📄 Whisper-MLA: Reducing GPU Memory Consumption of ASR Models Based on MHA2MLA Conversion
#语音识别 #语音大模型 #注意力机制 #模型优化 #推理优化
✅ 7.0/10 | 前25% | #语音识别 | #注意力机制 | #语音大模型 #模型优化
学术质量 6.0/7 | 选题价值 0.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Sen Zhang(天津大学智能与计算学院)
- 通讯作者:Xianghu Yue(† 标注,天津大学智能与计算学院)
- 作者列表:Sen Zhang¹, Jianguo Wei¹, Wenhuan Lu¹, Xianghu Yue¹,†, Wei Li², Qiang Li², Pengcheng Zhao², Ming Cai², Luo Si²(¹天津大学智能与计算学院,²斑马网络技术有限公司)
💡 毒舌点评
这篇论文的亮点在于将复杂的MLA机制巧妙地“翻译”到了Whisper的绝对位置编码架构上,并通过实验精准地找到了最佳部署点(仅解码器自注意力),实现了显著的内存节省和可忽略的精度损失,实用性很强。短板在于其验证仅限于Whisper-small模型,缺乏在更大规模模型(如Whisper-large)上的数据来证明其普适性;同时,对于语音任务中至关重要的流式处理场景,论文未做任何分析和探讨。
🔗 开源详情
- 代码:论文提供了公开的代码仓库链接:https://github.com/sssssen/Whisper MLA。
- 模型权重:论文未提及是否公开转换后的Whisper-MLA模型权重。
- 数据集:使用的是公开的LibriSpeech数据集,论文中已说明。
- Demo:未提及提供在线演示。
- 复现材料:提供了相当充分的复现信息,包括:转换方法(SVD细节)、微调数据集(LibriSpeech 960h)、训练超参数(3 epochs)、硬件环境(单卡RTX 4090)、批大小与梯度累积设置、转换与微调总时长(12小时)。
- 论文中引用的开源项目:主要依赖于OpenAI的Whisper模型作为基线和预训练源。
📌 核心摘要
本文旨在解决Whisper模型因Multi-Head Attention (MHA)机制中Key-Value (KV)缓存线性增长而导致的GPU内存消耗过高问题,该问题在长语音识别中尤为突出。核心方法是将Multi-Head Latent Attention (MLA)引入Whisper,并针对其绝对位置编码特性进行了适配。与已有工作相比,本文新在:1)提出了适配绝对位置编码的MLA架构,保留了原始模型的参数与能力;2)系统研究了MLA在编码器自注意力、解码器自注意力、解码器交叉注意力三种模块中的应用,发现仅应用于解码器自注意力(DSO)是性能与内存效率的最佳平衡点;3)开发了一种参数高效的转换策略,可从预训练Whisper模型快速转换而来。实验在LibriSpeech基准上表明,Whisper-MLA (DSO) 可将KV缓存大小减少高达87.5%,同时平均词错误率(WER)仅比微调后的Whisper基线高0.17%。该工作的实际意义在于,为在资源受限硬件上部署Whisper模型处理长音频提供了可行的内存优化方案。主要局限性在于仅在Whisper-small模型上进行了验证。
主要实验结果(LibriSpeech WER %):
| 模型 | 维度保留策略 | KV缓存减少 | dev-clean | dev-other | test-clean | test-other | 平均WER |
