📄 VoXtream: Full-Stream Text-To-Speech With Extremely Low Latency
#语音合成 #自回归模型 #流式处理 #零样本
🔥 8.5/10 | 前25% | #语音合成 | #自回归模型 | #流式处理 #零样本
学术质量 6.0/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Nikita Torgashov(KTH皇家理工学院,语音、音乐与听觉系)
- 通讯作者:未说明
- 作者列表:Nikita Torgashov(KTH皇家理工学院,语音、音乐与听觉系)、Gustav Eje Henter(KTH皇家理工学院,语音、音乐与听觉系)、Gabriel Skantze(KTH皇家理工学院,语音、音乐与听觉系)
💡 毒舌点评
亮点:这篇论文最精妙的地方在于,它通过将文本编码器(Phoneme Transformer)设计为增量式,并限制了前瞻长度,巧妙地实现了“收到一个词就开口说”的极低延迟,同时利用单调对齐和分层预测保证了合成质量的连贯性。短板:尽管模型效率很高,但训练数据规模(9k小时)在当下这个“数据为王”的大模型时代只能算中等,这可能限制了其在超大规模、多语言或更复杂说话风格下的泛化能力上限,论文也承认了数据规模是未来工作之一。
🔗 开源详情
- 代码:提供代码仓库链接:https://herimor.github.io/voxtream
- 模型权重:论文中未明确提及是否公开训练好的VoXtream模型权重。仅提到引用了开源的CSM模型和ReDimNet。
- 数据集:使用了Emilia和HiFiTTS-2数据集,这两个都是公开数据集。但论文中未提供其预处理后的具体获取方式。
- Demo:提供在线演示链接:https://herimor.github.io/voxtream
- 复现材料:论文给出了模型架构的详细描述、主要的训练超参数(学习率、batch size、优化器、epoch数)、硬件环境(A100 GPU)。但未提供完整的训练脚本、配置文件或检查点。
- 引用的开源项目:g2p(音素转换)、Mimi编解码器、Montreal Forced Aligner (MFA)、CSM模型、ReDimNet说话人编码器、Llama架构。
- 总体开源情况:论文提供了核心的推理代码和演示,但训练所需的完整复现材料(如预处理数据、详细训练配置、预训练模型权重)并未完全公开。
📌 核心摘要
- 问题:当前流式文本转语音(TTS)系统存在较高的初始延迟(从输入文本到发出第一个音素的时间),或需要复杂的多阶段流水线,影响了实时交互体验。
- 方法核心:提出VoXtream,一个完全自回归的零样本流式TTS模型。其核心是一个三层Transformer架构:(1) 增量音素Transformer(PT)逐步编码输入文本并允许有限前瞻;(2) 时间Transformer(TT)基于音素和过去音频预测语义令牌和时长令牌;(3) 深度Transformer(DT)基于前两者生成声学令牌。关键设计是基于“停留/切换”标志的单调音素对齐预测。
- 创新点:与先前工作相比,VoXtream首次实现了从接收到第一个词就开始生成语音的增量处理模式,无需等待整个句子或固定数量的未来词。它将文本编码、时序预测和声学生成解耦到三个专用模块中,平衡了延迟与质量。
- 实验结果:在公开流式TTS模型中达到了最低的首次分组延迟(FPL):102ms(使用torch.compile加速后)。在9k小时数据上训练,其质量(WER, SPK-SIM, UTMOS)可与甚至超越许多使用更大规模数据训练的非流式和流式基线模型。在主观MUSHRA评测中,其流式版本的自然度与部分非流式模型相当。在长文本流式场景下,其自然度显著优于CosyVoice2。
- 实际意义:为需要极低延迟响应的实时语音应用(如语音助手、同步翻译、对话AI)提供了一个高效且高质量的解决方案,推动了流式语音合成技术的实用化。
- 主要局限性:训练数据规模(9k小时)中等;在零样本说话人相似度上,仍低于使用更大规模数据和非自回归解码器(如流匹配)的顶级模型(如CosyVoice2);长文本流式合成的稳定性有待进一步验证。
