📄 ZSV2C-MLLM: Zero-Shot Visual Voice Cloning Via Multimodal Large Language Models
#语音克隆 #多模态模型 #零样本 #强化学习 #语音合成
✅ 6.5/10 | 前50% | #语音克隆 | #多模态模型 | #零样本 #强化学习
学术质量 5.8/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yanling Zhang(昆明理工大学)
- 通讯作者:Shengxiang Gao(昆明理工大学)
- 作者列表:Yanling Zhang(昆明理工大学,云南人工智能重点实验室)、Linqing Wang(昆明理工大学,云南人工智能重点实验室)、Shengxiang Gao(昆明理工大学,云南人工智能重点实验室)
💡 毒舌点评
亮点:论文最大的亮点在于将“情感规划”这个抽象任务显式地交给一个经过微调的大语言模型来完成,这个思路比传统基于规则或回归的方法更灵活,也更契合当前LLM赋能各任务的潮流。短板:论文在最关键的“如何做到零样本”和“LLM具体如何规划韵律”这两个核心问题上,细节描述过于粗疏,比如对“融合”操作(公式1)和“情绪调制”函数(公式4)的实现一笔带过,给人的感觉是框架大于细节,实验数据漂亮但“黑盒”感较强。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了公开数据集GRID和CHEM,但未提供获取方式或预处理脚本。
- Demo:未提及在线演示。
- 复现材料:仅提供了极有限的训练设置(优化器、学习率、硬件),缺乏复现所需的详细配置文件、超参数表、代码或检查点。
- 论文中引用的开源项目:引用了CosyVoice/CosyVoice2的工作,但未明确说明其开源项目是否被直接使用或作为基础进行构建。
- 总结:论文中未提及任何开源计划。
📌 核心摘要
- 要解决的问题:现有的视觉语音克隆(V2C)方法大多依赖于配对的音频-视觉数据,缺乏零样本能力,这限制了其在资源受限环境(如无配对数据)下的可扩展性。
- 方法核心:提出一个零样本V2C框架,集成文本、静音视频、参考音频和用户情感标签作为输入。其核心创新是一个基于预训练大语言模型(Qwen)的情感韵律规划器,它能根据多模态融合特征生成连续的韵律轨迹(如音高、语速、停顿)。
- 与已有方法相比新在哪里:主要区别在于引入了LLM作为多模态信息整合与情感韵律规划的中心模块,并实现了无需配对音频数据的零样本推理。相比于V2C-Net、Face-TTS等方法,该框架在数据要求上更灵活。
- 主要实验结果:在GRID和CHEM两个数据集上,该方法在语音质量(MOS-S)、自然度(MOS-N)和说话人相似度(SPK-SIM)上均显著优于基线方法。例如,在GRID数据集上,MOS-S达到3.94,比最强基线Multi-TTS(3.50)高0.44;SPK-SIM达到71.52,远高于其他方法。消融实验证明,移除视觉输入、情感控制、强化学习或LLM规划器都会导致性能明显下降。
- 实际意义:为电影配音、语音修复、交互媒体等需要情感化语音合成但缺乏配对训练数据的场景,提供了一种可扩展的解决方案。