|---|---|---|---|---|---|---|---|
| Whisper (微调) | - | 0% | 6.32 | 14.86 | 6.86 | 15.05 | 10.95 |
| Whisper-MLA (DSO) | 全压缩 | 87.50% | 8.69 | 16.99 | 8.87 | 17.86 | 13.29 |
| Whisper-MLA (DSO) | 均匀采样 | 81.25% | 6.60 | 15.23 | 6.61 | 15.32 | 11.12 |
| Whisper-MLA (DSO) | 2-范数 | 81.25% | 7.33 | 16.17 | 7.82 | 16.18 | 12.06 |
图表说明:
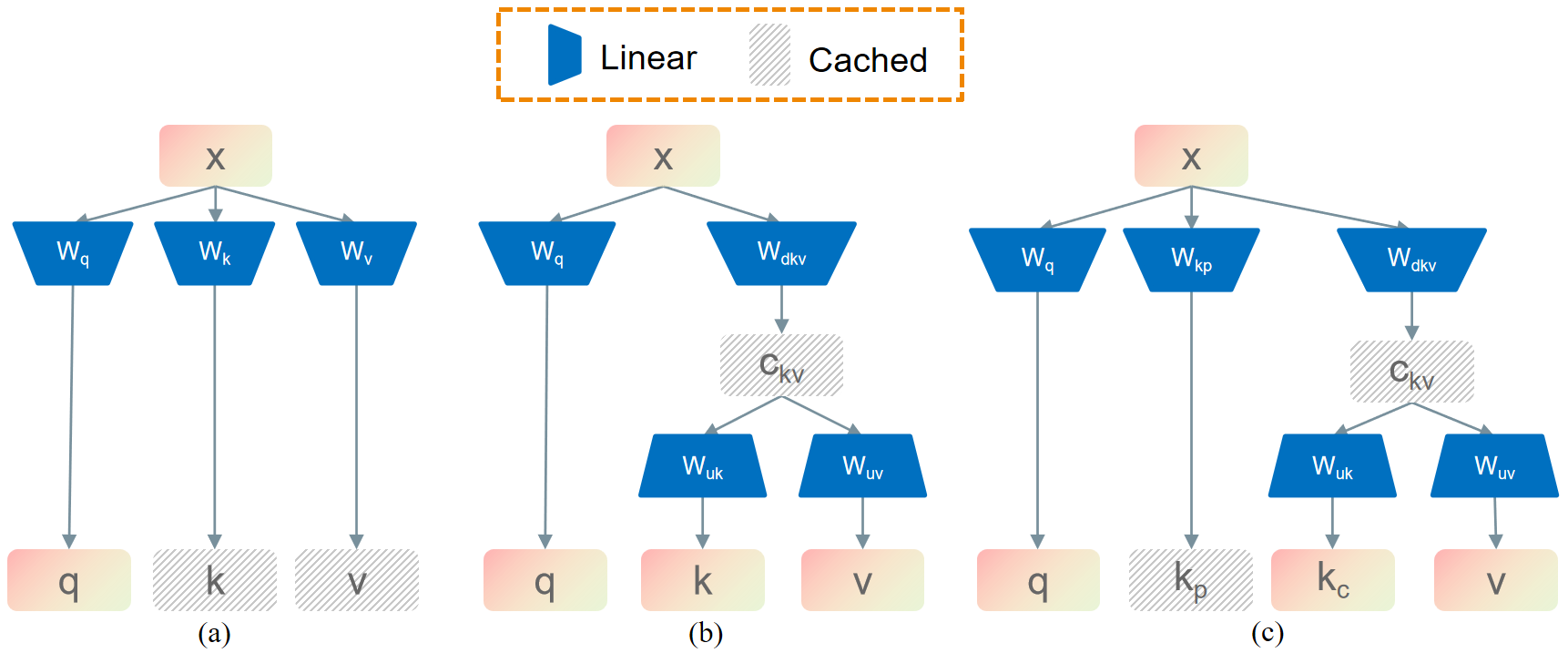 图1展示了原始MHA、全压缩MLA和维度保留MLA的结构。维度保留MLA通过保留一小部分原始Key维度(阴影部分)来维持性能,其余维度与Value一同压缩到低秩潜在空间。
图1展示了原始MHA、全压缩MLA和维度保留MLA的结构。维度保留MLA通过保留一小部分原始Key维度(阴影部分)来维持性能,其余维度与Value一同压缩到低秩潜在空间。
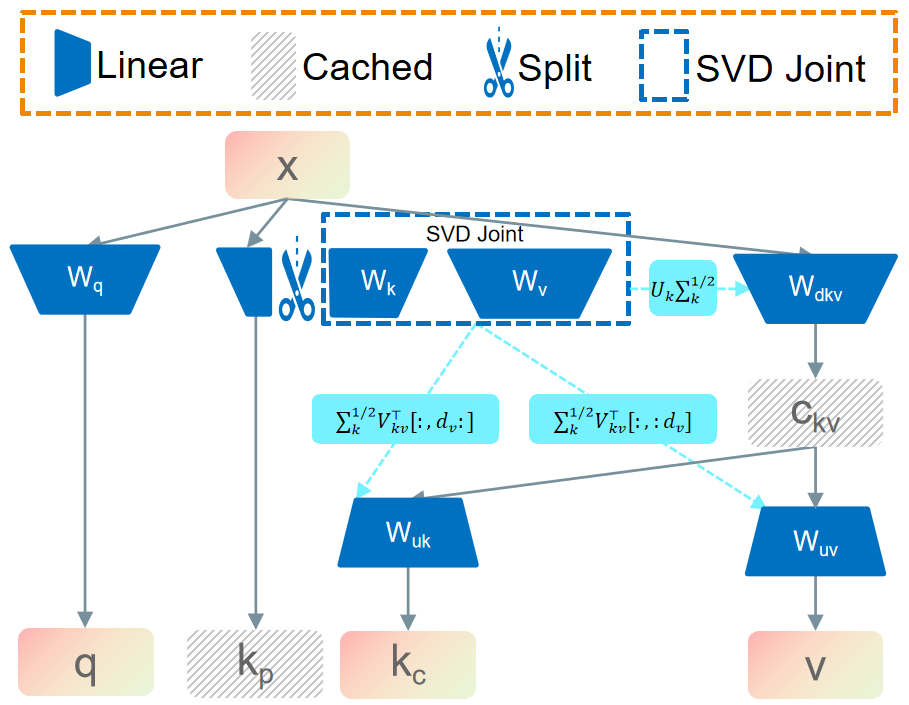 图2详细说明了转换流程:将预训练的Key投影矩阵拆分为保留部分(Wkp)和可压缩部分(Wkc),然后对[Wkc, Wv]进行联合SVD分解,得到低秩投影矩阵(Wuk, Wuv),从而复用原始参数。
图2详细说明了转换流程:将预训练的Key投影矩阵拆分为保留部分(Wkp)和可压缩部分(Wkc),然后对[Wkc, Wv]进行联合SVD分解,得到低秩投影矩阵(Wuk, Wuv),从而复用原始参数。
图3:GPU内存消耗对比 该图(论文中未提供具体图片URL,仅描述)展示了在不同批次大小(bsz)和序列长度下,Whisper与Whisper-MLA的GPU内存占用。关键结论是:随着序列长度和批次大小增加,内存节省优势愈发明显。例如,在bsz=64,序列长度=2048时,Whisper超出24GB显存(OOM),而Whisper-MLA仅使用15.4GB。
🏗️ 模型架构
Whisper-MLA的整体架构与原始Whisper保持一致,均为编码器-解码器结构。核心改变在于将解码器中的部分或全部Multi-Head Attention (MHA)层替换为本文设计的Multi-Head Latent Attention (MLA)层。
- 输入与输出流程:
- 输入:音频特征序列(如Mel频谱图)。
- 编码器:处理音频特征,输出高维表示。在Whisper-MLA (DSO)方案中,编码器保持原始Whisper架构不变。
- 解码器:接收编码器输出和之前生成的token,自回归地输出下一个token的概率分布。其内部的自注意力层被替换为MLA。
- 输出:最终输出为token序列(文本转录)。
- MLA层内部结构(针对Whisper适配):
(此图与上文引用为同一张)
- 查询(Q):保留原始Whisper的查询处理方式,不参与KV缓存,因此不改变。
- 键(K)与值(V):这是内存优化的关键。
- 维度保留策略:为了适配Whisper编码器的绝对位置编码(正弦余弦编码,按频率子空间组织),论文提出两种策略选择要“保留”不压缩的K维度子空间:
均匀采样和2-范数贡献。这对应了图1(c)中阴影部分的维度。 - 压缩流程(图1(c) → 图2):将原始K投影矩阵
