📄 Automatic Stage Lighting Control: Is it a Rule-Driven Process or Generative Task?
#音乐生成 #自回归模型 #端到端 #多模态模型 #生成模型
🔥 8.5/10 | 前25% | #音乐生成 | #自回归模型 | #端到端 #多模态模型
学术质量 8.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Zijian Zhao(The Hong Kong University of Science and Technology)
- 通讯作者:Xiaoyu Zhang(City University of Hong Kong)
- 作者列表:Zijian Zhao(The Hong Kong University of Science and Technology),Dian Jin(The Hong Kong Polytechnic University),Zijing Zhou(The University of Hong Kong),Xiaoyu Zhang(City University of Hong Kong)
💡 毒舌点评
亮点: 论文最具价值之处在于开创性地将“自动舞台灯光控制”从传统的分类-映射范式重新定义为端到端的生成任务,并提供了从数据集构建到模型设计、评估的完整解决方案,思路清晰,闭环完整。 短板: 模型架构的核心(Skip-BART)是对现有BART模型的适配与改进,而非全新架构设计;“生成”的概念虽新,但任务本身的复杂度和数据规模(699个样本)使其技术深度相较于文本或图像生成领域的突破性工作仍有距离。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/RS2002/Skip-BART
- 模型权重:论文明确表示提供了“trained model parameters”,链接同上。
- 数据集:论文发布了首个舞台灯光数据集RPMC-L2,提供处理后的HDF5特征文件(约40GB),而非原始视频,以解决版权问题。获取方式应通过上述GitHub仓库。
- Demo:论文中未提及在线演示链接。
- 复现材料:论文在附录中提供了极其详细的复现材料,包括:模型配置表(Table 4)、预训练与微调的具体损失函数与超参数、数据处理步骤(音频与灯光)、人类评估的完整问卷与流程、消融实验的具体设置。
- 论文中引用的开源项目:依赖或参考的开源项目包括:OpenL3(音频特征提取)、PianoBART(预训练骨干网络)、PyTorch框架。此外,跨域评估中使用了Suno生成音乐。
- 总结:论文的开源工作非常到位,提供了从数据、代码、模型到评估细节的全套材料,为研究的可重复性和后续工作提供了极大便利。
📌 核心摘要
这篇论文针对现有自动舞台灯光控制(ASLC)方法多基于有限类别分类和预定义规则映射,导致结果公式化、单调的问题,首次提出将ASLC视为一个生成任务而非简单的规则驱动过程。方法核心是提出了Skip-BART,一个端到端的深度学习模型,以BART为骨架,通过跳过连接机制显式建模音乐帧与灯光帧的对应关系,并利用预训练(PianoBART)和迁移学习技术缓解数据稀缺问题。与已有方法相比,其创新在于:1)任务定义从分类映射转变为序列生成;2)设计了专用的跳过连接以增强模态对齐;3)构建了首个专用的舞台灯光数据集RPMC-L2。