📄 A Brain-Inspired Gating Mechanism Unlocks Robust Computation in Spiking Neural Networks
#脉冲神经网络 #音频分类 #鲁棒性 #神经形态计算
✅ 7.0/10 | 前25% | #音频分类 | #脉冲神经网络 | #鲁棒性 #神经形态计算
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Qianyi Bai(天津大学智能与计算学院,天津大学计算机科学与技术学院)
- 通讯作者:Qiang Yu(天津大学智能与计算学院,认知计算与应用天津市重点实验室)
- 作者列表:Qianyi Bai(天津大学智能与计算学院,天津大学计算机科学与技术学院)、Haiteng Wang(天津大学智能与计算学院,天津大学未来技术学院)、Qiang Yu(天津大学智能与计算学院,通讯作者)
💡 毒舌点评
亮点:论文成功地将生物神经元中“动态电导”这一相对复杂的生理现象,抽象并简化为一个可计算、可训练的“门控机制”,并用令人信服的实验(尤其是广泛的噪声和对抗攻击测试)证明了它在提升SNN鲁棒性上的显著效果。短板:虽然与LIF等基础SNN模型对比充分,但与更近期、同样旨在提升SNN性能和鲁棒性的复杂模型(如文中提到的HetSyn、TC-LIF等)的对比,有时仅在特定设置下(如参数量更少)占优,在绝对性能上并未全面碾压,其“通用最优”的结论有待更广泛验证。
🔗 开源详情
- 代码:论文中未直接提供代码仓库链接。但致谢中提及工作部分由小米基金会支持,且在实验部分多次提到“reproduced using public code”,暗示基线代码可能来源于公开实现。DGN本身的实现细节已在附录伪代码(算法1)和超参数表(表5)中充分公开。
- 模型权重:未提及是否公开训练好的模型权重。
- 数据集:实验所用数据集(Ti46Alpha, TIDIGITS, SHD, SSC)均为学术界公开的标准基准,论文未提供自有数据集。
- Demo:未提及在线演示。
- 复现材料:非常充分。附录A.1-A.5包含了完整的数学推导、模型伪代码、所有实验的详细超参数设置、噪声/攻击生成算法、以及大量未在正文中完全展示的实验结果表格(表11-16)。
- 论文中引用的开源项目:论文未明确列出其依赖的特定开源代码库或工具。但基线模型的复现可能基于了社区已有的SNN实现(如SpikingJelly等,但论文未明确说明)。
📌 核心摘要
- 解决的问题:传统脉冲神经网络(SNN)使用的漏积分发放(LIF)神经元模型过于简化,忽略了生物神经元中动态的离子通道电导调节机制,导致其处理噪声和时序变化的能力有限,鲁棒性不足。
- 方法核心:提出了一种新型的动态门控神经元(DGN)模型。其核心是在神经元膜电位的更新方程中,引入了依赖于突触输入活动的动态电导项(C_i * D_i),该项与固有的泄漏电导(g_l)共同构成一个“门控”因子,动态调节膜电位的衰减速率。
- 与已有方法相比新在哪里:与静态参数(如LIF)或引入静态可学习门控(如GLIF)的SNN模型不同,DGN的门控机制是动态的、输入依赖的、且直接源于生物电导调节原理。论文还首次从理论上将这种动态电导与LSTM中的门控机制进行了类比和功能映射。
