📄 VMSP: Video-to-Music Generation with Two-Stage Alignment and Synthesis
#音乐生成 #扩散模型 #多模态模型 #跨模态
✅ 7.0/10 | 前25% | #音乐生成 | #扩散模型 | #多模态模型 #跨模态
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Xin Gu(中国传媒大学信息与通信工程学院)
- 通讯作者:Wei Jiang*(中国传媒大学信息与通信工程学院)
- 作者列表:Xin Gu(中国传媒大学信息与通信工程学院)、Wei Jiang*(中国传媒大学信息与通信工程学院)、Yujian Jiang(中国传媒大学信息与通信工程学院)、Zhibin Su(中国传媒大学信息与通信工程学院)、Ming Yan(中国传媒大学信息与通信工程学院)
💡 毒舌点评
论文的亮点在于其清晰的“先对齐中间表示,再生成”的两阶段框架设计,这有效缓解了端到端模型常忽略音乐结构的问题,逻辑自洽。但短板也明显:它严重依赖特定的、可能闭源的MLLM(Qwen2.5-VL, Qwen2-Audio)来生成感知描述,这增加了复现成本和不可控性,且论文未开源任何资源,让后续研究者“只能看,不能练”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的模型权重。
- 数据集:使用了公开数据集MVED, MuVi-Sync, V2M-bench,但论文未说明其自身的数据预处理脚本或额外数据是否公开。
- Demo:未提供在线演示。
- 复现材料:给出了部分训练细节(优化器、学习率调度、训练轮数、硬件)和模型架构参数(Transformer层数、维度),但关键组件的完整训练配置(如VAE-GAN)、MLLM的详细使用方式(Prompt、是否微调)、以及评估脚本未提供。
- 论文中引用的开源项目:引用并依赖了MetaClip、CLAP、Qwen2.5-VL、Qwen2-Audio等模型/工具。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的视频生成音乐(V2M)方法大多直接将视频特征映射到声学标记或波形,跳过了对音乐中间表示(如语义、结构)的建模,导致生成的音乐结构连贯性差、和声不丰富。
- 方法核心:提出VMSP,一个基于分层条件映射的两阶段生成框架。第一阶段(跨模态映射)通过Transformer学习视频与音乐语义特征的段级对齐,并利用多模态大语言模型(MLLM)确保视频与音乐在感知层面的一致性。第二阶段(音乐生成)使用扩散Transformer(DiT),将上述对齐后的语义特征和感知信息作为分层条件,指导音乐波形的生成。
- 与已有方法的新颖性:相比于直接映射或依赖文本中间描述的方法,VMSP显式地建模了音乐的“中间表示”(语义和感知),并设计了分层条件注入机制(全局感知条件+局部语义条件),旨在同时保证全局氛围一致和局部时间对齐。
- 主要实验结果:在MVED和MuVi-Sync数据集上训练,在V2M-bench数据集上评估。定量对比显示VMSP在KL、FAD、Density和Coverage指标上均优于CMT、Video2Music、M2UGen和VidMuse等基线模型。消融实验表明两阶段框架和双重条件(语义+感知)缺一不可。用户研究也显示VMSP在音频质量、音乐性、对齐度和感知和谐度上具有优势。