🏗️ 模型架构
VoXtream的架构(见图1)旨在实现从文本流到音频流的端到端、低延迟转换。它由三个核心Transformer模块组成,数据流如下:
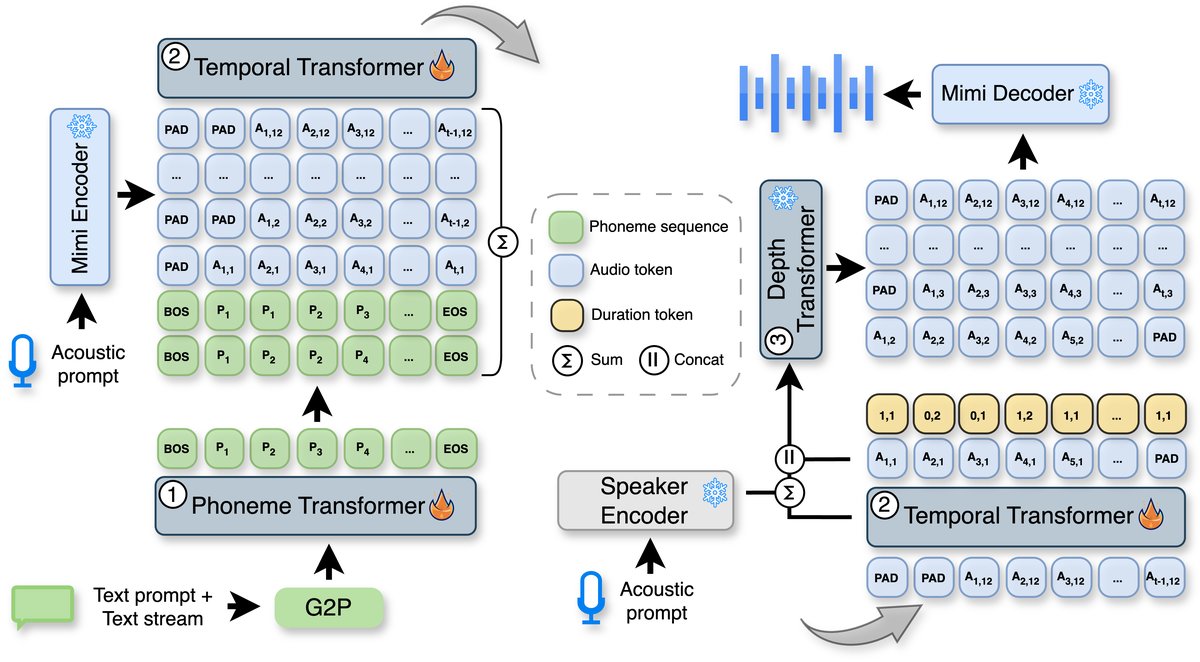 图1:VoXtream架构概览。输入文本流被增量地送入Phoneme Transformer(PT)。PT结合有限的未来音素(Look-Ahead)进行编码。其输出被送入时间Transformer(TT),TT联合预测语义令牌(来自Mimi编码器的第一码本)和时长令牌(包含“停留/切换”标志及发音速度信息)。TT的输出和语义令牌被送入深度Transformer(DT),DT结合说话人嵌入,自回归地生成剩余的声学令牌(来自Mimi编码器的第2-12码本)。最后,Mimi解码器将每帧的语义和声学令牌转换为波形。
图1:VoXtream架构概览。输入文本流被增量地送入Phoneme Transformer(PT)。PT结合有限的未来音素(Look-Ahead)进行编码。其输出被送入时间Transformer(TT),TT联合预测语义令牌(来自Mimi编码器的第一码本)和时长令牌(包含“停留/切换”标志及发音速度信息)。TT的输出和语义令牌被送入深度Transformer(DT),DT结合说话人嵌入,自回归地生成剩余的声学令牌(来自Mimi编码器的第2-12码本)。最后,Mimi解码器将每帧的语义和声学令牌转换为波形。
组件详解:
- 音素Transformer(Phoneme Transformer, PT):这是一个解码器风格的Transformer,负责将输入的音素序列编码为隐藏表示。其核心创新是增量处理:每收到一个新词,就将其音素加入输入序列并更新隐藏状态,而不是等待整个句子。为了提升韵律自然度,允许PT“向前看”最多N个音素(Look-Ahead, LA),但这个前瞻是有限且延迟最小化的——模型在收到第一个词后立即开始输出,前瞻仅影响后续生成,不阻塞启动。
- 时间Transformer(Temporal Transformer, TT):这是系统的自回归核心,以步进方式工作。在每个时间步(对应Mimi编码器的一个音频帧,12.5Hz),TT接收:a) 过去生成的音频令牌(第一码本,语义令牌);b) 由MFA对齐工具得到的、与当前时间步对齐的音素序列及其隐藏状态(来自PT)。TT输出两个分类结果:
- 语义令牌:Mimi编码器的第一码本令牌,代表当前帧的语音内容。
- 时长令牌:一个二元组
(shift_flag, phoneme_count)。shift_flag(1或0)是“停留/切换”标志,指示下一帧是继续发当前音素(0,停留)还是切换到下一个音素(1,切换)。phoneme_count(1或2)表示当前帧对应的音素数量,用于控制语速(1个音素=慢,2个音素=快)。这种设计实现了单调对齐,确保音频和文本的进度严格同步。
- 深度Transformer(Depth Transformer, DT):在TT预测出当前帧的语义令牌后,DT负责填充该帧的其余声学细节。它是一个更小的自回归Transformer,以TT的输出嵌入、当前的语义令牌以及一个预训练的说话人嵌入(来自ReDimNet)为条件,自回归地生成Mimi编码器的第2至第12码本的声学令牌。这些令牌共同描述了该帧的详细声学特征。
- 音频编解码器(Mimi):采用预训练的Mimi流式编解码器。编码器将24kHz的波形编码为多码本令牌(12个码本,帧率12.5Hz)。TT预测第一码本(语义),DT预测其余码本(声学)。解码器能以流式方式将每帧的令牌转换为80ms的音频波形。
整体流程:文本流 → 音素流 → PT增量编码 → TT逐帧预测语义+时长令牌 → DT逐帧填充声学令牌 → Mimi解码器流式输出波形。整个过程是纯自回归的,且文本输入和音频输出是交织进行的,因此实现了极低的首次分组延迟。
💡 核心创新点
增量式文本编码与有限前瞻(Limited Look-Ahead):
