📄 Wavenext 2: Convnext-Based Fast Neural Vocoders with Residual Denoising and Sub-Modeling for Gan And Diffusion Models
#语音合成 #卷积神经网络 #扩散模型 #对抗生成网络
🔥 9.0/10 | 前25% | #语音合成 | #卷积神经网络 | #扩散模型 #对抗生成网络
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Wangzixi Zhou(奈良先端科学技术大学院大学 & 日本信息通信研究机构)
- 通讯作者:未说明
- 作者列表:Wangzixi Zhou(奈良先端科学技术大学院大学 & 日本信息通信研究机构)、Takuma Okamoto(日本信息通信研究机构)、Yamato Ohtani(日本信息通信研究机构)、Sakriani Sakti(奈良先端科学技术大学院大学)、Hisashi Kawai(日本信息通信研究机构)
💡 毒舌点评
该论文的最大亮点在于其“统一框架”的野心和务实的工程优化,用一个基于ConvNeXt的模块巧妙兼容了GAN与扩散两条技术路线,特别是将扩散模型声码器的训练时间压缩到32小时,对资源敏感场景极具吸引力。然而,其创新更多是架构整合与效率优化,而非底层原理突破,且随着迭代次数增加,模型大小线性膨胀(从15M到75M)的短板在资源严格受限的边缘设备上可能会抵消其部分速度优势。
🔗 开源详情
- 代码:论文中提供了演示页面链接 (https://37integer.github.io/WAVENEXT-2),但未提及WaveNeXt 2代码仓库链接。论文中引用了多个开源项目作为基线实现。
- 模型权重:未提及是否公开预训练模型权重。
- 数据集:使用的是公开的LibriTTS-R数据集。
- Demo:提供在线演示页面。
- 复现材料:提供了部分复现信息,包括训练硬件(A100 40GB)、训练时长、关键超参数(如梅尔谱维度、跳步大小、噪声调度等),但未提供完整的训练脚本、配置文件或检查点。
- 论文中引用的开源项目:ParallelWaveGAN(用于HiFi-GAN实现)、wavefit-pytorch、FastDiff官方实现、Vocos官方实现、BDDM(用于噪声调度预测)。
📌 核心摘要
- 要解决什么问题:现有神经声码器大多局限于GAN或扩散模型中的一种,难以统一;且原始的ConvNeXt声码器(如WaveNeXt)在多说话人场景下性能有限。
- 方法核心是什么:提出WaveNeXt 2,一个统一的ConvNeXt生成器框架,其核心是残差去噪子模型设计。生成器预测的是每一步的噪声分量,而非直接预测波形,从而使同一架构可适配GAN(采用固定点���代)和扩散模型(采用分阶段子模型训练)两种训练范式。
- 与已有方法相比新在哪里:首次将ConvNeXt架构同时应用于GAN和扩散声码器;通过子模型训练策略改进了原始WaveNeXt在多说话人上的不足;简化了WaveFit的训练流程(移除了不必要的初始噪声和增益调整)。
- 主要实验结果如何:在多说话人数据集LibriTTS-R上进行验证,结果如下表所示。GAN-WaveNeXt 2在推理速度上显著优于WaveFit和HiFi-GAN,同时保持质量相当;Diff-WaveNeXt 2在训练效率(仅需32小时)和CPU推理速度上远超FastDiff,并取得竞争性的质量。
