📄 A Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers
#生成模型 #扩散模型 #多模态模型 #模型评估
✅ 6.5/10 | 前50% | #生成模型 | #扩散模型 | #多模态模型 #模型评估
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Trung X. Pham (韩国科学技术院 KAIST)
- 通讯作者:Chang D. Yoo (韩国科学技术院 KAIST)
- 作者列表:Trung X. Pham (韩国科学技术院 KAIST)、Kang Zhang (韩国科学技术院 KAIST)、Ji Woo Hong (韩国科学技术院 KAIST)、Chang D. Yoo (韩国科学技术院 KAIST)
💡 毒舌点评
这篇论文以系统性的实验揭开了扩散Transformer条件嵌入的“假满汉全席”——看似丰盛的1152维向量里,99%都是“凑数”的摆设,证明了模型在条件表达上存在惊人的冗余。遗憾的是,论文止步于“发现并解释现象”,未能将此洞察转化为一个新的、更高效的条件注入架构,更像是给Transformer扩散模型做了一次精确诊断却没开出新药方。
🔗 开源详情
- 代码:论文中未提及分析代码的开源仓库链接。
- 模型权重:论文分析所用模型权重为公开发布的预训练权重(如DiT, REPA等),论文本身未发布新模型。
- 数据集:使用公开数据集ImageNet-1K, DeepFashion, VGGSound。
- Demo:未提供在线演示。
- 复现材料:附录(Appendix)提供了更详细的实验设置、额外可视化(如t-SNE图、更多剪枝结果)和分析,但未提供具体的代码或配置文件。
- 论文中引用的开源项目:引用了多个SOTA模型的官方代码库(DiT, MDT, SiT, LightningDiT, MG, REPA, X-MDPT, MDSGen)。
📌 核心摘要
- 解决的问题:扩散Transformer(如DiT, MDT等)通过自适应层归一化(AdaLN)注入条件向量(如类别、姿态),但这些高维向量内部的结构与信息编码方式尚不明确。
- 方法核心:对多个SOTA扩散Transformer的预训练条件嵌入进行系统性分析,量化其成对余弦相似度、幅度分布和维度贡献度(参与率PR),并通过剪枝实验验证其冗余性。
- 新意:首次系统揭示了扩散Transformer条件嵌入的两个反直觉涌现特性:1) 极端相似性(离散任务>99%, 连续任务>99.9%);2) 极端稀疏性(仅约1-2%的维度携带主要语义信息)。这与对比学习中的特征坍塌不同,且未损害生成质量。
- 主要结果:
- 在ImageNet-1K上,6个SOTA模型的条件向量两两余弦相似度在90%-99.5%之间(如REPA为99.46%)。
- 在DeepFashion(姿态生成)和VGGSound(视频转音频)上,相似度超过99.98%。
- 条件向量的有效维度(参与率PR)极低。例如,REPA模型在1152维中仅有约17.67个有效维度(nPR=1.53%)。
- 关键消融:以REPA为例,剪枝绝对值低于阈值τ=0.02的尾部维度(移除762维,占66.21%),FID仅从7.1694微升至9.2202,而CLIP分数下降有限(29.746->29.221)。在τ=0.01时(移除38.94%),性能基本保持不变。
- 反之,移除少量高幅度“头部”维度(如8维)会严重破坏生成质量(FID>500)。
| 模型/方法 | 数据集 | 指标 (FID↓ / IS↑ / CLIP↑) |
|---|---|---|
| REPA (基线) | ImageNet-1K | 7.1694 / 176.02 / 29.746 |
| REPA (剪枝 τ=0.01, t0) | ImageNet-1K | 7.1690 / 175.97 / 29.807 |
| REPA (剪枝 τ=0.02, ti) | ImageNet-1K | 9.2202 / 125.15 / 29.221 |
| REPA (剪枝 τ=5.0, ti,移除头部) | ImageNet-1K | 356.135 / 1.77 / 21.922 |
 图8:不同阈值τ剪枝尾部维度后的生成图像。即使剪枝高达80%以上(τ=0.03),图像质量仍与基线REPA(τ=0)相当。