实验结果表明,在定量分析中(见Table 1),Skip-BART在所有指标上均显著优于规则基线方法(如Hue RMSE:36.13 vs 48.67);在人类评估中(见Table 2, Table 3),Skip-BART的总体得分(M=4.35)与专业灯光工程师的地面真值(M=4.51)无显著差异(p=0.724),且远高于规则方法(M=2.67, p<0.001)。该研究为自动化艺术内容创作提供了新范式,其实际意义在于有望大幅降低舞台灯光设计的成本与技术门槛。主要局限性在于模型偶尔出现过强的局部灯光波动,且当前仅支持离线单主灯生成,未考虑实时与多灯协同控制。
🏗️ 模型架构
Skip-BART的整体架构如图1所示,旨在将音乐音频序列映射为对应的灯光(色相Hue与亮度Value)序列。其工作流程如图3所示。
输入处理:
- 音频输入:原始音乐音频经过预处理,使用OpenL3模型提取高维嵌入向量,再通过一个多层感知机(MLP)将其映射到与BART嵌入层匹配的维度。
- 灯光输入/标签:灯光信息在HSV色彩空间处理,饱和度(S)固定为255。对于每帧,提取主要色相(众数)和亮度(加权平均),形成离散化的色相和亮度标签。
- 嵌入层:色相(0-179)和亮度(0-255)分别通过独立的嵌入层转化为向量,然后拼接,作为解码器的输入。嵌入层能更好地处理色相的环形特性。
骨干网络(BART):
- 编码器:基于PianoBART(一个在符号音乐上预训练的BART模型)的编码器,并通过DARE方法融合了其在多个下游任务上的微调参数,从而获得强大的音乐表示能力。使用LoRA进行高效微调。
- 解码器:接收灯光嵌入序列(在训练时为右移的真实标签),并自回归地生成下一个灯光帧的预测。
核心创新组件 - 跳过连接:这是模型的关键设计。在解码器端,为了显式地告知模型每个时间步的灯光生成应重点参考对应时间步(或前一时间步)的音乐信息,论文将来自编码器的当前音乐帧的嵌入与前一时刻灯光帧的嵌入相加(如图1中“Add”操作),然后输入给解码器的自注意力层。这直接强化了音乐与灯光之间的一对一帧级对应关系,解决了标准BART解码器难以学习这种对齐的痛点。
输出头与训练:
- 预训练阶段:采用掩码语言模型(MLM)任务,仅在音频数据上进行预训练。解码器输出通过MLP映射回原始音频嵌入空间,损失函数结合了重建损失、掩码恢复损失和GAN对抗损失(判别器区分真实与重建的音频嵌入)。
- 微调阶段:采用语言模型(LM)任务,解码器输出通过两个独立的MLP头分别预测色相和亮度的类别概率,损失函数为交叉熵损失,并采用自适应权重调整。
推理:使用受限随机温度控制(RSTC)采样。在自回归生成每一步时,根据温度参数对预测概率分布进行采样,并限制相邻帧的灯光变化幅度,以保证输出的多样性和平滑性。
架构图说明:
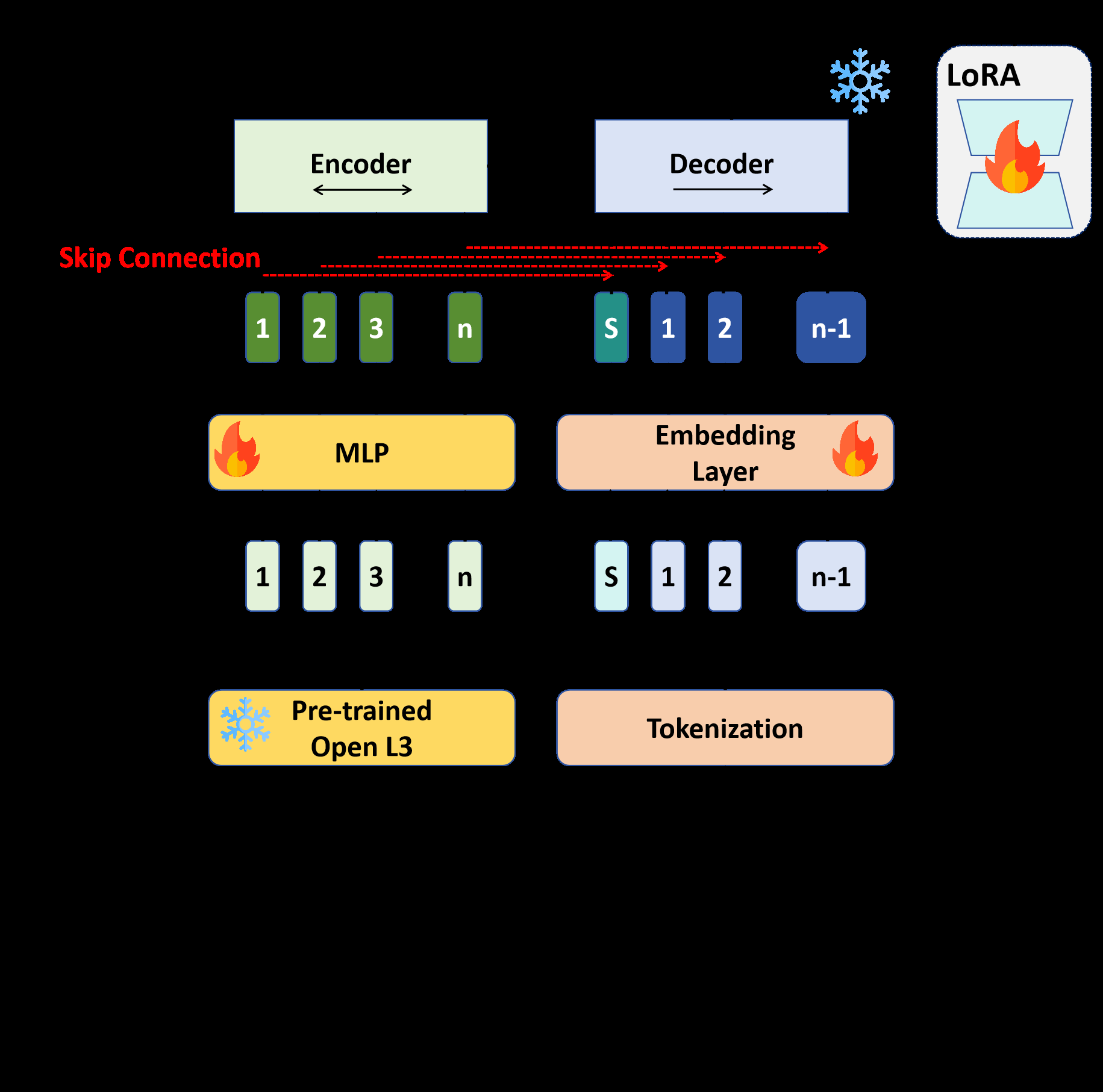 图1展示了Skip-BART的总体结构。左侧为音频编码路径(蓝色),使用OpenL3和MLP提取特征,输入到BART编码器(由PianoBART初始化)。右侧为灯光生成路径(绿色),灯光标签通过嵌入层输入。核心跳过连接(紫色)将编码器输出的音乐特征与解码器的灯光特征相加后,输入给BART解码器。最终解码器输出通过两个MLP头分别预测色相和亮度。