- 主要实验结果:DGN在多个语音分类数据集(Ti46Alpha, TIDIGITS, SHD, SSC)上取得了有竞争力的准确率。关键鲁棒性结果(见表2):在TIDIGITS数据集上,前馈DGN在加性噪声(p=0.006)下准确率为95.34%,而LIF仅为46.83%;在PGD攻击(ε=0.003)下,DGN准确率为86.76%,LIF为15.39%。DGN在多种噪声和攻击下均展现出显著优于LIF、ALIF、HeterLIF以及RNN/LSTM的鲁棒性。
- 实际意义:为构建更鲁棒、更能适应非理想环境(如含噪声的传感器输入)的神经形态计算系统提供了新的神经元模型设计范式,有助于推动SNN在边缘计算、低功耗设备等实际场景中的应用。
- 主要局限性:模型的计算开销和参数量(见表3)相比标准LIF有所增加;论文主要聚焦于语音分类任务,在视觉等其他脉冲神经网络典型应用场景下的泛化性未得到验证;动态电导机制引入的额外超参数(如τ_s, C_i)可能增加调优难度。
🏗️ 模型架构
论文提出的动态门控神经元(DGN)模型是对标准LIF神经元的扩展,其核心架构在于修改了膜电位的更新动力学,引入了动态的突触后电导。
完整输入输出流程: 输入为离散的时间脉冲序列 \( z_t^i \)。DGN模型在每个时间步t,首先更新每个突触的动态变量 \( D_t^i \)(式5),该变量反映了突触输入的历史整合(带有指数衰减)。然后,计算一个动态的“衰减因子” \( \rho_t \)(式6),它由固定的泄漏电导 \( g_l \) 和所有突触的动态电导贡献(\( C_i D_t^i \))共同决定。膜电位 \( V_t \) 的更新(式7)依赖于这个动态衰减因子、来自突触的输入电流(\( W_i D_t^i \))以及上一次的发放重置。最后,通过阈值判断产生输出脉冲 \( z_t \)(式8)。
主要组件与功能:
- 动态突触变量 \( D_t^i \):功能类似一个带时间常数 \( \tau_s \) 的指数衰减滤波器,用于整合第i个突触的历史脉冲输入。这是动态电导的基础。
- 动态门控因子 \( \rho_t \):这是模型的核心创新。它计算为 \( \phi(1 - g_l \Delta t - \Delta t \sum_i C_i D_t^i) \),其中 \( \phi \) 是截断函数(如Sigmoid)。该项将膜电位的衰减率从LIF中的固定值 \( e^{-g_l \Delta t} \) 变为一个由当前输入活动(通过 \( D_t^i \))动态调制的变量。直观上,当突触输入活跃时,总电导增大,\( \rho_t \) 减小,膜电位衰减加快,实现了对强输入的“门控”或抑制。
- 输入电流通路 \( W_i D_t^i \):这是向神经元胞体注入电流的路径,与LIF模型类似,但电流大小也受动态变量 \( D_t^i \) 调制。
- 膜电位更新与发放重置:\( V_t = \rho_t V_{t-1} + \Delta t \sum_i W_i D_t^i - \vartheta z_{t-1} \)。这结合了动态衰减、输入电流和硬/软重置。
组件间的数据流与交互: 输入脉冲序列首先被转换为一系列动态突触变量 \( D_t^i \)。这些 \( D_t^i \) 同时用于: a) 计算动态门控因子 \( \rho_t \)(路径1:调制衰减)。 b) 计算输入电流通路 \( W_i D_t^i \)(路径2:驱动去极化)。 这两个路径在膜电位更新方程中汇合。\( \rho_t \) 控制了前一时刻膜电位的“遗忘”或保持程度,而输入电流则提供新的信息。这模仿了生物神经元中电导同时影响膜时间常数和驱动电流的双重作用。