图8:不同阈值τ剪枝尾部维度后的生成图像。即使剪枝高达80%以上(τ=0.03),图像质量仍与基线REPA(τ=0)相当。
- 实际意义:揭示了扩散Transformer在条件编码上存在严重的过参数化,为设计更轻量、高效的条件注入机制(如使用稀疏向量、或只保留关键维度)提供了直接依据和理论洞察。
- 主要局限性:论文以分析和现象揭示为主,未提出一种新的、基于此发现的条件编码架构或训练方法;对于“为何高相似度仍能生成正确结果”的深层机理,仍停留在假设层面。
🏗️ 模型架构
本文并非提出新模型,而是系统分析现有扩散Transformer架构(DiT, MDT, SiT, LightningDiT, MG, REPA)的条件嵌入。其核心分析对象是这些模型中通过自适应层归一化(AdaLN) 注入的全局条件向量 c。
- 输入与流程:条件向量
c通常由学习到的类嵌入(或连续条件嵌入)与时间步嵌入相加得到。该向量c作为一个低维(相对Transformer隐藏层)的全局信号,被用于调制Transformer每一层的隐藏状态。 - AdaLN机制:这是理解论文发现的关键。给定隐藏状态
h,AdaLN计算为:AdaLN(h | c) = γ(c) ⊙ (h - μ(h))/σ(h) + β(c)。其中γ(c)和β(c)是通过线性投影W_γ c和W_β c得到的缩放和偏移参数。论文指出,正是这种全局线性投影机制,使得语义信息可以被压缩到c的少数几个维度上。 - 交互方式:
c是每个去噪步骤中所有Transformer层共享的、全局恒定的输入,不参与序列内的注意力计算,而是独立地调制每一层的特征。
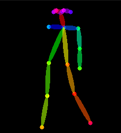 图2:展示了Transformer扩散模型如何通过AdaLN将紧凑的条件向量
图2:展示了Transformer扩散模型如何通过AdaLN将紧凑的条件向量 v (对应论文中的 c) 注入到生成过程中。
💡 核心创新点
- 首次系统量化扩散Transformer条件嵌入的极端相似性:跨越多个SOTA模型和任务(图像生成、姿态生成、音频生成),揭示条件向量在向量空间中几乎平行的现象。这挑战了“不同语义条件应对应差异明显嵌入”的直觉。
- 揭示条件嵌入的极端稀疏性与“头尾”结构:发现语义信息高度集中于少数(约1-2%)高幅度维度(“头部”),而绝大多数维度幅值接近于零(“尾部”)。通过参与率(PR)等指标进行了严格量化。
- 通过剪枝实验证实并利用冗余性:通过破坏性实验(移除头部维度)和保留性实验(移除尾部维度),证明了尾部维度的冗余性。特别是,激进地剪枝超过2/3的条件维度仍能维持甚至轻微提升生成质量,为高效推理提供了可能。
🔬 细节详述
- 训练数据:论文分析基于现有SOTA模型的公开预训练权重,主要使用ImageNet-1K进行类条件生成分析。连续条件任务使用了DeepFashion(姿态生成)和VGGSound(视频转音频)。
- 损失函数:未说明。论文专注于分析已有模型,未涉及训练过程。
- 训练策略:未说明。使用各模型的官方公开权重。
- 关键超参数:分析的核心超参数是剪枝阈值 τ。例如,τ=0.01用于移除低幅度维度。此外,论文定义了归一化参与率(nPR) 和稀疏比率来量化有效维度。
- 训练硬件:未说明。
- 推理细节:在剪枝实验中,推理时对条件向量
c应用剪枝操作(将绝对值低于τ的维度置零),然后输入到原始的、未修改的扩散Transformer中进行生成。论文比较了在不同推理步数应用剪枝的效果(t0:仅初始步, ti:每一步, tn-k,n:最后k步)。 - 正则化或稳定训练技巧:未说明,但论文观察到条件向量的稀疏性在训练过程中逐渐增强(如图12所示)。
📊 实验结果
- 余弦相似度分析
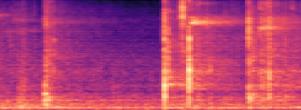 图3:REPA模型在ImageNet-1K上1000个类条件向量的两两余弦相似度矩阵(左)及10个类的放大视图(右)。对角线外的值普遍高于0.99。
图3:REPA模型在ImageNet-1K上1000个类条件向量的两两余弦相似度矩阵(左)及10个类的放大视图(右)。对角线外的值普遍高于0.99。
表1:不同模型与任务下的条件嵌入指标对比
| 模型 | 条件维度(d) | 参与率(PR) | 归一化参与率(nPR) | 余弦相似度(cs) | 任务类型 |
|---|---|---|---|---|---|
