📄 What the student learns in knowledge distillation: A subspace view and evidence on Convolutional Recurrent Network
#知识蒸馏 #语音增强 #模型压缩 #子空间学习
✅ 6.5/10 | 前50% | #语音增强 | #知识蒸馏 | #模型压缩 #子空间学习
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Bo Jin(清华大学电子工程系)
- 通讯作者:Dongmei Li(清华大学电子工程系)
- 作者列表:Bo Jin(清华大学电子工程系),Timin Li(清华大学电子工程系),Guhan Chen(清华大学统计与数据科学系),Dongmei Li(清华大学电子工程系)
💡 毒舌点评
论文的理论推导部分将卷积层线性化并建立统一的子空间损失形式,确实为理解知识蒸馏提供了一个优雅的数学视角,这是其核心亮点。但遗憾的是,所有实验都局限于DCCRN这一特定模型在语音增强任务上的表现,缺乏在其他经典架构(如ResNet、Transformer)或任务(如图像分类)上的跨域验证,大大削弱了其“统一视角”宣称的说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的Interspeech 2021 DNS Challenge数据集和DNS2020片段,论文中未提供数据集下载链接,但指明了数据集名称。
- Demo:未提及。
- 复现材料:提供了较详细的实现细节(如数据集预处理、模型配置、优化器设置、训练轮数对应关系),但缺乏完整的脚本和配置文件。
- 论文中引用的开源项目:引用了DCCRN模型的原始论文 [12]。
📌 核心摘要
这篇论文旨在从统一的子空间视角解释知识蒸馏的工作原理。其核心方法是将卷积神经网络局部线性化,证明在该表示下,一大类知识蒸馏损失可统一为投影残差目标,进而等价于一个迹最大化问题,即学生的有限容量被引导去对齐教师模型的主能量子空间。与已有研究相比,该工作提出了一种更形式化、更统一的解释框架,并能够解释在语音增强实验中观察到的三个稳健现象:1) 多阶段蒸馏优于单阶段蒸馏;2) 多层特征蒸馏通常优于等层匹配蒸馏;3) 样本级别的教师-学生一致性会涌现。实验在DNS Challenge数据集上使用DCCRN模型进行,结果显示,相比无蒸馏基线,所测试的知识蒸馏方法均能提升学生模型性能(例如,1/16学生模型在CLSKD方法下STOI达到0.886,WB-PESQ达到2.732)。该论文的实际意义在于为知识蒸馏的机制提供了新的理论解释,并可指导蒸馏策略的设计。主要局限性是理论验证仅在单一架构(DCCRN)和单一任务(语音增强)上进行,普适性有待进一步检验。
表1: 非混响测试集上蒸馏与非蒸馏模型的客观语音指标对比
| 模型 | 方法 | 参数量 | STOI | WB-PESQ |
|---|---|---|---|---|
| DCCRN-T (教师) | 无 | 3.67M | 0.895 | 2.991 |
| DCCRN-S (学生) | 无 | 0.23M | 0.863 | 2.565 |
| DCCRN-S (学生) | RespondKD | 0.23M | 0.871 | 2.650 |
