📄 When Noise Lowers the Loss: Rethinking Likelihood-Based Evaluation in Music Large Language Models
#音乐生成 #模型评估 #自回归模型 #音频大模型 #对抗样本
✅ 7.0/10 | 前25% | #音乐生成 | #模型评估 | #自回归模型 #音频大模型
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xiaosha Li (Georgia Institute of Technology)
- 通讯作者:未说明(根据惯例,最后一位作者Ziyu Wang可能为通讯作者,但论文中未明确标注)
- 作者列表:Xiaosha Li (Georgia Institute of Technology), Chun Liu (ByteDance Inc.), Ziyu Wang (Courant Institute of Mathematical Sciences, New York University; Mohamed bin Zayed University of Artificial Intelligence (MBZUAI))
💡 毒舌点评
亮点在于发现了一个反直觉但可重复验证的现象(“噪声降低损失”),并据此提出了一个新颖的、基于损失曲线形状的评估视角,而非简单否定损失指标,这为音乐生成评估提供了具体的诊断工具和改进方向。短板在于,论文的核心论证主要基于“噪声注入”和“顺序打乱”两种人工扰动,其与真实音乐质量(如乐感、结构、情感表达)的关联性仍需更多元、更贴近实际场景的验证,且提出的“基于曲线形状”的评估框架目前更多是定性描述,缺乏可直接应用的定量标准。
🔗 开源详情
- 代码:提供了官方代码与演示页面链接:
https://noiseloss.github.io。 - 模型权重:论文分析的模型(MusicGen系列, YuE)均为已公开的预训练模型,论文中未提及自己训练或发布新模型权重。
- 数据集:论文使用了部分公开数据集(ASAP)和私有数据(Shutterstock子集)。Generated数据由公开模型生成,可复现。
- Demo:提供了在线演示页面(链接同上)。
- 复��材料:论文详细描述了噪声注入和顺序打乱的实验设置(参数、位置、长度),并提供了分析代码,复现其核心实验具有较高可行性。
- 引用的开源项目:明确依赖 EnCodec(音频分词器)、MusicGen 模型、YuE 模型、ASAP 数据集。
📌 核心摘要
- 问题:当前音乐大语言模型(LLM)普遍采用基于似然(或交叉熵损失)的指标来评估生成音乐的质量,但该指标的可靠性在音乐领域尚未得到充分验证,可能出现模型认为“更差”的音乐(如加了噪声)反而损失更低的情况。
- 方法核心:通过系统的“噪声注入”和“顺序打乱”实验,分析模型损失曲线在面对输入扰动时的动态变化,提出了“上下文遗忘效应”(Context Amnesia Effect)的概念来解释该现象。
- 新意:不同于以往研究仅指出似然评估的偏差,本文系统量化了音乐LLM对不同类型扰动的反应模式,发现模型仅对非常短暂的局部扰动敏感(表现为损失峰值),但对持续较长或结构性的扰动表现出“遗忘”和适应(损失回落或不变),因此提出评估应关注损失曲线的形状(profile) 而非绝对值。
- 主要实验结果:
- 对MusicGen系列和YuE模型的实验一致显示:注入的噪声或打乱的片段越长,序列整体损失越可能降低(损失差为负值)。相关性分析显示噪声长度与损失差呈强负相关(r < -0.85, p < 0.001)。
- 逐Token分析揭示了三阶段行为:1)扰动开始时损失急剧上升(Peak);2)随后损失迅速下降并保持低位(Assimilation);3)扰动结束后损失不稳定波动(Recovery)。
