📄 ViTex: Visual Texture Control for Multi-Track Symbolic Music Generation via Discrete Diffusion Models
#音乐生成 #扩散模型 #可控生成 #多轨道 #数据集
✅ 7.0/10 | 前50% | #音乐生成 | #扩散模型 | #可控生成 #多轨道
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xiaoyu Yi(北京大学信息科学与技术学院,MBZUAI 音乐实验室)
- 通讯作者:未明确说明(论文中未使用“通讯作者”标识)
- 作者列表:Xiaoyu Yi(北京大学信息科学与技术学院,MBZUAI 音乐实验室)、Qi He(MBZUAI 音乐实验室)、Gus Xia(MBZUAI 音乐实验室)、Ziyu Wang(纽约大学柯朗数学科学研究所,MBZUAI 音乐实验室)
💡 毒舌点评
亮点:将“画图”这一直观操作引入多轨道音乐的“织体”控制,比提供抽象的潜在变量或文本描述更贴近人类作曲思维,解决了实际创作中的一个痛点。短板:ViTex的基于规则的织体特征提取(如静音比例阈值0.3)显得有些“手工匠气”,可能难以捕捉和表达更复杂、更主观的音乐织体,且离散化的视觉表示在表达连续性强弱变化时存在固有局限。
🔗 开源详情
- 代码:提供链接
https://vitex2025.github.io/,论文中声明代码可在该页面获取。 - 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:使用了公开的Lakh MIDI和Meta MIDI数据集,但提供了具体的筛选条件和最终规模(7175首)。论文未提及是否公开其筛选处理后的子集。
- Demo:论文中声明提供了Demo页面,链接为
https://vitex2025.github.io/。 - 复现材料:提供了详细的训练设置(优化器、学习率、batch size、调度策略)、数据处理工具(muspy)、硬件环境(4 H100 GPU)、以及关键的模型架构图和条件表示细节。
- 论文中引用的开源项目:使用了
muspy进行数据处理,引用了GETMusic[8]的吸收态离散扩散框架。 - 总结:论文提供了较好的开源基础,代码和Demo链接明确,训练细节清晰。但模型权重和处理数据集的公开性未明确说明。
📌 核心摘要
- 问题:现有的多轨道符号音乐生成系统缺乏一种直观、细粒度的“乐器织体”控制方式,无法让用户直接指定不同乐器在特定音区和时间点如何演奏。
- 方法:提出ViTex,一种将乐器织体可视化的表示方法(颜色编码乐器,位置编码音高/时间,笔触属性编码局部纹理)。基于此,构建了一个以ViTex和和弦进行为条件的离散扩散模型,使用无分类器引导进行训练,以生成8小节多轨道音乐。
- 创新点:首次将视觉化的织体表示用于多轨道音乐生成控制;该表示同时支持人类直观操作和作为模型条件;结合离散扩散模型实现了高质量、可控的生成。
- 实验结果:在Lakh MIDI和Meta MIDI的子集上训练和评估。定量实验(表1)显示,在条件生成任务中,本方法在乐器控制准确率(IA=0.600 vs Q&A-1: 0.584)、和弦准确率(CA=0.875 vs Q&A-1: 0.607)及排列质量(DOA=0.296 vs Q&A-1: 0.188)上均优于基线。无条件生成(表2)在律动相似度(GPS)和排列质量(DOA)上也优于AMT和MMT基线。主观听音测试(图3)表明,在给定乐器的生成任务中,本方法在连贯性、音乐性和创造性评分上均高于基线。
- 实际意义:为音乐制作人和爱好者提供了一种更自然、更精细的方式来控制AI生成的多声部音乐,有望成为音乐创作辅助工具的新范式。