模型 RTF (CPU) ↓ UTMOS ↑ NISQA ↑ 训练时间 (GPU) GAN-WaveNeXt 2 (4 iter) 0.20 4.04 ± 0.09 4.01 ± 0.20 410 小时 WaveFit (5 iter) 5.36 4.04 ± 0.09 4.02 ± 0.19 410 小时 HiFi-GAN V1 0.80 4.05 ± 0.11 3.99 ± 0.22 270 小时 Diff-WaveNeXt 2 0.16 3.87 ± 0.05 3.81 ± 0.19 32 小时 FastDiff w/ sub-modeling 0.80 3.78 ± 0.06 3.67 ± 0.20 96 小时 - 实际意义是什么:为声码器选择提供了灵活方案:GAN-WaveNeXt 2适用于对合成质量要求极高的场景,而Diff-WaveNeXt 2则以其极快的训练速度和优秀的CPU推理能力,非常适合资源受限或需要快速迭代的应用。
- 主要局限性是什么:采用子模型策略后,模型总体参数量随子模型数量线性增长(如Diff-WaveNeXt 2达57.68M),增加了存储和部分计算负担。论文中未明确讨论其在流式处理中的应用。
🏗️ 模型架构
WaveNeXt 2 的整体架构旨在成为一个兼容GAN与扩散模型的统一生成器。
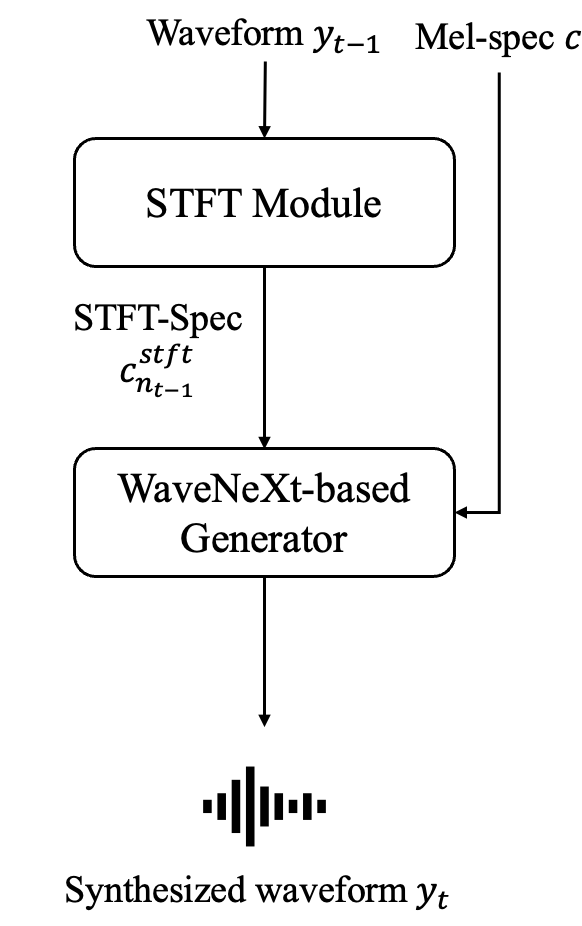 图2:提出的WaveNeXt生成器与子模型架构
图2:提出的WaveNeXt生成器与子模型架构
- WaveNeXt生成器 (图2a):保留了原始WaveNeXt的核心结构。输入是梅尔频谱图,输出是预测的噪声分量(而非最终波形)。其内部由一个STFT模块和n=8个ConvNeXt块组成。STFT模块将输入的梅尔频谱图转换为STFT谱(Real和Imag部分),与梅尔频谱图拼接后送入后续网络。
- ConvNeXt块:是架构的核心,源自图像处理领域ConvNeXt,因其在保持高性能的同时结构简单高效而被采用。在语音任务中,它作为强大的序列到序列映射模块。
- 残差去噪子模型 (图2b):这是实现统一框架的关键。每个子模型接收两个输入:1)梅尔频谱图(条件信息);2)当前步的含噪波形或残差。其输出是预测的噪声或残差,用于更新波形。这个设计使得生成器可以灵活地集成到不同的训练流程中。
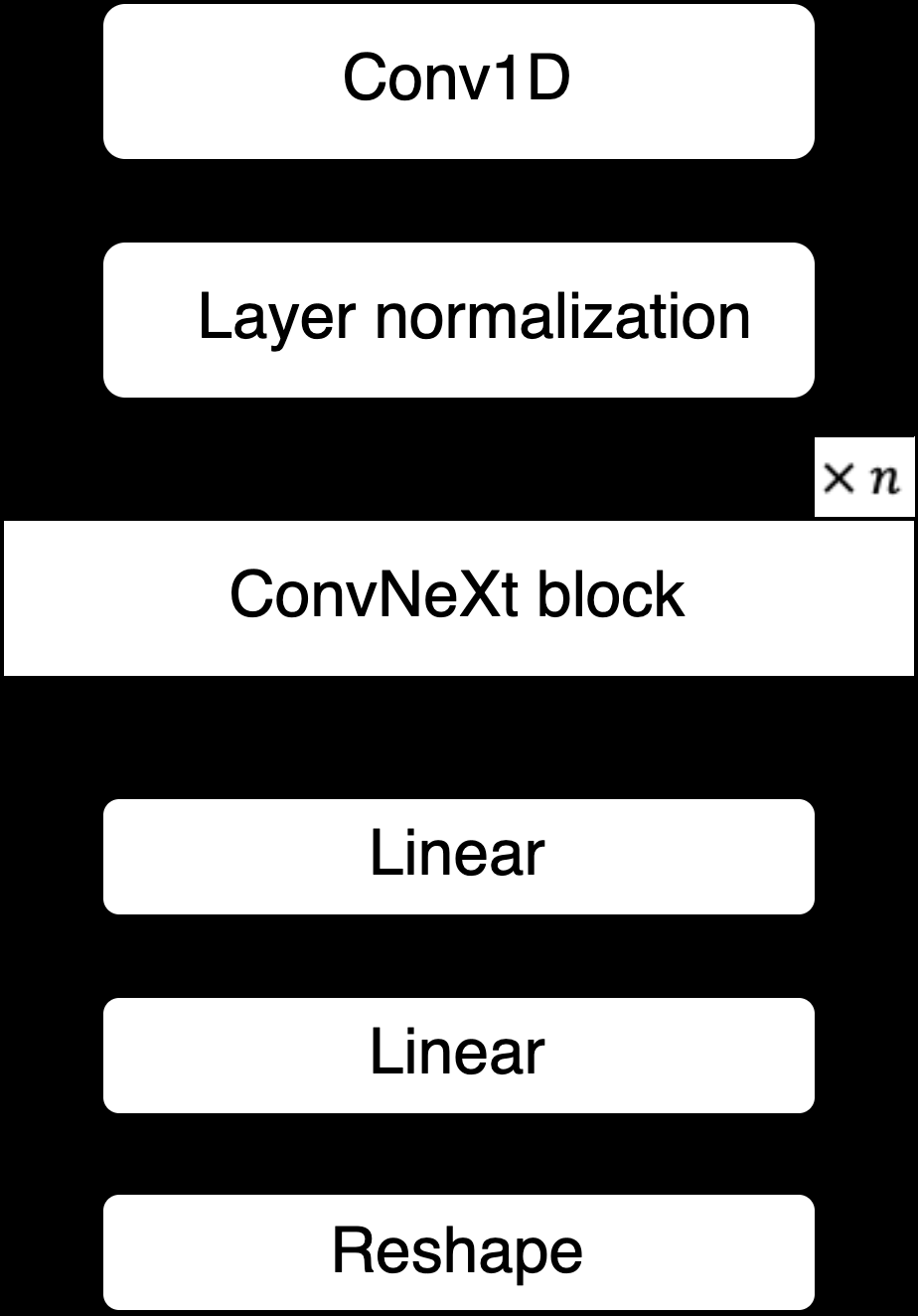 图1:GAN-WaveNeXt 2 (a) 与 Diff-WaveNeXt 2 (b) 的训练方案
图1:GAN-WaveNeXt 2 (a) 与 Diff-WaveNeXt 2 (b) 的训练方案
- 数据流与交互:
- GAN-WaveNeXt 2:采用类似WaveFit的固定点迭代训练。对于t个迭代步,生成器(子模型)依次接收梅尔谱图和上一步的波形
yt,预测并更新为yt-1,最终得到y0。损失由判别器提供的对抗损失和STFT损失共同监督。 - Diff-WaveNeXt 2:遵循条件扩散模型框架,但使用了子模型训练策略。将整个去噪过程分为T个阶段(论文中T=4),为每个阶段训练一个独立的子模型。每个子模型负责在一个特定的噪声级别范围(由噪声调度预测器给出)内进行去噪。推理时,从随机噪声开始,依次通过这些子模型,逐步得到干净波形。
