📄 Windowed SummaryMixing: An Efficient Fine-Tuning of Self-Supervised Learning Models for Low-Resource Speech Recognition
#语音识别 #自监督学习 #迁移学习 #低资源 #多语言
✅ 6.5/10 | 前50% | #语音识别 | #自监督学习 | #迁移学习 #低资源
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Aditya Srinivas Menon(Media Analysis Group, Sony Research India)
- 通讯作者:未说明(论文未明确标注,所有作者邮箱后缀相同)
- 作者列表:Aditya Srinivas Menon(Media Analysis Group, Sony Research India)、Kumud Tripathi(Media Analysis Group, Sony Research India)、Raj Gohil(Media Analysis Group, Sony Research India)、Pankaj Wasnik(Media Analysis Group, Sony Research India)
💡 毒舌点评
本文在SummaryMixing的框架内巧妙地引入了局部窗口摘要(WSM),思路直观有效,并通过“只替换最后两层”的选择性微调策略,在低资源场景下实现了效率与性能的合理平衡。然而,其创新局限于对现有线性注意力变体的改进,且实验规模(主要评估几种主流SSL模型)和理论分析深度有限,更像是一项扎实的工程优化工作,而非开创性的学术突破。
🔗 开源详情
- 代码:论文中未提及代码链接或开源仓库。
- 模型权重:未提及公开的WSM微调后模型权重。
- 数据集:评估所用数据集(Kathbath, Common Voice, SBCSAE)均为公开可获取的语料库。
- Demo:未提供。
- 复现材料:论文详细说明了实验设置(如使用SpeechBrain, 单卡H100, batch size 16, 学习率等),但未提供完整的配置文件或训练脚本。
- 论文中引用的开源项目:明确依赖SpeechBrain工具包。
📌 核心摘要
本文旨在解决自监督学习(SSL)模型在语音识别任务中因自注意力机制导致的高计算复杂度问题,特别是在低资源场景下的高效微调需求。方法核心是提出Windowed SummaryMixing(WSM),它在原有的全局均值摘要(SummaryMixing)基础上,为每个帧引入一个局部邻域窗口摘要,从而在保持线性时间复杂度的同时,增强了模型对局部时序依赖的建模能力。同时,论文采用选择性微调策略,即仅将SSL模型编码器的最后两层自注意力层替换为WSM块并微调这些新层,而冻结其余预训练参数。实验在wav2vec 2.0、XLS-R等六种主流SSL模型及六种语言的数据集上进行。关键结果表明,WSM在低资源设置下普遍优于基线方法(原始SummaryMixing),例如,XLS-R模型在西班牙语上的WER从28.09%降至26.42%。此外,该方法将微调过程的峰值VRAM使用量降低了约40%,并将100秒音频的推理时间缩短了约25%。该工作的实际意义在于为在资源受限设备上部署和微调大规模SSL模型提供了一种高效且性能有保障的方案。主要局限性在于,创新程度有限,是已有工作的增量改进;实验仅替换了模型的最后两层,未探索更深层次或全局替换的效果;且未开源代码。
🏗️ 模型架构
本文的核心是改进SSL模型微调阶段的编码器层。整体流程是:将原始的SSL模型(如wav2vec 2.0)的编码器中最后两层的自注意力模块替换为Windowed SummaryMixing(WSM)模块,其余层保持预训练冻结状态。冻结层的输出通过一个可学习的加权层融合,再送入一个轻量级LSTM预测头进行解码。
WSM模块(图1b)的内部结构与原始SummaryMixing(图1a)类似,但增加了局部上下文。对于输入序列 \(H \in R^{T \times d}\):
- 全局摘要:通过一个前馈网络(FF)处理所有帧后,在时间维度上取均值,得到一个全局摘要向量 \(s_g\)(公式1)。该摘要对所有帧是共享的。
- 局部窗口摘要:对于当前帧 \(h_t\),以其为中心,取一个大小为 \(2k+1\)(k=5)的窗口内的帧,通过FF处理后取均值,得到该帧专属的局部摘要向量 \(s^w_t\)(公式3)。
- 输出融合:最终,将当前帧自身的FF变换 \(FF(h_t)\)、全局摘要 \(s_g\) 和局部摘要 \(s^w_t\) 在特征维度上拼接,再通过另一个FF网络得到该帧的输出 \(y_t\)(公式4)。
