📄 Beyond Instance-Level Alignment: Dual-Level Optimal Transport for Audio-Text Retrieval
#音频检索 #最优传输 #对比学习 #鲁棒性
🔥 8.0/10 | 前25% | #音频检索 | #最优传输 | #对比学习 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Wenqi Guo(上海交通大学)
- 通讯作者:Shikui Tu(上海交通大学),Lei Xu(上海交通大学,深圳人工智能与数字经济广东省实验室)
- 作者列表:Wenqi Guo(上海交通大学)、Shikui Tu(上海交通大学)、Lei Xu(上海交通大学,深圳人工智能与数字经济广东省实验室)
💡 毒舌点评
这篇论文的亮点在于它聪明地将最优传输(OT)从“实例级对齐”推广到“特征级正则化”,为解决小批量训练下的噪声敏感性问题提供了新颖且理论扎实的视角,实验结果在多个基准上确实很强。然而,其短板也很明显:提出的“可靠性感知边缘分布”计算依赖于批次统计量,在实际大规模分布式训练中的稳定性和计算开销可能成为落地隐患,且论文未提供代码,复现门槛较高。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用的AudioCaps, Clotho, ESC-50均为公开数据集,论文中给出了获取来源引用。
- Demo:未提及在线演示。
- 复现材料:提供了极其详细的复现材料:完整的训练算法伪代码(算法1)、所有实验的超参数设置(表6)、可靠性分数计算的具体公式(附录B)、理论证明(附录C)、以及所有消融和敏感性实验(表5, 7-13)。
- 论文中引用的开源项目:引用了Sinkhorn算法(Cuturi, 2013),并使用了预训练的编码器(如BERT, Beats等)。
📌 核心摘要
- 问题:现有的跨模态检索(如音频文本检索)方法主要依赖实例级对齐(如对比损失),隐含假设所有特征维度贡献相等。在小批量训练和标签稀缺时,这种假设会放大噪声,导致对齐信号不稳定且有偏差。
- 方法核心:提出DART(Dual-level Alignment via Robust Transport)框架,在实例级对齐(基于逆最优传输IOT)的基础上,增加了基于非平衡Wasserstein距离(UWD)的特征级正则化。同时,设计了“可靠性感知边缘分布”,根据通道的跨模态一致性、方差和峰度统计量,自适应地为特征通道赋权,以抑制噪声通道。
- 创新点:首次将OT视角从样本对齐拓展到特征通道对齐;引入可靠性先验引导特征级运输计划;提供了理论分析,证明特征级目标比实例级目标具有更紧的集中界,对异常值和噪声更鲁棒。
- 实验结果:在AudioCaps、Clotho两个音频文本检索基准和ESC-50零样本声音事件检测任务上,DART均取得了SOTA性能。例如,在AudioCaps上,与最强基线相比,文本到音频R@1提升1.1%,音频到文本R@1提升4.5%。在小批量(k=32)和40%标签缺失的困难设定下,性能下降幅度显著小于基线方法(见表2)。
- 实际意义:为资源受限(小批量训练)或数据质量不高(标签噪声)场景下的跨模态检索提供了更鲁棒的解决方案,提升了模型在实际应用中的可靠性和泛化能力。
- 主要局限性:引入的特征级正则化和可靠性计算增加了训练时的计算复杂度(虽然论文分析内存开销可控)。可靠性估计依赖于小批量统计,其稳定性有待更广泛验证。此外,论文未开源代码。
🏗️ 模型架构
DART的整体架构是一个双层对齐框架,如图1所示。
- 输入:成对的音频波形和文本描述数据。
- 编码器:使用音频编码器和文本编码器(如ResNet38、BERT、Beats等)分别提取音频和文本的嵌入向量。
- 实例级对齐分支:
- 计算样本对成本矩阵:基于编码后的嵌入,计算所有音频-文本对之间的欧氏距离。
- 使用熵正则化最优传输求解器(Sinkhorn)生成耦合矩阵Π,表示模型推断的匹配关系。
- 计算实例级IOT损失(公式5):最小化推断耦合Π与真实匹配(单位矩阵)之间的KL散度。
- 特征级对齐分支:
- 特征成本矩阵构建:将每个特征维度(列)视为一个在小批量样本上分布的“单位”。计算音频和文本特征矩阵中各列之间的欧氏距离,得到特征成本矩阵C_Feature。
- 可靠性感知边缘分布:计算每个特征通道的可靠性分数(公式10),该分数由跨模态相关性、方差不稳定性和峰度(重尾性)三个统计量经sigmoid函数聚合而成。将这些分数归一化为概率分布,作为源和目标的先验边缘u和v。