- GAN-WaveNeXt 2:采用类似WaveFit的固定点迭代训练。对于t个迭代步,生成器(子模型)依次接收梅尔谱图和上一步的波形
- 关键设计选择:将生成器输出改为预测噪声分量,是实现“一个架构,两种用法”的核心。在GAN模式下,噪声分量被解释为需要减去的“残差”;在扩散模式下,它直接对应于去噪过程中的噪声预测任务。
💡 核心创新点
- 统一的残差去噪子模型框架:提出了首个能同时兼容GAN和扩散神经声码器的ConvNeXt生成器架构。通过预测噪声/残差分量,而非直接生成波形,实现了架构的通用性。
- 针对多说话人的性能改进:通过上述子模型框架,有效解决了原始GAN-WaveNeXt(即WaveNeXt)在多说话人场景下性能不佳的问题,使其达到了与HiFi-GAN、WaveFit等强基线可比的质量。
- 简化的GAN训练流程:发现并证实了在WaveFit式的固定点迭代训练中,移除初始噪声输入和增益调整模块是可行且有效的,这简化了训练过程且不影响性能。
- 极高的扩散模型训练效率:将Diff-WaveNeXt 2的训练时间大幅缩减至32小时(相比FastDiff的96小时),使其在训练资源成本上极具竞争力。
🔬 细节详述
- 训练数据:LibriTTS-R数据集的
train-clean-100和train-clean-360子集,约585小时,24kHz采样率,多说话人英文朗读语音。未提及其他数据增强。 - 损失函数:
- GAN-WaveNeXt 2:完全沿用WaveFit的损失定义(包括对抗损失、STFT损失等),以确保比较的公平性。
- Diff-WaveNeXt 2:每个子模型的训练损失为MSE(均方误差),即预测噪声与真实噪声之间的损失。
- 训练策略:
- GAN-WaveNeXt 2:采用固定点迭代策略,T步迭代训练(实验评估了2-5步)。每步训练对应一个独立的子模型,但参数共享(根据图2b描述推测)。
- Diff-WaveNeXt 2:采用“噪声级别受限子模型训练”策略。将去噪过程分为4个阶段,为每个阶段训练一个独立的子模型。噪声调度由来自BDDM的预测器给出,4步的调度为
[1.0e-04, 2.8e-02, 5.6e-01, 9.1e-01]。 - 学习率、优化器、Batch Size等:论文中未说明。
- 关键超参数:
- 模型大小:GAN-WaveNeXt 2随迭代步数增加,参数量从29.97M(2步)线性增长到74.93M(5步)。Diff-WaveNeXt 2(含4个子模型)总参数为57.68M。作为对比,WaveFit固定为15.51M。
- 生成器结构:固定使用n=8个ConvNeXt块。
- 输入特征:128维梅尔频谱图。
- 跳步大小:GAN模型与WaveFit一致为300,扩散模型与FastDiff一致为256。
- 训练硬件:单卡NVIDIA A100 (40GB)。
- 训练时长:GAN-WaveNeXt 2和WaveFit均为410小时;HiFi-GAN为270小时;Diff-WaveNeXt 2为32小时;FastDiff为96小时。
- 推理细节:
- GAN模型:迭代步数T是推理时的关键超参数(2-5步)。
- 扩散模型:固定使用4步推理,依次通过4个子模型。
- 后处理:Diff-WaveNeXt 2使用了来自[21]的时不变频谱增强后滤波技术,以恢复可能丢失的高频细节。
