📄 WaveSP-Net: Learnable Wavelet-Domain Sparse Prompt Tuning for Speech Deepfake Detection
#语音伪造检测 #时频分析 #预训练 #自监督学习 #参数高效微调
🔥 8.0/10 | 前25% | #语音伪造检测 | #时频分析 #预训练 | #时频分析 #预训练
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xi Xuan(University of Eastern Finland)
- 通讯作者:Xi Xuan(University of Eastern Finland, 邮箱:xi.xuan@uef.fi)
- 作者列表:
- Xi Xuan(University of Eastern Finland)
- Xuechen Liu(National Institute of Informatics)
- Wenxin Zhang(University of Chinese Academy of Sciences, University of Toronto)
- Yi-Cheng Lin(National Taiwan University)
- Xiaojian Lin(Tsinghua University)
- Tomi Kinnunen(University of Eastern Finland)
💡 毒舌点评
亮点: 论文巧妙地将经典的、可解释的小波变换(多分辨率分析)与前沿的参数高效微调(Prompt Tuning)相结合,不仅提升了检测性能,还通过消融实验有力地证明了可学习小波滤波器和稀疏化机制的关键作用,这种“老树开新花”的思路值得肯定。
短板: 尽管在DE24和SpoofCeleb两个基准上表现优异,但论文的实验验证相对局限,主要依赖于SSL模型XLSR和特定后端Mamba,未能探讨该小波提示框架在其他预训练模型(如HuBERT)或更轻量级端侧模型上的泛化能力与适用性,其“普适性”有待更广泛验证。
🔗 开源详情
- 代码: 提供代码仓库链接:https://github.com/xxuan-acoustics/WaveSP-Net。
- 模型权重: 论文未明确提及是否提供预训练模型权重下载。
- 数据集: 使用的DE24和SpoofCeleb均为公开基准数据集,论文提供了数据集获取链接(DE24: https://huggingface.co/datasets/nuriachandra/Deepfake-Eval-2024, SpoofCeleb: https://www.jungjee.com/spoofceleb/)。
- Demo: 未提及。
- 复现材料: 提供了完整的实现细节,包括:音频预处理方式、使用的SSL模型(XLSR-300M)、提示令牌数量、稀疏比率、Mamba块数量、dropout率、batch size、学习率、优化器、训练轮数、早停策略以及开发集选择标准。
- 论文中引用的开源项目: 依赖Facebook的XLSR-300M预训练模型(Hugging Face提供)。
📌 核心摘要
- 问题: 当前基于全微调大型自监督模型(如XLSR)的语音深度伪造检测方法参数效率低,且在面对真实世界中未见过的复杂攻击、编解码器和压缩格式时,泛化能力可能不足。
