📄 Confident and Adaptive Generative Speech Recognition via Risk Control
#语音识别 #风险控制 #大语言模型 #自适应
🔥 8.0/10 | 前50% | #语音识别 | #风险控制 | #大语言模型 #自适应
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Amit Damri (amitdamti@mail.tau.ac.il)
- 通讯作者:Bracha Laufer-Goldshtein (blaufer@tauex.tau.ac.il)
- 作者列表:Amit Damri(特拉维夫大学电气与计算机工程学院)、Bracha Laufer-Goldshtein(特拉维夫大学电气与计算机工程学院)
💡 毒舌点评
亮点:这篇论文巧妙地将“学习-然后-测试”这一理论严谨的风险控制框架嫁接到语音识别后处理中,为“应该给LLM看几个假设”这个工程问题提供了有理论保证的解决方案,并在实验中实现了显著的计算节省(最高达52%)。短板:方法的理论根基扎实,但核心创新更偏向于一项应用良好的工程整合,对于追求全新模型架构或根本性算法突破的读者来说,可能会觉得“不过如此”;此外,框架的有效性高度依赖于ASR置信度分数的质量,论文对此讨论略显不足。
🔗 开源详情
- 代码:提供代码仓库链接:
https://github.com/amitdamritau/adaptive-ger - 模型权重:论文中未提及是否公开微调后的LLM权重。
- 数据集:实验使用了公开的基准数据集(TedLium-3, CHiME-4, CommonVoice, FLEURS),但论文中未说明是否提供经过处理的数据或专门的下载脚本。
- Demo:未提供在线演示。
- 复现材料:提供了非常详细的训练配置(超参数、优化器、学习率调度、硬件、训练时长)、风险校准流程细节(算法1)以及大量消融研究的设置和结果,复现材料充分。
- 论文中引用的开源项目:
- Whisper(用于ASR)
- LLaMA-2(作为LLM基础)
- PEFT/LoRA(用于参数高效微调)
- Hugging Face Transformers相关库(推断,用于模型实现)
- evaluate2库(用于语料级WER计算)
- HyPoradise、RobustGER等基准框架(用于数据和实验设置)
📌 核心摘要
这篇论文针对基于大语言模型的语音识别生成式错误纠正(GER)方法中,固定使用N-best假设集导致的计算资源浪费和性能不保证的问题,提出了一个自适应框架。该框架利用ASR模型的置信度分数,通过设定阈值动态决定每个输入音频所需的最优假设数量,并采用“学习-然后-测试”(LTT)风险控制方法来校准该阈值,从而以高概率保证纠正后的词错率(WER)相对于该模型在该假设集上的最佳可能性能的退化不超过预设水平。