📄 Whisper-FEST: Single-Channel Far-Field Enhanced Speech-to-text without Parallel Data
#语音识别 #语音增强 #边缘计算 #多任务学习
✅ 7.5/10 | 前50% | #语音识别 | #语音增强 | #边缘计算 #多任务学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:未说明(论文作者列表未明确标注第一作者,根据列表顺序推测为 M A Basha Shaik)
- 通讯作者:未说明
- 作者列表:M A Basha Shaik (Samsung Research Institute, Bangalore, India), Vijendra R. Apsingekar (Samsung Research America, Mountain View, USA), Vineeth Rao (RV College of Engineering, Bangalore, India), Manonmani V. Amarnath (RV College of Engineering, Bangalore, India), Rahil Khan (RV College of Engineering, Bangalore, India), Mohammed Iqbal (RV College of Engineering, Bangalore, India), Manonmani Srinivasan (RV College of Engineering, Bangalore, India)
💡 毒舌点评
亮点: 该工作直面“如何在不重训大模型的前提下,让Whisper这类近场专家处理远场信号”的工程难题,其“即插即用”的模块化前端设计理念非常务实,且在VOiCES干净远场条件下取得了惊人的64.7%相对WER下降,证明了Conformer瓶颈对声学降质建模的有效性。短板: 论文中“计划开源”的承诺如同“画饼”,对至关重要的训练超参数细节(如学习率)语焉不详,让想复现的同行望而却步;此外,其方法本质上仍是“语音增强+ASR”的级联范式,未探索与Whisper更深度的端到端联合优化潜力。
🔗 开源详情
- 代码:论文中未提及代码链接,但表示“计划近期开源模型检查点”。
- 模型权重:论文中提及“计划近期开源”,但未提供具体链接或仓库地址。
- 数据集:使用的AMI、VOiCES、DNS均为公开数据集,论文中给出了获取方式(引用)。
- Demo:论文中未提及在线演示。
- 复现材料:论文描述了模型架构概览(表1)、训练两阶段策略和数据集组成,但缺失关键训练超参数(如学习率、优化器、batch size、epoch数、损失权重W的具体值),这些对完整复现至关重要。
- 论文中引用的开源项目:主要依赖Whisper(OpenAI开源的预训练模型)作为后端S2T引擎。
📌 核心摘要
- 问题:单通道远场语音转文本(S2T)性能在复杂声学条件下(如混响、噪声)显著下降,阻碍了其在真实世界边缘设备中的可靠部署。现有的数据增强或联合训练方法成本高,且可能损害近场性能。
- 方法核心:提出Whisper-FEST框架,其核心是一个名为TU-Net的前端增强模型。TU-Net是一个增强的U-Net架构,在其瓶颈层嵌入了Conformer模块,以更好地建模长距离声学降质。该模型直接在梅尔谱图上进行特征到特征的变换,并通过一个“S2T感知”的损失函数(结合谱图损失和冻结的Whisper编码器特征损失)进行训练,以确保增强后的信号对后端ASR友好。
- 新颖性:与传统方法相比,该工作无需并行数据(如近-远场配对数据),也不需要重新训练或微调已部署的Whisper模型,实现了模块化集成。其架构设计(Conformer瓶颈)和训练目标(直接优化对Whisper编码器友好的特征)是主要创新点。