- 主要局限性:ViTex表示基于规则,可能无法涵盖所有织体类型;当前仅支持8小节的片段生成;控制维度(音色、音区、密度)虽比之前工作更细,但仍有限。
🏗️ 模型架构
 模型整体架构:采用标准的UNet结构(图2),以处理被噪声污染的多轨道钢琴卷帘(pianoroll)
模型整体架构:采用标准的UNet结构(图2),以处理被噪声污染的多轨道钢琴卷帘(pianoroll)xt。模型接收两个额外条件输入:乐器织体特征y1(ViTex)和和弦进行y2。
- 输入:
xt是一个四维张量{0,1,2,3}^{128×128×11}(128时间步,128音高,11个乐器轨道,状态为静音/起始/持续/掩码),以及时间步t的嵌入。 - 条件注入:条件
y1(乐器织体,形状{0,1}^{8×8×33})和y2(和弦,形状{0,1}^{32×12×3})首先通过一个“Reshape Block”。该模块通过直接拉伸对齐宽度维度,并使用小型MLP变换高度和通道维度,以匹配UNet各层的特征图尺寸。对齐后的条件特征图通过元素级加法注入到UNet的相应层级。具体地,y1注入到底部两层,y2注入到中间两层。 - 核心组件:每个UNet层级包含ResBlock、Self Attention(自注意力)、下采样(Downsample)或上采样(Upsample)模块。自注意力机制用于建模
xt长距离依赖。 - 输出:模型预测
pθ(x̂0 | xt, y1, y2)的对数概率,通过无分类器引导(公式5)得到最终引导后的预测,用于反向扩散采样。
💡 核心创新点
- 提出ViTex视觉化织体表示:这是本文的核心贡献。之前的方法要么用粗粒度的乐器标签,要么用难以解释的潜在变量。ViTex通过颜色、空间位置和笔触属性,将高维的乐器织体信息编码为直观的图像,既便于人类“绘画式”控制,又可转化为紧凑的机器可读特征图作为模型条件。
- 定义并解决了“多轨道织体控制”生成任务:明确指出了现有工作在多轨道生成控制上的空白——缺乏对“乐器织体”(即哪些乐器在什么音区、何时、如何演奏)的直接控制能力。本文将“乐器编配”定义为一个关键控制维度,并提供了完整的解决方案。
- 将规则特征提取与生成模型紧密结合:ViTex的生成不是学习得到的,而是基于音乐理论规则(计算同步音符数、静音比例)从钢琴卷帘中提取。这种设计保证了控制信号的可解释性和确定性,并成功作为条件驱动了强大的扩散生成模型。
- 采用离散扩散模型处理多轨道音乐:沿用GETMusic的吸收态离散扩散框架,该框架天然适合处理离散的符号音乐表示(钢琴卷帘状态),并支持无分类器引导,使模型能在条件生成(跟随ViTex和和弦)和无条件生成之间灵活切换。
🔬 细节详述
- 训练数据:使用Lakh MIDI和Meta MIDI数据集的筛选子集。筛选条件:4/4拍,速度110-130 BPM,无转调,至少40小节,至少5个活跃轨道且跨越3个以上乐器类别,音符数>50,包含鼓且至少有钢琴/吉他/贝斯之一。最终得到7175首歌曲,90%/10%划分训练/测试。使用
muspy处理。 - 损失函数:使用
x0预测损失(公式4):L_pred = -E_{t~U(1,T), q(x0)q(xt|x0)}[log pθ(x0 | xt)]。在无分类器引导训练中,pθ(x0 | xt)被替换为pθ(x0 | xt, y1, y2)。 - 训练策略:优化器为AdamW,学习率3e-4(余弦衰减调度),batch size 100,在4块H100 GPU上训练。训练时,条件
y1和y2以0.5的概率被替换为空(null)。 - 关键超参数:音乐表示为16分音符分辨率,8小节(32拍),128个音高,11个乐器类别(钢琴、钢片琴、吉他、贝斯、小提琴、合奏、小号、萨克斯、长笛、合成器效果、鼓)。织体特征图为8x8(时间x音高区),和弦特征图为32x12(拍x音高类)。
