📄 WAV2LEV: Predicting Levenshtein Edit Operation Sequences For Fine-Grained Estimation of Automatic Speech Recognition Error
#语音识别 #模型评估 #数据增强 #数据集 #语音大模型
✅ 7.5/10 | 前25% | #语音识别 | #数据增强 | #模型评估 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Harvey Donnelly(多伦多大学计算机科学系 & 爱丁堡大学信息学院)
- 通讯作者:Harvey Donnelly(对应作者标识为†)
- 作者列表:Harvey Donnelly(多伦多大学计算机科学系 & 爱丁堡大学信息学院)、Ken Shi(多伦多大学计算机科学系)、Gerald Penn(多伦多大学计算机科学系)
💡 毒舌点评
亮点在于其构建Mini-CNoiSY数据集的方法颇具匠心——通过YouTube文件名搜索来获取近乎纯净的自然背景噪声,并人工合成带噪语音以确保标签质量,这为ASR错误评估领域提供了一个可靠且多样化的测试台。短板是其核心模型WAV2LEV本质上是一个基于强大预训练模型(Whisper)的特定任务适配头,创新更多体现在任务范式的转变(从预测标量WER到预测操作序列)而非模型架构本身,导致性能相较于直接预测WER的“WHISP-MLP”基线并无优势。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/HarveyRDonnelly/WAV2LEV
- 模型权重:论文中未提及是否公开预训练的WAV2LEV模型权重。
- 数据集:论文提供了Mini-CNoiSY数据集的获取链接:https://github.com/HarveyRDonnelly/MiniCNoiSY
- Demo:论文中未提及在线演示。
- 复现材料:论文中提供了详细的模型架构、训练超参数(优化器、学习率、损失函数等)、基线模型设置等复现信息。
- 论文中引用的开源项目:
- Whisper large-v3 [6]
- AdamW优化器 [7]
- HuBERT large [14] (用于Fe-WER基线)
- XLM-RoBERTa large [15] (用于Fe-WER基线)
- YODAS2语料库 [10] (音频来源)
- Pyannote.audio [13] (用于语音活动检测)
- 用于噪声合成的相关挑战赛工具/数据 [11, 12]
📌 核心摘要
- 要解决什么问题:在缺乏真实文本(ground-truth)的情况下,评估自动语音识别(ASR)生成文本的质量。现有方法主要直接预测整个片段的词错误率(WER),但忽略了token级别的错误细节。
- 方法核心是什么:提出WAV2LEV模型,其核心思想是预测将ASR假设文本转化为真实文本所需的Levenshtein编辑操作序列(匹配、替换、删除、插入),从而能从中计算出WER并获得细粒度的错误定位。
