📄 VoxMorph: Scalable Zero-Shot Voice Identity Morphing via Disentangled Embeddings
#语音克隆 #零样本 #语音合成 #流匹配 #音频安全
🔥 9.0/10 | 前10% | #语音克隆 | #流匹配 | #零样本 #语音合成
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Bharath Krishnamurthy (北德克萨斯大学)
- 通讯作者:Ajita Rattani (北德克萨斯大学)
- 作者列表:Bharath Krishnamurthy (北德克萨斯大学), Ajita Rattani (北德克萨斯大学)
💡 毒舌点评
这篇论文堪称生物识别安全领域的一声警钟,它用优雅的技术(解纠缠表示学习)和极低的成本(5秒音频),制造出了一个足以让现有语音验证系统头疼不已的“合成身份”。其亮点在于将看似复杂的攻击变得异常简单高效;短板则是,这种“降维打击”式的技术突破,也立刻暴露了当前ASV系统在应对此类高级、细粒度伪造时的脆弱性,给防御方带来了前所未有的压力。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
Vcbsl/VoxMorph。 - 模型权重:论文中未明确提及是否公开预训练模型权重,但鉴于其代码开源,权重很可能包含在内或后续会提供。
- 数据集:公开。论文明确声明“we release the first publicly available dataset of 10, 000 high-fidelity voice morphs”,并提供了项目页面链接。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了充分的复现信息,包括:数据集(LibriSpeech)、评估指标(FAD, KLD, WER, MMPMR/FMMPMR)及其计算方式、使用的基线模型(ViM, Vevo, MorphFader)、硬件环境(RTX 5000 Ada GPU)以及详细的消融实验设置。
- 引用的开源项目:论文引用并依赖了多个开源项目/模型,包括:GE2E(说话人验证)、CAM++(说话人验证)、自回归语言模型(如LLaMA)、条件流匹配模型(如COSYVOICE)、HiFTNet(声码器)、ECAPA-TDNN、HuBERT、Wav2Vec2(用于编码器消融)、Resemblyzer(用于评估)、Wav2Vec2-Base-960h(用于WER计算)。
📌 核心摘要
- 解决的问题:现有的语音身份变形(VIM)攻击方法存在严重缺陷:计算成本高、不可扩展(需要为每对说话人微调)、依赖声学相似的说话人对,且生成语音质量低。这些限制了其作为实际威胁的可行性。
- 方法核心:提出VoxMorph,一个零样本框架。其核心是将声音解纠缠为韵律嵌入(说话风格)和音色嵌入(核心身份)。对两个说话人的这两种嵌入分别使用球面线性插值进行混合,然后将融合的嵌入输入一个三阶段合成管线:自回归语言模型生成声学令牌(由融合韵律引导),条件流匹配网络生成梅尔频谱图(由融合音色引导),最后神经声码器生成波形。