关键设计选择及其动机:
- 引入 \( C_i \) 作为可学习参数:动机是让每个突触不仅能影响输入电流强度(通过 \( W_i \)),还能影响其对膜电位衰减的调制强度,从而实现更精细的门控。
- 使用 \( \phi \) 截断函数:确保 \( \rho_t \) 在合理范围内(如0到1),使衰减过程稳定。
- 与LSTM的类比(如图2所示):论文明确指出,\( \rho_t \) 的功能类似于LSTM中的遗忘门 \( f_t \),而 \( \sum_i W_i D_t^i \) 类似于输入门 \( i_t \)。这为SNN模型引入门控提供了生物可解释性视角。
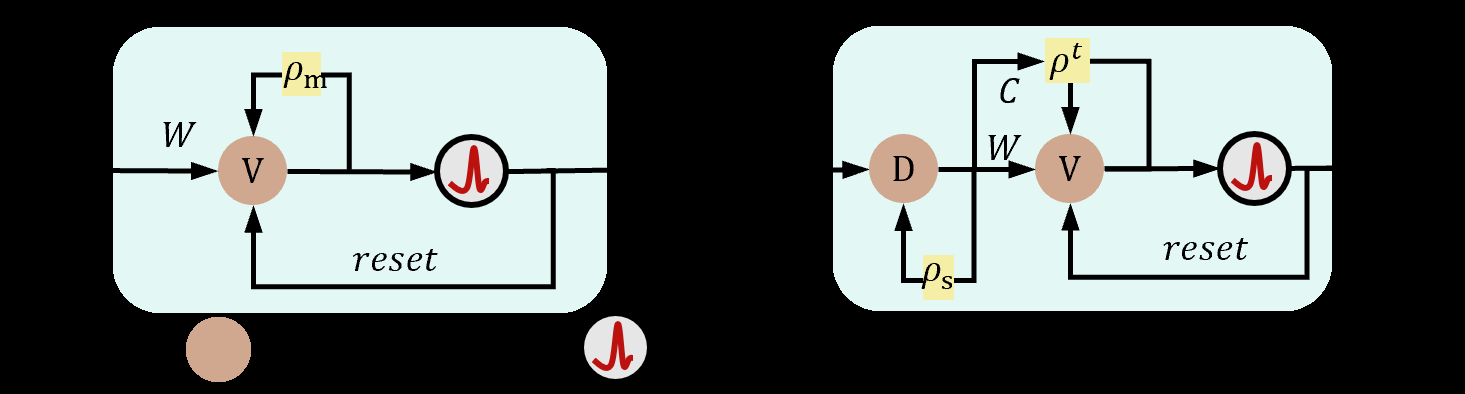 图1清晰展示了LIF和DGN模型的结构差异。LIF(a)具有固定的泄漏电导 \( g_l \)。DGN(b)则引入了由突触活动调制的动态电导项 \( \sum C_i D_i \),形成了动态的门控因子 \( \rho \),从而根据输入动态自适应地调节膜电位衰减。
图1清晰展示了LIF和DGN模型的结构差异。LIF(a)具有固定的泄漏电导 \( g_l \)。DGN(b)则引入了由突触活动调制的动态电导项 \( \sum C_i D_i \),形成了动态的门控因子 \( \rho \),从而根据输入动态自适应地调节膜电位衰减。
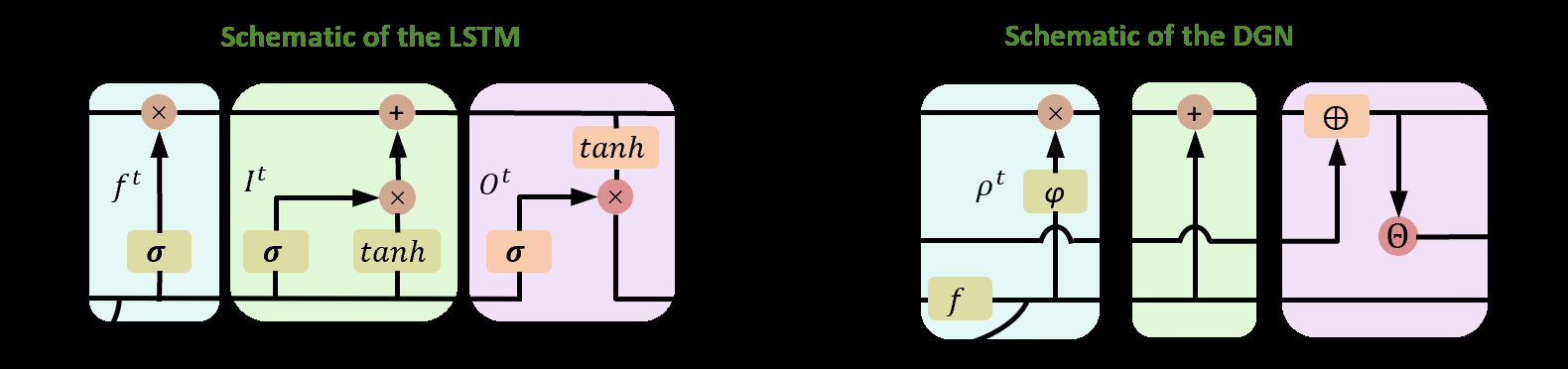 图2直观地建立了DGN与LSTM在信息处理机制上的同构性。DGN的自适应衰减系数(源于动态电导)类比LSTM的遗忘门,动态突触电流累积类比输入门,而尖峰重置机制与LSTM的细胞状态更新方程在数学上对应。
图2直观地建立了DGN与LSTM在信息处理机制上的同构性。DGN的自适应衰减系数(源于动态电导)类比LSTM的遗忘门,动态突触电流累积类比输入门,而尖峰重置机制与LSTM的细胞状态更新方程在数学上对应。
💡 核心创新点
提出动态门控神经元(DGN)模型:这是核心创新。它将生物神经元中动态的离子通道电导调节机制,抽象并实现为一个可微分、可训练的计算单元。通过引入输入依赖的电导项 \( C_i D_t^i \),使神经元的衰减特性能够根据输入历史动态调整,从而实现了自适应的信息过滤和噪声抑制。
- 之前局限:传统LIF等模型使用固定或静态可学习的衰减常数,无法根据输入内容动态调整神经元的时间整合特性。
- 如何起作用:动态电导项增大了有效膜电导,加快了膜电位衰减,使得神经元对持续强输入或噪声的响应更倾向于“重置”,而非累积,从而增强了抗干扰能力。
- 收益:在理论分析(式13)和实验中(表2,图4)均证明,DGN比LIF等模型在噪声和对抗攻击下具有显著更高的准确率。
揭示动态电导作为生物门控机制的功能本质:论文不仅提出了模型,更从功能角度阐释了其生物合理性。将动态电导明确与LSTM的门控机制建立联系,指出这可能是生物神经计算中一种普适的信息调控原理。
- 之前局限:生物启发的SNN模型往往只追求生物细节的还原,而忽略了对功能原理的抽象和利用。