- 主要局限性:实验仅在两个相对小规模和特定领域的数据集(GRID为命令式语音,CHEM为情感语音)上验证,对于更复杂、更自然对话场景的泛化能力未证明。此外,论文未公开代码和模型细节,可复现性存疑。
🏗️ 模型架构
该框架是一个多输入、多模块的端到端系统,旨在生成情感可控的语音。整体流程可概括为:多模态特征提取与融合 -> LLM情感韵律规划 -> 条件概率语音生成 -> 强化学习优化。
- 输入:静音视频(提供节奏和情感线索)、文本(提供语义内容)、参考音频(提供目标说话人音色)、用户定义的情感及强度。
- 组件与数据流:
- 视频编码器:分析视频帧,提取面部表情、唇部运动等视觉特征(V),捕捉情绪和节奏信息。
- 文本编码器:将输入文本编码为语义嵌入向量(T)。
- 说话人编码器:从参考音频中提取音色嵌��(A),保留说话人身份信息。
- 特征融合:三个模态的特征(V, T, A)通过一个融合函数
f_fusion被整合为统一的特征表示(F)。论文未详细说明此融合函数的具体结构(如注意力、拼接等)。 - 情感控制网络:用户提供情感类型和强度,由情感专家分类器(EmoBox)引导。这产生一个随时间步变化的情感参数(E_t 或 η_t)。
- LLM情感韵律规划器(核心创新):采用微调后的Qwen大语言模型。它接收融合特征(F)和情感参数(E_t),输出韵律轨迹(P_t),包括情感强度、音高偏移、语速、停顿时长等。这一步是动态、细粒度的控制关键。
- 语音分词器与条件概率生成:根据韵律轨迹(P_t)和文本,以自回归方式(公式3)生成语音token。公式4引入了情绪调制概率,使情感影响语音的生成过程。
- 强化学习模块:通过最大化奖励函数(R)来优化整个生成过程,奖励(r_t)基于语音自然度、情感表达力、与参考音频的对齐程度等。
- 架构图:论文提供了两张关键图表。
- 图1:
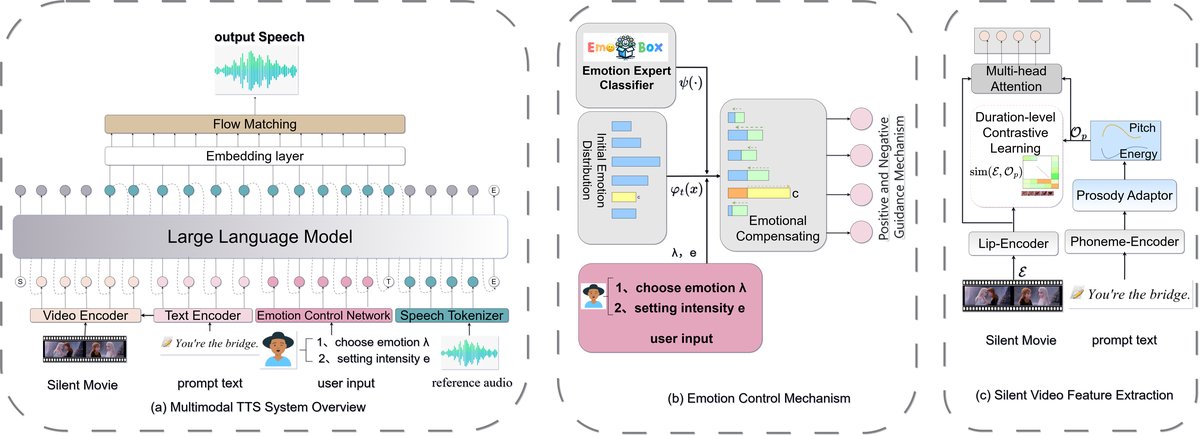此图清晰地展示了系统的三大块:(a) 系统架构,包含LLM规划器、视频编码器、文本编码器、情感控制网络和语音分词器;(b) 情感控制机制,展示了用户如何选择情感并调整强度;(c) 静音视频特征提取细节,显示了视频编码器如何利用多头注意力对齐韵律与视觉线索。 - 图2:
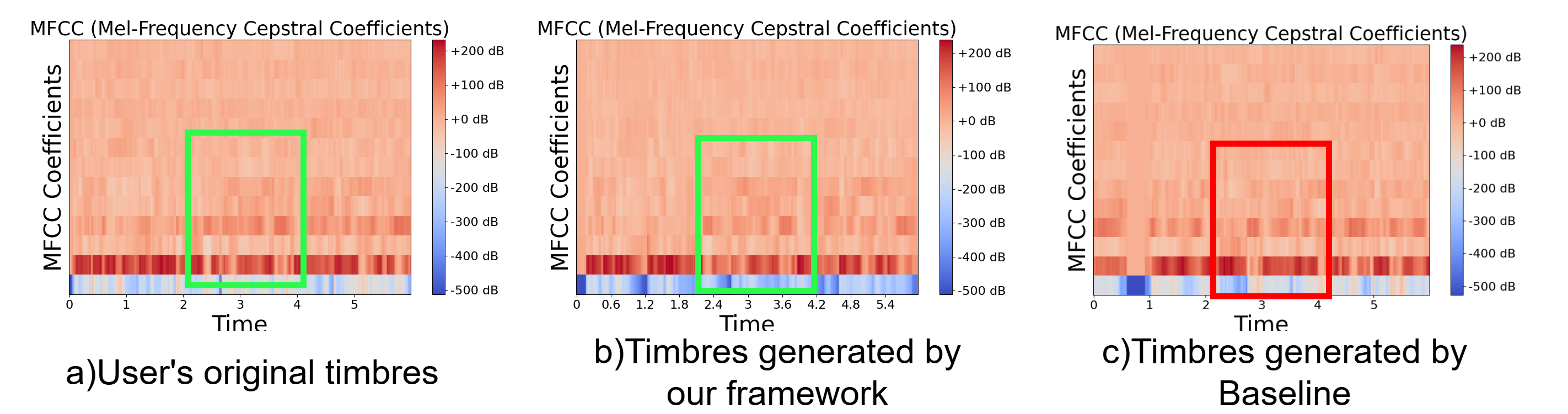此图对比了用户原始音色、本文方法生成音色和基线生成音色的MFCC图,直观地展示了该方法在保持音色(SPK-SIM)方面的优势。
- 图1:
- 设计选择动机:选择LLM作为规划器,是因其强大的序列建模和上下文理解能力,有望更好地捕捉韵律与情感、文本之间的长程依赖关系,克服传统规则或简单回归模型的局限。
💡 核心创新点
- 基于LLM的情感韵律规划器:是什么:使用微调的大语言模型(Qwen)作为核心,根据多模态输入生成连续的、细粒度的韵律控制参数。之前局限:传统方法多采用基于规则或轻量级神经网络(如Variance Adaptor)的规划器,其建模复杂情感-韵律交互的能力有限。如何起作用:LLM能利用其从海量数据中学到的丰富序列知识,更好地理解“在何种情感和视觉情境下,应该采用何种韵律”这一复杂映射。收益:消融实验表明,用LLM替代规则或方差适配器规划器,在所有指标上都取得了提升,尤其在情感一致性和自然度上优势明显。