- 局限:之前的流式TTS(如SpeakStream)要么等待完整文本,要么需要较多的未来词前瞻(如2个词),这都增加了输入侧延迟。
- 创新:将文本编码器(PT)设计为状态可增量更新的,并将前瞻长度限制为少数几个音素(最多10个)。关键在于,模型在收到第一个词后立即启动音频生成,前瞻仅用于改善后续生成的韵律,不阻塞启动。
- 收益:实现了极低的首次分组延迟(102ms),同时通过利用少量未来信息维持了较好的自然度。
基于“停留/切换”标志的单调时长预测:
- 局限:传统的自回归TTS需要预测每个音频帧对应的音素ID,这可能在长距离上导致对齐错误或跳字/漏字。
- 创新:TT不直接预测音素ID,而是预测一个时长令牌,包含“是否切换到下一音素”(shift flag)和“当前帧处理几个音素”(phoneme count)。这实质上将音素-音频的对齐问题转化为一个单调的、二元的状态机决策。
- 收益:极大地简化了对齐过程,保证了文本和语音进度的严格同步,提升了流式合成的稳定性和可读性,且计算高效。
三层解耦的自回归架构:
- 局限:单阶段自回归TTS(如VoiceCraft)将文本到音频的复杂映射压缩在一个模型中,难以针对不同子问题(语言学编码、时序对齐、声学细节)进行优化,也限制了流式能力。
- 创新:明确地将任务分解为PT(语言学与上下文编码)、TT(内容与时序规划)、DT(声学与音色填充)三个专门模块。每个模块功能单一,可以更高效地训练和推理。
- 收益:这种解耦使得模块可以独立设计和优化(如DT可以使用冻结的预训练权重),平衡了模型容量、训练数据和推理速度。同时,为实现流式处理提供了清晰的结构基础。
高效利用基础模型组件:
- 局限:从头训练高质量的声学解码器和说话人编码器需要大量数据和计算。
- 创新:直接采用预训练的CSM-DT(一个在大规模数据上训练的深度Transformer)作为DT的基础并冻结其权重,同时使用预训练的ReDimNet作为说话人编码器。
- 收益:通过知识迁移,用较小的数据(9k小时)训练,就获得了接近大规模模型的合成质量(如SPK-SIM和UTMOS),显著降低了训练门槛和成本。
🔬 细节详述
- 训练数据:使用Emilia(4.5k小时)和HiFiTTS-2(4.5k小时)数据集,总计9k小时英语数据,包含自发和朗读风格。对Emilia数据进行了额外的说话人分离以去除多说话人段落,并使用NISQA过滤了低质量音频。使用CMU词典进行文本到音素的转换,并使用MFA进行音素-音频对齐。语音分词使用24kHz的Mimi编码器。
- 损失函数:训练目标是最小化时间Transformer(TT)和深度Transformer(DT)输出的负对数似然(Negative Log-Likelihood)。论文未提及具体权重分配。
- 训练策略:
- 使用AdamW优化器。
- 学习率:首个epoch预热至峰值
5 × 10^{-4}。 - 批量大小:每张GPU 128。
- 训练轮数:9 epochs。
- 输入处理:使用固定的20秒音频块及其对应音素序列作为输入。由于大部分话语短于20秒,会将同一说话人的多个短话语拼接起来。
- 关键超参数:
- Phoneme Transformer (PT):6层,8个注意力头,嵌入维度1024,前馈维度未明确说明。
- Temporal Transformer (TT):12层,16个注意力头,嵌入维度1024,前馈维度4096。
- Depth Transformer (DT):4层,8个注意力头,前馈维度8192。使用冻结的CSM-DT权重初始化。
- 说话人编码器:ReDimNet,训练于100k+说话人身份。
- Mimi编码器:使用12个码本(作为延迟与质量的权衡)。
- 训练硬件:两块NVIDIA A100-80GB GPU。
- 推理细节:
- 解码策略:自回归采样。
- 流式设置:文本以逐词方式流式输入,模拟从LLM接收文本流。音频以80ms为帧单元流式输出。
- 加速:使用
torch.compile和DeepSpeed (DS) 可进一步降低延迟。
- 正则化或稳定训练技巧:论文未提及除数据过滤和固定音频块输入外的其他正则化技巧。
📊 实验结果