- 与已有方法相比新在哪里:a) 零样本与可扩展性:仅需5秒音频,无需微调即可生成变形语音。b) 解纠缠表示:将风格与身份分离,可独立精细控制,避免了传统单一嵌入混合产生的声学伪影。c) 先进合成架构:利用自回归模型和流匹配模型的强大生成能力,确保了高保真度。d) 首个大规模数据集:发布包含10,000个样本的数据集用于防御研究。
- 主要实验结果:在严格安全阈值(0.01% FAR)下,VoxMorph-v2实现了67.8%的完全匹配变形成功率(FMMPMR),比之前最优方法(ViM的2.61%)高出数十倍。音频质量(FAD)比基线提升2.6倍,可理解性错误(WER)降低73%。详细对比见下表:
| 方法 | FAD↓ (vs Real) | WER↓ | KLD↓ | MMPMR (%) @ 0.01% | FMMPMR (%) @ 0.01% |
|---|---|---|---|---|---|
| MorphFader [16] | 8.96 | 1.84 | 0.4332 | 0.0 | 0.0 |
| Vevo [3] | 9.14 | 0.54 | 0.1899 | 82.40 | 9.00 |
| ViM [14] | 7.52 | 1.06 | 0.3501 | 2.61 | 0.00 |
| VoxMorph-v1 | 5.03 | 0.33 | 0.1404 | 78.60 | 60.60 |
| VoxMorph-v2 | 4.90 | 0.19 | 0.1385 | 99.80 | 67.80 |
- 实际意义:证明了语音变形攻击已从理论走向实用,对自动说话人验证(ASV)系统构成切实、可扩展的安全威胁。同时,通过开源代码、模型和大规模数据集,为社区研究和开发下一代变形攻击检测(MAD)对策提供了关键工具和基准。
- 主要局限性:a) 攻击属性:该技术本身是一种攻击手段,存在滥用风险。b) 评估局限:评估主要在LibriSpeech数据集上进行,且攻击的是特定ASV系统(Resemblyzer),对真实世界、多场景、多模态ASV系统的威胁程度有待进一步验证。c) 多说话人变形:当前方法聚焦于两两变形,未来可扩展至更多说话人融合。
🏗️ 模型架构
VoxMorph是一个端到端的零样本语音身份变形框架,其整体架构如图1所示,包含提取、插值、合成三个核心阶段。
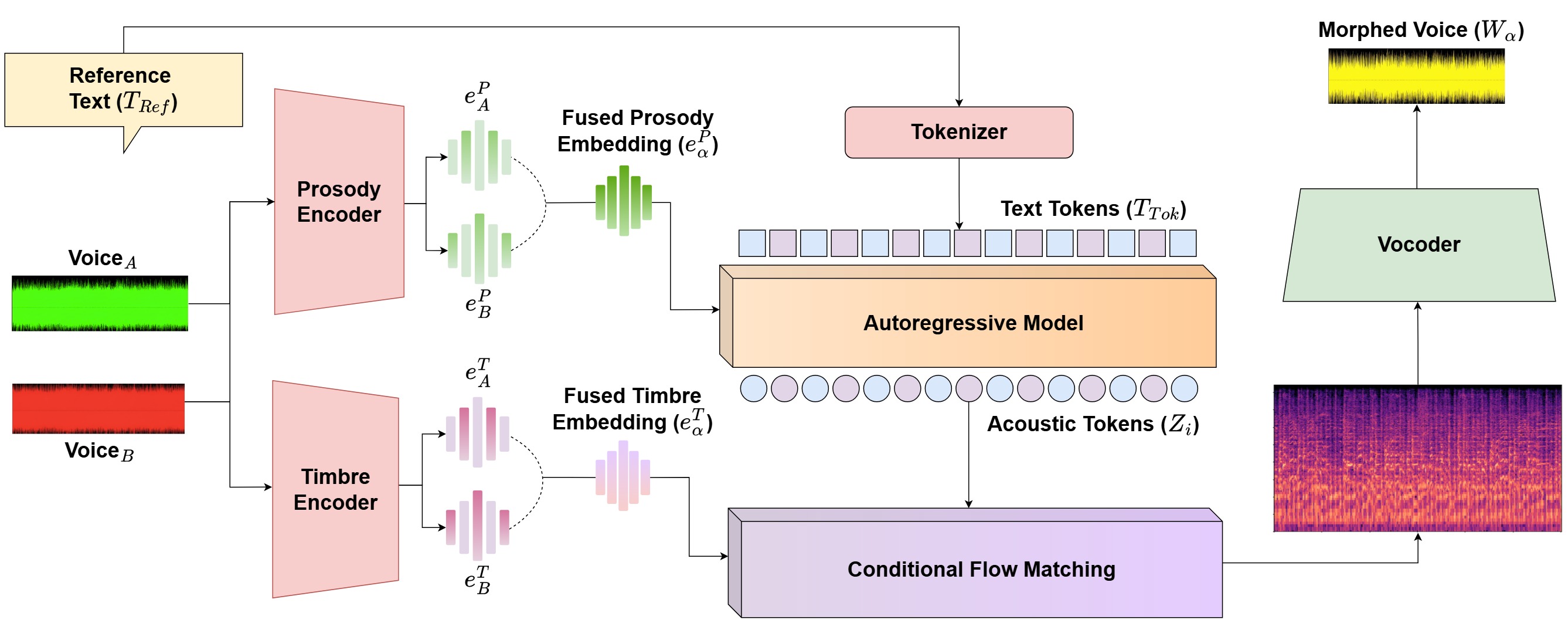 图1:VoxMorph框架概览。该流程包含三个核心阶段:(1) 提取:从两个说话人身份中提取解纠缠的韵律(风格)和音色(身份)嵌入。(2) 插值:使用Slerp对嵌入表示进行独立插值。(3) 合成/变形:融合的韵律嵌入调节自回归语言模型,而融合的音色嵌入引导条件流匹配网络生成梅尔频谱图。最后,神经声码器将频谱图转换为高保真的变形波形。
图1:VoxMorph框架概览。该流程包含三个核心阶段:(1) 提取:从两个说话人身份中提取解纠缠的韵律(风格)和音色(身份)嵌入。(2) 插值:使用Slerp对嵌入表示进行独立插值。(3) 合成/变形:融合的韵律嵌入调节自回归语言模型,而融合的音色嵌入引导条件流匹配网络生成梅尔频谱图。最后,神经声码器将频谱图转换为高保真的变形波形。
详细架构分解:
- 解纠缠特征提取 (Disentangled Vocal Feature Extraction):
- 输入:每个说话人的原始音频片段(≥5秒)。
- 组件:
- 韵律编码器 (Prosody Encoder):采用基于GE2E的模型。其功能是将输入语音中与说话风格相关的高阶特征(如节奏、音高模式)编码成一个低维的韵律嵌入 (
eP)。 - 音色编码器 (Timbre Encoder):采用CAM++编码器。其功能是提取与说话人生物身份核心相关的特征(如声道特性),生成一个音色嵌入 (
eT)。
- 韵律编码器 (Prosody Encoder):采用基于GE2E的模型。其功能是将输入语音中与说话风格相关的高阶特征(如节奏、音高模式)编码成一个低维的韵律嵌入 (
- 设计动机:使用不同的专用编码器,旨在将语音中混杂的“风格”和“身份”信息在表示层面进行解耦,为后续独立、精细的操纵奠定基础。
- 独立插值 (Interpolation):
- 输入:来自两个说话人(A和B)的韵律嵌入 (
eP_A,eP_B) 和音色嵌入 (eT_A,eT_B)。 核心操作:对eP_A/eP_B和eT_A/eT_B分别应用球面线性插值 (Slerp)。公式为e_α = sin((1-α)Ω)/sin(Ω) e_A + sin(αΩ)/sin(Ω) * e_B,其中Ω是两个嵌入向量之间的夹角。 - 设计动机:由于嵌入向量经过L2归一化,它们位于一个超球面上。简单的线性平均(Lerp)会使插值结果偏离该流形,导致质量下降。Slerp沿着超球面的最短路径(测地线)进行插值,确保结果仍然是一个有效的、高质量的说话人表示,从而最小化声学伪影并实现平滑过渡。
α控制两个说话人特征的混合比例。
- 输入:来自两个说话人(A和B)的韵律嵌入 (
- 多阶段合成 (Multi-Stage Synthesis):
- 输入:融合后的韵律嵌入 (
eP_α)、融合后的音色嵌入 (eT_α),以及要合成的文本。 - 阶段1 - 声学令牌生成:
- 组件:一个自回归语言模型 (AR LM)。
- 过程:将
eP_α投影到令牌空间并作为前缀条件,与文本一起输入AR LM。模型以自回归方式生成一串离散的声学令牌 (z)。公式z_i ~ P(z_i | z_{<i}, Ttok, eP_α)表示当前令牌的生成依赖于先前令牌、文本和韵律嵌入。
- 阶段2 - 梅尔频谱图合成:
- 组件:一个条件流匹配 (CFM) 网络。
- 过程:CFM模型以声学令牌为输入,并以
eT_α为条件,生成梅尔频谱图。它通过学习一个向量场,将噪声分布转化为目标频谱图的分布(求解概率流常微分方程)。论文提到使用了无分类器引导 (CFG) 以增强条件嵌入的效果。
- 阶段3 - 波形合成:
- 组件:一个HiFTNet 神经声码器。
- 过程:接收生成的梅尔频谱图,将其转换为高保真、自然的最终变形语音波形 (
W_α)。
- 输入:融合后的韵律嵌入 (
💡 核心创新点
- 零样本、可扩展的语音变形框架:这是最核心的创新。与先前需要为每对说话人收集大量数据并进行长时间微调(8-10小时)的ViM方法不同,VoxMorph仅需每方5秒音频,无需任何模型重训练即可生成变形语音。这使得大规模生成攻击成为可能。
- 基于解纠缠表示的精细化控制:首次在语音变形中系统性地将声音解纠缠为韵律(风格)和音色(身份)两个独立的嵌入空间。这解决了传统方法使用单一混合嵌入导致的声学伪影和身份不连贯问题,允许对说话风格和身份进行独立、精细的插值控制。
