📄 WavLink: Compact Audio–Text Embeddings with a Global Whisper Token
#音频检索 #对比学习 #零样本 #预训练 #迁移学习
🔥 8.0/10 | 前25% | #音频检索 | #对比学习 | #零样本 #预训练
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Gokul Karthik Kumar (Technology Innovation Institute, Abu Dhabi, UAE)
- 通讯作者:未说明
- 作者列表:Gokul Karthik Kumar (Technology Innovation Institute, Abu Dhabi, UAE)、Ludovick Lepauloux (Technology Innovation Institute, Abu Dhabi, UAE)、Hakim Hacid (Technology Innovation Institute, Abu Dhabi, UAE)
💡 毒舌点评
这篇论文巧妙地将用于语音识别的Whisper模型“降维”用于音频文本嵌入,用一个全局token替代了1500个帧特征,在检索任务上取得了优于CLAP系列模型的效果,思路清晰且实用。然而,其在零样本分类(如ESC-50)上的性能落后于专用模型,表明为ASR预训练的特征在通用音频理解上仍有局限;同时,论文对“为何选择现代BERT并表现不佳”的讨论不够深入。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集(AudioCaps, Clotho, VGGSound, ESC-50, US8K, AIR-Bench, Auto-ACD, AudioSetCaps),但未提供额外或处理后的数据。
- Demo:未提及。
- 复现材料:提供了详细的训练超参数、硬件配置、模型尺寸规格,以及系统性的设计扫描思路,但这些信息仅存在于论文文本中,未以独立仓库或文档形式提供。
- 论文中引用的开源项目:依赖的主要开源项目为预训练模型Whisper、CLIP、ModernBERT以及LoRA方法。
📌 核心摘要
要解决的问题:当前大型音频语言模型普遍使用Whisper作为音频编码器(产生大量帧级特征),而音频文本嵌入模型(如CLAP)却主要使用HTSAT/PaST等专用编码器,两者存在方法论上的割裂。同时,如何获得紧凑高效的音频表示以降低存储和检索成本是一个关键挑战。
方法核心:提出WavLink模型,在预训练的Whisper编码器末尾添加一个可学习的全局token(而非使用全部帧特征),通过对比学习与文本编码器联合训练,将一段30秒音频映射为单个紧凑的嵌入向量。
新在哪里:首次将Whisper有效用于紧凑的音频文本嵌入任务;引入全局token作为内容自适应聚合器;系统性地探索了文本编码器、损失函数、微调策略等24种设计组合;采用两阶段训练和Matryoshka监督来提升性能与可扩展性。
主要实验结果:
- 检索任务:在AudioCaps和Clotho数据集上,WavLink-Large(761M参数)在Recall@1等指标上全面超越了LAION-CLAP、MGA-CLAP等基线。WavLink-Base(84M参数)性能也具竞争力。
- 零样本分类:在VGGSound上达到31.8%准确率(WavLink-Small),为最佳。但在ESC-50和US8K上落后于专用模型。