- 在训练集、生成数据和分布外数据上均观察到此效应。
- 实际意义:揭示了当前主流音乐生成模型评估体系的一个根本缺陷,即基于绝对损失的指标无法可靠区分音乐的结构完整性。这促使研究者和开发者需重新审视评估基准,并考虑更关注局部动态或设计新的评估范式。
- 主要局限性:研究主要聚焦于自回归模型在音频波形域(使用RVQ分词器)的行为,未探讨其他架构(如扩散模型)。所提的“基于曲线形状的评估”目前是一个方向性建议,缺乏具体的、可自动化的评估协议和算法。实验扰动类型(白噪声、顺序打乱)相对简单,与真实音乐编辑或低质量生成的差异仍需进一步研究。
🏗️ 模型架构
本文是一篇分析与评估导向的论文,其研究对象是现有的音乐生成模型(如MusicGen, YuE),而非提出一种新的生成模型架构。因此,本节将基于论文内容描述被分析模型的核心架构特征。
论文分析的MusicGen是一个基于Transformer的自回归音乐生成模型。其核心流程如下:
- 输入:一段音频信号。
- 分词:使用EnCodec神经音频编解码器将波形音频转换为离散的RVQ(残差向量量化)token序列。论文中指出,在32kHz采样率下,token速率约为50Hz,即每个token代表约20ms的音频。
- 建模:模型(Transformer解码器)接收token序列
x_{1:T},并自回归地计算每个token在给定前文条件下的条件概率分布p_θ(x_t | x_{<t})。 - 训练与损失:训练目标是最小化交叉熵损失,即公式(1)所示的负对数似然
ℓ(x_{1:T}) = −∑ log p_θ(x_t | x_{<t})。 - 输出:生成过程即从自回归分布中采样出新的token序列,再通过EnCodec解码器恢复为音频波形。
论文的实验部分还提到了YuE模型,这是一个规模更大(1B参数)的开源音乐生成模型,同样采用自回归架构。论文未提供这两种模型内部的详细架构图。
💡 核心创新点
- 揭示“上下文遗忘效应”:首次系统地定义并验证了音乐LLM在面对输入扰动时的一个独特行为模式——模型会在短暂抵抗(损失峰值)后,迅速“遗忘”原有上下文,开始适应扰动信号(如噪声),导致后续损失降低。这是对模型在推理时动态特性的一次深入观察。
- 提出基于损失曲线形状的评估新视角:与以往关注损失绝对值不同,本文指出损失曲线的局部动态(如扰动起始处的峰值高度、同化阶段的持续时间和深度)携带了关于模型对音乐结构感知能力的更可靠信息。这为评估方法提供了新的设计思路。
- 实证音乐LLM的评估偏差:通过在多种数据集(训练集、生成数据、分布外数据)、多个模型(MusicGen不同尺寸、YuE)和多种扰动(噪声注入、顺序打乱)上的广泛实验,强有力地证明了基于似然的评估指标在音乐领域的不可靠性,其缺陷具有普遍性。
- 将“暴露偏差”与评估可靠性关联:论文将观察到的“上下文遗忘效应”与经典的“暴露偏差”(exposure bias)概念联系起来,指出这一训练阶段的问题不仅影响生成质量,也破坏了以训练损失为基础的评估的有效性。
🔬 细节详述
训练数据:
- TrainingSet:来自Shutterstock训练语料库的一个子集,包含20首歌曲,用于MusicGen的训练。
- OOD(分布外)数据:来自ASAP数据集的78首古典乐曲,涵盖多种作曲家和风格。
- Generated数据:由MusicGen-Small模型在不同生成设置(top-k值)下产生的140个样本;以及由YuE模型自身生成的样本。
- 论文未提供训练数据的详细规模、预处理和数据增强方法。
损失函数:使用标准的自回归交叉熵损失(公式(1)),即每个时间步预测真实下一个token的负对数似然之和。