- 如何起作用:通过理论分析和与人工门控网络的类比,将动态电导重新诠释为一种“门控”操作,为SNN模型设计提供了新的理论依据。
- 收益:提升了DGN模型的可解释性,并为未来设计更复杂的类脑门控机制铺平了道路。
提供理论鲁棒性保证并进行系统性实证:论文不仅通过实验展示了优越性,还通过随机微分方程(SDE)分析(式13 vs 式14),从理论上推导出DGN的稳态电压方差小于LIF,揭示了其噪声抑制能力的内在机理。同时,实验设计严谨(在干净数据上训练,在未见噪声/攻击上测试),对比全面。
- 之前局限:许多SNN鲁棒性工作侧重于训练技巧或特定结构修改,缺乏对神经元模型本身鲁棒性来源的理论分析。
- 如何起作用:理论分析表明,动态电导引入了自适应的泄漏缩放和突触噪声补偿两种机制,共同降低了电压波动。
- 收益:为DGN的优越性能提供了理论支撑,增强了论文的说服力和学术深度。
🔬 细节详述
- 训练数据:
- 数据集:Ti46Alpha(英文语音字母,4142/6628样本),TIDIGITS(数字语音,2464/2486样本),SHD(Heidelberg脉冲数字,8332/2088样本),SSC(Google语音命令脉冲,75466/20382样本)。
- 来源:均为公开数据集,具体获取链接未提供。
- 预处理:对Ti46Alpha和TIDIGITS,使用梅尔滤波器组将音频转换为脉冲序列(500输入通道)。对SHD和SSC,使用事件相机传感器(CochleaAMS1b)编码的脉冲数据,并进行了时间分辨率降低(聚合时间窗),约250时间步。
- 数据增强:论文中未提及使用数据增强。
- 损失函数:使用交叉熵损失函数,作用于整个时间序列输出的平均值 \( y_{pred} = \frac{1}{T} \sum_{t=1}^T o_t \)。
- 训练策略:
- 优化器:Adam优化器。
- 学习率:Ti46Alpha和TIDIGITS为0.001;SHD和SSC为0.001。
- 训练轮数:Ti46Alpha和TIDIGITS为64个epoch;SHD和SSC为128个epoch。
- Batch Size:论文中未说明。
- Warmup/调度策略:论文中未说明。
- 关键超参数:
- 网络结构:通常为单隐藏层的前馈或循环网络。具体隐藏层大小见表1(如Ti46Alpha/TIDIGITS为100,SHD/SSC为128或128-128)。
- 膜时间常数 \( \tau_m \)(用于计算 \( \rho_m = e^{-\Delta t / \tau_m} \))、突触时间常数 \( \tau_s \)、阈值 \( \vartheta \)、参数初始化范围 \( (c, w) \):详见附录表5,随数据集和网络类型(前馈/循环)变化。
- 训练硬件:前馈网络使用NVIDIA GeForce RTX 4060 (8GB) GPU;循环网络使用NVIDIA GeForce RTX 4090 (24GB) GPU。未提供具体训练时长。
- 推理细节:基于脉冲的推理,循环网络使用标准BPTT进行训练。输出基于所有时间步的平均。
- 正则化或稳定训练技巧:论文中未提及使用Dropout等显式正则化。使用替代梯度(surrogate gradient)处理脉冲函数的不可导问题。
📊 实验结果
