📄 Compose and Fuse: Revisiting the Foundational Bottlenecks in Multimodal Reasoning
#多模态推理 #评估框架 #多模态模型 #逻辑推理 #基准测试
🔥 8.5/10 | 前25% | #多模态推理 | #评估框架 | #多模态模型 #逻辑推理
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yucheng Wang, Yifan Hou(共同第一作者,苏黎世联邦理工学院)
- 通讯作者:Mrinmaya Sachan(苏黎世联邦理工学院)
- 作者列表:Yucheng Wang(苏黎世联邦理工学院),Yifan Hou(苏黎世联邦理工学院),Aydin Javadov(苏黎世联邦理工学院),Mubashara Akhtar(苏黎世联邦理工学院),Mrinmaya Sachan(苏黎世联邦理工学院)
💡 毒舌点评
亮点在于提出了一个非常系统、基于命题逻辑的六类模态交互评估框架,并对“识别”与“推理”的分离进行了严谨的实验验证,为理解多模态模型瓶颈提供了清晰的诊断工具。短板是使用高度受控的合成数据进行评估,虽然逻辑清晰但可能无法完全反映真实世界中多模态信息的复杂性和噪声,且评估的模型规模较小(7-8B),对超大模型是否适用有待验证。
🔗 开源详情
- 代码:论文提到“Our code and data are publicly available”,但未提供具体链接。
- 模型权重:评估的是公开的第三方模型(Baichuan, Qwen, MiniCPM, Phi4),未提及作者自己训练或微调的模型。
- 数据集:作者生成的合成评估数据集,论文表示将公开,但未提供获取方式。
- Demo:未提及。
- 复现材料:提供了极其详细的实验设置(附录A)、所有提示模板(附录A.3及图4-11)、线性探针设置和评估协议,复现指南性强。
- 论文中引用的开源项目:CosyVoice2 TTS(用于生成音频)、GraphViz(用于生成图像)、HuggingFace(用于模型推理)。
📌 核心摘要
- 问题:现有研究对多模态大语言模型(MLLMs)在推理任务中,额外模态(如图像、音频)究竟是助力还是阻碍存在矛盾结论,缺乏系统性的评估框架来隔离和分析模态交互的作用。
- 方法:提出了一个基于命题逻辑的六类模态交互评估框架(等价、替代、蕴含、独立、矛盾、互补),通过控制信息在模态间的分布和逻辑组合方式,系统性地测试MLLMs的推理能力。同时,通过注意力探针和两步提示等方法剖析模型内部机制。
- 创新:与已有工作相比,本文的创新在于:(1) 提供了统一的、可控的逻辑框架来分类和测试模态交互;(2) 明确分离并诊断出MLLMs的两个核心瓶颈:“任务组合瓶颈”(识别与推理难以在一次前向传播中联合完成)和“融合瓶颈”(早期融合导致模态偏见)。
- 实验结果:在四个开源MLLMs(Baichuan-Omni-1.5d, Qwen2.5-Omni, MiniCPM-o-2.6, Phi-4 Multimodal)上的实验表明:(1) 仅当额外模态提供独立、充分的推理路径时(如“替代”交互),性能才略有提升(平均+1.7% to text-only);(2) 蕴含、矛盾、互补交互均导致性能显著下降(平均分别比text-only基线下降12.8%,导致偏好不一致,且无法有效整合互补信息)。关键实验结果如表1、2、3、4所示。
- 实际意义:研究结论表明,当前MLLMs的核心障碍并非感知,而是信息整合。这为未来的模型设计指明了方向:需要发展“感知-组成感知”的训练目标、显式的证据选择监督以及能控制早期融合的架构。
- 局限性:评估任务基于简化的单步逻辑推理和合成数据,可能无法完全代表复杂的真实世界推理场景;所评估的模型参数规模均在8B以下,对更大型模型的表现未知。
主要实验结果表格:
| 表1:多模态是否有助于推理?(准确率%及相对单模态基线的变化) | ||||
|---|---|---|---|---|
| 模型 | 等价 (≡) | 替代 (∨) | 蕴含 (→):最终事实在V/A/T | |
| ΔV, ΔA, ΔT | ΔV, ΔA, ΔT | ΔV, ΔA, ΔT | ||
| Baichuan | 84.8 (+5.4, +9.8, -11.1) | 97.6 (+19.6, +17.8, +0.3) | 79.5 (-2.0), 75.6 (-6.4), 80.7 (-13.6) | |
