📄 AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer
#音频生成 #流匹配 #多模态模型 #音视频 #零样本
✅ 7.5/10 | 前25% | #音频生成 | #流匹配 | #多模态模型 #音视频
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Pengjun Fang(The Hong Kong University of Science and Technology)
- 通讯作者:Harry Yang(The Hong Kong University of Science and Technology,标注有邮箱B)
- 作者列表:Pengjun Fang(香港科技大学)、Yingqing He(香港科技大学)、Yazhou Xing(香港科技大学)、Qifeng Chen(香港科技大学,标注有邮箱B)、Ser-Nam Lim(University of Central Florida,标注有邮箱B)、Harry Yang(香港科技大学,标注有邮箱B)
💡 毒舌点评
亮点:巧妙地利用“参考音频”作为控制信号,绕过了文本描述的语义模糊和粒度不足问题,实现了真正细粒度(如不同狗叫)和创意性(如音色迁移)的音效生成,两阶段训练策略的设计也颇具巧思。短板:核心生成模型(多模态Transformer+Flow Matching)是已有框架的整合,原创性集中在“控制方式”和“训练技巧”上;论文坦诚的指出,在处理复杂多声源场景时仍显力不从心,这限制了其在真实世界复杂声景中的即刻应用。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及公开专用数据集。所使用的VGGSound、AudioCaps、WavCaps均为已有公开数据集。
- Demo:未提及。
- 复现材料:提供了极其详细的训练细节(附录A)、网络架构细节(附录B)以及方法描述,为复现奠定了坚实基础。
- 引用的开源项目:论文引用了多个开源工具或模型,包括:CLIP、Synchformer、BigVGAN(声码器)、ImageBind(用于数据筛选)、AdamW优化器、EMA技术等。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 要解决什么问题:现有视频到音频(V2A)生成方法主要依赖文本提示,存在两大瓶颈:训练数据中的语义粒度模糊(如将不同的狗叫统称为“狗叫”)和文本难以描述微声学特征(如“金属碰撞声”无法区分锤击和链条声),导致无法进行精细的声音合成控制。
- 方法核心是什么:提出AC-Foley,一个参考音频引导的V2A生成框架。它直接利用一段参考音频的声学特征(而非语义)作为条件,结合视频和文本信息,通过多模态Transformer和条件流匹配模型,生成与视频同步且具有目标音色特征的声音。
- 与已有方法相比新在哪里:a) 控制维度升级:从文本/视频语义控制升级为直接的声学特征控制,实现细粒度合成和音色迁移。b) 训练策略创新:采用两阶段训练(重叠与非重叠条件学习),使模型既能从对齐样本中学习声学特征,又能泛化到非对齐的时序上下文中,避免简单复制。c) 零样本生成能力:通过参考音频条件,能生成训练集中未见过的声音类别(如带消音器的枪声)。
- 主要实验结果如何:在VGGSound测试集上,AC-Foley在音频条件控制设置下,所有指标均优于基线(如MMAudio+CLAP)。例如,其FDPaSST为56.00(优于基线70.80),MCD为11.37(优于基线14.63)。在无音频条件的纯V2A任务中,AC-Foley(w/o audio)也达到或接近SOTA水平(FDPaSST 64.90)。在音色迁移任务(Greatest Hits数据集)上,即使未在此数据集训练,AC-Foley的MCD(3.39)也显著优于CondFoley(4.18)。人工评估显示,在声学保真度上,83.5%的参与者认为AC-Foley生成的音频更接近真实音频。