- 零样本视觉语音克隆框架:是什么:一个无需配对音视频数据即可进行视觉语音克隆的完整框架。之前局限:现有V2C方法(如V2C-Net, HPMDubbing)严重依赖大规模、高质量的配对数据进行训练,限制了其应用场景和扩展性。如何起作用:通过分离音色(来自参考音频)和情感/韵律(来自视觉和文本)的建模路径,并利用迁移学习(预训练LLM和编码器),使得模型能够泛化到未见过的说话人。收益:实验证明该方法在“使用未见过的说话人作为参考音频”设置下仍表现优异,使其适用于电影配音等现实场景。
- 显式、连续的情感控制机制:是什么:允许用户通过选择情感类型和调节强度(e和λ)来精确控制生成语音的情感表达。之前局限:许多方法的情感控制是隐式或离散的(仅限预定义类别),控制粒度粗糙。如何起作用:情感参数(E_t)作为关键输入,被送入LLM规划器,直接影响韵律轨迹的生成。收益:提供了灵活、可调的情感表达能力,增强了实用性。
🔬 细节详述
- 训练数据:使用了两个数据集:GRID(提供同步音视频,用于学习视觉-音频关系)和CHEM(带有情感标签的语音数据)。论文未提供具体的数据集规模、预处理步骤或数据增强方法。
- 损失函数:论文未明确说明训练时使用的主要损失函数(如重建损失、KL散度等)。仅提及通过强化学习优化一个包含自然度、表达力、对齐度等的综合奖励函数(公式5)。
- 训练策略:优化器为Adam,初始学习率1e-4,每10,000步衰减0.9。采用了基于验证集损失的早停法。未说明batch size、训练总步数/轮数、warmup策略等。
- 关键超参数:论文未提供模型的具体规模参数,如LLM的层数、隐藏维度、各编码器的参数量等。
- 训练硬件:在6块NVIDIA RTX 4090 GPU集群上训练。未提供训练时长。
- 推理细节:采用自回归方式生成语音token(公式3)。未提及具体的解码策略(如温度、beam search大小)、是否支持流式输出等。
- 正则化技巧:仅提到了早停法,未提及其他正则化方法(如Dropout、权重衰减的具体设置)。
📊 实验结果
论文在两个数据集上进行了充分的对比实验和消融研究。
主要对比结果:
- 数据集:GRID,CHEM。评估指标:MOS-S(语音质量),MOS-N(自然度),SPK-SIM(说话人相似度)。
- 结果表格:
| 方法/组件 | GRID数据集 | CHEM数据集 | ||||
|---|---|---|---|---|---|---|
| MOS-S ↑ | MOS-N ↑ | SPK-SIM ↑ | MOS-S ↑ | MOS-N ↑ | SPK-SIM ↑ | |
| V2C-Net [7] | 3.05 ± 0.07 | 2.83 ± 0.09 | 38.38 | 3.02 ± 0.08 | 2.80 ± 0.10 | 40.21 |
| HPMDubbing [8] | 3.11 ± 0.08 | 2.92 ± 0.09 | 49.31 | 3.05 ± 0.07 | 2.88 ± 0.10 | 47.20 |