| 模型/方法 | KL↓ | FAD↓ | Density↑ | Coverage↑ |
|---|---|---|---|---|
| GT | 0.000 | 0.000 | 1.167 | 1.000 |
| CMT[7] | 1.220 | 8.637 | 0.080 | 0.070 |
| Video2Music[9] | 1.782 | 18.722 | 0.103 | 0.023 |
| M2UGen[18] | 0.997 | 5.104 | 0.608 | 0.433 |
| VidMuse[6] | 0.734 | 2.459 | 1.250 | 0.730 |
| VMSP | 0.607 | 2.580 | 1.280 | 0.870 |
表1: 客观定量对比结果(来自论文)
| 模型变体 | KL↓ | FAD↓ | Density↑ | Coverage↑ |
|---|---|---|---|---|
| VMSP w/o T | 0.844 | 3.488 | 0.531 | 0.487 |
| VMSP w/o P | 0.705 | 2.553 | 1.032 | 0.730 |
| VMSP w/o S | 0.773 | 2.783 | 0.606 | 0.582 |
| VMSP | 0.607 | 2.580 | 1.280 | 0.870 |
表2: 消融实验结果(来自论文)
- 实际意义:为视频自动配乐提供了一种新的、注重音乐结构连贯性的解决方案,有望应用于视频剪辑、广告创作等多媒体内容生成领域。
- 主要局限性:框架依赖外部大型多模态模型(Qwen系列)提取感知描述,计算成本高且可能引入黑箱不确定性;论文未开源代码和模型,限制了可复现性;在更长视频或更复杂语义场景下的泛化能力有待验证。
🏗️ 模型架构
VMSP采用两阶段架构(如图1所示):跨模态映射阶段和音乐生成阶段。
整体流程:
- 输入:视频片段(T秒)。
- 第一阶段(跨模态映射):
- 视频特征提取:使用预训练的MetaClip模型对视频按1fps采样,得到T个关键帧,每帧提取512维视觉特征,构成序列
V ∈ R^{T×512}。 - 音乐语义特征提取与对齐:使用CLAP模型的音乐版本提取目标音乐的语义特征,同样按1秒粒度提取。然后通过K-Means聚类(K=1024)将连续特征离散化为聚类中心ID序列
Y ∈ {1, ..., K}^T,作为语义映射的监督信号。 - 视频-音乐语义映射:使用一个4层Transformer编码器-解码器模型。输入视频特征序列
V,解码器自回归预测离散的CLAP聚类ID序列Y,通过交叉熵损失L_S训练。这一步实现了视频与音乐在段级语义上的对齐。 - 感知一致性对齐:利用多模态大语言模型(MLLM)——具体为Qwen2.5-VL(用于视频)和Qwen2-Audio(用于音乐)——分别生成视频和音乐的感知描述文本(侧重于氛围、情绪等),为后续全局条件提供监督。
- 视频特征提取:使用预训练的MetaClip模型对视频按1fps采样,得到T个关键帧,每帧提取512维视觉特征,构成序列
- 第二阶段(音乐生成):
- 音乐潜在表示:通过一个音频VAE-GAN将原始音乐波形压缩成低维潜在表示
z。 - 扩散模型(DiT):使用Diffusion Transformer作为骨干生成模型。
- 分层条件注入:
- 全局条件:将视频的感知描述文本输入CLAP文本编码器得到嵌入
T_text,与扩散时间步嵌入相加后,作为前缀拼接到DiT输入序列前,控制音乐的全局感知基调。 - 局部条件:将第一阶段得到的视频-音乐对齐语义特征序列