与已有固定大小的方法相比,本文的创新在于首次将风险控制理论引入GER任务,实现了难度感知的资源分配和理论性能保证。在三个不同难度的基准数据集(TedLium-3, CHiME-4, CommonVoice)上的实验表明,该方法在保持或略微提升纠正性能(WER变化在-0.13%到+2.28%相对值内)的同时,平均假设集使用量减少了23%至52%,实现了显著的计算节省,且实证风险控制成功率均超过理论最小值(1-δ)。其实际意义在于为ASR后处理提供了可量化风险、高效率的部署方案。主要局限性在于框架参数(如归一化参数γ)的选择需要基于数据集特性的预先分析,且其理论保证依赖于风险函数的有界性和一定条件下的单调性假设。
🏗️ 模型架构
本文提出的是一个框架,而非单一的神经网络模型。其核心流程是在现有GER流程中插入一个自适应假设集选择模块。
整体架构如图1(b)所示,与固定N的流程对比:
- 标准GER流程:输入音频 → ASR模型生成固定大小N=5的N-best假设集 → LLM(微调后的LLaMA-2)生成纠正转录。
- 本文自适应GER流程:
- 输入:音频信号
x。 - ASR假设生成:使用Whisper模型通过波束搜索生成排名后的N-best假设列表
HN及其对数似然分数c。 - 自适应假设集选择(核心模块):
- 首先,对原始对数似然分数
c进行变换ϕγ(c)和温度缩放τ,得到归一化分数s(公式10)。ϕγ是一个插值函数(公式11),通过参数γ在恒等变换和倒数变换之间平滑切换,以适应不同数据集的分数分布特性。 - 然后,将分数转换为累积和,并与一个从校准集中选出的阈值
λ进行比较。动态假设集Γλ(HN)由累积分数首次达到或超过λ的假设数量n决定(公式5-6)。 LLM生成:将筛选出的、大小可变的假设集输入到LLM(MH2T)中,生成最终纠正转录ŷ。
- 首先,对原始对数似然分数
- 阈值校准:阈值
λ并非固定,而是在一个校准集上通过LTT程序(算法1)离线确定,以满足给定的风险水平α和错误率δ。
- 输入:音频信号
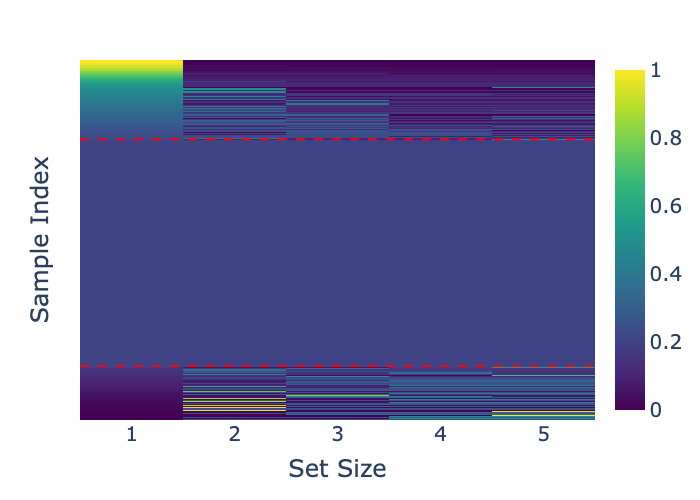 图1(b):标准GER(固定5个假设)与本文自适应GER(动态选择变长假设集并用风险控制约束性能退化)的对比示意图。
图1(b):标准GER(固定5个假设)与本文自适应GER(动态选择变长假设集并用风险控制约束性能退化)的对比示意图。
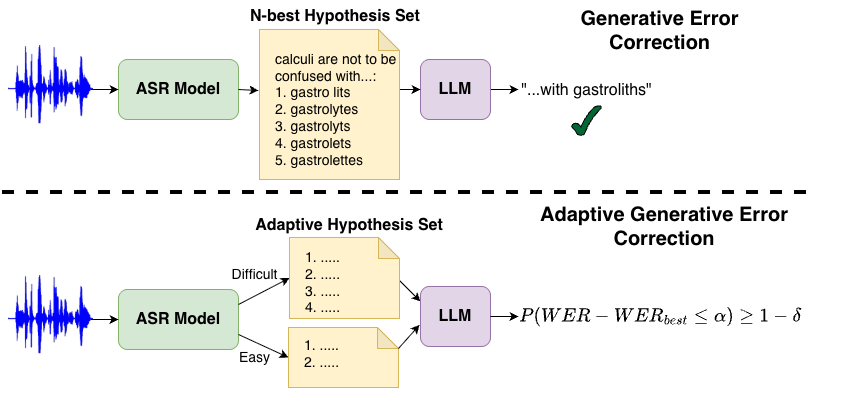 图2:三个数据集上的性能-计算权衡曲线。曲线表示使用固定大小假设集(N=1至5)的WER性能。虚线为Oracle性能(每个样本单独选择最优大小的WER)。彩色标记点代表本文自适应方法在不同
图2:三个数据集上的性能-计算权衡曲线。曲线表示使用固定大小假设集(N=1至5)的WER性能。虚线为Oracle性能(每个样本单独选择最优大小的WER)。彩色标记点代表本文自适应方法在不同α值下的工作点,展示了其在WER和平均假设集大小上相比固定基线的更优权衡。
💡 核心创新点