训练策略:论文中未详细说明具体的学习率、warmup、batch size、优化器、训练步数等信息。这些细节属于被分析模型(MusicGen, YuE)的原始训练配置,本文未重复给出。
关键超参数:
- 模型大小:测试了MusicGen的四个版本:Small (300M), Medium (1.5B), Large (3.3B), Melody (1.5B);以及YuE (1B)。
- 分词器:EnCodec,将音频转换为RVQ token。
- 扰动设置:
- 噪声类型:白噪声,响度匹配原始音频(-30至-12 dB)。
- 注入长度:5, 10, 50, 100, 150, 200个token(对应0.1秒至4秒)。
- 顺序打乱长度:1, 2, 5, 10, 35, 50, 70, 100, 150, 200个token。
- 注入位置:在总长750 token(15秒)序列的第250 token(5秒)处开始。
训练硬件:论文中未提及具体的GPU/TPU型号、数量和训练时长。
推理细节:对于生成数据,提到了使用不同的top-k值(10, 50, 100, 150, 200, 250, 500等)进行采样,但未提供具体的温度或其他解码参数。
正则化或稳定训练技巧:论文中未提及。
📊 实验结果
论文的实验主要围绕“噪声注入”和“顺序打乱”两种扰动展开,旨在分析损失的变化规律。
- 噪声注入实验的整体趋势(图2) 实验对比了三个数据集(OOD, TrainingSet, Generated)在四个MusicGen模型上的表现。下表总结了各模型在不同数据集上的平均损失及标准差:
| 模型 | 数据集 | 平均损失 (± 标准差) |
|---|---|---|
| MusicGen Small | OOD | 4.19 ± 1.01 |
| TrainingSet | 5.41 ± 0.83 | |
| Generated | 5.59 ± 1.18 | |
| MusicGen Medium | OOD | 6.47 ± 0.66 |
| TrainingSet | 6.81 ± 0.67 | |
| Generated | 6.71 ± 0.63 | |
| MusicGen Melody | OOD | 3.83 ± 0.90 |
| TrainingSet | 5.27 ± 0.97 | |
| Generated | 5.18 ± 1.14 | |
| MusicGen Large | OOD | 5.88 ± 0.68 |
| TrainingSet | 6.64 ± 0.64 | |
| Generated | 6.19 ± 1.10 |
关键结论:随着注入噪声长度的增加,损失差 Δℓ 普遍变为负值(即损失降低)。此趋势在所有模型和数据集上一致,并通过Pearson/Spearman相关检验(r < -0.85, p < 0.001)得到验证。YuE模型上也复现了此现象。
 图2显示了损失差(Δℓ)随噪声注入长度变化的趋势。横轴为噪声长度(token),纵轴为损失差。三条线分别代表OOD、TrainingSet和Generated数据集。在所有子图(a-d)中,随着噪声长度增加,损失差普遍呈下降趋势,且为负值。
图2显示了损失差(Δℓ)随噪声注入长度变化的趋势。横轴为噪声长度(token),纵轴为损失差。三条线分别代表OOD、TrainingSet和Generated数据集。在所有子图(a-d)中,随着噪声长度增加,损失差普遍呈下降趋势,且为负值。
- 损失动态分析:三阶段效应(图3,图4)
通过对扰动区间的逐Token损失差