- 方法核心: 提出了一种新型参数高效前端 WaveSP-Net,其核心是“可学习小波域稀疏提示调优”(Partial-WSPT)。该方法冻结XLSR参数,为每一层引入一组可学习的提示令牌(Prompt Tokens),并创新性地对其中部分令牌进行小波域增强处理:通过可学习的小波分解(LWD)提取信号的多分辨率特征,利用随机稀疏化(WDS)进行正则化与去噪,最后通过可学习的小波重构(LWR)将处理后的特征合并回提示令牌序列。该前端与一个双向Mamba后端分类器相结合。
- 创新之处: 与未结构化的普通提示调优相比,该方法首次将结构化的、具有时频局部化能力的小波变换引入到提示嵌入中,通过施加信号处理领域的先验知识来约束和增强提示令牌,使其能更有效、更稀疏地引导模型关注与伪造伪影相关的频带和时间局部特征。
- 主要结果: 在两个具有挑战性的新基准 Deepfake-Eval-2024 (DE24) 和 SpoofCeleb 上,WaveSP-Net 取得了最佳性能。在DE24上,其EER为10.58%(相比最强基线XLSR-1B的11.85%有10.72%的相对改进);在SpoofCeleb上,EER低至0.13%。同时,可训练参数量仅占模型总参数量的1.298%,体现了极高的参数效率。关键消融实验表明,移除稀疏化(WDS)会导致EER相对上升35.54%,而使用固定小波滤波器比使用可学习滤波器EER相对上升56.44%,验证了各组件的有效性。
- 实际意义: 该工作为语音安全领域提供了一种高效、高性能的检测模型,尤其适用于需要更新或适配大规模预训练模型以应对新攻击的场景,降低了计算和存储成本。
- 主要局限性: 论文主要评估了在两个特定大规模基准上的性能,未深入探讨在更极端退化条件(如高背景噪声、低比特率压缩)下的鲁棒性。此外,其Mamba后端虽然高效,但也引入了新的架构复杂性。
🏗️ 模型架构
WaveSP-Net 是一个端到端的语音深度伪造检测模型,其架构(如图1所示)可分为三个主要部分:冻结的SSL特征提取前端、可学习的小波域稀疏提示调优模块和Mamba后端分类器。
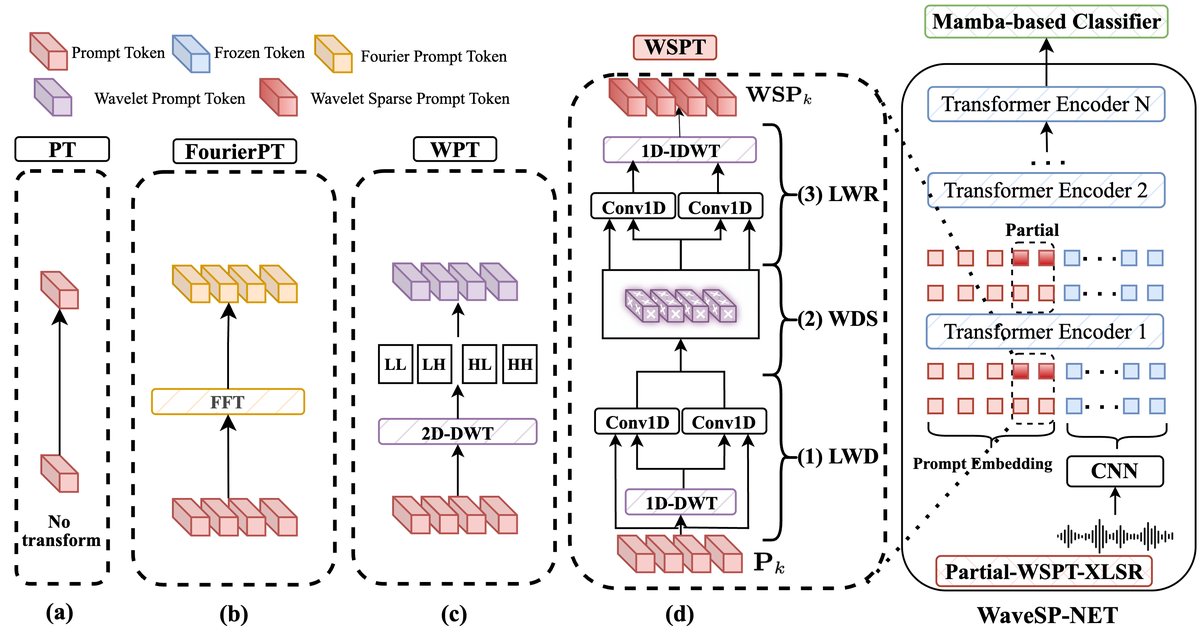 (图1:论文展示了五种XLSR前端变体,最右侧为提出的WaveSP-Net架构,集成Partial-WSPT-XLSR前端与Mamba分类器)
(图1:论文展示了五种XLSR前端变体,最右侧为提出的WaveSP-Net架构,集成Partial-WSPT-XLSR前端与Mamba分类器)
- 冻结的SSL特征提取前端 (XLSR-300M)
- 功能: 作为固定不变的特征提取器,将原始音频波形转换为高级语义特征表示。
- 内部结构: 采用Meta的 XLSR-300M 自监督预训练模型。输入为16kHz、4秒的音频,输出尺寸为(201, 1024)的2D特征图,其中201是时间步(帧数),1024是隐藏维度。
- 关键选择: 在训练和推理过程中,该模块的参数完全冻结,不进行更新。这既利用了其强大的通用语音表示能力,又确保了参数高效性。
- 可学习小波域稀疏提示调优模块 (Partial-WSPT) 这是WaveSP-Net的核心创新模块,作用于XLSR的每一个Transformer层。它为每一层引入一组可学习的提示令牌,并对其中的一部分进行增强。
- 提示令牌初始化: 在第k层,引入p个(论文中为10个)可学习的提示令牌
P_k ∈ R^(p×d),d为隐藏维度(1024)。这些令牌初始化后,在训练中被优化,作为“虚拟输入”引导冻结的XLSR层。 - 小波域增强 (LWD, WDS, LWR): 论文提出仅对最后m个(论文中为4个)提示令牌进行小波域处理,形成“部分”增强策略。
- (1) 可学习小波分解 (LWD): 使用一对可学习的低通分析滤波器