- 多选题问答(AIR-Bench):WavLink-Base(84M参数,1个token)平均准确率为42.0%,显著优于LAION-CLAP(35.8%),并接近参数量大43倍的Falcon3-Audio-3B(42.0%),仅落后Qwen2-Audio Instruct(44.0%)2个百分点。
- 可扩展性:通过Matryoshka监督,将嵌入维度压缩至1/8时,性能平均下降小于1个点。
关键数据表(摘自论文):
表2:检索性能(Recall@K)
模型 AudioCaps (T2A R@1) AudioCaps (A2T R@1) Clotho (T2A R@1) Clotho (A2T R@1) WavLink-Large 46.7 60.0 22.4 27.4 WavLink-Small 44.5 54.3 21.2 25.3 WavLink-Base 39.7 50.5 17.6 21.1 LAION-CLAP 36.1 46.8 16.1 22.7 MGA-CLAP 41.8 54.4 20.4 25.3 表4:多选题问答性能(Accuracy %)
模型 参数量(M) 音频Token数 总平均 声音平均 音乐平均 语音平均 WavLink-Base 84 1 42.0 48.3 47.9 34.4 LAION-CLAP 193 1 35.8 42.6 46.2 24.7 Qwen2-Audio Instruct 8400 750 44.0 49.8 46.1 43.5 Falcon3-Audio 3B 3600 750 42.0 53.4 42.2 35.1 实际意义:证明了Whisper的ASR预训练特征经过适配后,可以高效地用于通用音频文本嵌入任务,实现了一个模型兼顾存储/检索效率(单token)和强大的跨模态理解能力(在AIR-Bench上与大型音频-LLM性能接近)。
主要局限性:在强调细粒度分类和描述的任务(如ESC-50, US8K)上,性能不及专门为这些任务设计的CLAP模型;在需要精确时序对齐的任务(如音频定位)上,单token表示可能不如帧级特征的模型;论文未提供代码和预训练权重,限制了立即复现的可能。
🏗️ 模型架构
WavLink是一个双塔(Dual-Encoder)音频文本嵌入模型,架构如下:
- 输入:音频为对数梅尔频谱图,文本为自然语言描述。
- 音频塔:
- 骨干编码器:使用预训练的Whisper编码器。输入音频经过Whisper的卷积前端后,得到隐藏状态序列(对于30秒音频,约为1500个帧特征)。
- 全局Token聚合:在隐藏状态序列末尾追加一个可学习的参数向量(
acls ∈ R^{1×D})。将这个扩展后的序列输入Whisper的Transformer堆栈进行处理。 - 池化:取全局token在最后一层的输出
za作为整个音频的表示,替代了传统的平均池化或取CLS token。这是将1500个帧特征压缩为1个紧凑表示的关键设计。 - 投影与归一化:通过一个轻量级的线性投影层
fa将za映射到共享嵌入空间,然后进行L2归一化,得到最终音频嵌入ûa。
- 文本塔:
- 骨干编码器:使用CLIP文本编码器或ModernBERT。输入文本经过编码器,取其CLS token的输出
zt。 - 投影与归一化:通过线性投影层
ft和L2归一化,得到文本嵌入ût。
- 骨干编码器:使用CLIP文本编码器或ModernBERT。输入文本经过编码器,取其CLS token的输出
- 交互:音频嵌入
ûa和文本嵌入ût在共享的嵌入空间中计算相似度(如点积),用于对比学习训练和推理时的检索。