- 非平衡最优传输:使用UWD公式(公式8)求解最优传输计划P。其中,KL项约束了P的边缘与可靠性先验u、v的偏离程度,从而将更多质量分配到可靠通��。
- 特征级损失:计算特征成本矩阵与传输计划P的Frobenius内积,即UWD损失(公式9),并使用可靠性感知边缘版本L_UWD-R(公式12)。
- 总损失:将两个损失加权求和(公式14),平衡实例级对齐和特征级正则化。可靠性分数通过EMA在训练中平滑更新(公式13)。
💡 核心创新点
- 双层对齐框架:核心创新是将跨模态对齐从单一的“实例级”提升到“实例级+特征级”双层。之前的实例级方法将所有特征维度同等对待,而特征级正则化显式地建模和优化特征通道间的关系,为模型提供了更细粒度的约束。
- 可靠性感知边缘分布:设计了一个轻量级的统计模块,用于估计每个特征通道的跨模态语义可靠性。这作为先验知识融入UWD,主动引导运输计划远离噪声或模态特定通道,稳定了训练信号。
- 理论分析与集中界证明:提供了严格的理论分析。证明实例级IOT损失的集中界受最大配对距离D_max控制,对异常值敏感;而特征级UWD损失的集中界受运输计划的Frobenius范数控制,是所有通道贡献的聚合,因此对噪声更鲁棒(定理1、2)。这为双层设计提供了理论动机。
- 特征级损失的通用性:实验证明,提出的特征级损失L_UWD可以作为即插即用的正则化项,与多种实例级损失(对比损失、三元组损失、IOT损失)结合,并一致带来性能提升(表11)。这超越了特定的音频检索任务,具有更广的适用性。
🔬 细节详述
- 训练数据:
- 数据集:AudioCaps(约4.5万对,音频来自AudioSet),Clotho(约5千对,音频来自Freesound),ESC-50(用于零样本评估,50类环境声音)。
- 预处理:音频统一处理为10秒(AudioCaps)或15-30秒(Clotho)。文本使用预训练语言模型(如BERT)的Tokenizer处理。
- 数据增强:论文中未提及使用特定的数据增强策略。
- 损失函数:
- 实例级IOT损失:L_IOT(θ, ϕ) = KL(Π^b ∥ Π_{(θ,ϕ)}^b)。在一对一匹配下简化为-log Π_{ii}。直接优化此损失。
- 特征级UWD损失:L_UWD(θ, ϕ) = ⟨C_Feature, P⟩。其中P是公式8的优化解。
- 可靠性感知UWD损失:将公式8中的均匀边缘替换为可靠性先验u,v,得到L_UWD-R。
- 总损失:L_total = (1/B) Σ [L_IOT + λ L_UWD-R]。λ是权重超参数。
- 训练策略:
- 优化器:Adam或AdamW。
- 学习率:对于ResNet38+BERT为5e-5,对于CNN+BPE为1e-6,对于Beats+BERT为5e-7。
- 批量大小:主要实验使用256,小批量鲁棒性实验使用6,8,32,128。
- 训练轮数:10 epochs。
- 权重衰减:在0.0到0.01之间。
- EMA平滑:可靠性分数的EMA系数β=0.9。
- 关键超参数:
- λ:实例级损失与特征级损失的权重,主要实验设置为0.5,敏感性分析范围为0.1-0.7。
- ε:熵正则化参数,设置为0.03。
- τ:UWD中质量泄漏惩罚参数,设置为0.05。
- 编码器:使用了多种预训练或随机初始化的编码器(ResNet38, BERT, CNN, BPE, Beats, BERT)。
- 训练硬件:在配备NVIDIA A100-40GB GPU的工作站上进行。
- 推理细节:对于检索任务,计算查询与所有候选样本的距离(公式3),并返回距离最小(或相似度最大)的样本。论文未提及使用温度缩放或束搜索。
- 正则化或稳定训练技巧:
- 熵正则化:用于OT求解,提高计算效率并得到平滑耦合。
- 非平衡OT:放宽质量守恒约束,适应分布不匹配。
- EMA:稳定可靠性分数估计。
- Hysteresis规则、Warm-up、Freeze、Top-K过滤:在附录B中提及,用于进一步稳定通道选择,但未说明主实验是否全部使用。
📊 实验结果
主要基准性能(表1)
| 方法 | 编码器 (音频-文本) | T→A (AudioCaps) R@1 | T→A (AudioCaps) R@10 | A→T (AudioCaps) R@1 | A→T (AudioCaps) R@10 | T→A (Clotho) R@1 | T→A (Clotho) R@10 | A→T (Clotho) R@1 | A→T (Clotho) R@10 |