Wk拆分为保留部分Wkp和可压缩部分Wkc。然后,将Wkc与Value投影矩阵Wv拼接,进行联合SVD分解,得到低秩近似。最终,推理时只需缓存一个压缩后的潜在向量(图1(c)中“Latent”部分),而不是完整的K和V,从而大幅降低KV缓存大小。
- 维度保留策略:为了适配Whisper编码器的绝对位置编码(正弦余弦编码,按频率子空间组织),论文提出两种策略选择要“保留”不压缩的K维度子空间:
- 整体架构变体与组件交互: 论文探索了两种主要变体:
- Whisper-MLA (Full):将编码器自注意力、解码器自注意力、解码器交叉注意力全部转为MLA。这破坏了编码器精心学习的声学特征表示。
- Whisper-MLA (DSO):仅将解码器的自注意力层转为MLA,保留编码器和交叉注意力不变。作者论证,推理时内存瓶颈主要来自解码器自注意力的动态KV缓存,而编码器的KV缓存是静态的。因此,DSO方案在获得同等KV缓存缩减的同时,最大程度保护了编码器强大的声学建模能力。
💡 核心创新点
- 适配绝对位置编码的MLA架构:突破了MLA通常与RoPE等相对位置编码配合使用的限制,通过维度保留策略,使其能应用于采用绝对位置编码(特别是正弦位置编码)的模型,扩展了MLA的适用范围。
- 基于维度保留的压缩策略:提出“全压缩”与“维度保留”的对比,并设计了
均匀采样和2-范数贡献两种具体的维度选择方法。实验证明,保留少量关键维度(6.25%)能显著提升模型性能,避免了全压缩带来的性能损失。 - 针对ASR编码器-解码器架构的系统性部署研究:首次系统性地研究了MLA在encoder-decoder模型不同注意力模块(编码器自注意、解码器自注意、解码器交叉注意)中的应用效果,并证明了“仅解码器自注意力(DSO)”是效率与性能的最优解。
- 高效的参数复用转换方法:设计了基于联合SVD分解的转换流程,能从预训练的Whisper模型初始化Whisper-MLA,仅需在目标数据上进行少量微调(3个epoch),极大降低了训练成本。
🔬 细节详述
- 训练数据:转换后的微调使用LibriSpeech数据集,规模为960小时。
- 损失函数:论文未具体说明,通常Whisper使用标准的交叉熵损失(负对数似然)。
- 训练策略:在单块NVIDIA RTX 4090 GPU (24GB) 上,以批大小8、梯度累积步数4进行微调,共训练3个epoch。整个转换与微调过程耗时约12小时。
- 关键超参数:基线模型为Whisper-small(244M参数)。维度保留策略中,对于768维的Key,保留48维(6.25%),将剩余720维与Value维度通过低秩近似投影到一个96维的联合潜在空间。
- 推理细节:论文主要评估了推理时的内存占用和识别精度(WER)。未提及具体的解码策略(如beam size),但Whisper默认使用beam search。
- 正则化或稳定训练技巧:论文未提及。
📊 实验结果
主要Benchmark与指标:在LibriSpeech数据集的dev-clean, dev-other, test-clean, test-other四个子集上,使用词错误率(WER, %) 进行评估。
与最强基线对比:
- 最强基线:在相同数据集上微调后的原始Whisper模型(Whisper (finetuned)),平均WER为10.95%。
- 本文最佳结果:Whisper-MLA (DSO) 采用均匀采样策略,平均WER为11.12%,仅比基线高0.17个百分点,同时KV缓存减少81.25%。
关键消融实验:
- 注意力模块部署位置:对比Whisper-MLA (Full) 和 Whisper-MLA (DSO)。在相同维度保留策略(如均匀采样)下,DSO的平均WER(11.12%)显著优于Full(16.81%),验证了保留编码器完整性的重要性。