关键设计选择与动机:
- 全局Token:动机是为了用单一向量替代大量帧级特征,大幅降低存储和检索成本。该token是内容自适应的,其最终状态聚合了整个音频序列的信息。
- Whisper作为骨干:动机是利用其在海量语音数据上预训练获得的强大通用音频表示能力,填补其在紧凑嵌入任务中的应用空白。
- 两阶段训练:第一阶段在大规模合成/自动标注数据上训练,第二阶段在高质量人工标注数据上微调,以平衡规模和质量。
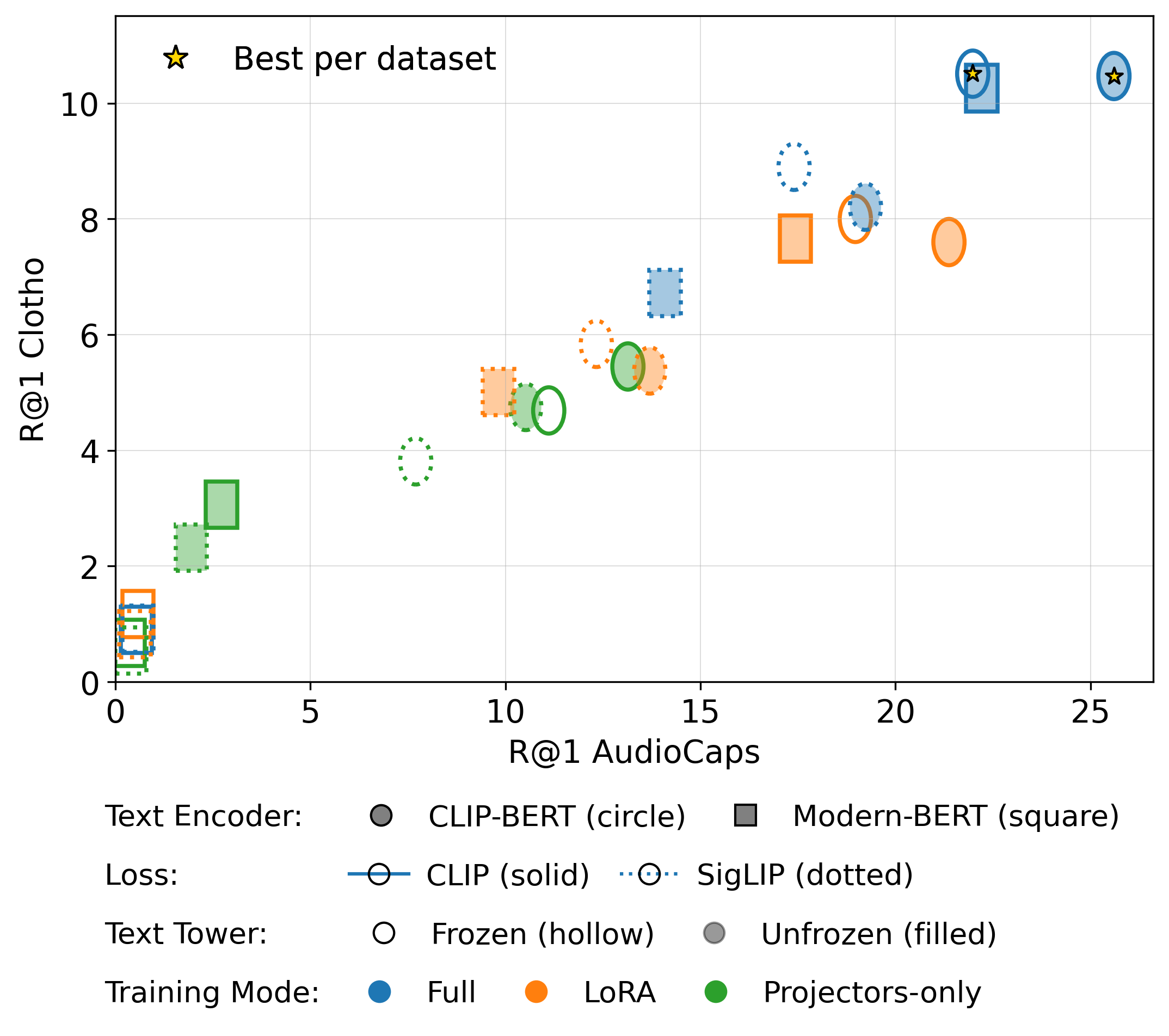 图1:基于AudioCaps和Clotho基准的Recall@1检索性能进行的设计扫描。横轴为不同配置,纵轴为R@1分数。该图表明,使用CLIP文本编码器、CLIP损失、全参数微调且双塔联合更新的配置是最佳选择。
图1:基于AudioCaps和Clotho基准的Recall@1检索性能进行的设计扫描。横轴为不同配置,纵轴为R@1分数。该图表明,使用CLIP文本编码器、CLIP损失、全参数微调且双塔联合更新的配置是最佳选择。
💡 核心创新点
- 首次将Whisper适配为紧凑音频文本嵌入的骨干:打破了音频-LLM和嵌入模型在骨干网络选择上的隔阂,证明了为ASR预训练的Whisper特征经适配后,在通用音频文本理解任务上具有强大潜力。
- 可学习的全局Token聚合机制:设计了一个简单但高效的机制,将Whisper的1500帧级表示聚合为单个向量。相比平均池化,该token能学习更复杂的内容自适应聚合策略。
- 系统性的设计扫描与两阶段训练策略:对24种组合进行了系统评估,确定了最优配置(CLIP文本编码器、CLIP损失、全参数微调、双塔更新),并设计了从大规模粗数据到小规模精数据的两阶段训练流程,保证了模型性能。
- 引入Matryoshka监督实现多分辨率嵌入:通过在不同嵌入维度(如768, 384, 192, 96)上施加对比损失,训练出的单个模型能输出不同长度的嵌入,且在维度压缩时性能损失极小(<1%),极大提升了部署灵活性和效率。
🔬 细节详述
- 训练数据:
- 设计扫描阶段:约200万音频文本对,来自Auto-ACD数据集(基于AudioSet和VGGSound)。
- 扩大训练阶段(Stage-1):额外约600万描述,来自AudioSetCaps数据集(基于AudioSet, VGGSound, YouTube-8M)。
- 微调阶段(Stage-2):约10万描述,来自AudioCaps v2和Clotho训练集。
- 损失函数:
- CLIP损失(InfoNCE):标准的双向对比损失,使用可学习温度参数。
- SigLIP损失:基于Sigmoid的二元交叉熵损失,对所有样本对进行计算,仅将对角线对标记为正样本。
- 训练策略:
- 优化器:AdamW,学习率1e-4,余弦学习率调度器,5%的warmup。
- Batch Size:设计扫描为80;扩大训练为768。
- 训练轮数:设计扫描为10轮;扩大训练每个阶段3轮。
- 精度:BF16混合精度。
- 并行策略:DDP,嵌入在计算损失前跨GPU收集。
- 关键超参数:
- 模型尺寸:Large(637M音频+123M文本), Small(88M+63M), Base(20M+63M)。
- 嵌入维度:Large支持768及以下(通过Matryoshka), Small/Base支持512及以下。
- Matryoshka维度:K=4, 目标维度为d, d/2, d/4, d/8。
- LoRA:设计扫描中使用的LoRA秩为8。