- 与已有方法相比新在哪里:范式创新:将WER估计任务从“回归一个标量”转变为“序列到序列预测”(预测编辑操作序列)。数据集贡献:构建了Mini-CNoiSY噪声语音语料库,通过可控的人工加噪确保了ground-truth标签的可靠性,并涵盖了多样的噪声类型。
- 主要实验结果如何:WAV2LEV在Mini-CNoiSY测试集上进行WER估计的RMSE为0.1488,皮尔逊相关系数(PCC)为89.71%,性能与重新实现的直接WER估计器WHISP-MLP(RMSE 0.1376, PCC 91.01%)接近,且显著优于文献中复现的Fe-WER模型(RMSE 0.2333, PCC 82.20%)。对于预测编辑序列本身,其token错误率(TER)为0.2972。分析表明,模型对真实文本长度的预测比对编辑序列长度的预测更准确,暗示其能较好地理解对齐关系。
- 实际意义是什么:能够为ASR转录提供更细粒度的置信度信息,有助于在语音理解(SLU)等下游任务中抑制错误传播,或用于更精确地筛选高质量ASR结果。
- 主要局限性是什么:引入更复杂的序列预测目标并未在WER估计准确性上超越相对简单的直接预测方法(WHISP-MLP),其核心优势(细粒度诊断)目前主要通过新提出的TER指标评估,缺乏与既有工作的直接对比。TER指标本身的局限性也被作者指出。
🏗️ 模型架构
WAV2LEV的模型架构是一个基于Whisper大模型的序列到序列系统,其流程如下:
- 输入:一段语音音频及对应的ASR假设文本。
- 音频特征提取:使用预训练的Whisper large-v3 编码器处理音频,生成音频特征序列。
- 不确定性特征提取:将假设文本输入Whisper large-v3 解码器(使用teacher forcing),获取每个token位置的logit分布。从该分布中计算12种统计特征,包括熵、Top-k概率、基尼不纯度等,构成不确定性特征序列。
- 文本嵌入:获取假设文本的文本嵌入序列。
- 特征融合:将上述三个序列(音频特征、不确定性特征、文本嵌入)在特征维度上拼接,形成一个长的特征序列。
- 序列预测:拼接后的特征序列被送入一个12层、16头、隐藏维度1024的Transformer解码器。该解码器通过自注意力机制对齐和融合多模态信息,最终输出一个序列,其中每个位置对应一个编辑操作类别(匹配、替换、删除、插入)的logit分布。
- 输出:通过贪心解码,得到预测的Levenshtein编辑操作序列。从该序列可计算出预测的WER,并可获得每个token对应的错误类型标签(token级细粒度错误)。
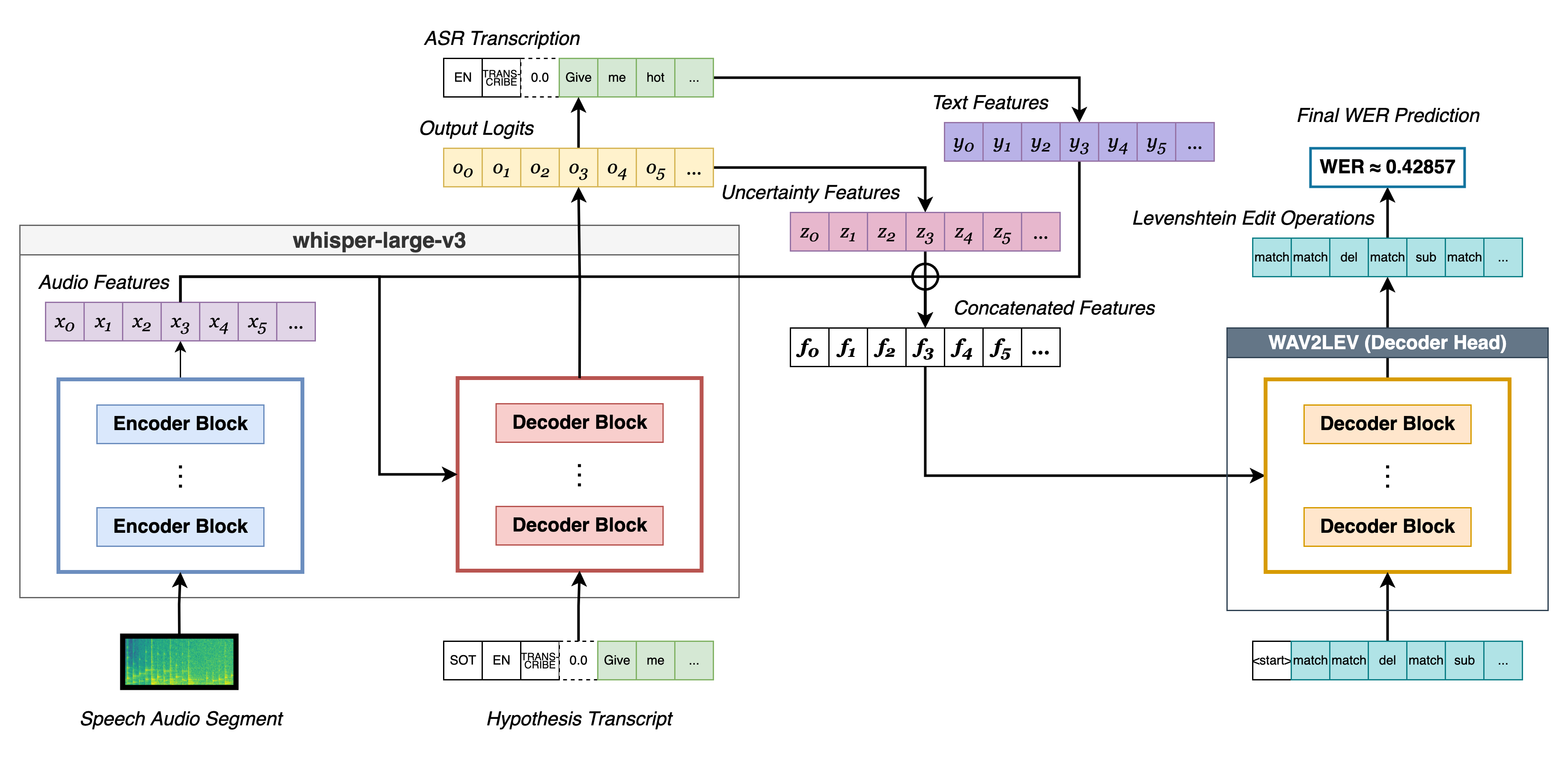 图1. WAV2LEV语音到WER的流程图。展示了从音频和假设文本输入,经过Whisper编码器、解码器生成不确定性特征,最后由WAV2LEV解码器预测编辑操作序列的过程。
图1. WAV2LEV语音到WER的流程图。展示了从音频和假设文本输入,经过Whisper编码器、解码器生成不确定性特征,最后由WAV2LEV解码器预测编辑操作序列的过程。