论文在三个测试集上评估:LibriSpeech test-clean(续写任务)、SEED-TTS test-en(跨句任务)和LibriSpeech long(长文本流式任务)。评估指标包括WER(可懂度)、SPK-SIM(说话人相似度)、UTMOS(质量)和MUSHRA(自然度)。
表1:零样本TTS评估结果(主要实验)
| 模型 | 文本类型 | 训练数据量(h) | 参数量 | SEED test-en | LibriSpeech test-clean | MUSHRA (自然度) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| WER(%) ↓ | SPK-SIM ↑ | UTMOS ↑ | WER(%) ↓ | SPK-SIM ↑ | UTMOS ↑ | μ ± 95% CI | ||||
| Human | - | - | - | 2.17 | 0.734 | 3.53 | 2.30 | 0.664 | 4.10 | 58.4 ± 2.5 |
| 大规模组 | ||||||||||
| CosyVoice | BPE | 170k Multi. | 416M | 4.75 | 0.635 | 3.88 | 3.75 | 0.575 | 4.09 | - |
| Spark-TTS | BPE | 102k Multi. | 507M | 3.29 | 0.570 | 3.94 | 3.02 | 0.513 | 4.20 | - |
| Llasa-1B | BPE | 250k Multi. | 1000M | 3.18 | 0.578 | 4.08 | 3.18 | 0.490 | 4.19 | - |
| VoiceStar | Phone | 65k EN | 840M | 2.91 | 0.605 | 3.92 | 3.92 | 0.509 | 4.10 | - |
| CosyVoice2 | BPE | 167k Multi. | 618M | 2.87 | 0.656 | 4.18 | 2.97 | 0.587 | 4.23 | - |
| FireRedTTS-1S | BPE | 500k Multi. | 550M | 2.66 | 0.633 | 3.62 | 6.43 | 0.540 | 3.82 | - |
| 中等规模组 | ||||||||||
| VoiceCraft | Phone | 9k EN | 830M | 3.77 | 0.515 | 3.63 | 3.11 | 0.444 | 3.90 | 53.6 ± 2.5 |
| XTTS-v2 | BPE | 27k Multi. | 470M | 3.64 | 0.467 | 3.57 | 3.90 | 0.444 | 3.72 | 53.8 ± 2.7 |
| VoXtream-NS | Phone | 9k EN | 441M | 3.64 | 0.537 | 3.89 | 2.99 | 0.465 | 4.07 | 51.8 ± 2.6 |
| 流式组 | ||||||||||
| CosyVoice2:Out | BPE | 167k Multi. | 618M | 2.70 | 0.662 | 4.05 | 2.65 | 0.592 | 4.19 | 60.6 ± 2.4 |
| XTTS-v2:Out | BPE | 27k Multi. | 470M | 3.99 | 0.480 | 3.59 | 4.06 | 0.440 | 3.64 | 53.0 ± 2.7 |
| VoXtream:Out | Phone | 9k EN | 441M | 3.82 | 0.529 | 3.88 | 3.09 | 0.461 | 4.08 | 53.4 ± 2.5 |
| VoXtream:Full | Phone | 9k EN | 441M | 3.81 | 0.529 | 3.90 | 3.15 | 0.458 | 4.07 | 51.9 ± 2.6 |