- 实验结果:在VOiCES数据集上,与Whisper baseline相比,远场干净条件WER从24.6%降至8.6%(相对降低64.7%),远场噪声条件WER从46.2%降至38.8%(相对降低16.0%),同时近场性能保持稳定或略有提升。在AMI数据集上,与Whisper tiny.en结合,SDM(单远场麦克风)的WER从71.8%降至52.6%(相对降低约27%),小模型(Whisper small.en)下WER从40.2%降至35.63%(相对降低11.4%)。主要对比数据见下表:
方法 语料库/条件 基线WER(%) 增强后WER(%) 相对降低(%) TU-NET (ours) VOiCES (Far-Field Clean) 24.60 8.68 64.7 TU-NET (ours) VOiCES (Far-Field Noisy) 46.24 38.84 16.0 TU-NET (ours) AMI (SDM) + Whisper small.en 40.20 35.63 11.4 - 实际意义:该框架为提升已部署的轻量级ASR模型(如Whisper tiny/small)的远场性能提供了一种计算高效、即插即用的解决方案,非常适合资源受限的边缘设备。
- 局限性:主要依赖于预训练的Whisper编码器作为“教师”,其性能上限可能受此约束;训练策略虽然创新,但混合损失中权重W的网格搜索细节未充分披露;论文主要关注英语数据集,多语言泛化能力未验证。
🏗️ 模型架构
该论文提出的TU-Net架构(如图1所示)是一个为语音增强设计的增强型U-Net,用于将远场/噪声语音的梅尔谱图变换为更干净的版本,其完整流程如下:
- 输入:原始语音信号转换成的梅尔谱图(80通道,对应30秒音频,尺寸为80x3000)。
- 编码器:
- 初始层:一个7x7的大卷积核(GroupNorm)将输入通道从1映射到64,用于捕获宽时频上下文。
- 下采样块:三个连续的下采样块,每个包含一个残差块(ResBlock)和一个4x4步幅卷积。通道数逐级倍增(64 → 128 → 256 → 512),同时空间维度(时间和频率)减半,从而提取从低级到高级的层次化声学特征。
- 瓶颈层:
- 位于特征图分辨率最低处,是模型的核心。它包含两个串联的残差块和一个自注意力层。这个设计被称为“Conformer块”,结合了残差块的局部模式识别能力和自注意力的全局依赖建模能力。其动机是让模型能够有效处理由距离引起的长时混响、持续背景噪声等复杂声学降质,通过关联远距离时间步和频率单元的声学事件来实现。
- 解码器:
- 与编码器对称,包含三个上采样块,每个使用转置卷积(Transposed Convolution)逐步恢复特征图分辨率,通道数相应减半。
- 带注意力的跳跃连接:这是解码器的关键创新。在每个解码阶段,来自编码器对应层级的高分辨率特征图与解码器的特征图进行拼接,然后通过一个交叉注意力(CA)层。这允许网络智能地融合来自编码器的细节信息和来自瓶颈层的抽象特征,确保增强后的谱图既干净又保留关键细节。
- 输出层:最后一个3x3卷积将64通道特征图映射回1通道,输出增强后的梅尔谱图。
- 输出:增强后的梅尔谱图,直接作为输入送入后续的Whisper S2T模型。
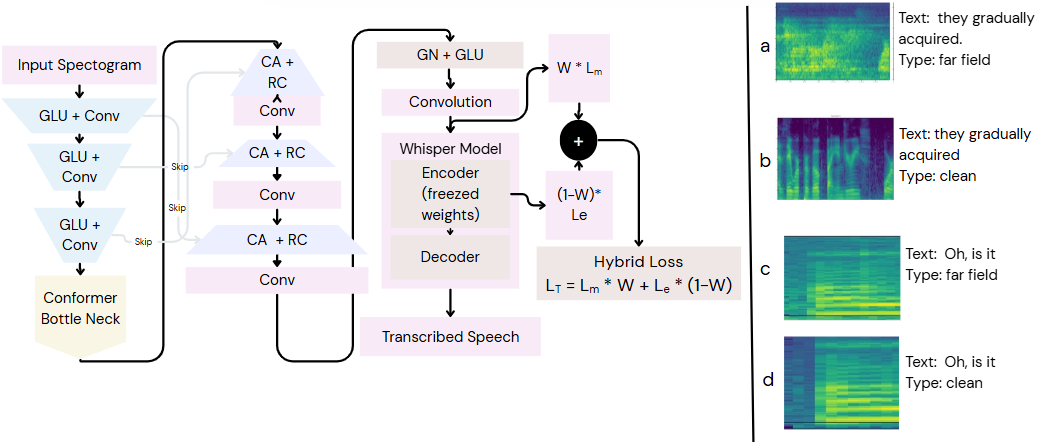 图1展示了TU-Net的完整架构流程,包括编码器、带Conformer和自注意力的瓶颈、以及带注意力跳跃连接的解码器。同时提供了VOiCES数据集中远场/干净谱图和AMI数据集中SDM/IHM谱图的可视化示例,直观展示了增强任务面临的声学挑战。
图1展示了TU-Net的完整架构流程,包括编码器、带Conformer和自注意力的瓶颈、以及带注意力跳跃连接的解码器。同时提供了VOiCES数据集中远场/干净谱图和AMI数据集中SDM/IHM谱图的可视化示例,直观展示了增强任务面临的声学挑战。
💡 核心创新点