- 实际意义是什么:为影视、游戏、动画等内容创作者提供了强大的音效设计工具,能够根据示例音频快速生成、修改或替换音轨中的声音元素,极大提升了创作灵活性和效率。
- 主要局限性是什么:当输入视频和参考音频包含多个重叠声源(如对话、环境声、动作声混合)时,模型难以将特定声音元素与对应的视觉事件精确对齐。参考音频与视频内容节奏差异过大时,生成质量会下降。
🏗️ 模型架构
整体架构是一个基于条件流匹配(Conditional Flow Matching) 的多模态Transformer模型,旨在生成与视频同步、受参考音频和文本条件控制的梅尔谱图,最终通过声码器转换为波形。
完整输入输出流程:
输入:静音视频 V、参考音频 Ac、文本提示 T。
输出:生成的音频 At(与视频前8秒同步,时长由条件音频 Ac 指定)。
主要组件及数据流:
- 编码器:
- 视频编码器:采用CLIP视觉编码器,提取视频片段的语义特征。
- 文本编码器:采用CLIP文本编码器,提取文本提示的语义特征。
- 音频编码器:采用预训练的VAE编码器。它接收原始音频波形,通过STFT和梅尔频谱计算,输出紧凑的声学潜在表示(
x1)。此编码器是关键,它保留了参考音频的完整声学特征(频谱/音色),而非仅语义信息。 - 同步特征提取器:使用Synchformer,以24 fps提取视频帧级的同步特征,然后通过最近邻插值重采样以匹配音频潜在表示的时间帧率。
- 多模态条件向量
c的构建:- 将文本特征、视频特征、条件音频潜在表示分别进行平均池化,得到各自的向量。
- 从Synchformer获得的同步特征也进行时间维度的平均池化。
- 上述所有向量与流时间步
t的傅里叶编码相连接(Concatenation),形成统一的多模态条件向量c(维度1×h)。这向量注入了语义、时序和声学信息。
- 生成模型(多模态Transformer):
- 由7个多模态块和14个单模态块组成,隐藏维度为896。
- 条件向量
c通过自适应层归一化(adaLN) 层调制Transformer各块的输入特征f:adaLN(f, c) = LayerNorm(f) · Wγ(c) + Wβ(c),其中Wγ和Wβ是MLP。 - 模型学习在噪声
xt和多模态条件c下预测速度场vθ,通过流匹配目标进行训练。
- 解码与声码器:
- 生成过程的输出是音频潜在表示,通过VAE解码器映射回梅尔谱图。
- 梅尔谱图通过预训练的BigVGAN声码器转换为44.1kHz的音频波形。
架构图(对应原文图2):
 图2展示了多模态Transformer如何整合视频、文本和条件音频的信息。条件音频通过VAE编码器处理,提取完整的声学特征(而非仅语义),与文本、视频及同步特征一起构建多模态条件向量
图2展示了多模态Transformer如何整合视频、文本和条件音频的信息。条件音频通过VAE编码器处理,提取完整的声学特征(而非仅语义),与文本、视频及同步特征一起构建多模态条件向量 c,通过adaLN注入Transformer。
关键设计选择及其动机:
- 直接使用VAE编码参考音频而非CLAP:动机是CLAP主要提取语义信息,会丢失微声学细节。直接用VAE编码能保留频谱、音色等完整声学签名,实现细粒度控制。
- 使用Synchformer提取同步特征:为确保生成音频的事件与视频动作在帧级别对齐。
- 两阶段训练:动机是防止模型简单“复制”条件音频。重叠阶段学习特征提取,非重叠阶段学习在时序上应用这些特征,迫使模型理解声学特征与视频上下文的自相似性。
💡 核心创新点
- 参考音频条件控制范式:
- 是什么:将一段参考音频的声学特征作为直接条件信号,引导生成。
- 之前局限:现有方法主要依赖文本或视频语义控制,无法精确指定“什么样的狗叫”或“什么材质的脚步声”。
- 如何起作用:通过预训练VAE编码参考音频,保留其频谱和音色信息,与视频/文本特征融合后,指导流匹配模型生成具有目标声学特性的音频。
- 收益:实现了细粒度声音合成、音色迁移和零样本生成(图1)。实验上,MCD指标(衡量声学保真度)显著提升(表1)。
- 两阶段训练策略(重叠与非重叠条件学习):
- 是什么:第一阶段使用与目标音频时间重叠的片段作为条件;第二阶段使用非重叠片段作为条件。