图1展示了Skip-BART的总体结构。左侧为音频编码路径(蓝色),使用OpenL3和MLP提取特征,输入到BART编码器(由PianoBART初始化)。右侧为灯光生成路径(绿色),灯光标签通过嵌入层输入。核心跳过连接(紫色)将编码器输出的音乐特征与解码器的灯光特征相加后,输入给BART解码器。最终解码器输出通过两个MLP头分别预测色相和亮度。
 图3更清晰地展示了模型的工作流程:包括MLM预训练(仅用音频)、端到端微调(用配对的音频-灯光数据)和RSTC推理三个阶段,以及跳过连接在帧级如何融合音乐和灯光特征。
图3更清晰地展示了模型的工作流程:包括MLM预训练(仅用音频)、端到端微调(用配对的音频-灯光数据)和RSTC推理三个阶段,以及跳过连接在帧级如何融合音乐和灯光特征。
💡 核心创新点
- 范式创新:将ASLC重新定义为生成任务:这是论文最根本的贡献。以往方法将灯光控制视为“分类音乐风格/情绪 -> 映射到固定灯光模式”的规则驱动过程。本文认为灯光设计是一种艺术创作,首次提出并论证了ASLC应被视为一个序列到序列的生成任务,为领域研究开辟了新方向。
- 跳过连接机制(Skip Connection):针对序列生成任务中常见的模态对齐难题,设计了该机制。它直接将编码器中对应时间步的音乐表示与解码器的灯光表示融合,显式地提供了帧级对应线索,有效提升了生成灯光与音乐节奏、结构的同步性,消融实验(w/o skip connection)证实了其有效性。
- 首个舞台灯光数据集(RPMC-L2):为解决该领域缺乏数据的问题,作者构建并发布了第一个用于训练和评估的舞台灯光数据集,包含699个来自现场演出的音视频样本,并提供了详细的数据处理流程(包括从视频中提取灯光信息的增强方法)。
- 迁移学习与预训练策略:为克服小数据挑战,模型骨干网络从音乐符号领域的PianoBART迁移而来,并利用DARE方法融合其在多个任务上的知识。同时,设计了基于MLM和GAN的预训练任务,让模型在纯音乐数据上学习有用的表示,为后续灯光生成奠定基础。
🔬 细节详述
- 训练数据:使用自建的RPMC-L2数据集,包含699个样本,来自摇滚、朋克、金属等风格,长度20秒至5分钟不等。按8:1:1划分为训练、验证、测试集,且确保不同现场演出的数据不会出现在同一个划分中。预处理包括音频嵌入(OpenL3)和灯光信息提取(HSV色彩空间,设置亮度阈值,提取主要色相和亮度)。
- 损失函数:
预训练损失:
Lpre = α1l1 + α2l2 + α3l3,其中l1为整体重建MSE损失,l2为被掩码token的恢复MSE损失,l3为GAN判别器损失(判别重建结果为真)。权重α1=0.8, α2=0.2, α3=0.1。 微调损失:Lstf = β1CE(ˆh, h) + β2*CE(ˆv, v),为色相和亮度的交叉熵损失。权重β采用自适应策略,根据前一epoch验证集上的准确率动态调整,使模型更关注学习较慢的属性。 - 训练策略:
- 预训练:采用MLM任务,掩码比例从
U(0.15, 0.30)中随机采样。使用AdamW优化器,学习率0.0001,批大小16。训练15小时。 - 微调:采用LM任务。同样使用AdamW优化器,学习率0.0001。训练1.5小时。
- 迁移学习:骨干网络使用PianoBART,并通过DARE公式融合其在5个下游任务(priming, melody extraction, velocity prediction, composer classification, emotion classification)的微调参数。