F0和高通分析滤波器F1,对选中的令牌进行1D离散小波变换,将其分解为低频(概貌)和高频(细节)系数。滤波器的系数在训练中更新,以自适应地提取与伪造检测最相关的信号成分。 - (2) 小波域稀疏化 (WDS): 将分解后的系数堆叠后,仅随机选择其中一小部分(稀疏比ρ=0.1)的位置进行更新。这借鉴了压缩感知的稀疏表示原理,起到隐式正则化、去噪和增强鲁棒性的作用。
- (3) 可学习小波重构 (LWR): 使用一对可学习的合成滤波器
H0和H1,将处理后的稀疏系数逆变换回令牌表示空间,生成增强后的令牌WSP_k。
- (1) 可学习小波分解 (LWD): 使用一对可学习的低通分析滤波器
- 融合与输出: 将增强后的
WSP_k与未处理的原始提示令牌拼接,形成最终的提示表示~P_k,其形状与原始P_k相同,但部分位置已被更优的表示替换。 - 数据流交互: 在每一层k,将增强后的提示令牌
~P_k与上一层的嵌入输出E_{k-1}拼接,共同输入该层的Transformer计算,得到更新后的嵌入E_k和提示输出Z_k。
- Mamba后端分类器
- 功能: 接收来自XLSR最后一层的完整输出(包括提示输出
Z_l和最终嵌入E_l),进行时序建模并做出二分类判断(真实/伪造)。 - 内部结构: 采用12个双向Mamba块。Mamba作为一种状态空间模型,能够以线性复杂度捕捉长程时序依赖,适合处理高维的波let域特征表示。
- 输出: 输出二分类概率。
💡 核心创新点
- 小波域稀疏提示调优框架: 首次提出将离散小波变换(DWT)与提示调优(PT)深度结合。不同于简单的特征增强,该方法通过可学习的小波滤波器和稀疏化机制,对提示令牌本身进行结构化、信号处理理论驱动的约束与增强,使提示能够更高效、更聚焦地引导冻结的大型模型。
- 部分增强策略: 创新性地采用“Partial-WSPT”策略,即仅对提示令牌集合的一个子集进行小波域处理。这既保留了原始提示的语义信息,又注入了经过精细加工的、富含多分辨率信息的特征,在效率和效果间取得了良好平衡。
- 可学习的小波滤波器: 舍弃了固定的小波基(如Haar),设计了可训练的分析/合成滤波器对。这使得模型能够根据语音伪造检测任务的具体需求,自适应地调整频率响应,更有效地分离真实语音与合成伪影的频谱特征。
- 端到端联合优化设计: 将新颖的WSPT前端与高效的Mamba后端进行端到端联合训练。前端负责生成更具判别性的提示特征,后端负责对这些特征进行强大的时序建模,两者协同工作,最大化检测性能。
🔬 细节详述
- 训练数据: 使用两个官方基准数据集进行独立训练和评估:
- Deepfake-Eval-2024 (DE24): 包含来自88个网站、42种语言的音频,经过预处理被切分为4秒片段。训练集、开发集和测试集划分遵循官方协议。
- SpoofCeleb: 训练包含攻击类型A01-A10,评估包含A15-A23。更多细节参见原始论文。
- 损失函数: 论文未明确提及具体损失函数名称,但根据其二分类任务性质,推断使用交叉熵损失 (Cross-Entropy Loss)。论文中提到“Models are trained with cross-entropy loss”。
- 训练策略:
- 优化器:Adam。
- 学习率:5e-4。
- 批大小:16。
- 训练轮数:最多100个epoch,采用早停策略:当开发集损失连续7个epoch不再下降时停止训练。
- 模型选择:根据开发集上最低的EER选择最终检查点。
- 正则化:使用了dropout,比例为0.1。
- 关键超参数:
- 提示令牌数:p=10(对于FT, FourierPT, WSPT);对于WPT和Partial-WSPT,包含4个小波令牌和6个常规令牌。
- 小波稀疏提示令牌数:m=4(在WaveSP-Net的最优配置中)。
- 稀疏比率:ρ=0.1(即仅更新10%的小波系数位置)。
- Mamba分类器:包含12个Mamba块。
- 训练硬件: 单卡Tesla V100 GPU。
- 推理细节: 论文未提及特殊解码策略,为标准前向传播。音频预处理为下采样至16kHz,并填充或裁剪至4秒固定长度。
- 其他: 论文提到所有实验在固定随机种子下进行。
📊 实验结果
主要性能对比 论文在两个挑战性基准上,将提出的三种前端变体(FourierPT-XLSR, WSPT-XLSR, Partial-WSPT-XLSR)与Mamba后端组合,并与多个SOTA模型进行了对比。
表1:提出的三种前端变体在DE24和SpoofCeleb上的性能对比
| 模型 | Deepfake-Eval-2024 | SpoofCeleb | ||||||
|---|---|---|---|---|---|---|---|---|
| EER (%) ↓ | ACC (%) ↑ | F1 (%) ↑ | AUC (%) ↑ | EER (%) ↓ | ACC (%) ↑ | F1 (%) ↑ | AUC (%) ↑ | |
| FourierPT-XLSR | 16.58 (±0.52) | 83.42 | 79.53 | 90.35 | 0.23 (±0.06) | 99.84 | 99.87 | 99.86 |
| WSPT-XLSR | 13.15 (±0.47) | 86.85 | 83.84 | 93.33 | 0.19 (±0.06) | 99.89 | 99.92 | 99.91 |
| Partial-WSPT-XLSR | 10.58 (±0.43) | 89.42 | 86.35 | 94.26 | 0.13 (±0.04) | 99.87 | 99.93 | 99.99 |
表2:与SOTA模型在Deepfake-Eval-2024上的对比
| 模型 | 可训练参数占比 | EER (%) ↓ | ACC (%) ↑ | F1 (%) ↑ | AUC (%) ↑ |
|---|---|---|---|---|---|
| AASIST | - | 16.99 (±0.52) | 83.60 | 77.80 | 90.60 |
| RawNet2 | - | 20.91 (±0.56) | 81.70 | 86.00 | 87.60 |
| P3 | - | 15.38 (±0.50) | 85.50 | 81.00 | 92.00 |
| XLS-R-1B | - | 11.85 (±0.45) | 86.83 | 89.43 | 94.35 |
| BCM | - | - | 89.00 | 87.00 | 93.00 |
| PT-XLSR | 4.145M | 20.40 (±0.56) | 79.60 | 77.19 | 90.21 |
| WPT-XLSR | 4.145M | 14.39 (±0.49) | 85.61 | 81.01 | 91.29 |
| WaveSP-Net | 4.146M (1.298%) | 10.58 (±0.43) | 89.42 | 86.35 | 94.26 |
表3:与SOTA模型在SpoofCeleb上的对比
| 模型 | 可训练参数占比 | EER (%) ↓ | ACC (%) ↑ | F1 (%) ↑ | AUC (%) ↑ |
