📄 Whisper: Courtside Edition - Enhancing ASR Performance through LLM-Driven Context Generation
#语音识别 #大语言模型 #领域适应
✅ 6.5/10 | 前50% | #语音识别 | #大语言模型 | #领域适应
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yonathan Ron(Reichman University, Efi Arazi School of Computer Science)
- 通讯作者:未说明
- 作者列表:Yonathan Ron(Reichman University)、Shiri Gilboa(Reichman University)、Tammuz Dubnov(Reichman University)
💡 毒舌点评
本文巧妙地将多智能体LLM管道作为“提示工程师”,通过两次转录的方式让Whisper模型“听懂”篮球解说,避免了昂贵的模型重训练,工程思路清晰。然而,整个系统严重依赖GPT-4o这一商业“黑盒”以及固定的球员名册,其延迟、成本和对外部知识库的强依赖性,使其在真实、动态的体育直播或成本敏感场景下的落地前景存疑。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。使用的是开源的Whisper模型和商业的GPT-4o API。
- 数据集:未公开。论文中描述数据为手动收集和分割,未提供下载链接或获取方式。
- Demo:未提及。
- 复现材料:论文未提供具体的提示工程模板、代理的详细指令或知识库(球员名单、术语表)的内容。
- 论文中引用的开源项目:OpenAI Whisper模型、OpenAI GPT-4o API(商业服务)。
📌 核心摘要
本文针对领域特定语音识别(以NBA篮球解说为例)中ASR模型因专有名词和领域术语识别不准导致转录错误率高的问题,提出了一种基于大语言模型的多智能体管道。该方法不修改Whisper模型本身,而是利用其首次转录文本,通过一系列LLM代理(主题分类、命名实体识别、领域术语提取)生成一段简明的上下文提示,再将该提示注入Whisper进行第二次转录,从而引导模型产生更准确的输出。与直接文本后处理(LLM Post-Fix)或仅提供主题提示(Topic-Only)的方法相比,该方法在421个NBA解说片段上实现了统计显著的词错率(WER)下降:从基线的0.217降至0.180,相对改进17.0%(p<0.001),且仅有7.1%的片段出现性能下降。其实际意义在于提供了一种灵活、无需重训练的领域适配方案,其主要局限性在于对商业LLM(GPT-4o)的依赖引入了延迟与成本,并需要维护领域知识库(如球员名单)。
🏗️ 模型架构
本文的核心并非一个新的端到端ASR模型,而是一个后处理与提示生成管道,用于增强现有Whisper模型的解码过程。其整体架构如图1所示,是一个多阶段、多智能体的串行流程:
- 输入:音频文件和Whisper模型。
- 第一阶段(Whisper首次转录):将音频输入标准的Whisper-medium.en模型,获得一个可能包含领域特定错误的初始文本转录稿。