Δℓ_t进行可视化和自动区域检测,论文发现了三个特征区域: 图3示意性地展示了在音乐上下文中注入噪声时,绝对损失的动态变化。横轴为时间(token),纵轴为绝对损失。可以清晰看到三个阶段:1) 噪声开始时的“Peak”(峰值);2) 噪声持续期间的“Assimilation”(同化,损失降低);3) 噪声结束后的“Recovery”(恢复,损失波动)。
图3示意性地展示了在音乐上下文中注入噪声时,绝对损失的动态变化。横轴为时间(token),纵轴为绝对损失。可以清晰看到三个阶段:1) 噪声开始时的“Peak”(峰值);2) 噪声持续期间的“Assimilation”(同化,损失降低);3) 噪声结束后的“Recovery”(恢复,损失波动)。
 图4展示了通过自动化区域检测方法,在四个MusicGen模型上量化得到的三个区域(Peak, Assimilation, Recovery)的平均损失差。所有模型均显示Peak区域损失差为正(约0.5-0.8),Assimilation区域损失差为负(范围从-0.86到-3.83),Recovery区域接近零。这定量验证了三阶段行为。
图4展示了通过自动化区域检测方法,在四个MusicGen模型上量化得到的三个区域(Peak, Assimilation, Recovery)的平均损失差。所有模型均显示Peak区域损失差为正(约0.5-0.8),Assimilation区域损失差为负(范围从-0.86到-3.83),Recovery区域接近零。这定量验证了三阶段行为。
- 顺序打乱实验(图5)
作为更接近真实音乐结构破坏的扰动,顺序打乱实验也观察到了类似的模式:短段打乱导致损失峰值,长段打乱后模型适应新顺序,整体损失变化不大。
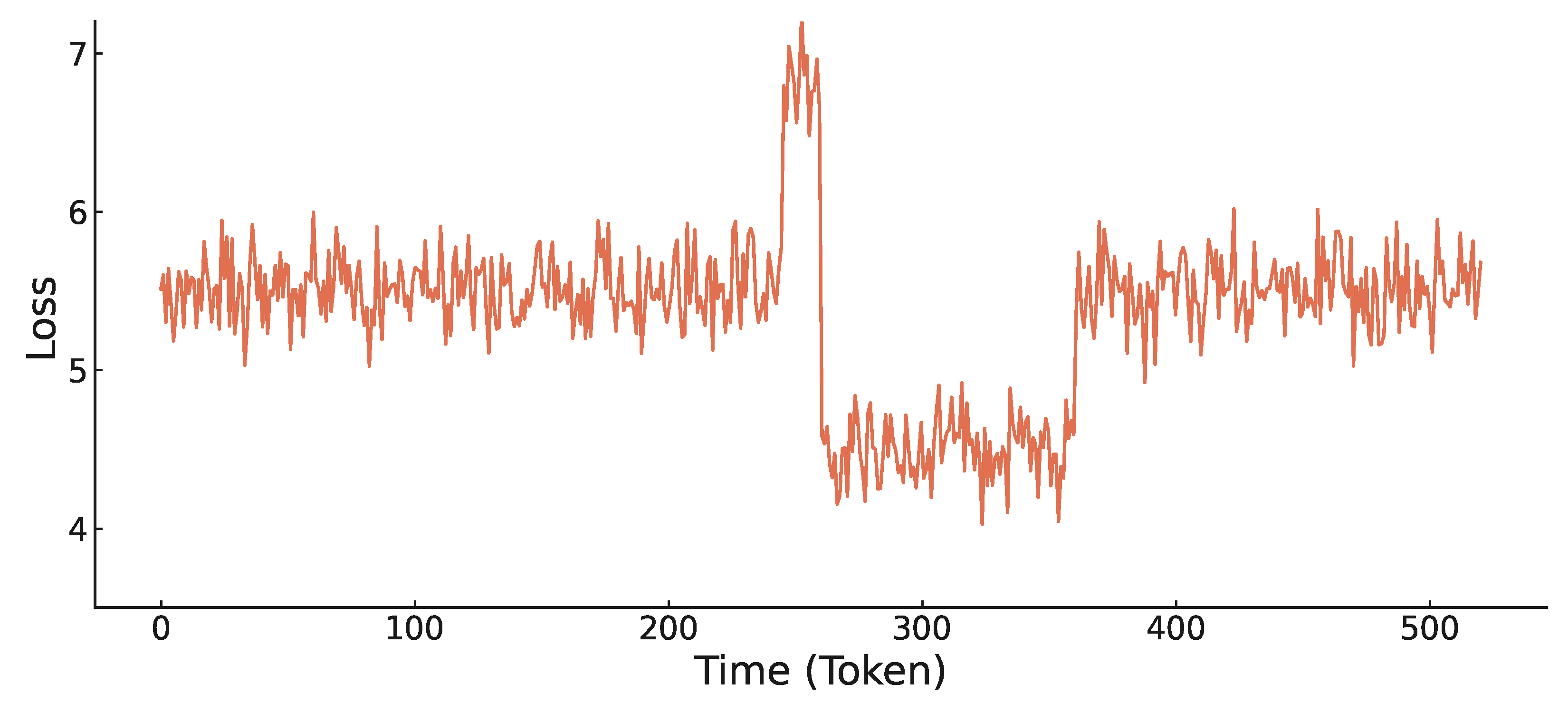 图5左侧示意了将音乐片段顺序打乱的操作。右侧的图表(虽然标签被截断,但根据描述)显示了类似的损失差随打乱长度变化的趋势,与噪声注入实验结论一致。
图5左侧示意了将音乐片段顺序打乱的操作。右侧的图表(虽然标签被截断,但根据描述)显示了类似的损失差随打乱长度变化的趋势,与噪声注入实验结论一致。
⚖️ 评分理由
学术质量:6.0/7
- 创新性(2/2):提出了“上下文遗忘效应”这一新概念,并通过系统实验加以验证,为理解音乐LLM的评估偏差提供了新颖的视角。从“损失绝对值”转向“损失曲线形状”的评估思路具有启发性。
- 技术正确性(1.5/2):实验设计合理,控制了变量(噪声响度、注入位置、长度),使用了多种数据和模型进行验证,统计分析(相关性检验)方法恰当。结论与实验数据吻合。
- 实验充分性(1.5/2):实验覆盖了主要变量(模型尺寸、数据类型、扰动类型/长度),并进行了自动化区域检测作为定量验证。然而,实验主要停留在对现有模型的分析上,缺乏对所提“基于曲线形状评估”框架的进一步开发、定义和验证,使说服力略有折扣。
- 证据可信度(1/1):论文公开了代码和演示页面,增强了结果的可复现性。实验现象在多个设置下稳健复现。
选题价值:1.0/2
- 前沿性(0.5/1):针对音乐生成评估这一关键但研究尚不充分的环节,指出了当前主流方法(基于损失)的局限性,选题切中要害。
- 潜在影响与应用空间(0.5/1):研究结果对指导音乐生成模型的评估基准设计、训练目标改进(如缓解暴露偏差)有直接参考价值。但其影响范围主要局限于模型评估这一特定任务,对生成模型架构本身的直接影响有限。与广义的音频/语音大模型读者的相关性中等。
开源与复现加成:0.5/1
- 论文明确提供了代码和演示页面的链接(
https://noiseloss.github.io),并详细描述了实验设置(数据、扰动参数),这为复现其分析实验提供了良好基础。然而,它分析的模型(MusicGen, YuE)本身是已有的开源模型,而非论文自己训练的模型,因此“复现”主要指复现其评估分析流程,而非训练过程。
- 论文明确提供了代码和演示页面的链接(