|---|---|---|---|---|---|
| AASIST | - | 2.37 (±0.16) | 71.38 | 81.25 | 83.56 |
| RawNet2 | - | 1.12 (±0.11) | 87.23 | 88.92 | 92.14 |
| PT-XLSR | 4.145M | 0.26 (±0.06) | 99.74 | 99.85 | 99.93 |
| WPT-XLSR | 4.145M | 0.15 (±0.04) | 99.85 | 99.92 | 99.97 |
| WaveSP-Net | 4.146M (1.298%) | 0.13 (±0.04) | 99.87 | 99.93 | 99.99 |
关键结论:
- 波域优于傅里叶域: 在两个数据集上,基于小波变换的方法(WSPT, Partial-WSPT)均优于基于傅里叶变换的方法(FourierPT),表明联合时频分析对捕捉伪造伪影更有效。
- 部分增强策略最优: “部分增强”策略(Partial-WSPT)在所有指标上均优于对所有令牌进行增强(WSPT)或不增强(PT),证实了其设计的有效性。
- 全面超越SOTA: WaveSP-Net(使用Partial-WSPT前端)在DE24上实现了最低的EER(10.58%),相比强基线XLS-R-1B有显著提升。在SpoofCeleb上也达到了最优的EER(0.13%)。
- 极高参数效率: WaveSP-Net的可训练参数(约4.15M)仅占XLSR-300M总参数的1.298%,远低于全微调方案。
消融实验与参数敏感性分析(表4) 表4:WaveSP-Net在DE24上的消融实验与参数敏感性分析
| 实验设置 | EER (%) ↓ | ACC (%) ↑ | F1 (%) ↑ | AUC (%) ↑ |
|---|---|---|---|---|
| WaveSP-Net (完整) | 10.58 (±0.43) | 89.42 | 86.35 | 94.26 |
| Ablation1: 部件移除 | ||||
| 无可学习小波分解 (w/o LWD) | 12.97 (±0.47) | 87.03 | 84.37 | 94.00 |
| 无小波域稀疏化 (w/o WDS) | 14.34 (±0.49) | 85.66 | 83.09 | 93.73 |
| 无可学习小波重构 (w/o LWR) | 11.33 (±0.44) | 88.67 | 85.33 | 94.09 |
| Ablation2: 可学习 vs 固定滤波器 | ||||
| 使用固定小波滤波器 | 16.55 (±0.51) | 83.45 | 79.63 | 90.36 |
| Hyperparameter1: 稀疏比率 | ||||
| 0.5 | 12.42 (±0.46) | 87.58 | 84.49 | 93.44 |
| 0.7 | 13.84 (±0.48) | 86.16 | 83.31 | 93.56 |
| 0.9 | 12.73 (±0.46) | 87.27 | 84.28 | 93.75 |
| Hyperparameter2: 小波令牌数 | ||||
| 2 | 11.23 (±0.44) | 88.77 | 84.31 | 93.82 |
| 6 | 14.86 (±0.49) | 85.14 | 81.04 | 91.03 |
| 8 | 12.65 (±0.46) | 87.35 | 84.50 | 93.88 |