- 第二阶段(多智能体上下文生成):这是论文的核心贡献。该阶段拦截第一阶段的文本输出,并依次由四个专用模块进行处理:
- 话题分类代理:分析文本,推断出宽泛的领域上下文(例如,“NBA篮球解说”)。
- 命名实体识别代理:从文本中提取人名(球员名),并通过模糊匹配映射到官方的NBA球员名册上,生成正确的拼写。
- 领域术语提取代理:利用关键词启发规则和一个篮球术语表,从文本中识别出领域专用术语(如“pick and roll”)。
- 决策过滤与句子构建器:这是一个验证与优化模块。它对前面代理提出的候选名称和术语进行置信度过滤,确保它们是原始识别错误的合理修正(防止插入未出现的词)。同时,它将筛选后的主题、人名、术语组合成一个简洁、自然语言的句子。关键设计在于:该句子会将高价值(稀有或领域特定)的词置于末尾,并严格控制总长度在Whisper的提示词限制(≤224词元)以内。
- 第三阶段(Whisper二次转录):将第二阶段生成的提示句子,通过Whisper的
initial_prompt参数,在解码过程中注入到模型。Whisper会利用该提示对解码进行上下文偏置,从而在重新处理原始音频时,更倾向于输出提示中包含的正确拼写和术语,最终生成改进后的转录文本。 - 输出:上下文感知的增强转录稿。
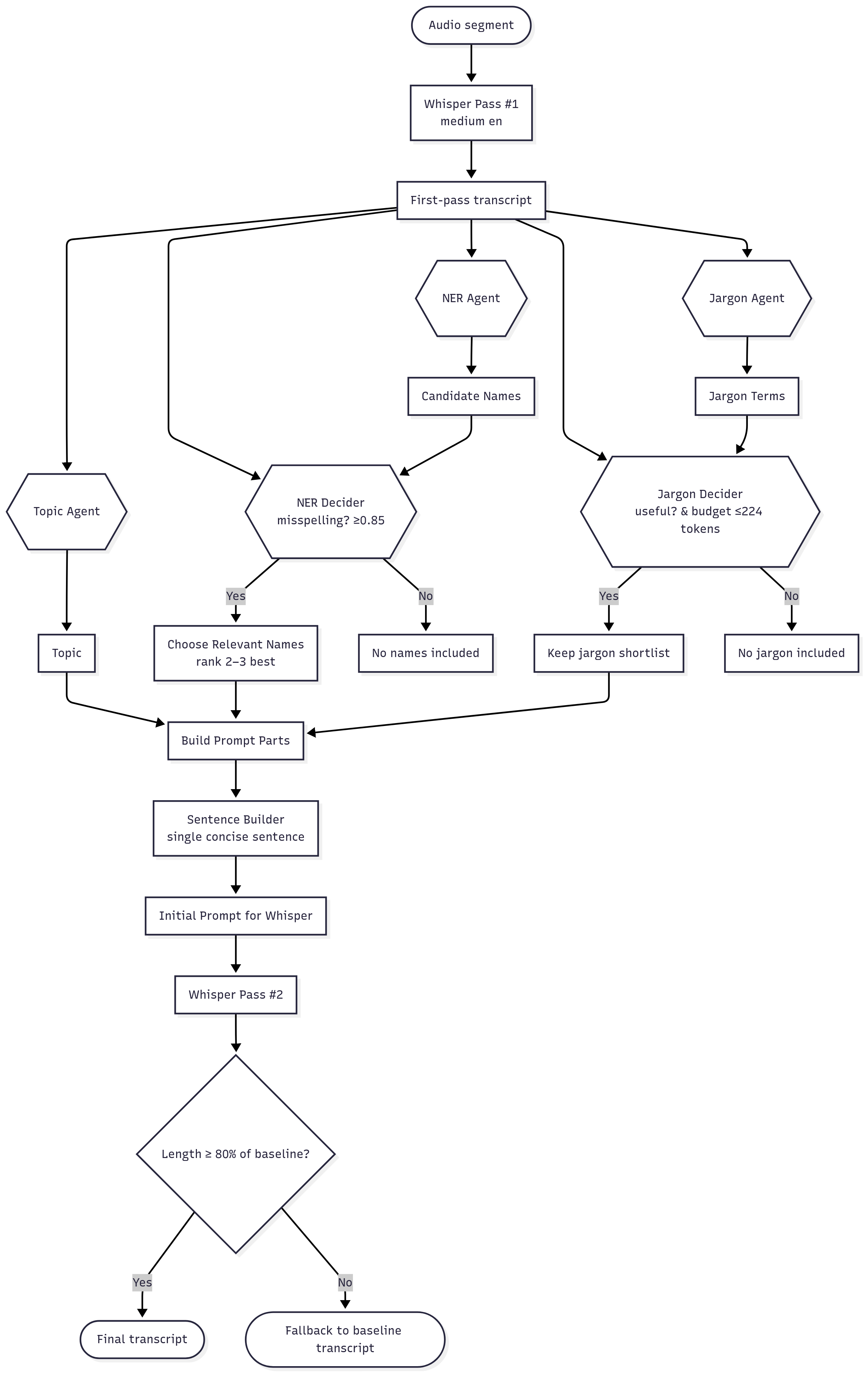 图1展示了完整的处理流程:Whisper首次转录输出被送入多个GPT-4o代理(话题、人名、术语),经过滤后生成提示句,再次输入Whisper的解码器,得到最终转录。
图1展示了完整的处理流程:Whisper首次转录输出被送入多个GPT-4o代理(话题、人名、术语),经过滤后生成提示句,再次输入Whisper的解码器,得到最终转录。
💡 核心创新点
- 基于LLM多智能体管道的提示工程:核心创新在于设计了一个由多个专用LLM代理组成的协作系统,自动化地分析ASR初步输出,并生成一个能有效“引导”ASR模型自身的高质量提示。这区别于单一提示或简单的文本后处理。
- 利用ASR内置提示机制进行二次引导:不同于用LLM直接修改转录文本(后处理),本文方法通过生成提示来影响ASR的解码过程。这使得修正能同时结合LLM的知识和原始的声学证据,避免了纯文本修复无法挽回听错信息的局限。
- 模块化与领域可迁移性:架构将话题、实体、术语的处理解耦为独立代理,使得系统可以通过简单替换知识库(如换用足球运动员名单)和调整代理提示来适配新领域,而无需重新训练ASR模型。
- 带有验证的可靠性设计:在生成提示前,引入了决策过滤器对候选修正进行可信度验证,有效防止了将未出现在语音中的“幻觉”词注入转录,确保了系统的净提升(7.1%的退化率 vs 40.1%的改进率)。
🔬 细节详述
- 训练数据:未说明。本文方法不涉及模型训练。评估数据集为421段手动收集、分割的NBA篮球解说音频(每段10-30秒),来源于YouTube视频,并由领域专家进行了高质量人工转写作为基准。
- 损失函数:不适用。本文不训练模型。
- 训练策略:不适用。
- 关键超参数:
- 基线模型:OpenAI Whisper-medium.en。
- 提示长度限制:224词元(Whisper的最大提示长度)。
- 所有LLM代理均使用OpenAI GPT-4o API实现。