| Face-TTS [16] | 3.10 ± 0.05 | 3.17 ± 0.15 | 33.80 | 3.08 ± 0.06 | 3.15 ± 0.14 | 31.70 |
| MimicNet [17] | 3.27 ± 0.12 | 3.22 ± 0.14 | 55.10 | 3.22 ± 0.11 | 3.19 ± 0.13 | 53.90 |
| Multi-TTS [12] | 3.50 ± 0.10 | 3.41 ± 0.08 | 60.45 | 3.45 ± 0.09 | 3.38 ± 0.07 | 59.80 |
| Ours | 3.94 ± 0.12 | 3.87 ± 0.14 | 71.52 | 3.89 ± 0.10 | 3.82 ± 0.12 | 69.30 |
| 无视觉输入 | 3.47 ± 0.10 | 3.53 ± 0.11 | 58.32 | 3.47 ± 0.10 | 3.53 ± 0.11 | 58.32 |
| 无情感控制 | 3.68 ± 0.09 | 3.72 ± 0.12 | 64.10 | 3.68 ± 0.09 | 3.72 ± 0.12 | 64.10 |
| 无强化学习 | 3.75 ± 0.11 | 3.78 ± 0.14 | 66.25 | 3.75 ± 0.11 | 3.78 ± 0.14 | 66.25 |
| 规则型规划器 | 3.65 ± 0.09 | 3.55 ± 0.10 | 60.25 | 3.60 ± 0.10 | 3.52 ± 0.11 | 62.10 |
| 方差适配规划器 | 3.72 ± 0.11 | 3.60 ± 0.12 | 63.15 | 3.72 ± 0.10 | 3.64 ± 0.13 | 64.90 |
关键结论:
- 所提方法(“Ours”)在两个数据集的所有指标上均大幅超越所有基线。在说话人相似度(SPK-SIM)上提升尤为显著,分别高出最强基线(Multi-TTS)约11分和9.5分。
- 消融实验明确显示了各组件的不可或缺性:移除视觉输入、情感控制、强化学习,或将LLM规划器替换为规则型或方差适配型,都会导致性能在所有指标上的下降。这证实了多模态融合、情感调制、RL优化和LLM规划器各自的重要性。
- 图2的MFCC对比直观地支持了SPK-SIM数据,显示本方法生成的音色特征(b)与原始音色(a)更为接近,而基线(c)存在明显差异。
⚖️ 评分理由
- 学术质量:5.8/7:创新点明确且合理(LLM用于情感规划),实验设计完整(包含全面基线对比和消融研究),数据支撑有力。主要扣分项在于技术细节的披露严重不足(模型结构、损失函数、超参数等),这影响了工作的可验证性和学术严谨性。
- 选题价值:2.0/2:选题直接命中语音合成领域的关键挑战(零样本、情感控制),并给出了有前景的解决方案,应用导向明确,对学术界和工业界均有较高价值。
- 开源与复现加成:-0.5/1:这是论文最大的弱点。尽管描述了训练的大致环境和数据集,但完全缺失可操作的复现信息(代码、模型权重、详细配置)。对于一篇强调工程实现和复杂系统的工作,这严重阻碍了他人跟进和验证,因此给予负分。