- 预训练:采用MLM任务,掩码比例从
- 关键超参数:色相词汇��小180,亮度词汇大小256。嵌入维度512。网络层数8,隐藏维度2048,注意力头数8。总参数量240M,可训练参数量19M(因使用了LoRA)。
- 训练硬件:Intel Xeon Gold 6133 CPU,2× NVIDIA 4090 GPU,1× NVIDIA A100 GPU。
- 推理细节:采用RSTC采样。温度参数
t可调(论文未给出具体推理值)。在采样时,会计算相邻帧的色相距离(环形距离)和亮度距离,若超过预设阈值d_h或d_v(论文未给出具体值),则将对应类别的概率置零,以强制平滑过渡。 - 数据增强/预处理技巧:在从视频提取灯光信息时,提出了改进方法。仅从亮度(V)超过动态阈值的像素中统计色相分布,以避免低光照下的色相失真,并更好地还原极端光照下的颜色(如图2所示)。在HSV空间中固定饱和度为100%,以抵消环境散射、烟雾等对颜色纯度的影响。
📊 实验结果
论文通过定量分析和人类评估验证了方法的有效性。
- 定量分析结果(Table 1): 在RPMC-L2测试集上,与基线(Rule-based)和多种消融变体进行比较。
| 方法 | Hue RMSE ↓ | Value RMSE ↓ | Hue MAE ↓ | Value MAE ↓ | Hue corr(|Δ|) ×10⁻² ↑ | Value corr(|Δ|) ×10⁻² ↑ | | :— | :—: | :—: | :—: | :—: | :—: | :—: | | Rule-based | 48.67 | 93.39 | 43.43 | 86.55 | 0.50 | 0.58 | | Skip-BART | 36.13 | 60.74 | 28.72 | 51.27 | 0.88 | 2.94 | | w/o skip connection | 36.89 | 68.33 | 29.44 | 58.34 | 1.15 | 0.30 | | w/o light embedding | 51.04 | 67.25 | 41.50 | 54.87 | 0.80 | 0.70 | | train from scratch | 36.63 | 67.49 | 28.83 | 57.22 | 0.69 | 0.53 | | pre-train w/o random [MASK] | 49.97 | 64.45 | 42.07 | 52.63 | 0.54 | 1.11 | | pre-train w/o discriminator | 50.40 | 68.09 | 41.52 | 56.54 | 0.46 | 1.13 |
结论:Skip-BART在色相和亮度的所有绝对误差指标(RMSE, MAE)上均达到最优,显著优于规则基线和大多数消融变体。消融实验表明,跳过连接、预训练策略(随机掩码、判别器)对性能有重要贡献。
- 人类评估结果(Table 2, Table 3): 38名参与者对4种方法(Ground Truth, Skip-BART, Ablation Study (w/o skip connection), Rule-based)在6个维度上进行评分(1-7分)。
域内评估(摇滚等风格)得分:
| 方法 | Emotion | Impact | Rhythm | Smoothness | Atmosphere | Surprise | Overall |
|---|---|---|---|---|---|---|---|
| Ground Truth | 4.50±0.93 | 4.48±0.99 | 4.61±0.99 | 4.62±1.07 | 4.49±0.89 | 4.34±1.10 | 4.51±0.88 |
| Skip-BART | 4.69±0.87 | 4.39±0.95 | 4.50±1.06 | 4.32±1.12 | 4.32±0.93 | 3.83±1.06 | 4.35±0.87 |
| Ablation Study | 4.31±0.94 | 3.78±0.96 | 4.54±1.08 | 4.43±1.12 | 4.11±0.98 | 3.50±1.00 | 4.11±0.84 |
| Rule-based | 3.12±1.52 | 2.65±1.39 | 2.54±1.47 | 2.56±1.27 | 2.77±1.50 | 2.35±1.40 | 2.67±1.29 |
总体得分成对比较:
| 比较 | 域内评估 ∆M (p值) | 跨域评估 ∆M (p值) |
|---|---|---|
| Ground Truth vs. Skip-BART | 0.16 (p=0.724) | – |
| Skip-BART vs. Rule-based | 1.68 (p<0.001) | 1.00 (p<0.001) |
| Skip-BART vs. Ablation Study | 0.23 (p=0.152) | 0.24 (p=0.167) |
结论:Skip-BART的总体得分(M=4.35)与地面真值(M=4.51)无统计学显著差异,表明其表现接近专业工程师。它在所有维度上都显著优于规则方法(p<0.001)。跨域评估(使用Suno生成的民谣、R&B、爵士音乐)中,Skip-BART同样表现最佳且显著优于规则方法。
 图5展示了两个例子。顶部为输入音乐的梅尔频谱图,中部为真实灯光序列,底部为Skip-BART生成的序列。每列的颜色代表该时刻的灯光颜色和亮度。图(b)中的红框高亮了一个成功识别的段落转换,Skip-BART生成的灯光在此处与真实值一样变亮,显示了其捕捉音乐结构的能力。
图5展示了两个例子。顶部为输入音乐的梅尔频谱图,中部为真实灯光序列,底部为Skip-BART生成的序列。每列的颜色代表该时刻的灯光颜色和亮度。图(b)中的红框高亮了一个成功识别的段落转换,Skip-BART生成的灯光在此处与真实值一样变亮,显示了其捕捉音乐结构的能力。
⚖️ 评分理由
- 学术质量:6.5/7。创新性突出(任务范式转换),技术方案完整且针对性强(跳过连接、预训练策略),实验非常充分(定量+跨域人类评估),证据链条可信。扣分点在于模型架构的创新深度相较于基础模型有提升空间,且任务本身的数据规模和复杂度有限。
- 选题价值:1.5/2。将生成式AI应用于舞台灯光控制是一个新颖且有应用前景的探索,对于MIR和艺术AI社区有启发。但任务相对小众,其直接影响力和应用广度可能不及更通用的音频生成或理解任务。
- 开源与复现加成:+1.0/1。提供了代码、数据集、预训练模型,附录包含极尽详细的超参数、数据处理流程、评估问卷,复现友好度极高,这是论文的一大亮点。