- 自适应假设集选择框架:提出了一种基于ASR置信度分数的自适应机制,动态决定传递给LLM的假设数量,替代了传统的固定大小策略。这实现了“难度感知”的资源分配,对简单输入用小集,对复杂输入用大集。
- 将风险控制(LTT)应用于GER:首次将“学习-然后-测试”(LTT)这一分布无关的风险控制框架引入生成式语音识别错误纠正任务。这提供了关键的理论突破,能够以高概率保证纠正性能相对于模型最佳表现的退化受到控制(公式9),填补了该领域缺乏性能保证的空白。
- 相对性能退化的损失函数设计:定义了以“相对词错率退化”为核心的损失函数(公式8),即当前选择假设集的WER与该样本在固定大小集上能达到的最佳WER之差。这个设计避免了设定绝对WER目标的难度,且其损失特性更适合风险控制框架的应用。
- 兼顾效率与保证的实证验证:通过大量实验(包括跨数据集、不同LLM规模、零样本设置及跨任务扩展到语音翻译),系统性地证明了该框架能在大幅减少计算量(平均假设集大小降低23-52%)的同时,维持甚至提升性能,并且实证风险控制成功率始终超过理论保证水平。
🔬 细节详述
- 训练数据:
- GER模型训练:使用HyPoradise基准数据集。TedLium-3(50k语句,35.5k训练/验证)、CHiME-4(9.6k训练语句用于训练/验证)、CommonVoice(50k样本,35k用于训练/验证)。预处理包括去除重复语句。
- 风险控制校准:从上述数据集的测试集中划分出一部分(30-50%)作为校准集,用于训练LTT程序。
- 损失函数:核心是相对WER退化损失
ℓ(公式8),定义为使用动态假设集的WER减去该样本在N=1到N=5所有固定大小假设集下能达到的最小WER。该损失在实验中被裁剪(clipped)在B=1.25以满足理论有界性要求。 - 训练策略:
- GER模型:使用LoRA对LLaMA-2-7B进行微调。优化器:AdamW。有效批大小:32(批大小8 + 4步梯度累积)。学习率调度:余弦退火,预热比例0.05。LoRA参数:秩r=16,缩放α=32。训练轮数:5-10轮,取决于数据集大小。学习率范围:5e-5到1e-4。
- LTT校准:离线进行。在校准集上,对参数网格
Λ中的每个阈值λ计算经验风险,使用Hoeffding-Bentkus不等式计算p值,并通过固定序列检验(FST)控制族错误率,以确定满足风险约束α的阈值λ。
- 关键超参数:
γ:分数归一化插值参数(0到1),根据数据集信噪比(SNR)特性预设(TedLium-3: 1.0, CHiME-4: 0.5, CommonVoice: 0.0)。τ:温度参数,用于缩放归一化分数(TedLium-3: 0.05, CHiME-4: 1.0, CommonVoice: 1.0)。α:目标风险水平,即允许的预期相对WER退化上限。在各数据集的可行范围内选取。δ:LTT框架的错误率参数,根据校准集大小设置(论文中报告为0.10或0.25)。β:重复假设惩罚因子,设为1.25。