- 融合Conformer的U-Net前端(TU-Net):在U-Net的瓶颈层引入Conformer模块。之前的U-Net语音增强模型主要使用卷积或简单的注意力机制。该创新通过结合Conformer的局部建模(残差块)和全局建模(自注意力)能力,更有效地捕获和去除远场语音中特有的、与距离相关的长时失真和混响,这是对传统架构的有效增强。
- S2T感知的优化策略:不同于仅最小化谱图重建误差(如L1/L2损失)的传统语音增强训练方法,该工作提出在第二阶段训练中引入一个混合损失。该损失结合了传统的梅尔谱图损失(L_m)和一个来自冻结的Whisper编码器的特征空间损失(L_e)。这直接优化了增强模型产生“对ASR系统友好”的特征,解决了单纯提升听感质量可能不提升甚至损害机器识别准确率的矛盾。
- 无需并行数据和微调的模块化框架:这是该方法在实用层面的核心优势。现有许多远场ASR方法依赖成对的近-远场数据进行训练,或需要联合微调ASR模型,成本高昂。Whisper-FEST作为一个独立的前端,只需用(可能非成对的)干净语音进行预训练,然后用少量数据进行S2T感知微调,即可插入到任何现有的、冻结的Whisper模型前,无需修改ASR模型本身。
- 针对边缘部署的轻量化设计:论文明确提出了模型大小(12M/19M/43M参数)与性能的权衡,并展示了与Whisper tiny/small这类本身即为边缘设备设计的模型的成功集成,强调了其在低算力设备上的适用性。
🔬 细节详述
- 训练数据:采用多语料库混合训练策略以提升泛化能力。
- AMI数据集:约50.7小时平行数据(IHM耳机麦和SDM远场麦)用于训练,1.2小时用于测试。
- VOiCES数据集:14小时子集用于训练,48小时测试集(包含不同噪声/距离条件组合)。
- DNS数据集:约81.2小时(干净语音混合真实噪声)用于训练,1.7小时用于测试。
- 训练数据SNR≥0dB。三个数据集的数据在训练中混合使用。
- 损失函数:采用两阶段训练的混合损失。
- 第一阶段(预训练):仅使用梅尔谱图损失
L_m(生成谱图与干净谱图的平均绝对误差MAE),目标是基本的去噪。 - 第二阶段(微调):使用混合损失
L_t = W L_m + (1 - W) L_e。L_m:同上。L_e:冻结的预训练Whisper-tiny.en编码器所提取的特征表示与目标特征之间的均方误差(MSE)。Whisper编码器作为固定的“教师”,指导前端模型生成其偏好的特征。L_t:总损失。权重W通过网格搜索确定(论文未给出具体值)。
- 第一阶段(预训练):仅使用梅尔谱图损失
- 训练策略:
- 两阶段训练:先用Lm预训练,再用L_t微调。
- 优化器、学习率、batch size、训练轮次等关键超参数论文中未具体说明。
- 使用单张NVIDIA A100 GPU进行训练。
- 关键超参数:
- 模型大小:提供了三个版本的参数量/大小:Model-A (12M/49.3MB), Model-B (19M/75MB), Model-C (43M/164MB)。主要实验似乎使用Model-C。
- 架构细节:编码器/解码器中的具体残差块数量、自注意力头数等在表1中概述,但更深层的细节(如注意力头数、FFN维度)未说明。
- 推理细节:未详细说明。推测是将原始语音转换为梅尔谱图,输入TU-Net得到增强谱图,再输入Whisper进行解码。Whisper的解码策略(如beam search)可能沿用其默认设置。
📊 实验结果
实验在VOiCES、AMI和DNS三个数据集上进行,主要评估指标为词错误率(WER)和字符错误率(CER)。
- VOiCES数据集消融实验(表2):
展示了不同大小的TU-Net模型(A, B, C)与Whisper small.en组合在VOiCES测试集上的性能。