| DiT | 1152 | 120.69 | 10.47% | 0.9001 | 类条件 |
| SiT | 1152 | 26.25 | 2.28% | 0.9852 | 类条件 |
| MDT | 1152 | 18.45 | 1.60% | 0.9905 | 类条件 |
| LightningDiT | 1152 | 23.70 | 2.05% | 0.9779 | 类条件 |
| MG | 1152 | 19.98 | 1.73% | 0.9934 | 类条件 |
| REPA | 1152 | 17.67 | 1.53% | 0.9946 | 类条件 |
| X-MDPT | 1024 | 495.75 | 48.42% | 0.9998 | 连续条件 |
| MDSGen | 768 | 104.22 | 13.57% | 0.9999 | 连续条件 |
- 剪枝实验(核心结果)
表2:REPA模型在ImageNet-1K上的剪枝实验结果
| 剪枝类型 | 阈值 τ | 移除维度数(比例) | FID↓ | IS↑ | CLIP↑ |
|---|---|---|---|---|---|
| 基线 (无剪枝) | - | 0/1152 (0%) | 7.1694 | 176.02 | 29.746 |
| 尾部剪枝 | τ=0.01 (ti) | 448/1152 (38.94%) | 7.2143 | 171.99 | 29.737 |
| 尾部剪枝 | τ=0.01 (t0) | 448/1152 (38.94%) | 7.1690 | 175.97 | 29.807 |
| 尾部剪枝 | τ=0.01 (tn-k,n) | 448/1152 (38.94%) | 7.1598 | 175.49 | 29.805 |
| 尾部剪枝 | τ=0.02 (ti) | 762/1152 (66.21%) | 9.2202 | 125.15 | 29.221 |
| 尾部剪枝 | τ=0.05 (ti) | 1110/1152 (96.41%) | 56.2308 | 20.47 | 22.177 |
| 头部剪枝 | τ=5.0 (ti) | 2/1152 (0.20%) | 7.8478 | 164.15 | 29.555 |
| 头部剪枝 | τ=1.0 (ti) | 8/1152 (0.69%) | 523.7637 | 1.95 | 22.690 |
 图7:移除头部维度(高幅度)后的生成结果。仅移除极少数(如2-8个)头部维度就导致质量急剧下降。
图7:移除头部维度(高幅度)后的生成结果。仅移除极少数(如2-8个)头部维度就导致质量急剧下降。
- 方差分析
 图9:不同模型条件向量各维度的方差分布。方差高度集中在前15-20个“头部”维度,进一步证实语义信息集中。
图9:不同模型条件向量各维度的方差分布。方差高度集中在前15-20个“头部”维度,进一步证实语义信息集中。
- 其他模型剪枝验证
表3:LightningDiT和MG模型的尾部剪枝结果
| 模型 | 剪枝设置 | FID↓ | CLIP↑ |
|---|---|---|---|
| MG 基线 | 0/1152 (0%) | 7.2478 | 30.199 |
| MG 剪枝 (τ=0.01, tn-k,n) | 448/1152 (38.94%) | 7.2455 | 30.198 |
| LightningDiT 基线 | 0/1152 (0%) | 7.0802 | 30.720 |
| LightningDiT 剪枝 (τ=0.01, tn-k,n) | 448/1152 (38.94%) | 7.0745 | 30.729 |
⚖️ 评分理由
- 学术质量:5.5/7。论文对一个重要但被忽视的现象进行了全面、严谨的实证分析,实验设计合理,证据链清晰(从相似度、稀疏性到剪枝验证)。然而,核心贡献是现象发现与分析,而非提出解决新问题的新方法或新理论,因此创新性维度得分中等。
- 选题价值:1.0/2。选题具有前沿性,直指当前主流生成模型核心组件的内部机制,揭示的冗余性对提升效率有明确价值。但该研究偏向模型诊断,与直接的语音/音频任务应用相关性较弱(尽管分析了音频生成模型),潜在影响力需要后续工作来落地。
- 开源与复现加成:0.0/1。论文使用了公开预训练模型进行分析,但未提供其分析代码、剪枝脚本或任何复现所需的工具。复现其分析过程需要读者自行获取模型权重并重写分析代码,门槛较高。