| 10 | 13.15 (±0.47) | 86.85 | 83.84 | 93.33 |
关键发现:
- 组件不可或缺: 移除任何一个核心组件(LWD, WDS, LWR)都会导致性能下降,其中移除WDS(稀疏化)造成的性能下降最严重(EER从10.58%升至14.34%),凸显了稀疏表示在过滤噪声和冗余信息中的关键作用。
- 可学习滤波器至关重要: 使用固定小波滤波器相比可学习滤波器,性能大幅下降(EER从10.58%升至16.55%),证明了滤波器参数与后端模型联合优化的重要性。
- 超参数敏感性: 最优配置为稀疏比0.1(论文中未列出0.1,但根据上下文及“Best results”可知最优为0.1),4个小波令牌。改变这些超参数(如增加令牌数至6个或提高稀疏比)通常会导致性能下降。
可视化结果(图2)

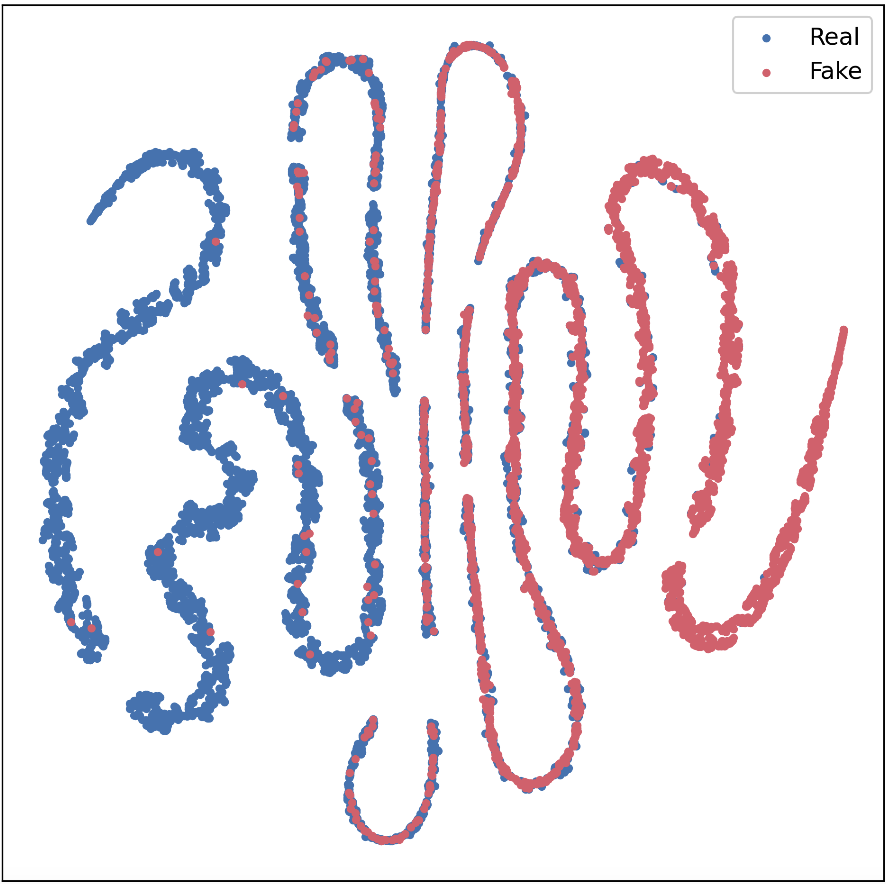
 (图2:DE24测试集的2D t-SNE可视化。(a) FourierPT-XLSR, (b) WSPT-XLSR, (c) Partial-WSPT-XLSR。蓝色为真实样本,红色为伪造样本。)
结论: 可视化图清晰地显示,相比前两种方法,Partial-WSPT-XLSR提取的特征在潜在空间中形成了真实样本与伪造样本之间更分离、更紧凑的聚类,直观地证明了该方法学习到更具判别性的特征表示的能力。
(图2:DE24测试集的2D t-SNE可视化。(a) FourierPT-XLSR, (b) WSPT-XLSR, (c) Partial-WSPT-XLSR。蓝色为真实样本,红色为伪造样本。)
结论: 可视化图清晰地显示,相比前两种方法,Partial-WSPT-XLSR提取的特征在潜在空间中形成了真实样本与伪造样本之间更分离、更紧凑的聚类,直观地证明了该方法学习到更具判别性的特征表示的能力。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性 (2.5/3): 将可学习小波变换与提示调优相结合是一个新颖且有启发性的想法,提出了Partial-WSPT的实现框架。创新点明确,技术路线合理。
- 技术正确性与实验充分性 (2.0/2.5): 论文技术描述清晰,方法设计有据可依。实验设计全面,包含了与多个SOTA基线的对比、详细的消融实验、超参数敏感性分析以及特征可视化。实验数据翔实,提供了EER的置信区间。
- 证据可信度 (1.5/1.5): 使用了公认的大规模基准数据集,实验设置标准,结果呈现规范,结论有数据支撑。
- 扣分点: 创新并非从0到1的突破,更多是在现有概念(PT, 小波)上的精巧组合与优化。实验虽然充分,但未能在更多样化的场景或更小的模型上验证其泛化性。
- 选题价值:1.5/2
- 前沿性 (0.8/1): 语音伪造检测是安全领域的重要前沿问题。参数高效微调是当前大模型时代的热门方向,两者结合具有前沿性。
- 潜在影响与应用空间 (0.7/1): 该方法为应对不断演变的伪造攻击提供了一种高效、可更新的模型适配方案,具有明确的实际应用价值,尤其适用于资源受限的更新场景。
- 开源与复现加成:+0.5/1
- 开源详情 (0.5/1): 论文明确提供了代码仓库链接(https://github.com/xxuan-acoustics/WaveSP-Net),并在“Implementation Details”部分提供了非常详细的超参数配置、训练硬件、优化器设置、停止准则等关键复现信息。模型权重未提及公开,但代码和配置的详细程度已大大降低复现门槛。