主要Benchmark与结果: 论文在四个语音相关数据集上评估了DGN的性能,与多种SNN基线(LIF, HeterLIF, ALIF)和ANN基线(RNN, LSTM)进行了对比。结果如表1所示。
表1:模型在四个数据集上的分类准确率对比(部分关键行)
| 数据集 | 方法 | 网络类型 | 隐藏层 | 准确率(%) |
|---|---|---|---|---|
| Ti46Alpha | LIF + HM2-BP (基线) | 前馈 | 800-800 | 90.98 |
| DGN (Ours) | 前馈 | 100 | 95.69 | |
| LSTM (基线) | 循环 | 100 | 96.05 | |
| DGN (Ours) | 循环 | 100 | 96.31 | |
| TIDIGITS | LIF + BPTE (基线) | 前馈 | 400-11 | 98.10 |
| DGN (Ours) | 前馈 | 100 | 98.59 | |
| LSTM (基线) | 循环 | 100 | 97.88 | |
| DGN (Ours) | 循环 | 100 | 99.10 | |
| SHD | TC-LIF (基线) | 前馈 | 128-128 | 83.08 |
| DGN (Ours) | 前馈 | 128 | 85.18 | |
| TC-LIF (基线) | 循环 | 128-128 | 88.91 | |
| DGN (Ours) | 循环 | 128-128 | 88.98 | |
| SSC | TC-LIF (基线) | 前馈 | 128-128 | 63.46 |
| DGN (Ours) | 前馈 | 128-128 | 67.54 | |
| LSTM (基线) | 循环 | 128-128 | 73.10 | |
| DGN (Ours) | 循环 | 128-128 | 75.63 |
结论:DGN在使用更少神经元或相当结构的情况下,达到了与当前最优SOTA方法相当甚至更高的准确率,特别是在TIDIGITS和SSC数据集上。
鲁棒性实验结果(核心亮点): 论文评估了模型在未见过的噪声(加性、减性、混合)和对抗攻击(FGSM, PGD, BIM)下的表现。表2给出了关键对比。
表2:模型在噪声和攻击下的准确率对比(TIDIGITS和SHD数据集,部分行)
| 数据集 | 模型 | 网络 | 干净准确率 | 加性噪声 | 减性噪声 | 混合噪声 | FGSM | PGD | BIM |
|---|---|---|---|---|---|---|---|---|---|
| TIDIGITS | LIF | 前馈 | 97.02 | 46.83 | 93.70 | 44.20 | 39.53 | 15.39 | 15.95 |
| HeterLIF | 前馈 | 96.52 | 77.49 | 89.37 | 72.78 | 52.48 | 43.94 | 43.68 | |
| DGN (Ours) | 前馈 | 98.59 | 95.34 | 93.70 | 78.12 | 90.35 | 86.76 | 86.88 | |
| LSTM | 循环 | 97.88 | 65.12 | 79.25 | 64.77 | 64.97 | 60.66 | 61.01 | |
| DGN (Ours) | 循环 | 99.10 | 94.84 | 96.70 | 93.86 | 89.40 | 87.52 | 87.68 | |
