6):证明短上下文Transformer和噪声增强是模型高性能的关键。
- 实际意义是什么:使得在轻量级设备(如笔记本电脑CPU)上运行高质量的实时音频生成成为可能。开源的“Pocket TTS”(100M参数)模型实现了这一目标,具有极高的实际应用价值。
- 主要局限性是什么:论文中音乐生成的训练数据集规模(约20K小时)相对有限;连续表示可能在某些细粒度控制上(如精确的音高、时长编辑)面临挑战;论文未提供其主训练数据集的下载链接。
🏗️ 模型架构
CALM的整体架构(图1)是一个端到端的连续自回归生成系统,由VAE编码器、双Transformer骨干和一致性模型头组成。
完整输入输出流程:
- 编码:输入音频波形通过一个基于Mimi的因果VAE编码器,被压缩为一个连续潜变量序列
x1, ..., xS。 - 上下文建模:在时间步
s,模型的输入是历史潜变量序列。该序列经过两种处理: 长上下文:整个历史x1, ..., xs-1在训练时被注入噪声(~xs = √ks ϵs + √(1-ks) * xs),然后输入到一个大型因果Transformer(Tlong,θ1),输出长上下文嵌入zs_long。噪声注入迫使模型关注粗粒度结构,防止推理时的误差累积。- 短上下文:最近
K个干净的潜变量xs-K, ..., xs-1输入到一个轻量因果Transformer(Tshort,θ2),输出短上下文嵌入zs_short,提供局部精细信息。
- 短上下文:最近
- 预测与生成:长、短上下文嵌入相加得到条件嵌入
Zs = zs_long + zs_short。然后,一个小型MLP一致性模型头fϕ接收来自标准高斯分布的噪声xs_1 = ϵ,时间步t=1,以及条件Zs,单步预测出下一个干净潜变量~xs。 - 解码:生成的连续潜变量序列送入VAE解码器,重建出最终的音频波形。
主要组件与交互:
- VAE-GAN:采用Mimi架构,但用连续高斯潜变量替代RVQ码本,使用重建损失、对抗损失、KL散度损失(及语音的WavLM蒸馏损失)训练。其目标是提供高质量的连续音频表示。
- 双Transformer骨干:这是模型的核心创新。
Tlong,θ1参数量大(如音乐模型1.35B),负责建模长期依赖,但通过噪声注入牺牲了部分细节保真度。Tshort,θ2参数量小(如音乐模型113M),窗口固定(K=10),负责补充Tlong因噪声而可能丢失的局部细节。两者互补。 - 一致性模型头:一个小型MLP(如音乐模型601M参数),其训练目标是让网络直接从任意噪声点一步映射到数据流概率流ODE(PF-ODE)的起点(干净数据)。这替代了多步扩散采样,实现了极快的单步生成。其参数化确保
fϕ(x, t=0) = x(边界条件)。
关键设计选择:噪声注入长上下文是为了鲁棒性;短上下文是为了质量;一致性模型头是为了速度。三者缺一不可,消融实验(表6)证实了这一点。

💡 核心创新点
- 提出CALM连续自回归框架:首次系统性地提出在VAE连续潜空间中进行音频自回归建模,并证明其可在质量和效率上同时超越基于离散令牌的SOTA方法。这从根源上解决了有损量化带来的质量-效率瓶颈。
- 双Transformer设计(噪声长上下文+干净短上下文):针对连续建模中的误差累积问题,创新性地结合了两种上下文表示。噪声长上下文确保了长期稳定性,干净短上下文保留了生成细节,共同解决了纯MAR框架在音频生成中质量不佳的问题。
- 将一致性模型引入音频生成采样头:用一致性模型(或LSD)替代扩散模型作为MLP头,将采样步数从数百步减少到1步(或4步),在保持甚至提升质量的前提下,将采样头速度提升了12-20倍。
- 潜在空间引导与蒸馏技术(Latent CFG & Distillation):将CFG应用于潜变量
Zs而非输出,适用于单步生成。并进一步提出潜在蒸馏,将教师模型(带CFG)的知识蒸馏到学生骨干中,使得推理时无需额外计算CFG,直接将批大小减半,或用于将大模型蒸馏为小模型(如Pocket TTS)。
🔬 细节详述
- 训练数据:
- 语音(延续与TTS):混合了AMI, EARNINGS22, GIGASpeech, SPGISpeech, TED-LIUM, VoxPopuli, LibriHeavy, Emilia等数据集,总规模约88K小时。
- 音乐(延续):从LAION-Disco-12M中随机选取了400K首歌曲(约20K小时,32kHz单声道)。
- 损失函数:
- 主损失(公式3):基于TrigFlow(Lu & Song, 2025)的连续一致性模型损失,用于训练一致性头MLP和自适应权重函数
wψ。 - LSD损失(附录A):一种替代的1步流匹配方法,实验显示在300M规模TTS任务上优于标准一致性损失(表10)。
- VAE损失(公式2):包括时间/频域重建损失、对抗损失、特征匹配损失、KL正则化损失,以及用于语音VAE的WavLM蒸馏损失。
- 主损失(公式3):基于TrigFlow(Lu & Song, 2025)的连续一致性模型损失,用于训练一致性头MLP和自适应权重函数
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.95)。
- 学习率调度:余弦调度(Cosine Schedule)。
- Head Batch Multiplier:训练时,对每个序列计算一次
zs_long,然后复用N次(N=8)计算不同噪声水平下的损失,加速训练。 - 噪声增强:训练时,对送入
Tlong的序列进行随机加噪,噪声系数ks~U(0,1),并使用方差保持缩放。
- 关键超参数:参见表14和表15。例如音乐模型骨干为1.35B参数,48层,维度1536;一致性头601M参数,12层,MLP维度3072。
- 训练硬件:音乐模型使用16块H100 GPU训练500K步;语音延续使用48块H100训练150K步;TTS使用8块H100训练400K步。
- 推理细节:
- 采样步数:一致性模型默认支持1步生成。报告中常用4步以获得更优质量(如音乐任务)。
- 温度采样(高斯温度):对初始噪声
ϵ的方差进行缩放,乘以√τ。语音延续中τ=0.8效果好(表2)。 - 潜在CFG:推理时,对于条件任务(如TTS),计算
Zs_CFG = Zs_∅ + α(Zs_C - Zs_∅),其中α为引导强度(如TTS中α=1.5)。
- 正则化与稳定技巧:训练时注入噪声是关键的稳定性技巧;潜在蒸馏是提升推理效率和部署灵活性的重要技巧。
📊 实验结果
表1:语音压缩模型比较(语音VAE vs VQ-VAE)
| 模型类型 | 尺寸/RVQ | 帧率 (Hz) | 比特率 (kbit/s) | MOSNET (↑) | ABX (↓) | PESQ (↑) | STOI (↑) | 声学质量 (↑) |
|---|---|---|---|---|---|---|---|---|
| VQ-VAE (Mimi) | 8 RVQ | 12.5 | 1.1 | 3.11 | 9.4% | 2.13 | 0.87 | 57.7 ± 1.3 |
| VAE | 32 DIMS | 12.5 | – | 3.15 | 8.1% | 2.42 | 0.90 | 66.0 ± 1.4 |
| 结论:32维VAE在声学质量上与8-RVQ的Mimi相当,并在语义区分度(ABX)、PESQ和STOI上显著优于后者。 |
表2:语音延续模型比较
| 模型类型 | 采样温度 | 总体加速 (↑) | 采样头加速 (↑) | 采样头耗时占比 (↓) | PPX (↓) | VERT (↓) | 声学质量 (↑) | 有意义性 Elo (↑) |
|---|---|---|---|---|---|---|---|---|
| RQ-transformer 8 RVQ | 1.0 | ×1.0 | ×1.0 | 26.7% | 52.4 | 36.3 | 2.42 ± 0.12 | 1841 ± 25 |
| RQ-transformer 8 RVQ | 0.8 | ×1.0 | ×1.0 | 26.7% | 26.8 | 33.1 | 2.75 ± 0.14 | 1870 ± 30 |
| CALM - 一致性 - 1步 | 1.0 | ×1.3 | ×12.3 | 2.9% | 42.9 | 34.3 | 2.82 ± 0.13 | 1947 ± 28 |
| CALM - 一致性 - 1步 | 0.8 | ×1.3 | ×1.2 | 2.9% | 23.8 | 31.2 | 3.45 ± 0.14 | 2023 ± 27 |
| 结论:CALM在各项指标上全面超越基线,采样头速度提升12.3倍,使用温度τ=0.8后,声学质量和有意义性显著提升,超越参考录音。 |
表3:文本到语音模型比较
| 模型 | 参数量 | WER (↓) | CER (↓) | SIM (↑) | 声学质量 (↑) | 说话人相似度 (人类Elo↑) |