这种设计使得每个输出向量既包含了全局信息,又融入了精细的局部邻域信息,在线性复杂度下提升了时序建模能力。
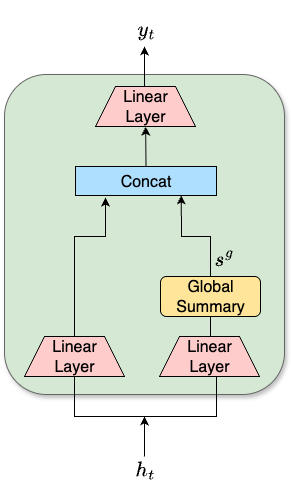 图1展示了两种模块的数据流。WSM (b) 相较于SM (a),为每个时间步增加了一个基于窗口的摘要 \(s^w_t\),与全局摘要 \(s_g\) 和当前帧特征一同送入最终的前馈网络。
图1展示了两种模块的数据流。WSM (b) 相较于SM (a),为每个时间步增加了一个基于窗口的摘要 \(s^w_t\),与全局摘要 \(s_g\) 和当前帧特征一同送入最终的前馈网络。
💡 核心创新点
- 窗口化摘要混合(WSM):在SM的全局摘要基础上,为每个帧计算一个局部邻域摘要。这是对现有高效注意力机制的增强,以线性复杂度捕获更细粒度的时序依赖,弥补了SM缺乏局部上下文的不足。
- 选择性微调策略:不是对整个SSL模型进行端到端微调(在低资源数据上易过拟合),也不是只训练一个浅层分类头,而是仅替换并微调编码器的最后两层,将其从自注意力变为WSM。这平衡了保留预训练知识与适应新任务的需要,显著降低了计算和内存开销。
- 系统性的效率与性能权衡评估:论文系统性地测试了替换不同数量层(1层、2层、…、所有层)的效果,通过实验(表1)确定了“替换最后两层”为性能与效率的最佳折衷点,为实践提供了具体指导。
🔬 细节详述
- 训练数据:使用多个公开数据集进行低资源和跨语言评估。印度语言:Kathbath数据集的印地语(hi)和泰米尔语(ta)。非印度语言:Common Voice 7.0的墨西哥西班牙语(es)、普通话(zh)、阿拉伯语(ar),以及Santa Barbara语料库(SBCSAE,英语)。数据规模未具体说明。
- 损失函数:使用CTC(连接时序分类)损失。
- 训练策略:
- 基线设置:采用“可学习加权层”融合所有冻结SSL层的输出,接轻量LSTM头。这是微调低资源ASR的有效基线。
- 本文方法:替换最后两层为WSM/SM并解冻这两层进行微调,同时训练加权层和LSTM头。
- 优化器:未明确说明。学习率:加权层和LSTM头为1e-3,解冻的SM/WSM层为3e-3。
- 批次大小:16。
- 训练轮数:25 epochs。
- 硬件:单卡NVIDIA H100 GPU。
- 解码:字符级分词,无语言模型。
- 关键超参数:
- WSM窗口大小k:测试了{3,5,7,9},固定为5。
- 替换策略:主要对比“替换最后1层”、“替换最后2层”等。
- 模型:使用多种SSL模型的Large版本(如wav2vec 2.0 Large, 24层编码器)。
- 推理细节:论文未提供温度、beam size等具体解码参数。图2展示了不同方法随输入音频长度变化的推理时间。
📊 实验结果
论文的核心实验旨在验证WSM在低资源ASR中的有效性、效率以及最优的层替换策略。
表1:不同层替换策略在Kathbath印地语和Common Voice墨西哥西班牙语上的WER(%)比较(wav2vec 2.0 和 XLS-R) 此表用于确定最佳替换层数。关键结论:对于两种模型和两个数据集,替换最后两层(Last 2) 的WSM变体通常取得最佳WER。替换所有层(All)的Att-PT变体在低资源下表现差,证实了全量微调会过拟合。
| SSL模型 | 变体 | Kathbath Hindi (WER ↓) | Mexican Spanish (WER ↓) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Last 1 | Last 2 | Last 3 | Last 4 | All | Last 1 | Last 2 | Last 3 | Last 4 | All | ||
| wav2vec 2.0 | SM | 18.20 | 18.18 | 18.29 | 18.26 | - | 34.54 | 34.65 | 35.44 | 34.79 | - |
| WSM | 17.89 | 17.03 | 18.24 | 18.11 | - | 35.24 | 33.97 | 34.82 | 34.37 | - | |
| Att-PT | 18.01 | 17.95 | 18.27 | 18.27 | 29.82 | 35.52 | 34.96 | 35.30 | 35.02 | 54.44 | |
| Att-scratch | 18.16 | 18.09 | 18.11 | 17.90 | - | 34.99 | 35.10 | 34.71 | 35.49 | - | |
| XLS-R | SM | 14.07 | 13.96 | 14.18 | 14.12 | – | 26.38 | 27.52 | 27.98 | 27.10 | – |