💡 核心创新点
- 范式创新:从预测WER到预测Levenshtein操作序列。这是本文最主要的创新。之前的方法(如e-WER3, Fe-WER)直接回归一个全局的WER标值。WAV2LEV则预测导致该WER的底层操作序列,从而在获得WER估计的同时,自然地提供了token级别的错误类型信息(是替换、删除还是插入),实现了更细粒度的错误诊断。
- 构建高质量、可控的ASR错误评估数据集Mini-CNoiSY。针对现有评估数据集(如TED-Lium, LibriSpeech)可能存在的ground-truth标签不可靠、噪声类型单一问题,本文提出了一套完整的数据构建方法:从YouTube获取干净语音并筛选标签一致性;再通过模拟混响、添加各种背景噪声(来源于YouTube的自然噪声)、带宽限制、编解码压缩、添加高斯白噪声和模拟丢包等阶段,合成多样化的带噪语音,并严格控制SNR范围。这确保了评估的可靠性。
- 融合多维度特征进行预测。模型不仅使用Whisper的音频和文本特征,还创新性地从ASR解码器的logit分布中提取了丰富的统计不确定性特征(如熵、概率质量、基尼系数等),作为模型判断置信度的重要依据。
🔬 细节详述
- 训练数据:使用本文提出的Mini-CNoiSY语料库。训练集包含88177个片段,总时长约346.44小时,平均WER为27.88%。验证集和测试集各约3.95小时。背景噪声来自通过特定方法(搜索匹配设备文件名前缀的YouTube视频)下载的39253个样本,总时长约325.95小时。
- 损失函数:Token级别的交叉熵损失(Cross-Entropy Loss),并使用了标签平滑(Label Smoothing),值为0.05。
- 训练策略:使用AdamW优化器,权重衰减为0.0001。学习率设置为12e-6。训练100个epoch。使用了混合精度训练、梯度累积、梯度裁剪。学习率调度采用线性预热(warmup为总步数的1%)。
- 关键超参数:WAV2LEV解码器:12层,16头,维度1024。激活函数为GELU,Dropout概率为10%。标签平滑系数0.05。
- 训练硬件:论文中未说明。
- 推理细节:评估时,WAV2LEV采用贪心解码生成编辑操作序列。
- 正则化技巧:Dropout(10%),标签平滑(0.05)。
📊 实验结果
主要对比实验(WER估计任务)
| 模型 | 学习率 | Epochs | RMSE ↓ | PCC ↑ | TER ↓ |
|---|---|---|---|---|---|
| WAV2LEV | 12e-6 | 100 | 0.1488 | 0.8971 | 0.2972 |
| WHISP-MLP | 12e-6 | 100 | 0.1376 | 0.9101 | ~ |
| Fe-WER* | 12e-6 | 100 | 0.2333 | 0.8220 | ~ |
注:Fe-WER是论文作者重新实现的模型。WHISP-MLP是使用相同输入特征(音频、不确定性、文本嵌入)但通过平均池化后接MLP直接预测WER的基线模型。*