| Qwen | 98.9 (+2.6, +4.5, +0.9) | 100.0 (+3.7, +6.1, +2.6) | 78.4 (-15.7), 86.6 (-8.2), 83.9 (-12.8) | |
| MiniCPM | 94.8 (+5.4, +5.2, -0.2) | 99.1 (+7.1, +8.0, +2.9) | 81.8 (-11.4), 80.0 (-12.0), 88.4 (-6.8) | |
| Phi4 | 84.1 (+25.3, +23.9, -12.5) | 97.9 (+20.3, +26.3, +1.0) | 73.0 (-2.2), 69.3 (-0.7), 79.7 (-18.0) | |
| 平均 | 90.7 (+9.7, +10.9, -5.7) | 98.7 (+12.7, +14.8, +1.7) | 78.2 (-7.8), 77.9 (-7.1), 83.2 (-12.8) |
| 表2:独立交互性能(准确率%)。决定性事实仅在一个模态中,其他模态为干扰项。 | ||||
|---|---|---|---|---|
| 模型 | 单模态基线 (V, A, T) | 多模态 (∅) ΔV, ΔA, ΔT | ||
| Baichuan | 60.2, 72.0, 94.8 | 67.6 (+7.4, -4.4, -27.2) | ||
| Qwen | 73.3, 94.3, 95.5 | 75.2 (+1.9, -19.1, -20.3) | ||
| MiniCPM | 77.6, 83.7, 91.2 | 78.7 (+1.1, -5.0, -12.5) | ||
| Phi4 | 49.9, 48.9, 96.3 | 59.7 (+9.8, +10.8, -36.6) | ||
| 平均 | 65.3, 74.7, 94.5 | 70.3 (+5.0, -4.4, -24.2) |
| 表4:互补交互性能(准确率%)。每个模态提供一个必要事实,需整合所有事实。 | ||||
|---|---|---|---|---|
| 模型 | 单模态基线 (V, A, T) | 多模态 (∧) ΔV, ΔA, ΔT | ||
| Baichuan | 50.5, 59.4, 87.7 | 30.2 (-20.3, -29.2, -57.5) | ||
| Qwen | 87.5, 98.8, 98.8 | 49.9 (-37.6, -48.9, -48.9) | ||
| MiniCPM | 74.8, 89.3, 92.4 | 48.8 (-26.0, -40.5, -43.6) | ||
| Phi4 | 80.0, 82.2, 99.6 | 79.1 (-0.9, -3.1, -20.5) | ||
| 平均 | 73.2, 82.4, 94.6 | 52.0 (-21.2, -30.4, -42.6) |
图1说明:展示了逻辑推理示例(a),事实如何被渲染为文本、音频(TTS)和视觉(图示)三种模态(b),以及评估提示的模式(c)。该图阐明了实验的基本设置。
 图2说明:(a) 对信息有用性进行注意力探针的准确率中等,表明模型无法清晰区分有用事实和干扰项。(b) 尽管模型在事实识别和文本推理上表现良好,但多模态推理性能显著下降,证实了瓶颈在于两者的联合执行。
图2说明:(a) 对信息有用性进行注意力探针的准确率中等,表明模型无法清晰区分有用事实和干扰项。(b) 尽管模型在事实识别和文本推理上表现良好,但多模态推理性能显著下降,证实了瓶颈在于两者的联合执行。
 图3说明:(a) 所有模型都能通过注意力模式完美预测模态类型。(b) 对Qwen模型的线性探针权重显示,模态信息主要集中在前四层。(c) 调整前四层注意力的温度(从0.4到1.8)能显著提升推理准确率,而调整中间或后期层则效果甚微,证实了早期融合的偏见是关键。
图3说明:(a) 所有模型都能通过注意力模式完美预测模态类型。(b) 对Qwen模型的线性探针权重显示,模态信息主要集中在前四层。(c) 调整前四层注意力的温度(从0.4到1.8)能显著提升推理准确率,而调整中间或后期层则效果甚微,证实了早期融合的偏见是关键。
🏗️ 模型架构
本文并非提出一个新的模型架构,而是对现有MLLMs(Baichuan-Omni-1.5d, Qwen2.5-Omni, MiniCPM-o-2.6, Phi-4 Multimodal)的推理能力进行系统评估和内部机制分析。其核心“架构”是基于逻辑推理的六类模态交互评估框架。
- 输入:统一格式的提示,包含系统指令、随机顺序的模态事实块(文本/图像/音频)、文本规则集和多选题。
- 处理流程:模型接收多模态输入,内部进行跨模态编码和融合,然后基于融合后的表示进行文本生成,以选择答案。