|---|---|---|---|---|---|---|
| REFERENCE | – | 2.23 | – | 0.69 | 61.8 ± 2.4 | 1953 ± 24 |
| F5 TTS (NFE=32) | 336M | 2.42 | – | 0.66 | 54.7 ± 2.8 | 2032 ± 18 |
| DSM (16 RVQ, CFG=3) | 750M | 1.95 | – | 0.67 | 60.2 ± 2.4 | 2112 ± 20 |
| CALM w/ LSD (NFE=1, CFG=1.5) | 313M | 1.81 | 0.57 | 0.52 | 61.1 ± 2.3 | 1966 ± 23 |
| 结论:CALM在WER和CER上取得最佳结果,声学质量与最强基线相当。说话人相似度的自动指标较低,但人类评估显示其表现良好。 |
表4:音乐延续模型比较(30秒生成)
| 模型 | 总体加速 (↑) | 采样头加速 (↑) | 采样头耗时占比 (↓) | FAD (↓) | 声学质量 (↑) | 愉悦度 Elo (↑) |
|---|---|---|---|---|---|---|
| RQ-TRANSFORMER 32 RVQ | × 1.0 | × 1.0 | 57.7% | 1.06 ± 0.06 | 2.85 ± 0.07 | 1824 ± 29 |
| CALM - 一致性 - 1步 | × 2.2 | × 19.3 | 6.6% | 0.83 ± 0.04 | 2.90 ± 0.07 | 1857 ± 28 |
| CALM - 一致性 - 4步 | × 1.9 | × 5.4 | 20.1% | 0.71 ± 0.05 | 3.07 ± 0.07 | 1847 ± 24 |
| CALM - TrigFlow - 100步 | × 0.3 | × 0.2 | 86.6% | 0.64 ± 0.04 | 3.12 ± 0.07 | 1921 ± 29 |
| 结论:CALM一致性模型(1步或4步)在FAD指标和人类评价上均优于离散基线,同时推理速度大幅提升。TrigFlow质量最佳但速度极慢。 |
表6:音乐CALM消融研究
| 模型变体 | FAD (↓) |
|---|---|
| 基础 (CALM - 一致性 - 4步) | 0.93 ± 0.06 |
| w/o Head Batch Multiplier | 1.32 ± 0.09 |
| w/o Noise Augmentation | 1.63 ± 0.11 |
| w/o Short-Context Transformer | 4.03 ± 0.16 |
| w/o Any of the above (≈ MAR) | 8.38 ± 0.17 |
| 结论:短上下文Transformer和噪声增强是性能最关键的组件,移除后FAD显著恶化。 |
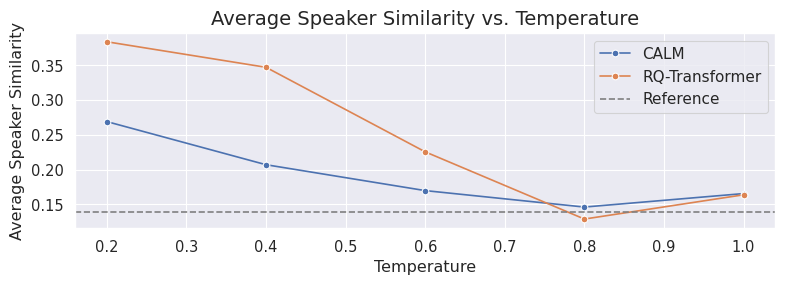 图2结论:随着温度升高,生成语音的说话人成对相似度降低,表明多样性增加,这与离散模型的温度效应趋势一致。
图2结论:随着温度升高,生成语音的说话人成对相似度降低,表明多样性增加,这与离散模型的温度效应趋势一致。
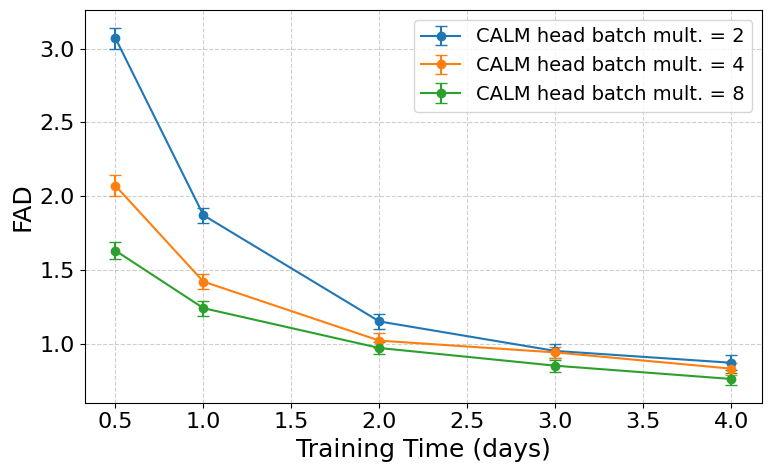 图3结论:使用更大的头批乘数值(如8或16)能显著加速FAD指标的收敛,验证了该技巧的有效性。
图3结论:使用更大的头批乘数值(如8或16)能显著加速FAD指标的收敛,验证了该技巧的有效性。
⚖️ 评分理由
- 学术质量:6.5/7:论文贡献是系统性的,提出了完整的CALM框架和多项配套技术创新(双上下文、一致性头、潜在CFG/蒸馏),逻辑严密。实验设计全面,在多个重要任务和基线上进行了比较,并包含了详尽的消融研究,有力地支撑了每个设计选择。技术细节描述清晰,公式明确。
- 选题价值:1.8/2:研究连续自回归音频生成是解决当前领域瓶颈(离散化的有损性)的根本路径,具有很高的前沿性和理论价值。通过“Pocket TTS”的实现,证明了该方向在边缘计算和实时应用上的巨大潜力,对工业界和学术界均有重要影响。
- 开源与复现加成:+1.0/1:论文提供了完整的代码仓库(GitHub)、开源的轻量级模型(Pocket TTS)、详尽的超参数表(表14,表15)和训练配置,复现路径非常清晰,极大地降低了后续研究的门槛。