- 评估硬件:GPU (A100) 和 CPU (AMD EPYC 7542, 1核)。
- 正则化或稳定训练技巧:GAN训练使用了与WaveFit相同的判别器和损失以保证稳定。扩散训练采用了分阶段子模型策略,本身有助于稳定和提升预测精度。
📊 实验结果
主要对比结果(来自Table 1):
| Model | RTF(GPU) ↓ | RTF(CPU) ↓ | UTMOS ↑ | NISQA ↑ | MCD ↓ | log F0 RMSE ↓ | Model size |
|---|---|---|---|---|---|---|---|
| Ground Truth | – | – | 4.08 ± 0.19 | 4.11 ± 0.09 | – | – | – |
| WaveNeXt (1 iter) | 0.0022 | 0.06 | 3.16 ± 0.24 | 3.20 ± 0.12 | 0.92 ± 0.52 | 0.31 ± 0.15 | 14.98M |
| WaveFit (2 iter) | 0.0111 | 2.15 | 3.80 ± 0.22 | 3.89 ± 0.11 | 1.03 ± 0.54 | 0.32 ± 0.15 | 15.51M |
| GAN-WaveNeXt 2 (2 iter) | 0.0033 | 0.10 | 3.77 ± 0.20 | 3.88 ± 0.11 | 0.97 ± 0.54 | 0.31 ± 0.15 | 29.97M |
| WaveFit (3 iter) | 0.0151 | 3.22 | 3.91 ± 0.22 | 3.98 ± 0.10 | 1.01 ± 0.54 | 0.32 ± 0.13 | 15.51M |
| GAN-WaveNeXt 2 (3 iter) | 0.0054 | 0.15 | 3.92 ± 0.22 | 3.91 ± 0.10 | 0.96 ± 0.57 | 0.30 ± 0.18 | 44.96M |
| WaveFit (4 iter) | 0.0213 | 4.28 | 3.97 ± 0.21 | 3.99 ± 0.10 | 1.01 ± 0.52 | 0.32 ± 0.11 | 15.51M |
| GAN-WaveNeXt 2 (4 iter) | 0.0066 | 0.20 | 4.01 ± 0.20 | 4.04 ± 0.09 | 0.95 ± 0.53 | 0.30 ± 0.11 | 59.94M |
| HiFi-GAN V1 | 0.0110 | 0.80 | 3.99 ± 0.22 | 4.05 ± 0.11 | 2.34 ± 0.83 | 0.16 ± 0. 01 | 13.9M |
| FastDiff wo/ sub-modeling | 0.0625 | 0.80 | 3.43 ± 0.20 | 3.50 ± 0.11 | 4.76 ± 0. 74 | 0.16 ± 0. 01 | 15.63M |
| Diff-WaveNeXt 2 wo/ sub-modeling | 0.0335 | 0.16 | 3.45 ± 0.19 | 3.55 ± 0.09 | 7.34 ± 1. 46 | 0.16 ± 0. 01 | 14.42M |