- 评估重点:通过控制事实在三种模态中的分布(等价、替代、蕴含、独立、矛盾、互补)来隔离不同的交互模式,分析模型的识别、推理和融合能力。
- 内部机制分析:通过在解码器注意力分布上训练线性探针,来分析模型对“信息有用性”(图2a)和“模态身份”(图3a)的编码情况。还通过调整注意力温度进行干预实验(图3c)。
💡 核心创新点
- 系统性、可控的模态交互分类与评估框架:基于命题逻辑定义了六种交互模式,首次在一个统一框架下系统性地量化了不同模态信息分布对推理的影响,解决了以往研究结论矛盾的问题。
- 识别并验证“任务组合瓶颈”:通过实验证明,模型在单独执行“事实识别”(跨模态感知)和“逻辑推理”(文本规则应用)时表现良好,但将两者在一次推理中结合时性能急剧下降。两步提示法能有效缓解此问题,明确了瓶颈所在。
- 识别并验证“融合瓶颈”:通过注意力探针发现模态身份在早期层就被清晰保留,且早期融合引入了模态偏见。通过简单调整早期层注意力温度来软化融合,显著提升了性能,提供了直接的因果证据。
- 揭示多模态推理失败的三种系统性模式:(1) 性能偏见(弱模态拖累强模态);(2) 偏好偏见(面对冲突时,模型偏好与单模态性能不一致的模态);(3) 融合偏见(无法整合互补的跨模态事实)。
🔬 细节详述
- 训练数据:论文未使用真实数据集进行训练,而是生成合成数据用于评估。事实由主体(人名、动物、水果)、谓词(“is”)和属性(34个形容词)随机组合生成。规则基于Clark et al. (2020)的方法生成。视觉图像用GraphViz生成示意图,音频用CosyVoice2 TTS合成。具体构成细节见附录A.1。
- 损失函数:未说明,因为本文是评估性工作,不涉及模型训练。
- 训练策略:未说明(评估的是现有模型)。
- 关键超参数:评估的模型规模为5.6B-8B参数。解码使用贪心搜索(
do_sample=False),最大生成长度1024 tokens。线性探针使用逻辑回归,5折交叉验证。 - 训练硬件:未说明。
- 推理细节:所有模型以float16精度运行,使用统一的提示模板(见附录A.3及图4-11)。
- 正则化技巧:未说明。
📊 实验结果
主要的实验结果已在核心摘要的表格中给出。关键图表结果如下:
 图4说明:展示了“等价”交互的一个具体输入-输出示例。事实“Erin is friendly”以文本和音频(冗余)形式给出,模型正确推理出结论“Erin is purple”。这验证了评估框架的可行性。
图4说明:展示了“等价”交互的一个具体输入-输出示例。事实“Erin is friendly”以文本和音频(冗余)形式给出,模型正确推理出结论“Erin is purple”。这验证了评估框架的可行性。
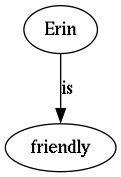 图10说明:展示了用于测试模型事实识别能力的提示模板。模型只需从给定的图像、音频、文本中找出被提及的事实,无需进行推理。该任务用于隔离“识别”能力。
图10说明:展示了用于测试模型事实识别能力的提示模板。模型只需从给定的图像、音频、文本中找出被提及的事实,无需进行推理。该任务用于隔离“识别”能力。
图11说明:展示了“两步推理”的提示模板。第一步要求模型列出各模态中的事实(识别),第二步再基于这些事实和规则进行推理(推理)。此方法有效缓解了“任务组合瓶颈”。
关键消融实验:通过对比多模态设置与单模态基线(表1),发现只有“替代”交互带来平均+1.7%的轻微文本基线提升,而“蕴含”交互导致平均-12.8%的显著下降。在“独立”交互中(表2),文本基线平均准确率94.5%,但多模态平均仅70.3%,证实了性能偏见。在“互补”交互中(表4),多模态平均准确率52.0%,远低于任何单模态基线(文本基线94.6%),证实了融合偏见。
⚖️ 评分理由
- 学术质量:6.5/7 - 本文提出了一个非常扎实、系统的评估框架,实验设计严谨,控制变量得当,从多个角度(性能、偏好、注意力模式)进行了深入分析,并得出了清晰、有证据支持的瓶颈结论。创新在于框架和诊断方法,而非提出新模型。
- 选题价值:1.5/2 - 选题直击多模态大模型发展的核心痛点——信息整合,对整个多模态AI领域具有重要指导意义。但与音频/语音读者的直接相关性主要在于“音频”作为一种模态在评估框架中的角色,而非专注于解决特定的音频处理任务。
- 开源与复现加成:0.5/1 - 论文声明代码和数据将公开,并在附录中提供了详细的设置、探针方法、提示模板(图4-11),复现性信息较充分。但截至当前,未提供具体的代码仓库链接,扣分。