- 利用Slerp在超球面上进行语义插值:创新性地将通常在度量学习中用于保持相似性的Slerp插值方法应用于嵌入融合。这比简单的线性平均更能保持嵌入的有效性和生成语音的质量,是提升变形保真度的关键技术细节。
- 构建首个大规模高质量语音变形数据集:不仅提出了攻击方法,还贡献了一个包含10,000个高保真语音变形样本的公开数据集。这为后续研究防御方法(如MAD)提供了不可或缺的资源,体现了完整的研究闭环。
🔬 细节详述
- 训练数据:使用 LibriSpeech 数据集的clean子集,规模约100小时(16kHz 英语朗读语音)。预处理包括性别筛选,随机选择500对(女-女,男-男)用于生成变形。论文中未详细说明具体的预处理和数据增强步骤。
- 损失函数:论文中未明确说明VoxMorph框架的训练损失函数。它主要利用了预训练的编码器和生成模型。其创新点在于推理时的解纠缠和融合策略,而非全新的损失函数设计。
- 训练策略:论文强调VoxMorph是零样本的,因此整个变形流程不需要训练。它利用的是预训练好的组件(韵律编码器、音色编码器、AR LM、CFM、声码器)。论文未提供这些预训练组件的具体训练策略,因为它们被视为已有的“工具”。
- 关键超参数:主要超参数是插值因子 α,论文设定
α ≥ 0.5以确保两个身份的均衡混合。其他如自回归模型和CFM的具体架构超参数未在论文中说明,可能继承自引用的模型(如COSYVOICE)。 - 训练硬件:论文中未明确提及训练硬件(因为其本身无需训练)。实验和生成是在单张 NVIDIA RTX 5000 Ada GPU上进行的。
- 推理细节:推理即上述三阶段流程。AR LM和CFM的解码细节(如温度、beam size)未详细说明,但提到了使用CFG来提升生成质量。整个流程在单张GPU上完成。
- 正则化或稳定训练技巧:不适用于此零样本推理框架。其稳定性依赖于各个预训练组件的稳健性以及Slerp插值的几何合理性。
📊 实验结果
论文在LibriSpeech数据集上,针对随机选取的500对说话人生成变形语音,并进行了全面评估。
主要对比结果(关键数据): 如表1所示,VoxMorph在所有指标上均显著超越了基线。
| 方法 | FAD↓ (vs Real) | FAD↓ (vs Clone) | KLD↓ | WER↓ | MMPMR (%) @ 0.01% | MMPMR (%) @ 0.1% | MMPMR (%) @ 1% | FMMPMR (%) @ 0.01% | FMMPMR (%) @ 0.1% | FMMPMR (%) @ 1% |
|---|---|---|---|---|---|---|---|---|---|---|
| MorphFader [16] | 8.96 | 0.25 | 0.4332 | 1.84 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Vevo [3] | 9.14 | 0.63 | 0.1899 | 0.54 | 82.40 | 94.60 | 98.80 | 9.00 | 44.00 | 85.60 |
| ViM [14] | 7.52 | 1.52 | 0.3501 | 1.06 | 2.61 | 29.66 | 89.38 | 0.00 | 5.61 | 52.10 |
| VoxMorph-v1 | 5.03 | 0.24 | 0.1404 | 0.33 | 78.60 | 98.40 | 100 | 60.60 | 96.00 | 99.80 |