麦克风类型 条件 Whisper Base (基线) WER/CER(%) Model-C (43M) WER/CER(%) 近场 (NF) 干净 (C) 5.5 / 1.5 5.0 / 1.2 远场 (FF) 干净 (C) 24.6 / 3.5 8.6 / 2.5 近场 (NF) 噪声 (N) 6.9 / 2.7 5.6 / 2.2 远场 (FF) 噪声 (N) 46.2 / 26.6 38.8 / 22.3 关键结论:随着TU-Net模型增大(参数从12M到43M),远场性能持续提升。最佳模型(Model-C)在远场干净条件下实现了64.7%的相对WER降低(24.6% → 8.6%),在远场噪声条件下实现了16.0%的相对降低(46.2% → 38.8%)。同时,近场性能保持稳定或略有提升,验证了模块化前端不会损害原有近场识别能力。
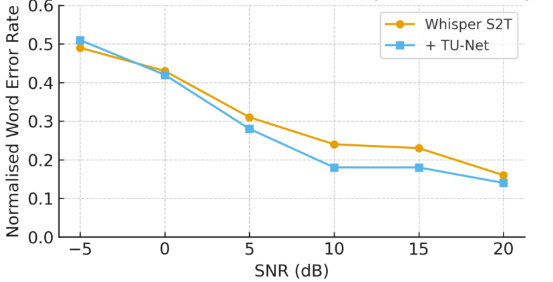 图2展示了在不同信噪比(SNRs)下,使用DNS数据集评估的近场S2T性能。曲线表明,所提模型在从高SNR到低SNR的各种噪声条件下,均能保持稳定或略优于基线Whisper的近场识别准确率,进一步证实了该方法在增强远场信号的同时,对近场性能的“无害性”。
图2展示了在不同信噪比(SNRs)下,使用DNS数据集评估的近场S2T性能。曲线表明,所提模型在从高SNR到低SNR的各种噪声条件下,均能保持稳定或略优于基线Whisper的近场识别准确率,进一步证实了该方法在增强远场信号的同时,对近场性能的“无害性”。
AMI数据集结果(表3):
模型 IHM (近场) WER/CER(%) SDM (远场) WER/CER(%) Whisper tiny.en 54.3 / 34.8 71.8 / 37.0 tiny.en + TU-Net (43M) 50.7 / 23.6 52.6 / 26.8 Whisper small.en 41.6 / 34.0 40.2 / 21.3 small.en + TU-Net (43M) 40.2 / 30.2 35.63 / 20.7 关键结论:在更具挑战性的AMI会议数据集上,TU-Net同样带来显著提升。与Whisper tiny.en结合时,远场WER从71.8%降至52.6%(相对降低约27%)。与Whisper small.en结合时,远场WER从40.2%降至35.63%(相对降低11.4%)。近场性能也得到小幅改善。 与SOTA方法对比(表4):
方法 语料库 基线WER(%) 增强后WER(%) 相对降低(%) Multi-tap MVDR [30]* 内部数据 17.44 9.96 42.9 Heterosc. AE [13] 内部数据 64.67 59.94 7.3 Joint-VAE [14] AMI (SDM) 55.52 51.56 7.1 TU-NET (ours) VOiCES (FC) 24.60 8.68 64.7 TU-NET (ours) VOiCES (FN) 46.24 38.84 16.0 TU-NET (ours) AMI (IHM) 41.67 40.27 2.5 TU-NET (ours) AMI (SDM) 43.83 35.63 19.0 DPLSTM-EC [4] VOiCES (Dev) 22.20 16.40 26.1 MASK NET [16]* AMI (Eval) 45.30 39.00 13.9 关键结论:与表中列出的其他单通道或双通道方法相比,TU-NET在VOiCES干净远场和AMI远场条件下取得了最高的相对WER降低率(64.7%和19.0%),显示出强大的竞争力。
⚖️ 评分理由
- 学术质量:5.5/7:创新性体现在架构融合(Conformer in U-Net)和训练目标(S2T-aware loss)上,有一定新意。技术路线正确,实验设计覆盖了多个数据集并展示了显著提升。主要扣分点在于部分实验细节(训练超参数)缺失,以及与最前沿的端到端或大规模预训练远场方法对比不够深入。
- 选题价值:1.5/2:问题(单通道远场识别)是语音技术落地的重要瓶颈,解决方案(轻量级前端)直击痛点,对工业界和边缘计算场景有明确的应用价值。
- 开源与复现加成:-0.5/1:论文明确计划开源模型权重,这是加分项。但关键训练细节缺失严重阻碍了复现性,因此给予负分。