| DCCRN-S (学生) | FitNets | 0.23M | 0.874 | 2.588 |
| DCCRN-S (学生) | ReviewKD | 0.23M | 0.874 | 2.677 |
| DCCRN-S (学生) | CLSKD | 0.23M | 0.886 | 2.732 |
表2: 两个样本在DNSMOS P.835上的表现(分数越高越好)
| 模型 | pub talk.wav | mensa talk.wav | ||||
|---|---|---|---|---|---|---|
| OVRL | SIG | BAK | OVRL | SIG | BAK | |
| 有噪 | 1.143 | 1.256 | 1.209 | 2.492 | 3.538 | 2.675 |
| DCCRN-T (教师) | 2.128 | 2.726 | 3.065 | 2.951 | 3.315 | 3.810 |
| FitNets 1/4 | 2.217 | 2.908 | 3.011 | 2.935 | 3.315 | 3.954 |
| RespondKD 1/4 | 2.122 | 2.845 | 2.810 | 2.842 | 3.357 | 3.610 |
| FitNets 1/16 | 2.181 | 2.832 | 2.969 | 2.749 | 3.228 | 3.599 |
| RespondKD 1/16 | 1.943 | 2.609 | 2.690 | 2.669 | 3.197 | 3.518 |
🏗️ 模型架构
本文的研究重点并非提出一个新的网络架构,而是利用一个现成的、广泛使用的语音增强模型——深度复数卷积循环网络(DCCRN)——作为验证其理论视角的载体。
- 教师模型 (DCCRN-T):一个标准的DCCRN模型。其架构是一个基于U-Net的编解码器,中间嵌入了一个复数LSTM循环模块,能够同时处理语音的幅度和相位。编码器各层通道宽度为[32, 64, 128, 256, 256, 256],解码器对称设计。卷积核大小和步长在频率和时间轴上分别为(5,2)和(2,1)。循环模块是一个2层的复数LSTM,每层有256个单元。
- 学生模型 (DCCRN-S):与教师模型共享相同的拓扑结构,但通过通道宽度缩放来减少参数量。例如,1/4和1/16学生模型的通道宽度相应按比例缩小。论文重点验证的是一个0.23M参数的1/16学生模型。
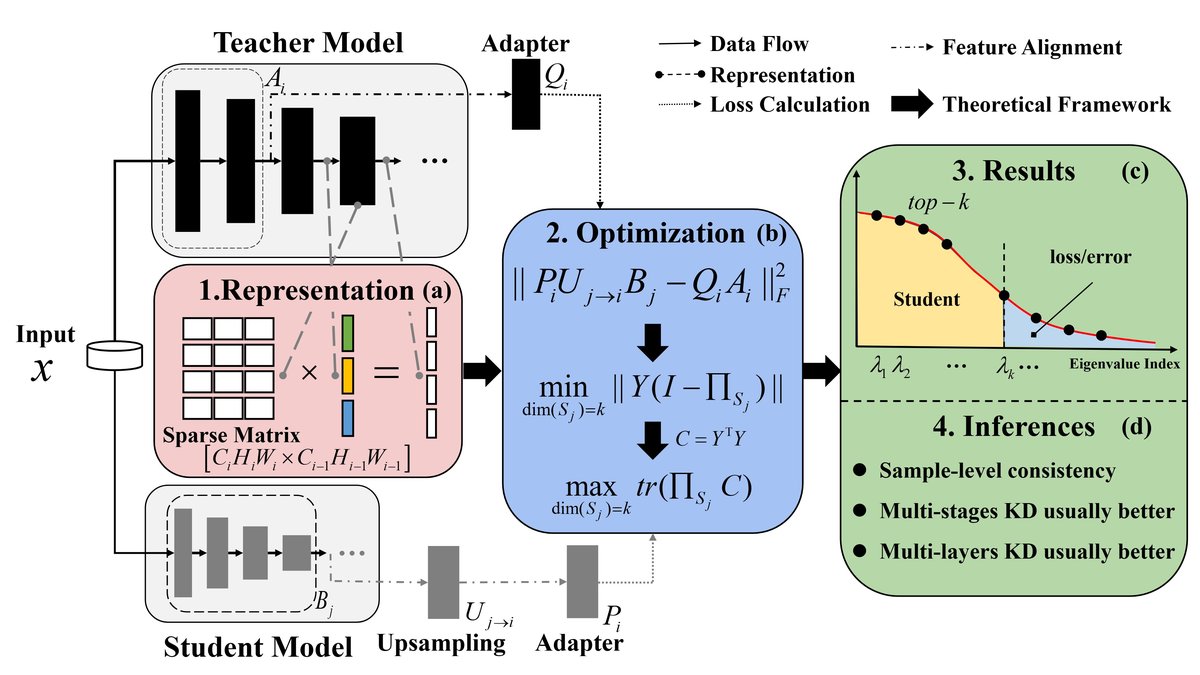 图1展示了论文提出理论框架的概览。(a) 部分展示了将传统卷积网络层(左)线性化为统一的稀疏矩阵-向量乘法形式(右)的表示过程,使得所有层的输出都位于同构的向量空间中。(b) 部分展示了在此表示下,广泛的蒸馏损失可以归结为一个投影残差形式,并等价于一个迹最大化优化问题。(c) 部分展示了根据Eckart-Young-Mirsky定理,最优学生子空间S⋆由教师特征矩阵Y的前k个右奇异向量(即协方差矩阵C=Y^⊤Y的k个最大特征值对应的特征向量)张成。