- 训练硬件:4块NVIDIA H100 GPU。
- 推理细节:采用吸收态离散扩散反向过程(公式2,3)。每一步先根据引导公式(5)预测
x̂0,若进行修复(inpainting)则替换已知区域,再从后验分布采样x_{t-1}。引导强度λ_ins和λ_chd是可调超参数。 - 正则化技巧:无分类器引导的训练本身可视为一种正则化,提升模型泛化能力。
📊 实验结果
条件生成定量评估(表1)
| 模型 | 乐器控制 | 和弦控制 | 质量 | ||
|---|---|---|---|---|---|
| IA↑ | OAD↑ | OAIOI↑ | CA↑ | OAP↑ | |
| Q&A-1[6] | 0.584 | 0.135 | 0.451 | 0.607 | 0.450 |
| Q&A-2[6] | 0.299 | 0.082 | 0.110 | 0.043 | 0.253 |
| Ours | 0.600 | 0.626 | 0.494 | 0.875 | 0.731 |
IA: 乐器准确率;OAD: 音符时长分布重叠度;OAIOI: 音符起始间隔分布重叠度;CA: 和弦准确率;OAP: 音高分布重叠度;DOA: 编排度。↑表示越高越好。
无条件生成定量评估(表2)
| 模型 | PCE | GPS | DOA ↑ |
|---|---|---|---|
| Ground Truth | 1.741 | 0.804 | 0.303 |
| MMT[1] | +0.103 | +0.080 | 0.171 |
| AMT[9] | -0.317 | +0.174 | 0.278 |
| Ours | -0.174 | +0.050 | 0.307 |
PCE: 音高类熵;GPS: 律动模式相似度;表示越接近真实值越好。DOA: 编排度,↑越高越好。*
关键结论:在条件生成中,本模型在所有控制指标和质量指标上均显著优于基线Q&A。在无条件生成中,本模型在律动相似度(GPS)和编排质量(DOA)上超越了基线MMT和AMT,PCE略有偏差但优于MMT。
主观听音测试(图3)
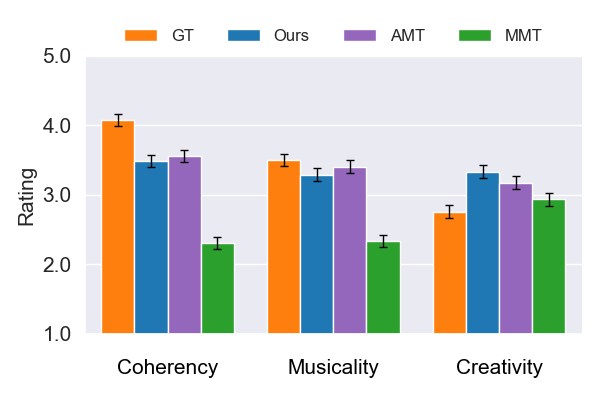
 (图a) 音乐续写任务:本模型在“创造性”上得分最高,在“连贯性”和“音乐性”上略低于AMT但高于MMT。
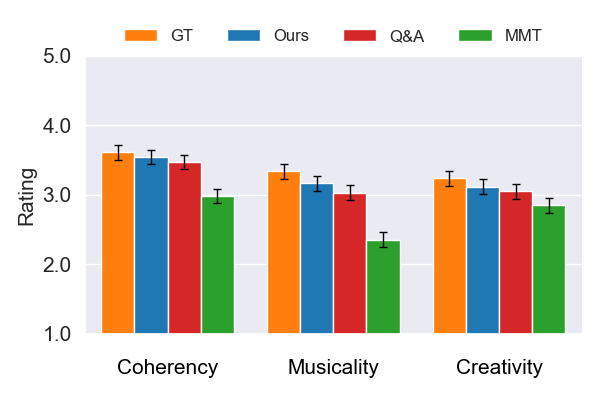
(图b) 给定乐器生成任务:本模型在“连贯性”、“音乐性”、“创造性”三项指标上均显著高于MMT和Q&A基线。
(图a) 音乐续写任务:本模型在“创造性”上得分最高,在“连贯性”和“音乐性”上略低于AMT但高于MMT。
(图b) 给定乐器生成任务:本模型在“连贯性”、“音乐性”、“创造性”三项指标上均显著高于MMT和Q&A基线。
⚖️ 评分理由
- 学术质量:5.5/7:论文清晰地定义并尝试解决一个重要但被忽视的问题(多轨道织体控制)。提出了一种新颖的控制表示ViTex,并将之与成熟的扩散模型框架结合。实验设计严谨,包含充分的定量对比和主观评估,结果支持其主张。扣分点在于技术集成的创新度(扩散模型非本作核心创新),以及ViTex规则提取的潜在局限性。
- 选题价值:1.0/2:问题实际且具体,面向音乐创作的真实需求。研究方向具有前沿性(可控生成、人机交互创作),对音乐科技社区有直接应用价值。但受众面相对较窄,主要限于音乐生成和信息检索领域的研究者。
- 开源与复现加成:0.5/1:论文明确提供了代码和Demo页面的链接,并在实验部分详细说明了数据集筛选、训练超参数、硬件环境等关键信息,有助于复现。未明确提及是否开源预训练模型和处理后的数据集,但整体复现信息较为充分。