关键结论:
- 在WER估计任务上,简单的WHISP-MLP基线性能最优,WAV2LEV紧随其后,两者均显著优于Fe-WER。这表明WAV2LEV的复杂序列预测目标在WER估计准确性上并未带来增益,但维持了相近水平。
- WAV2LEV获得了TER为0.2972,但该指标缺乏历史基线对比。
编辑序列生成分析
- 序列长度预测:模型对真实文本长度(Ground-Truth Length)的归一化RMSE(0.2792)显著低于对编辑操作序列长度(Levenshtein Sequence Length)的RMSE(0.4635)。且真实长度分布的KL散度(0.0273)也远小于编辑序列长度分布的KL散度(0.0999)。这表明模型能较好地理解内容(真实长度),但对操作序列的具体构成预测仍有难度。
预测与目标WER分布
- 模型预测的WER均值(0.3178)与真实WER均值(0.3162)非常接近。
- 但模型倾向于低估WER为0%和100%的极端样本(如图3所示)。
 图2. WAV2LEV (a) 与 WHISP-MLP (b) 在Mini-CNoiSY测试集上的预测WER与目标WER对比散点图。两者都表现出较强的相关性,但WHISP-MLP的点似乎更紧密地围绕对角线。
图2. WAV2LEV (a) 与 WHISP-MLP (b) 在Mini-CNoiSY测试集上的预测WER与目标WER对比散点图。两者都表现出较强的相关性,但WHISP-MLP的点似乎更紧密地围绕对角线。
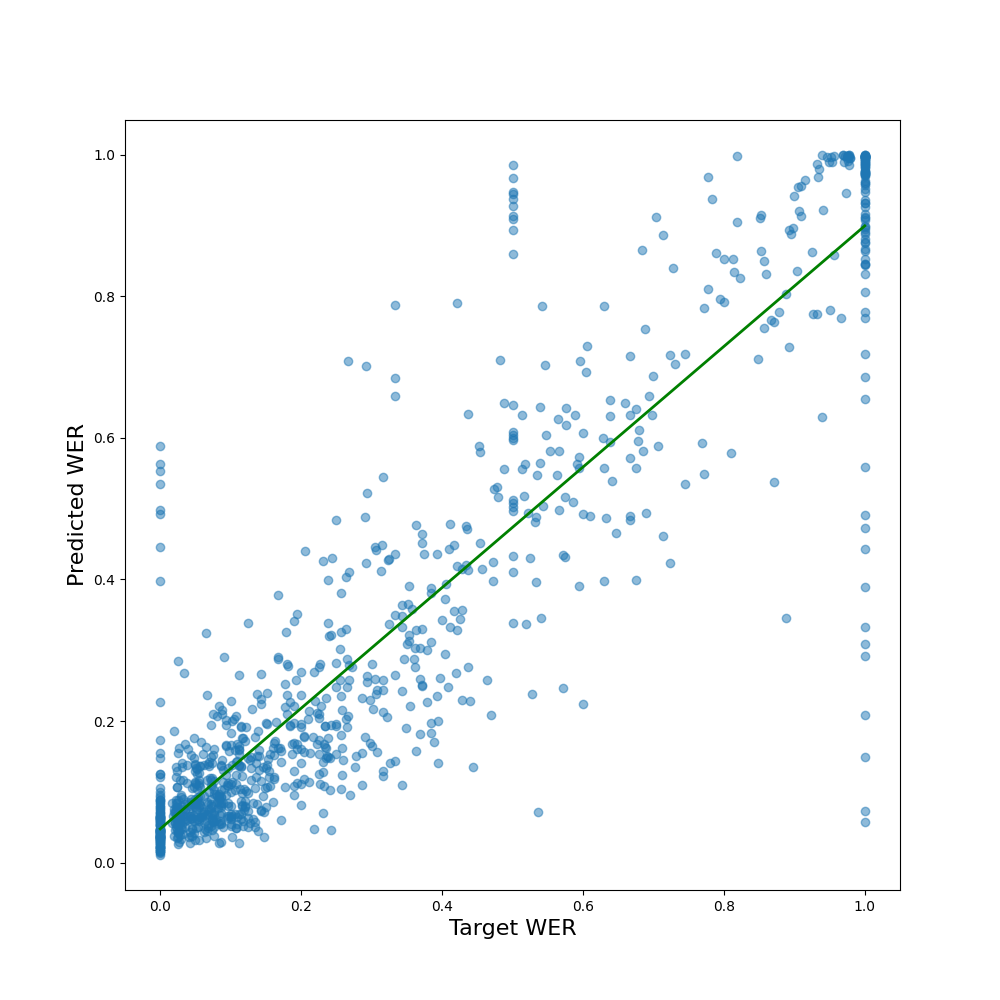 图3. WAV2LEV在Mini-CNoiSY测试集上的预测WER(a)与目标WER(b)的分布直方图。可以看出预测分布与真实分布趋势相似,但两端(0和1)的预测频率偏低。
图3. WAV2LEV在Mini-CNoiSY测试集上的预测WER(a)与目标WER(b)的分布直方图。可以看出预测分布与真实分布趋势相似,但两端(0和1)的预测频率偏低。
⚖️ 评分理由
- 学术质量(6.0/7):论文提出了一个清晰且有逻辑的新任务范式(细粒度错误序列预测),并为此贡献了一个设计精良的专用数据集(Mini-CNoiSY),实验对比充分(包括复现SOTA和设计强基线)。技术实现正确,分析细致(如长度预测分析)。扣分主要在于,新范式带来的核心价值(细粒度)的量化评估尚不充分(TER新指标),且其在主要可比指标(WER估计)上并未超越更简单的直接预测方法,使得范式转换的实际收益显得有限。
- 选题价值(1.5/2):ASR错误评估是实际应用中的真实需求,从粗粒度走向细粒度是自然且有价值的演进方向。该工作为语音处理社区提供了一个更可靠的评估基准(Mini-CNoiSY)和一个新的研究视角。
- 开源与复现加成(0.5/1):论文开源了代码库和数据集,并详细列出了训练超参数和模型架构,复现友好度高。主要减分项是未明确公开预训练的WAV2LEV模型权重,这限制了直接应用和快速验证。