| VoxMorph-v2 | 4.90 | 0.27 | 0.1385 | 0.19 | 99.80 | 100 | 100 | 67.80 | 97.20 | 100 |
关键结论:
- 音频质量:VoxMorph的FAD(vs Real)和KLD值最低,表明生成的语音在分布和频谱上最接近真实人类语音。
- 可理解性:WER值极低,证明变形过程完美保留了语音内容。
- 攻击有效性:这是最重要的结果。在最严格的0.01%错误接受率(FAR)阈值下:
- VoxMorph-v2的FMMPMR达到67.8%,意味着超过三分之二��变形语音能同时骗过验证系统,确认为两个源说话人。而ViM的FMMPMR为0%,Vevo仅为9%。
- VoxMorph-v2的MMPMR在0.01% FAR下已接近100%,表明其几乎可以稳定骗过至少一个身份。
- 扩展性:VoxMorph-v2(使用多个语音片段)比VoxMorph-v1(单个片段)性能更优,展示了框架利用更多数据提升攻击效果的能力。
消融实验结果:
- 插值方法消融 (表2):比较了线性平均(Lerp)、混合插值(Lerp/Slerp)和纯Slerp。纯Slerp方法(VoxMorph)在FMMPMR上达到67.8%,显著优于Lerp的62.6%,验证了在超球面上进行插值的有效性。
- 韵律编码器消融 (表3):比较了GE2E、ECAPA-TDNN、HuBERT、Wav2Vec2作为韵律编码器。基于LSTM的GE2E编码器在FMMPMR上达到60.6%,显著优于其他编码器,表明其对动态韵律特征的捕获能力更适合变形任务。
表2:插值方法消融研究。Slerp方法在FMMPMR上表现出显著优势。
表3:不同韵律编码器模型的消融研究。GE2E编码器在严格的0.01%阈值下表现出最高的FMMPMR。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性:极高。将语音变形问题转化为解纠缠表示的可控插值问题,并引入Slerp和现代生成模型管线,是概念和技术上的双重突破。
- 技术正确性:高。架构设计合理,各模块功能清晰,实验验证了每个关键设计点的必要性。
- 实验充分性:非常充分。与多个领域的SOTA进行了全面对比,包含了质量、可懂度、攻击成功率等多维度指标,并进行了两项深入的消融实验。
- 证据可信度:高。结果具有说服力,数字提升巨大且一致。提供了完整的数据集以供验证。
- 选题价值:1.5/2
- 前沿性:非常前沿,填补了语音生物识别安全中关于变形攻击的重要研究空白。
- 潜在影响:巨大且直接。它重新定义了ASV系统面临的威胁模型,迫使安全社区必须正视并研究此类高级攻击。
- 实际应用空间:应用空间明确但具有两面性:既可用于攻击测试,更重要的为构建更强的防御系统提供了研究基础。
- 读者相关性:对于从事语音安全、生物识别、深度学习防御的研究者来说,相关性极高。
- 开源与复现加成:+1/1
- 代码:提供了代码仓库链接(Vcbsl/VoxMorph)。
- 数据集:明确声明发布了首个大规模高保真语音变形数据集。
- 复现细节:论文详细描述了实验设置(数据集、硬件、指标、基线实现),并提供了消融实验,复现指南清晰。
- 整体开源计划非常完整,极大地降低了研究门槛。