| WSM | 13.55 | 13.36 | 13.86 | 13.80 | – | 27.57 | 26.42 | 27.15 | 26.70 | – | |
| Att-PT | 13.66 | 13.60 | 13.92 | 13.92 | 22.60 | 28.44 | 27.88 | 28.22 | 27.94 | 43.46 | |
| Att-scratch | 13.81 | 13.74 | 13.76 | 13.55 | – | 27.24 | 28.06 | 26.92 | 28.69 | – |
表2:在多种SSL模型和数据集上,替换最后两层后的WER/CER(%)比较(本文方法 vs. 基线) 此表展示WSM的泛化性能。基线指替换为原始SM或Att-PT(根据原文描述,基线更可能指原始预训练模型微调方式,即Att-PT Last 2)。关键结论:在所有单语和多语言SSL模型上,替换为WSM(Ours)相比基线普遍降低了WER/CER,证明了其有效性。
| SSL模型 | 版本 | SBCSAE (WER ↓) | hi (WER ↓) | ta (WER ↓) | es (WER ↓) | zh (CER ↓) | ar (WER ↓) |
|---|---|---|---|---|---|---|---|
| 单语SSL模型 (Large) | |||||||
| wav2vec 2.0 | Baseline | 69.24 | 17.31 | 34.66 | 34.30 | 24.10 | 53.82 |
| Ours | 69.26 | 17.03 | 32.09 | 33.97 | 22.85 | 51.46 | |
| HuBERT | Baseline | 70.70 | 18.78 | 36.20 | 29.99 | 22.02 | 48.95 |
| Ours | 68.54 | 17.33 | 35.23 | 28.55 | 21.56 | 48.63 | |
| data2vec | Baseline | 59.62 | 19.96 | 36.98 | 36.14 | 24.43 | 54.80 |
| Ours | 59.43 | 19.32 | 36.84 | 35.71 | 21.96 | 51.95 | |
| 多语SSL模型 (Large) | |||||||
| XLS-R | Baseline | 66.43 | 15.42 | 30.22 | 28.09 | 20.01 | 40.34 |
| Ours | 63.67 | 13.36 | 28.86 | 26.42 | 19.98 | 38.21 | |
| mHuBERT | Baseline | 68.35 | 17.55 | 31.82 | 27.38 | 19.82 | 54.54 |
| Ours | 64.65 | 15.67 | 30.77 | 24.58 | 18.99 | 52.31 | |
| MMS | Baseline | 55.62 | 16.03 | 29.75 | 29.32 | 18.28 | 42.53 |
| Ours | 54.86 | 14.97 | 28.93 | 27.44 | 17.82 | 39.08 |
效率分析:
- 内存:SM和WSM变体微调时仅需约30-32GB VRAM,而基于注意力的基线(Att-PT/Att-Scratch)需要约50GB,内存节省约40%。
- 速度:图2分析了wav2vec 2.0不同变体的推理时间。
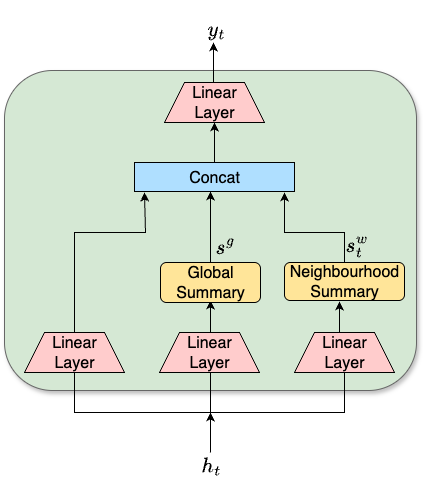 图2显示,对于短音频(<10秒),各方法速度相近。但随着音频变长,WSM(SM Window)的优势显现,在100秒时,其推理速度比注意力基线快约25%,体现了线性复杂度的优势。
图2显示,对于短音频(<10秒),各方法速度相近。但随着音频变长,WSM(SM Window)的优势显现,在100秒时,其推理速度比注意力基线快约25%,体现了线性复杂度的优势。
⚖️ 评分理由
- 学术质量:5.0/7:论文问题定义清晰,提出的WSM和选择性微调策略技术上合理,实验设计系统,涵盖了多种模型和语言,数据支持结论。扣分点在于创新为增量式改进,理论贡献有限;实验主要评估了替换“最后两层”的情况,对更优替换策略的探索不足;未与更多近期的高效微调方法(如LoRA等)进行对比。
- 选题价值:1.5/2:高效微调大模型是当前研究热点,低资源语音识别是实际需求。该方法在减少资源消耗的同时保持或提升性能,对边缘部署和低资源环境应用有直接价值。但该问题本身并非前沿热点中的突破性方向。
- 开源与复现加成:-0.5/1:论文提供了较详细的训练参数和基于SpeechBrain的实现说明,具备一定的可复现性。但未提供代码仓库、预训练权重或具体脚本链接,显著增加了完全复现的门槛。