- 训练硬件:模型训练在单块NVIDIA RTX 6000 Ada GPU(48GB显存)上进行。训练时间:CHiME-4约1小时,TedLium-3和CommonVoice各约3-4小时。
- 推理细节:ASR解码使用波束搜索(Whisper-base波束宽度60, Whisper-large-v2波束宽度50),取top-5。LTT校准和假设集选择是推理预处理的一部分。LLM生成采用标准自回归方式。
📊 实验结果
主要基准结果(LLaMA-2-7B微调):
| 测试集 | 基准 (Whisper top-1) | GER (固定N=5) | 本文方法 (LTT) | α(%) | δ | 成功率 | Oracle | 平均集大小 | WER相对变化 | 集大小减少 |
|---|---|---|---|---|---|---|---|---|---|---|
| TedLium-3 | 9.3 | 7.53 | 2.48 | 2.48 | 0.10 | 0.94 | 5.58 | 2.3 | -0.13% | -50.08% |
| CHiME-4 | 11.49 | 6.24 | 3.866 | 3.866 | 0.25 | 0.98 | 4.71 | 2.7 | +2.06% | -22.68% |
| CommonVoice | 12.44 | 8.32 | 3.29 | 3.29 | 0.10 | 0.92 | 6.96 | 1.9 | +2.28% | -34.2% |
注:WER列为实例平均WER。相对变化和减少率是与固定N=5的GER结果相比。
关键发现:
- 在计算节省方面:所有数据集上,平均假设集大小显著减小,TedLium-3节省50%,CommonVoice节省34%,CHiME-4节省23%。
- 在性能方面:在TedLium-3上,WER略有下降(性能提升0.13%);在CHiME-4和CommonVoice上,WER有小幅上升(性能损失约2%),但仍在Oracle性能范围内。
- 在风险控制方面:实证成功率(0.92-0.98)均高于理论下限
1-δ(0.90或0.75),验证了理论保证。
消融与扩展实验:
- 更大模型:在LLaMA-2-13B上,趋势一致。例如,在TedLium-3上实现了51.9%的计算节省,WER几乎不变(-0.01%)。
- 零样本设置:使用GPT-3.5-turbo,仍能实现42-56%的假设集大小减少,WER仅增加0.67-1.17%。
- 跨任务扩展:应用到语音翻译任务(FLEURS数据集),使用TER作为实例级损失,BLEU作为最终指标。结果显示,可实现36-66%的假设减少,同时保持甚至提升BLEU分数。
- CRC实现:作为对比,使用符合风险控制(CRC)实现也获得了类似的实证性能,但缺乏严格理论保证。
- 多参数优化:使用Pareto Testing联合优化
(γ, τ, λ),发现了比手动参数选择更优的性能-效率权衡曲线。
图示结果:
图2(重复):清晰展示了自适应方法的工作点(彩色点)相对于固定集大小曲线(蓝线)在WER-集大小权衡上的优势,即更靠近左下角。
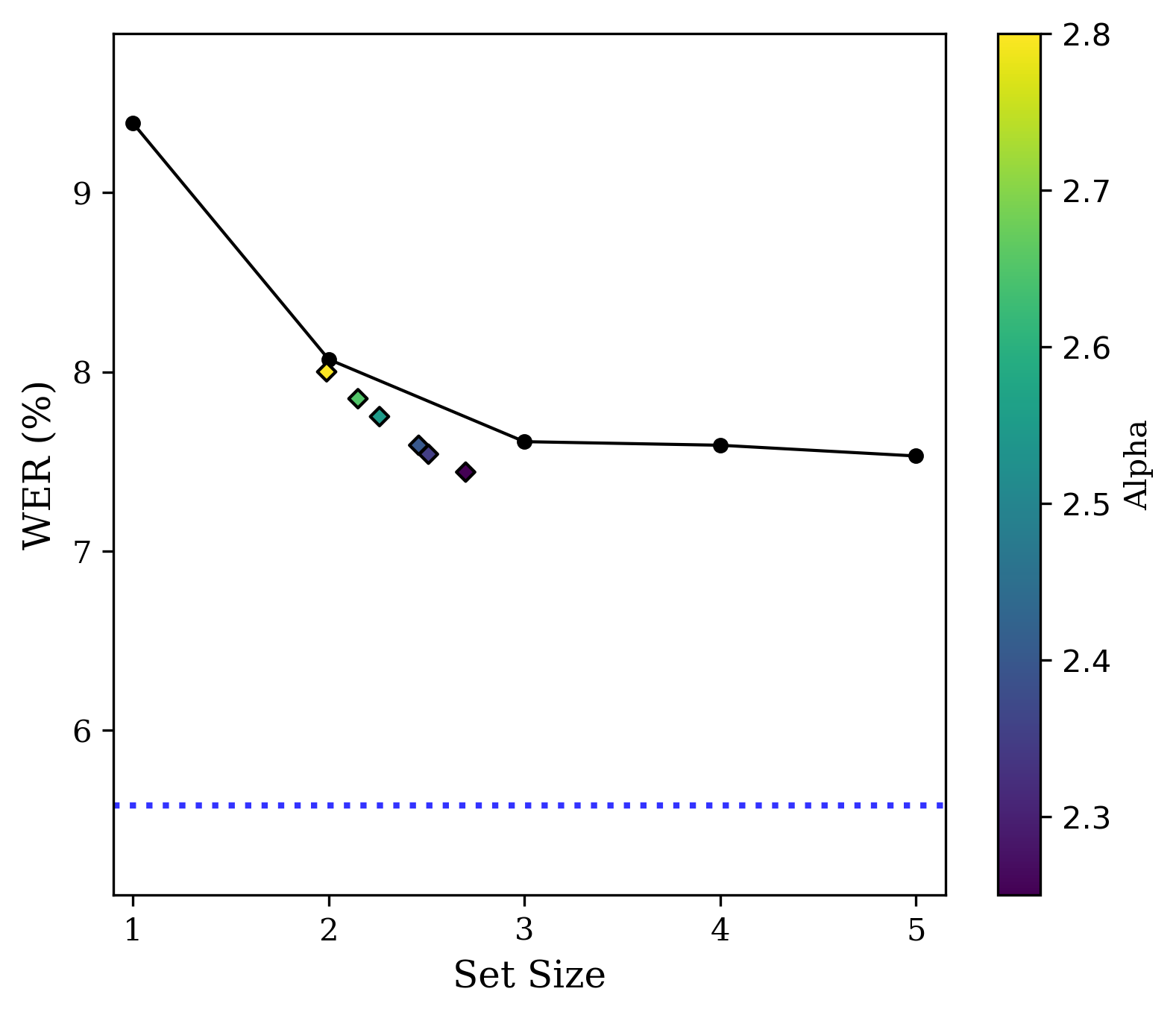 表2(图):通过三个具体案例,说明了分数分布如何影响最优假设集大小。案例1(全集必需)分数密集,需要全部5个假设才能达到0% WER。案例2(单假设最优)分数区分度高,仅需第1个假设即可达到0% WER,更多假设会引入噪声。案例3(性能平台)分数密集但WER已稳定,自适应方法可通过选择较小集合节省计算而不损失性能。
表2(图):通过三个具体案例,说明了分数分布如何影响最优假设集大小。案例1(全集必需)分数密集,需要全部5个假设才能达到0% WER。案例2(单假设最优)分数区分度高,仅需第1个假设即可达到0% WER,更多假设会引入噪声。案例3(性能平台)分数密集但WER已稳定,自适应方法可通过选择较小集合节省计算而不损失性能。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:将LTT风险控制框架引入GER任务是明确且有价值的创新点,为解决该领域长期存在的计算效率和性能保证问题提供了新思路。
- 技术正确性:方法论构建扎实,从损失函数设计(公式8)到算法实现(算法1),再到理论保证的讨论(有界性、单调性)都非常清晰和严谨。
- 实验充分性:实验非常充分。包括跨三个不同难度的数据集、使用不同规模和类型的LLM(微调LLaMA-2 7B/13B、零样本GPT-3.5)、扩展到语音翻译任务、以及多项消融研究(替代目标函数、训练集大小分析、CRC对比、多参数优化)。结果多维度呈现了方法的效力。
- 证据可信度:提供了多次独立运行(T=30)的平均结果,并报告了风险控制的成功率,这直接验证了核心理论承诺。实验设置和基线选择(如Oracle性能)合理。
- 选题价值:1.5/2
- 前沿性:结合LLM与ASR后处理是当前热点,但本文更深入一层,关注该流程内部的效率优化与可靠性,切中实际部署痛点。
- 潜在影响:对于构建高效、可靠的LLM增强ASR系统有直接指导意义,所提出的框架是即插即用的,易于集成到现有系统。
- 应用空间:主要应用于需要高准确率和可靠性的语音识别场景,如会议记录、医疗听写、法律转录等。
- 读者相关性:对于从事ASR、语音处理、以及LLM应用开发的研究者和工程师有较高参考价值。
- 开源与复现加成:0.5/1
- 论文明确提供了代码仓库链接(
https://github.com/amitdamritau/adaptive-ger)。 - 详细描述了LLM的训练超参数、模板、硬件环境(RTX 6000 Ada GPU)。
- 提供了关键的校准参数选择策略(基于SNR和熵的启发式规则)和消融实验的补充材料。
- 未提及是否公开预训练模型权重或原始数据集的获取方式(但数据集本身多为公开基准)。整体复现指引清晰,加成较高。
- 论文明确提供了代码仓库链接(