C_clap(即CLAP聚类ID对应的特征)通过交叉注意力层注入DiT。在扩散去噪步骤t,当前音乐潜在特征z_t作为Query,C_clap作为Key和Value,实现段级时间对齐。
- 全局条件:将视频的感知描述文本输入CLAP文本编码器得到嵌入
- 训练目标:预测噪声的均方误差损失
L_mse。
- 音乐潜在表示:通过一个音频VAE-GAN将原始音乐波形压缩成低维潜在表示
- 输出:生成的音乐波形。
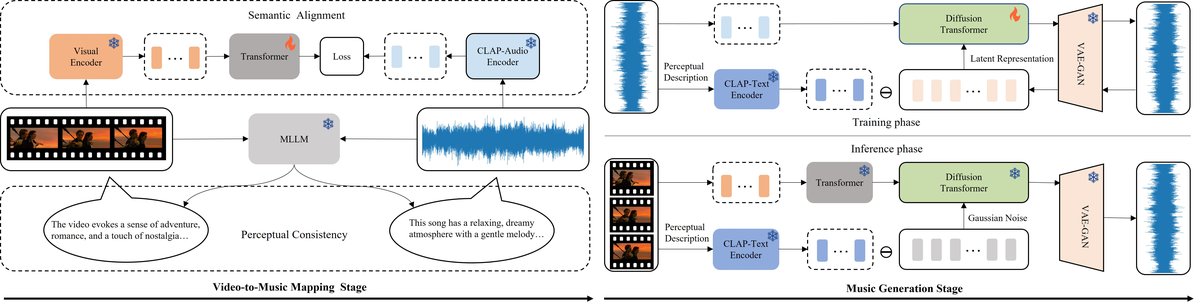 图1展示了两阶段框架:上半部分为跨模态映射阶段,通过Transformer进行语义映射,并用MLLM获取感知描述;下半部分为音乐生成阶段,DiT模型接受全局感知条件(文本+时间步)和局部语义条件(交叉注意力)的分层引导,生成音乐波形。
图1展示了两阶段框架:上半部分为跨模态映射阶段,通过Transformer进行语义映射,并用MLLM获取感知描述;下半部分为音乐生成阶段,DiT模型接受全局感知条件(文本+时间步)和局部语义条件(交叉注意力)的分层引导,生成音乐波形。
💡 核心创新点
两阶段解耦与中间表示建模:
- 之前局限:许多方法采用端到端架构,直接从视频特征映射到声学标记或波形,忽略了音乐自身的结构化中间表示(如和声、旋律轮廓),导致生成音乐缺乏连贯性。
- 如何起作用:将任务明确解耦为“对齐”和“生成”。第一阶段显式学习视频到音乐语义表示(CLAP聚类)和感知表示(文本描述)的映射。第二阶段以这些结构化表示为条件生成音乐。
- 收益:显式建模中间表示,为生成模型提供了更清晰、更结构化的指导信号,显著提升了生成音乐的结构连贯性(如消融实验表2所示,VMSP w/o T效果差)。
分层条件映射机制:
- 之前局限:多数方法使用单一层次的条件(如仅全局情感标签或仅局部特征),难以同时保证音乐整体氛围与视频匹配,又保证音画时间上的精准同步。
- 如何起作用:设计双路径条件注入:a) 全局感知条件:由MLLM生成的感知描述文本编码后注入,控制音乐整体风格、情绪与视频匹配。b) 局部语义条件:由第一阶段对齐的逐秒CLAP语义特征通过交叉注意力注入,确保音乐片段与视频片段在时间上对齐。
- 收益:实现了“宏观匹配+微观同步”的细粒度控制,增强了视频配乐的整体和谐度与时间一致性。实验对比(VMSP vs. VMSP w/o P, VMSP w/o S)证明了两种条件都不可或缺。
利用现有MLLM生成感知描述作为监督信号:
- 之前局限:传统方法依赖手工标注或简单的自动标签来描述视频/音乐的感知属性,标注成本高且粒度粗。
- 如何起作用:创新性地利用强大的闭源MLLM(Qwen2.5-VL, Qwen2-Audio)自动生成侧重感知维度的文本描述。这些描述被用作桥梁,将视频和音乐在抽象感知层面关联起来。
- 收益:利用预训练大模型的强大语义理解能力,低成本地获得了高质量、细粒度的感知对齐监督信号,提升了生成音乐与视频在情绪、氛围上的匹配度。
🔬 细节详述
- 训练数据:使用了两个公开数据集:MVED(3000个电影片段及背景音乐)和MuVi-Sync(748个音乐视频)。评估使用V2M-bench数据集。数据增强未提及。
- 损失函数:
- 语义映射损失
L_S:标准交叉熵损失,用于训练Transformer预测离散的CLAP聚类ID序列。 - 音乐生成损失
L_mse:扩散模型的均方误差损失,用于预测噪声。