| FastDiff w/ sub-modeling | 0.0282 | 0.80 | 3.67 ± 0.20 | 3.78 ± 0.06 | 4.32 ± 0.69 | 0.24 ± 0.33 | 62.52M |
| Diff-WaveNeXt 2 | 0.0164 | 0.16 | 3.81 ± 0.19 | 3.87 ± 0.05 | 4.16 ± 0. 88 | 0. 12 ± 0. 01 | 57.68M |
 图4:MOS主观评价结果
该图(图4)显示了主观MOS评分。GAN-WaveNeXt 2(4次迭代)的MOS分数与WaveFit(5次迭代)和HiFi-GAN非常接近,且置信区间重叠,表明主观质量相当。
图4:MOS主观评价结果
该图(图4)显示了主观MOS评分。GAN-WaveNeXt 2(4次迭代)的MOS分数与WaveFit(5次迭代)和HiFi-GAN非常接近,且置信区间重叠,表明主观质量相当。
关键结论与分析:
- GAN-WaveNeXt 2 vs. WaveFit:在相似或更优的质量(UTMOS/NISQA)下,推理速度(RTF)在GPU上提升约70%,在CPU上提升约90%(以4次迭代对比5次迭代为例)。这是核心优势。
- GAN-WaveNeXt 2 vs. HiFi-GAN:在质量相当的情况下(UTMOS/NISQA),GPU推理速度提升约40%,CPU提升约75%。但在log F0 RMSE(音高精度)上劣于HiFi-GAN,在MCD(频谱保真度)上优于HiFi-GAN。
- Diff-WaveNeXt 2 vs. FastDiff:采用子模型策略后,质量显著提升(UTMOS从3.78到3.87)。推理速度在GPU上提升约36%,在CPU上提升约80%。
- 消融实验:
- 不使用子模型训练的
Diff-WaveNeXt 2 wo/ sub-modeling性能显著下降(UTMOS 3.55),验证了子模型策略的重要性。 - 模型大小随迭代步数(GAN)或子模型数量(Diff)增加而显著增大,是该方法的主要代价。
- 不使用子模型训练的
训练时间对比(来自Table 2):
| Model | Training time |
|---|---|
| GAN-WaveNeXt 2 | 410 hours |
| HiFi-GAN | 270 hours |
| WaveFit | 410 hours |
| Diff-WaveNeXt 2 | 32 hours |
| Fastdiff | 96 hours |
⚖️ 评分理由
- 学术质量:7.0/7:本文提出了一个具有实用价值的统一框架,设计合理,实验充分,对比基线全面(包括主观MOS和多项客观指标),并提供了清晰的消融实验。技术实现正确,结论有数据支撑。创新性在于框架的整合与效率提升,而非提出全新的生成原理。
- 选题价值:1.5/2:神经声码器是语音合成系统的核心组件之一,统一框架提升了灵活性和适用性。训练效率(特别是扩散模型)的大幅提升对实际应用和快速原型开发有显著价值。与语音合成领域读者高度相关。
- 开源与复现加成:0.3/1:论文提供了demo页面(链接),并明确引用了多个基线模型的开源实现(如ParallelWaveGAN, wavefit-pytorch, FastDiff, Vocos)。给出了关键的训练硬件和时长。然而,未提及是否开源WaveNeXt 2本身的代码、模型权重或提供详细的训练配置文件,这限制了完全复现的可能性。