- 之前局限:单一阶段训练可能导致模型退化:仅重叠训练会复制条件音;仅非重叠训练缺乏对齐监督,特征利用不充分。
- 如何起作用:第一阶段(图3a)提供强监督,让模型学会提取和匹配声学特征。第二阶段(图3b)利用视频内声音的自相似性(如重复动作),迫使模型在新的时序上下文中应用已学特征。
- 收益:消融实验(表4)显示,两阶段训练使FDPaSST从80.07降至56.00(↓30.1%),同时保持了其他指标,证明了策略的有效性。
- 统一的多模态条件注入机制:
- 是什么:通过构建统一的多模态条件向量
c,将文本、视频、条件音频和同步特征的信息通过adaLN层共同调制生成过程。 - 之前局限:部分方法只使用部分模态,或控制方式割裂(如只用文本控制语义,用其他机制控制时序)。
- 如何起作用:使模型能同时考虑语义一致性、声学特性和时序对齐,所有信息在Transformer内部深度交互。
- 收益:消融实验(表6)表明,移除任何模态(音频、同步、视频、文本)都会导致特定维度的性能下降,而完整模型取得最佳整体性能。
- 是什么:通过构建统一的多模态条件向量
🔬 细节详述
- 训练数据:
- 音频-视频-文本数据:VGGSound(约180K个10秒视频)。
- 音频-文本数据:AudioCaps2.0(约98K带人工描述的10秒音频)和WavCaps(约7600小时带自动描述的音频,截取为10秒片段)。总计约60万对音频-文本数据。
- 微调数据:使用ImageBind分数>0.3筛选的VGGSound高质量子集。
- 损失函数:条件流匹配目标(公式1):
Et,q(x0),q(x1,C)∥vθ(t, C, xt) −(x1 −x0)∥2。即最小化模型预测的速度场与实际��度场(x1 - x0)之间的均方误差。 - 训练策略:
- 优化器:AdamW。
- 学习率:初始
1e-4,前1K步线性预热,在200K步后衰减至1e-5,在240K步后衰减至1e-6。 - 批次大小:320。
- 总训练步数:260K迭代。
- 精度:bfloat16混合精度。
- 稳定化技巧:使用指数移动平均(EMA),相对宽度参数
σ_rel = 0.05。 - 微调:在高质量VGGSound子集上进行40K次迭代微调。
- 关键超参数:
- 生成音频:44.1kHz。
- 音频潜在表示:40维,43.07帧/秒。
- Transformer:7个多模态块 + 14个单模态块,隐藏维度896。
- 训练硬件与耗时:8块NVIDIA H800 GPU,训练约26小时。
- 推理细节:未提供具体解码温度、beam size等参数。生成时,条件音频被替换为学习到的空嵌入(null embedding)以支持无条件生成。
📊 实验结果
主要实验与指标(来自表1):
| 方法 | 分布匹配 (FD PaSST↓) | 分布匹配 (FD PANNs↓) | 分布匹配 (FD VGG↓) | 分布匹配 (KL PaSST↓) | 分布匹配 (KL PANNs↓) | 语义 (IB↑) | 时序 (DeSync↓) | 时序 (Onset Acc.↑) | 时序 (Onset AP↑) | 频谱 (MCD↓) |
|---|---|---|---|---|---|---|---|---|---|---|
| 有音频条件 | ||||||||||
| Video-Foley | 613.05 | 73.17 | 17.45 | 4.16 | 4.75 | 3.6 | 1.214 | 0.2146 | 0.3409 | 17.41 |
| MMAudio + Clap | 70.80 | 7.95 | 4.33 | 1.17 | 1.36 | 35.7 | 0.431 | 0.2511 | 0.5107 | 14.63 |
| AC-Foley (ours) | 56.00 | 4.93 | 1.08 | 0.84 | 0.95 | 37.1 | 0.465 | 0.2832 | 0.5317 | 11.37 |
| 无音频条件 | ||||||||||
| MMAudio-L-V2 | 69.25 | 8.81 | 3.98 | 1.12 | 1.34 | 37.8 | 0.392 | 0.2816 | 0.5257 | 14.11 |