- 训练硬件:未说明。
- 推理细节:
- 采用两阶段转录:首次转录(无特定提示)-> 生成上下文提示 -> 第二次转录(使用生成的
initial_prompt)。 - 提示构建策略:将高价值词置于提示句末尾,以利用Whisper关注提示末尾词元的特性。
- 采用两阶段转录:首次转录(无特定提示)-> 生成上下文提示 -> 第二次转录(使用生成的
- 正则化或稳定训练技巧:不适用。
📊 实验结果
本文在421个NBA解说片段上进行了详尽的对比实验,使用词错率(WER)作为主要指标。结果总结如下:
表1:不同管道在421个NBA片段上的WER及片段结果
| 管道 | WER | 相对基线变化 | 改进片段占比 | 退化片段占比 |
|---|---|---|---|---|
| 基线 (Whisper) | 0.217 | — | — | — |
| P1: 仅主题 | 0.238 | +9% | 20.9% | 25.9% |
| P2: LLM后修 | 0.217 | 0% | 19.2% | 19.5% |
| P3: 增强人名 | 0.210 | -3% | 36.8% | 20.7% |
| P4: 完整多智能体 (本文) | 0.180 | -17% | 40.1% | 7.1% |
关键结果分析:
- 主实验:完整管道P4实现了17.0%的相对WER降低(从0.217到0.180),且该差异具有统计显著性(p<0.001)。这是四个方案中最佳结果。
- 消融实验与分析:
- P1 (仅主题) 性能反而变差(WER +9%),表明提供宽泛上下文而不提供具体正确词汇,会过度偏置模型产生与主题相关的幻觉词。
- P2 (LLM后修) 与基线持平,证明纯文本LLM无法可靠纠正未正确识别的语音内容,因为它没有访问原始音频。
- P3 (增强人名) 有一定改进(-3%),但退化率较高(20.7%)。这表明仅修正人名会引入更多错误的替换(过度纠正),而P4通过加入术语提取和置信过滤避免了这一问题。
- 错误修正案例:论文列举了具体例子,如将“yanis anteto kumbo”纠正为“Giannis Antetokounmpo”,将“picker roll”纠正为“pick and roll”。
图2:WER分布图] 图2(论文描述):对比了基线与P4在测试集上的WER分布。P4的分布整体向左(低WER方向)移动,直观显示了其降低错误率的效果。
图3:每片段ΔWER分布图] 图3(论文描述):展示了每个片段上(基线WER - P4 WER)的差值。绝大多数值为正,证实P4在大多数片段上带来了改进。
⚖️ 评分理由
- 学术质量(5.5/7):方法设计完整、实验严谨(多对照组、统计检验、错误案例分析),结论清晰可信。但核心创新(LLM生成提示)并非全新,且方案的有效性严重依赖外部的GPT-4o API和固定知识库,其独立贡献和可迁移性打了折扣。
- 选题价值(1.5/2):聚焦于体育解说这一垂直但重要的场景,解决实际痛点,有明确的应用价值(如体育媒体自动化)。但领域较为狭窄,通用性一般。
- 开源与复现加成(-0.5/1):论文未提供代码、处理后的数据、详细的提示模板或训练细节(虽然主要用API)。依赖GPT-4o这一商业服务,使得完全复现实验的经济成本和访问门槛较高,扣分。