- 语义映射损失
- 训练策略:
- 优化器:AdamW。
- 学习率调度:CosineAnnealingLR。
- 训练轮数:300 epochs。
- 批量大小:未说明。
- Warmup:未说明。
- 关键超参数:
- Transformer映射模型:4层编码器-解码器,4头注意力,隐藏层维度512。最大序列长度20,推理时使用滑动窗口处理长视频。
- CLAP聚类:K-Means聚类,K=1024。
- VAE-GAN:将44.1kHz音频压缩为43Hz,64维的潜在表示。
- 训练硬件:2张NVIDIA A100 GPU。
- 推理细节:未详细说明解码策略、温度等。提及对长视频使用滑动窗口。
- 正则化/稳定训练技巧:未说明。
📊 实验结果
主要定量对比(在V2M-bench上评估,数值来自论文表1): (表格已在核心摘要部分给出)
- 关键结论:VMSP在所有四个指标上均取得最优或接近最优的结果。与最强的基线VidMuse相比,VMSP在KL和Coverage(多样性)上有显著优势,FAD(保真度)和Density(质量)也更优。与M2UGen(基于LLM)相比,VMSP在所有指标上全面胜出。
消融实验(数值来自论文表2): (表格已在核心摘要部分给出)
- 关键结论:
- VMSP w/o T(单阶段,无中间表示):性能全面下降,尤其Density和Coverage骤降,证实了直接映射的局限性,凸显两阶段框架的必要性。
- VMSP w/o P(无全局感知条件):KL变好但Density和Coverage下降,说明仅靠局部语义对齐,音乐整体质量可能不稳定。
- VMSP w/o S(无局部语义条件):各项指标均下降,说明全局条件无法替代局部的时间对齐。
用户研究(结果见图2):
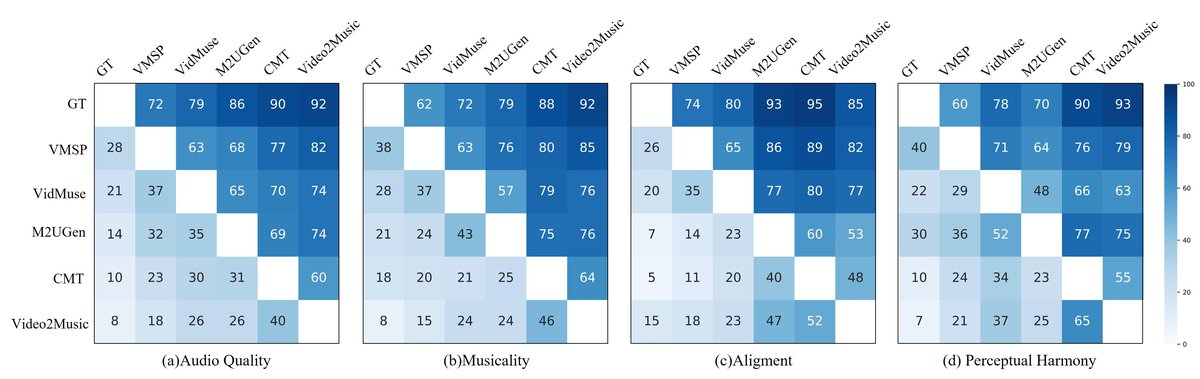 图2的混淆矩阵显示,在绝大多数成对比较中(与真实音频GT比较除外),参与者更倾向于选择VMSP生成的音乐,在音频质量、音乐性、对齐度和感知和谐度四个维度上均表现突出,提供了主观有效性证据。
图2的混淆矩阵显示,在绝大多数成对比较中(与真实音频GT比较除外),参与者更倾向于选择VMSP生成的音乐,在音频质量、音乐性、对齐度和感知和谐度四个维度上均表现突出,提供了主观有效性证据。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个设计精巧、目标明确的两阶段框架,有效解决了视频生成音乐中结构连贯性差的痛点。创新点(中间表示建模、分层条件)具有工程合理性和实证支持。技术实现上结合了Transformer、MLLM和Diffusion Model,符合当前技术趋势。然而,对MLLM的具体使用方式(是否微调、prompt设计细节)阐述较简,部分关键组件(如VAE-GAN)细节缺失。对比方法虽然覆盖了主要类型(符号、声学、LLM-based),但可能遗漏了一些最新的扩散模型工作。
- 选题价值:1.5/2:视频自动配乐是多模态生成领域的热点,应用前景明确。论文关注于提升生成音乐的“艺术质量”(连贯性、和谐度),而不仅仅是技术可行性,这具有很好的实际意义。对于关注音频生成和多模态内容创作的读者而言,该工作具有参考价值。
- 开源与复现加成:-0.5/1:论文完全未提及任何开源承诺。其关键依赖项(Qwen系列MLLM、CLAP音乐模型、MetaClip)中,部分本身是闭源或需要特定申请,结合论文自身未开源代码和模型,使得完整复现该工作面临较大障碍,严重扣分。