| AC-Foley (w/o audio) | 64.90 | 8.59 | 3.87 | 1.17 | 1.34 | 36.6 | 0.410 | 0.2619 | 0.5095 | 14.59 |
表1:视频到音频生成方法的定量比较。加粗为最佳,下划线为次佳。
关键结论:在音频条件下,AC-Foley在所有分布匹配(FD/KL)、语义(IB)和频谱(MCD)指标上均大幅优于基线。在无音频条件设置下,AC-Foley(w/o audio)性能与顶尖的MMAudio-L-V2相当或略优。
音色迁移实验(来自表2):
| 方法 | Onset Acc.↑ | Onset AP↑ | MCD↓ |
|---|---|---|---|
| CondFoley | 0.3906 | 0.6611 | 4.18 |
| AC-Foley (ours) | 0.3948 | 0.6629 | 3.39 |
表2:在Greatest Hits数据集上的音色迁移定量比较。注意CondFoley在该数据集上训练,而AC-Foley没有。
关键结论:AC-Foley在未在目标数据集训练的情况下,在音色迁移任务上取得了更优的声学保真度(MCD↓)。
人工评估结果(来自表3):
| 比较 | 时间对齐 | 声学保真度 | |
|---|---|---|---|
| 胜率 (%) | 平局率 (%) | 胜率 (%) | |
| AC-Foley vs MMAudio-L-V2 | 61.1 (±4.3) | 21.8 (±3.6) | 83.5 (±3.4) |
表3:人工研究结果比较。
关键结论:在声学保真度上,AC-Foley具有压倒性优势(83.5%胜率)。在时间对齐上,由于两者都表现良好,参与者常难以抉择,但AC-Foley仍有微弱优势。
消融实验关键结论(表4,表5,表6):
- 两阶段训练(表4):非重叠条件学习(第二阶段)相比仅重叠学习(第一阶段),使FDPaSST从80.07降至56.00,证明其能有效防止复制粘贴并促进泛化。
- 平均池化(表5):与注意力池化相比,性能相当,但更稳定、计算成本更低,且能保留关键声学特征。
- 模态必要性(表6):移除同步特征(w/o sync)导致DeSync剧增(1.240);移除音频条件(w/o audio)导致频谱失真(MCD↑)和分布匹配变差。证明多模态信息互补且必要。
实验结果图表:
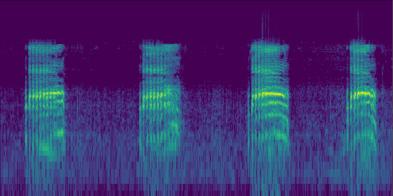 图4:带音频条件的Foley生成定性示例。展示了模型根据不同的条件音频,为同一段静音视频(狗跑、开枪)生成具有不同声学特性的同步音频,直观体现了音色控制能力。
图4:带音频条件的Foley生成定性示例。展示了模型根据不同的条件音频,为同一段静音视频(狗跑、开枪)生成具有不同声学特性的同步音频,直观体现了音色控制能力。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性(良好):明确提出了基于参考音频的控制范式来解决现有文本控制的瓶颈,并设计了针对性的两阶段训练策略。创新点清晰、实用。
- 技术正确性(高):模型架构和训练方法基于成熟技术(Transformer, Flow Matching, VAE, CLIP),整合逻辑正确,实验验证了其有效性。
- 实验充分性(高):与大量SOTA基线对比,评估指标全面,消融实验详细,覆盖了有/无条件控制、音色迁移等多种场景。
- 证据可信度(高):定量数据(表1-3)与定性示例(图4)相互印证,人工评估进一步支持了主要结论。
- 选题价值:2.0/2
- 前沿性:精准切入多模态生成中的“可控性”这一核心前沿问题。
- 潜在影响:为内容创作行业提供了实用的工具级创新,有明确的落地场景。
- 读者相关性:对音频生成、多模态学习、计算音频等领域的研究人员和工程师价值很高。
- 开源与复现加成:0.5/1
- 论文未提及代码、模型权重或专用数据集的开源计划。
- 然而,其提供的复现细节(训练配置、网络参数、两阶段策略详述)在同类论文中属于非常详尽的水平,极大降低了复现门槛,因此给予小幅正向加成。