- 维度保留策略:对比“全压缩”、“均匀采样”、“2-范数”三种策略。在DSO架构下,全压缩的WER最差(13.29%),均匀采样最好(11.12%),证明维度保留策略的有效性,且均匀采样略优于2-范数选择。
细分结果:所有模型在dev-other和test-other(更嘈杂、更困难)上的WER均显著高于对应的干净集,符合预期。Whisper-MLA (DSO) 在不同难度子集上均保持了与微调基线接近的相对性能。
实验结果表格:
| 模型 | 维度保留策略 | KV缓存减少 | dev-clean | dev-other | test-clean | test-other | 平均WER |
|---|---|---|---|---|---|---|---|
| Whisper(pretrained) | - | 0% | 16.37 | 19.78 | 16.00 | 20.90 | 18.36 |
| Whisper(finetuned) | - | 0% | 6.32 | 14.86 | 6.86 | 15.05 | 10.95 |
| Whisper-MLA (Full) | 全压缩 | 87.50% | 16.58 | 27.79 | 16.37 | 28.09 | 22.46 |
| Whisper-MLA (Full) | 均匀采样 | 81.25% | 12.32 | 19.72 | 13.18 | 21.34 | 16.81 |
| Whisper-MLA (Full) | 2-范数 | 81.25% | 11.75 | 20.83 | 12.15 | 21.74 | 16.82 |
| Whisper-MLA (DSO) | 全压缩 | 87.50% | 8.69 | 16.99 | 8.87 | 17.86 | 13.29 |
| Whisper-MLA (DSO) | 均匀采样 | 81.25% | 6.60 | 15.23 | 6.61 | 15.32 | 11.12 |
| Whisper-MLA (DSO) | 2-范数 | 81.25% | 7.33 | 16.17 | 7.82 | 16.18 | 12.06 |
图表说明:
(注意:根据用户说明,图3应为不同批次和序列长度下的内存消耗曲线图,但提供的图片URL对应的是图2的转换方法图。此处按论文描述内容进行说明,而非直接贴图。)
图3(按论文描述):该图直观展示了在推理阶段,Whisper-MLA在各种批次大小(bsz)和序列长度组合下,均比原始Whisper消耗更少的GPU内存。关键结论是:1) 内存节省随序列长度和批次增大而增大;2) 在极端情况(如bsz=64,序列长度=2048),Whisper发生显存溢出(OOM),而Whisper-MLA仍能正常运行,凸显其在长语音和高吞吐场景下的实用性。
⚖️ 评分理由
- 学术质量:6.0/7:创新性良好(适配绝对位置编码的MLA、系统性部署研究),技术实现描述清晰,实验设计合理且充分(包含消融研究、内存实测),证据可信。主要扣分点在于创新属于应用层面的适配和优化,而非提出全新的注意力机制;且实验规模(Whisper-small)限制了结论的普适性。
- 选题价值:0.5/2:选题具有明确的现实意义和应用价值,针对Whisper模型的内存瓶颈提供解决方案,符合高效AI的前沿趋势。但MLA本身非本文提出,本文是应用工作,因此“前沿性”和“影响力”得分中等。
- 开源与复现加成:0.5/1:提供了明确的代码仓库链接和详细的训练配置(数据、epoch、硬件、时长),复现门槛低,加分。