| SHD | LIF | 前馈 | 77.30 | 29.93 | 56.32 | 31.44 | 51.55 | 47.87 | 47.92 |
| DGN (Ours) | 前馈 | 85.18 | 59.46 | 64.05 | 58.87 | 63.81 | 61.59 | 61.44 | |
| LSTM | 循环 | 86.89 | 41.61 | 64.58 | 39.23 | 39.27 | 32.01 | 33.37 | |
| DGN (Ours) | 循环 | 87.78 | 78.97 | 61.91 | 79.35 | 69.45 | 66.13 | 66.34 |
结论:DGN在所有噪声类型和攻击下,均显著优于LIF、ALIF、HeterLIF以及RNN/LSTM。例如,在TIDIGITS上,面对加性噪声,前馈DGN(95.34%)比LIF(46.83%)高出约48.5个百分点;在PGD攻击下,循环DGN(87.52%)比LIF(61.79%)高出约25.7个百分点。
消融实验与不同扰动强度下的结果:
- 消融研究:论文提出了简化版DGN(s-DGN),减少参数量。在SHD数据集上(表3),s-DGN以接近LIF的参数量,实现了显著高于LIF和其他基线的准确率和鲁棒性。
- 不同扰动强度:图4(TIDIGITS前馈网络)和图6-8(其他设置)展示了在逐渐增强的扰动下,DGN的准确率下降最平缓,始终保持最高。这验证了其动态门控机制对扰动强度的良好适应性。
 图3展示了不同类型的噪声如何影响SHD数据集的输入信号(时间和通道维度),直观呈现了测试场景的复杂性。
图3展示了不同类型的噪声如何影响SHD数据集的输入信号(时间和通道维度),直观呈现了测试场景的复杂性。
 图4清晰地显示了DGN模型(黄色线)在所有扰动类型和强度下,分类准确率始终高于其他基线模型(LIF, HeterLIF, ALIF),且下降趋势最慢。
图4清晰地显示了DGN模型(黄色线)在所有扰动类型和强度下,分类准确率始终高于其他基线模型(LIF, HeterLIF, ALIF),且下降趋势最慢。
⚖️ 评分理由
- 学术质量(5.5/7):论文的创新点清晰(将生物电导作为门控),技术路径合理(从生物模型推导计算模型),并进行了扎实的理论和实验验证。理论分析(SDE)为鲁棒性提供了支撑,实验设计(干净训练,未见扰动测试)严谨,结果对比令人信服。扣分点在于,模型本质是现有生物模型(如Gütig & Sompolinsky, 2009)在SNN框架下的重新引入和工程化优化,而非完全原创的机制发现;部分基线(如LSTM)并非SNN领域最先进的鲁棒性方法。
- 选题价值(1.0/2):研究主题(提升SNN鲁棒性)是神经形态计算实用化的关键瓶颈,具有明确的实用价值和前沿性。然而,该工作主要在语音分类任务上进行验证,对于更广泛的音频/语音任务(如识别、增强、生成)的启示作用需要进一步论证,因此与读者的直接相关性中等。
- 开源与复现加成(0.5/1):论文提供了极其详尽的附录(A.1-A.5),包括模型推导、网络参数表、训练设置、噪声/攻击生成算法、伪代码(算法1)以及扩展实验数据(表11-16)。这些信息足以让研究者进行复现。虽然未提供代码仓库链接,但复现信息的完备性弥补了这一不足。