图1展示了论文提出理论框架的概览。(a) 部分展示了将传统卷积网络层(左)线性化为统一的稀疏矩阵-向量乘法形式(右)的表示过程,使得所有层的输出都位于同构的向量空间中。(b) 部分展示了在此表示下,广泛的蒸馏损失可以归结为一个投影残差形式,并等价于一个迹最大化优化问题。(c) 部分展示了根据Eckart-Young-Mirsky定理,最优学生子空间S⋆由教师特征矩阵Y的前k个右奇异向量(即协方差矩阵C=Y^⊤Y的k个最大特征值对应的特征向量)张成。
关键设计选择:选择DCCRN是因为其在语音增强中的优异性能和简单的“U-Net + LSTM”设计。更重要的是,其卷积层特性允许作者应用“局部线性化”技术(灵感来自im2col),将整个网络转化为一系列线性仿射算子的级联,从而能够进行统一的谱分析和跨层对齐。
💡 核心创新点
统一的子空间理论视角:这是最核心的创新。通过将卷积层线性化,作者证明了一大类知识蒸馏损失(如HCL, SKD)可以统一为最小化“教师特征在学生子空间外的能量”(公式11),这等价于最大化一个迹目标
tr(ΠS C)(公式15)。该视角揭示了KD的本质:学生的有限容量被分配去捕捉教师特征的主能量方向。- 之前方法的局限:以往对KD机制的解释(如信息论、梯度分析)较为零散,缺乏一个统一的数学框架来解释不同蒸馏损失为何有效,也难以系统性地指导设计。
- 如何起作用与收益:该理论统一了响应式、特征式蒸馏,并自然解释了后续的三个实验现象(见下文)。它提供了对KD过程的“过程级”理解,而非仅仅是最终性能比较。
解释三个稳健实验现象:
- 多阶段蒸馏优于单阶段蒸馏:从子空间视角看,多阶段蒸馏将一个困难的全局子空间对齐任务,分解为一系列更容易的局部对齐子任务,每一步都在已部分对齐的基础上进行优化,从而能获得更好的迹目标值,并稳定训练。
- 多层特征蒸馏优于等层匹配:在多层蒸馏中,目标协方差矩阵Cstack来自多个教师层的特征堆叠。最大化
tr(ΠS Cstack)促使学生去捕捉跨层稳定共享的主方向,这对于容量有限的学生尤其重要,避免了试图僵硬拟合某一层复杂特征导致的性能下降。 - 样本级别的教师-学生一致性涌现:该现象从子空间视角看,意味着困难样本(难对齐到教师主子空间)对于教师和学生都是困难的,因为教师偏见和关键模式都被编码在高能量子空间中,并传递给了学生。
过程级实验证据:论文不仅报告最终性能,还设计了一个“子空间能量监控器”(图3),动态追踪学生模型第一层编码器输出能量在教师前k个主子空间中的占比。这个监控器为理论提供了直接的过程证据:随着蒸馏权重增加,该占比显著上升,证实了KD确实在引导学生对齐教师的主导子空间。
🔬 细节详述
训练数据:
- 数据集:使用Interspeech 2021 DNS Challenge数据集。纯净语音和噪声以16 kHz采样,信噪比从[-5, 15] dB均匀采样混合。采用“重混”策略,每轮训练重新采样纯净-噪声对。每条混合语音切分为3秒。
- 预处理:使用512点FFT,30 ms汉宁窗,7.5 ms帧移进行STFT。
- 验证集:使用相同流程生成的保留集。此外,使用公开的DNS2020片段进行感知评估,指标为DNSMOS P.835 (OVRL/SIG/BAK)。
损失函数:
- 主损失:论文主要对比的知识蒸馏损失包括:ResponseKD(响应式蒸馏)、FitNets(特征式蒸馏)、ReviewKD(HCL损失)和CLSKD(跨层相似性蒸馏)。具体公式见原文。
- 监控实验损失:在图3的消融中,总损失为