- 训练硬件:
- 设计扫描:8× H100 80GB GPU。
- 扩大训练:64× H100 80GB GPU。
- 推理细节:未说明解码策略等细节,因为该模型是嵌入模型,主要用于计算相似度和检索,而非生成。
- 正则化技巧:未说明使用了Dropout等技巧。
📊 实验结果
论文在三个主要任务上进行了评估:
音频文本检索(AudioCaps & Clotho):使用召回率(Recall@K)作为指标。WavLink在所有变体上均超越或持平先前CLAP模型。关键结果见上述表2。消融实验显示,用HTS-AT替换Whisper编码器后,性能显著下降,尤其在长音频数据集Clotho上,证明了Whisper作为骨干的鲁棒性。
零样本音频分类(VGGSound, US8K, ESC-50):使用准确率(Accuracy)作为指标。结果见下表。
| 模型 | VGG-Sound | US8K | ESC-50 |
|---|---|---|---|
| WavLink-Large | 31.7 | 74.5 | 83.0 |
| WavLink-Small | 31.8 | 75.0 | 80.3 |
| WavLink-Base | 27.7 | 69.9 | 75.4 |
| LAION-CLAP | 29.1 | 73.2 | 89.1 |
| MGA-CLAP | 31.8 | 83.7 | 94.9 |
| ReCLAP | 29.2 | 95.2 | 92.8 |
WavLink在VGGSound上表现优异,但在ESC-50和US8K上落后于专为分类设计的CLAP模型,可能原因在于训练数据描述风格差异。
多选题问答(AIR-Bench Foundational):将MCQ重构为零样本分类任务。结果见上述表4。WavLink-Base在仅使用1个token和84M参数的情况下,总平均准确率(42.0%)大幅超越LAION-CLAP(35.8%),与Falcon3-Audio-3B持平,并接近Qwen2-Audio Instruct。这表明其紧凑表示在复杂音频推理任务上具有惊人竞争力。在声音和音乐子任务上表现强劲,在语音任务上也优于基线,但在需要精确定位的任务上较弱。
可扩展性:论文强调,通过Matryoshka监督,将嵌入维度降至1/8时,检索性能平均下降小于1个点(见表2中“∆ M-1/8”行)。这为存储和检索提供了极大的效率优化空间。
⚖️ 评分理由
学术质量:6.5/7
- 创新性:明确。将Whisper引入紧凑嵌入任务并设计全局token聚合机制是核心贡献,系统性的设计扫描方法论也值得肯定。
- 技术正确性:高。方法描述清晰,训练和评估流程规范,实验设计合理。
- 实验充分性:充分。覆盖了检索、分类、问答多个任务,进行了详细的设计扫描和消融实验,并提供了不同模型尺寸的对比。
- 证据可信度:高。结果以标准benchmark和指标呈现,与强基线进行了公平对比。
选题价值:1.5/2
- 前沿性:高。弥合音频-LLM和嵌入模型之间的差距,探索高效表示是热门方向。
- 潜在影响:中高。为音频文本嵌入提供了新的骨干选择,其紧凑表示特性对工业级检索和部署有直接价值。
- 实际应用空间:大。音频检索、零样本分类、推荐系统等。
- 读者相关性:对从事音频多模态学习、表示学习、检索系统的研究者和工程师有较高价值。
开源与复现加成:0.2/1
- 论文详细描述了模型架构、训练配置和数据,但未提供代码、预训练模型权重、或复现脚本的链接。因此,尽管方法描述清晰,但缺少关键复现材料,显著影响了可重复性加成。