关键结论:在中等规模数据组中,VoXtream非流式版本(VoXtream-NS)在SPK-SIM和UTMOS上取得了最佳结果,WER与VoiceCraft持平。其流式版本(Out和Full)在这些指标上仅有轻微下降,显示了架构的有效性。在流式组中,VoXtream在WER和UTMOS上优于XTTS-v2,自然度略低于CosyVoice2:Out,但后者使用了大得多的数据集。
表2:LibriSpeech长文本集上的全流式能力评估
| 模型 | WER (%) ↓ | SPK-SIM ↑ | UTMOS ↑ | 自然度偏好 (%) ↑ |
|---|---|---|---|---|
| Human | 1.97 | 0.784 | 4.16 | - |
| CosyVoice2:Full | 6.11 | 0.685 | 4.19 | 31 |
| VoXtream:Full | 3.24 | 0.564 | 4.23 | 57 |
关键结论:在处理长文本(平均15秒)的全流式场景下,VoXtream的WER(3.24%)显著低于CosyVoice2(6.11%),且自然度偏好(57%)大幅领先于CosyVoice2(31%),证明了其在长序列流式合成中的鲁棒性。
表3:A100 GPU上FP16性能
| 模型 | 首次分组延迟(FPL) (ms) ↓ | 实时率(RTF) ↓ |
|---|---|---|
| CosyVoice2 | 1643 | 0.85 |
| XTTS-v2 | 295 | 0.37 |
| XTTS-v2:DS | 196 | 0.26 |
| VoXtream | 171 | 1.00 |
| VoXtream:TC | 102 | 0.17 |
关键结论:这是论文最亮眼的成果。使用torch.compile(TC)后,VoXtream的首次分组延迟(FPL)降至102毫秒,远低于其他公开模型。其实时率(RTF)为0.17,意味着生成速度是实时的5倍以上。
表4:基础模型组件消融研究(SEED test-en)
| CSM-DT | SPK-ENC | WER (%) ↓ | SPK-SIM ↑ | UTMOS ↑ |
|---|---|---|---|---|
| ✗ | ✗ | 3.53 | 0.471 | 3.39 |
| ✓ | ✗ | 3.70 | 0.504 | 3.90 |
| ✗ | ✓ | 3.65 | 0.558 | 3.39 |
| ✓ | ✓ | 3.64 | 0.537 | 3.89 |
关键结论:单独引入冻结的CSM-DT能大幅提升UTMOS(3.39→3.90)和SPK-SIM。单独引入SPK-ENC能显著提升SPK-SIM(0.471→0.558)。两者结合时,UTMOS保持高位,SPK-SIM(0.537)高于基线但略低于仅用SPK-ENC,表明两者在提升说话人相似度上可能存在一定的协同但非完全叠加效应。WER在所有设置下变化不大,说明基础组件的引入主要提升了音质和音色。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一种架构新颖、逻辑自洽的低延迟流式TTS方案。其增量编码和单调时长预测的设计具有明确的创新性。实验全面,覆盖了零样本、输出流式、全流式等多种场景,并与多个强基线进行了对比。消融研究也证实了各个设计模块的有效性。技术正确性高,所有声称的性能都有数据支持。扣分点在于,作为一篇顶级会议论文,其核心架构组件(如TT和DT)在概念上(如基于语言模型的时序预测、分层生成)并非完全原创,更多是巧妙的组合与针对性优化。
- 选题价值:2.0/2:流式语音合成是AI实时交互的刚需,低延迟是核心痛点。本工作直面这一挑战,并取得了公开模型中的最优延迟,具有明确的理论价值和广阔的应用前景(如所有需要即时语音反馈的场景),与广大语音AI研究者和开发者高度相关。
- 开源与复现加成:0.5/1:论文提供了明确的GitHub代码仓库和在线演示,这极大地增加了工作的可信度和实用性。然而,对于模型权重(尤其是预训练的CSM-DT和ReDimNet的具体版本)的获取途径、以及完整的训练配置(如DeepSpeed详细参数)描述不够详尽,给完全复现带来了一定障碍。