L_total = (1−v)L_sup + vL_FitNets,其中v控制蒸馏权重(0, 0.95, 1),L_sup是监督损失(如SI-SDR损失,论文未明确说明,但通常用于语音增强)。
训练策略:
- 公平性:为确保公平比较,所有训练方案匹配总优化器更新次数。在作者的数据集和批大小设置下,对应:单阶段蒸馏240轮,多阶段蒸馏每阶段120轮。
- 优化器:Adam优化器,学习率0.001,批大小32。
- 多阶段蒸馏:教师先蒸馏给1/4学生,然后1/4学生再蒸馏给1/16学生。
关键超参数:
- 教师模型参数:3.67M。
- 1/16学生模型参数:0.23M。
- 蒸馏权重
v在消融实验中取值:0, 0.95, 1。
训练硬件:论文中未提及。
推理细节:论文中未提及。
正则化或稳定训练技巧:论文中未明确提及除标准技巧外的特殊技巧。
📊 实验结果
主要Benchmark与数据集:Interspeech 2021 DNS Challenge测试集(非混响),以及用于感知评估的DNS2020片段子集。
主要指标:STOI(短时客观可懂度), WB-PESQ(宽带感知语音质量评估), DNSMOS P.835 (OVRL/SIG/BAK)。
关键结果:
- 蒸馏 vs. 无蒸馏基线:如表1所示,在相同0.23M参数量下,所有蒸馏方法(ResponseKD, FitNets, ReviewKD, CLSKD)相比无蒸馏的DCCRN-S学生模型,在STOI和WB-PESQ上均有提升。其中CLSKD在STOI(0.886)和WB-PESQ(2.732)上取得最佳结果。
- 多阶段 vs. 单阶段蒸馏:图2直观显示了多阶段策略的优越性。文字描述指出,对于1/16学生模型,两阶段训练比单阶段训练一致产生更高的WB-PESQ和STOI。
- 多层 vs. 等层蒸馏:表1中,多层特征蒸馏方法(ReviewKD, CLSKD)的WB-PESQ得分(2.677, 2.732)普遍高于等层蒸馏的FitNets(2.588)。
- 过程级证据:图3显示了子空间能量监控结果。在无蒸馏(v=0)时,学生能量落入教师top-k子空间的比例约为20%。随着蒸馏权重v增加到0.95和1,该比例快速上升,但完全依赖蒸馏(v=1)且无监督损失时,SI-SDR性能下降,表明需要平衡。
- 样本级一致性:表2展示了两个样本在不同模型上的DNSMOS分数,显示了教师和蒸馏学生模型在样本难度排序上的一致性。
⚖️ 评分理由
- 学术质量:5.5/7:理论创新性值得肯定,将KD统一为子空间对齐问题,推导严谨。但实验验证严重受限,所有结论仅在DCCRN上得出,缺乏在CV经典任务和其他网络架构(如ResNet, ViT)上的验证,这极大地限制了其“统一视角”主张的强度和普适性。实验部分的数字对比(如表1)差异有时较小,虽支持结论但震撼力不足。
- 选题价值:1.0/2:知识蒸馏是重要方向,但论文切入角度(子空间理论)偏向理论解释,应用端的推进有限。聚焦于语音增强这一特定任务,尽管有实用价值,但相对小众,对更广泛的AI社区吸引力一般。
- 开源与复现加成:0.0/1:论文明确提供了作者、机构、数据集、模型细节和部分实验结果。然而,未提供代码仓库、预训练模型权重或完整的实验配置文件。这使得独立研究者难以完全复现其工作和进行公平的扩展实验,因此加成分为0。