|---|---|---|---|---|---|---|---|---|---|
| Luong et al. | ResNet38-BERT | 39.10 | 85.78 | 49.94 | 90.49 | 16.65 | 52.84 | 22.10 | 56.74 |
| DART w/ RAM | ResNet38-BERT | 41.67 | 85.97 | 55.27 | 90.38 | 17.18 | 54.52 | 23.54 | 58.85 |
| Wang et al. | CNN-BPE | 33.72 | 83.59 | 39.14 | 82.24 | 16.63 | 51.98 | 20.47 | 55.50 |
| DART w/ RAM | CNN-BPE | 33.42 | 82.53 | 43.30 | 84.11 | 20.07 | 59.08 | 26.79 | 62.00 |
| Chen et al. | Beats-BERT | 54.2 | 91.2 | 66.9 | 96.7 | 36.7 | 74.4 | 25.9 | 64.7 |
| DART w/ RAM | Beats-BERT | 56.9 | 93.2 | 72.1 | 97.0 | 37.5 | 75.9 | 27.9 | 69.5 |
结论:DART在不同编码器架构下均取得SOTA或极具竞争力的性能。
鲁棒性评估(表2, 批量大小32)
| 条件 | 方法 | T→A R@1 | A→T R@1 |
|---|---|---|---|
| 半监督 (20% 无标签) | Luong et al. | 32.93 | 39.81 |
| DART | 34.85 | 45.03 | |
| 半监督 (40% 无标签) | Luong et al. | 28.58 | 35.00 |
| DART | 33.24 | 43.67 | |
| 噪声标签 (20% 噪声) | Luong et al. | 31.32 | 38.35 |
| DART | 32.87 | 43.57 | |
| 噪声标签 (40% 噪声) | Luong et al. | 26.20 | 34.37 |
| DART | 29.67 | 37.09 |
结论:在标签缺失和噪声环境下,DART性能下降更平缓,鲁棒性显著优于基线。
零样本声音事件检测(表4, ESC-50)
| 损失函数 | Audio→Sound R@1 (准确率) | mAP |
|---|---|---|
| 三元组损失 | 71.25 | 80.09 |
| 对比损失 | 72.25 | 80.84 |
| IOT损失 | 79.25 | 87.09 |
| DART | 80.75 | 87.78 |
结论:DART在零样本泛化任务上也优于各种损失函数基线。
消融实验(表5, 表10)
- RAM有效性(表5):全RAM配置(corr+emavar+kurt)取得最佳平均R@1(45.55)。单独使用相关性(corr)不稳定,而方差(emavar)和峰度(kurt)提供稳定增益。
- 双层损失必要性(表10):仅使用L_UWD性能接近随机(R@1≈0),仅使用L_IOT是强基线,两者结合性能最优,证明其互补性。
可视化分析(图3)
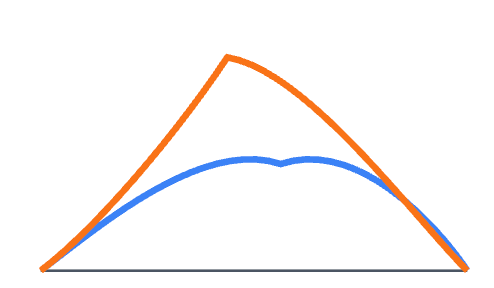 结论:可靠性分数r_j与标准化运输成本C_j呈负相关(ρ≈-0.379)。低可靠性(红色)通道对应高运输成本区域,高可靠性(绿色)通道对应低成本区域,验证了RAM能有效识别并抑制噪声通道。
结论:可靠性分数r_j与标准化运输成本C_j呈负相关(ρ≈-0.379)。低可靠性(红色)通道对应高运输成本区域,高可靠性(绿色)通道对应低成本区域,验证了RAM能有效识别并抑制噪声通道。
⚖️ 评分理由
- 学术质量:6.0/7。创新性良好,将OT从实例级应用到特征级,并提供了有趣的理论视角;技术正确,模型设计合理;实验非常充分,覆盖了多种编码器、数据集、小批量及噪声/半监督等挑战性场景,证据可信度高。
- 选题价值:1.5/2。音频文本检索是跨模态理解的基础任务,具有明确的实际应用价值(如多媒体搜索)。论文专注于解决小批量和噪声下的鲁棒性问题,契合实际部署需求,对相关领域读者有较高价值。
- 开源与复现加成:0.5/1。论文提供了详尽的训练伪代码(算法1)、超参数表(表6)、数据集信息、实验设置和消融分析,复现细节清晰。但未提及公开代码、模型权重或Demo链接,复现门槛仍需自行搭建。